当面试官问你,在不考虑数字越界的情况下,有1亿条搜索数据,让你从中找到前100条频率高的数据你会怎么实现?
当时,我的第一印象是把数据分组,分别求前多少条?但是没法保证每组的前100条或者多少条数据刚好是前几位的,这个被否定了。
然后突然想到这不就是topK算法的变异,然后给面试官说了一下。找到一个对照值,然后把大于对照值的存储在left = [] 数组中,小于对照值的存储在right = [] 数组中,这样我们就得到了,两个数组,然后根据数组长度和K值比对进行递归,最终得到topK值。
具体算法实现如下
function topK(arr, k) {
if (arr.length < k || !arr) return arr;
let mid = arr.splice(0, 1);
let left = [],
right = [];
let len = arr.length;
for (let i = 0; i < len; i++) {
arr[i] > mid ? left.push(arr[i]) : right.push(arr[i]);
}
if (left.length === k) {
return left;
}
if (left.length > k) {
return topK(left, k);
}
if (left.length < k) {
return left.concat(mid, topK(right, k - left.length - 1));
}
}测试数据
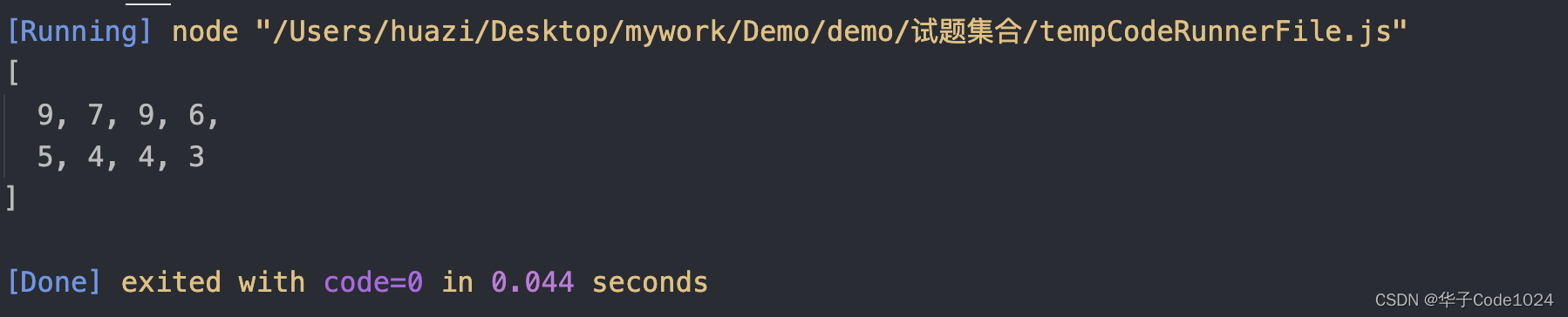
let karr = [6, 0, 1, 4, 9, 7, -3, 1, -4, -8, 4, -7, -3, 3, 2, -3, 9, 5, -4, 0];
let k = 8;
console.log(topK(karr, k));