常见问题
1.重复消费
- 产生的原因是发送消息时采用了多数分布式消息中间件产品提供的最少一次(at least once)的投递保障,对于这个问题最常见的解决方案,就是消息消费端实现业务幂等,只要保持幂等性,不管来多少条重复消息,最后处理的结果都是一样的
- 保障策略有at most once 最多消费一次, at least once 最少消费一次, exactly once 刚好一次,RocketMQ不支持exactly once只有一次的模式,因为要在分布式系统下实现发送不重复并且消费不重复,将会产生非常大的开销,RocketMQ为了追求高性能并没有支持此特性
其实该问题的本质时网络调用存在不确定性,即既不成功也不失败的第三种状态,所以才会产生消息重复的问题
2.为什么RocketMQ不用ZooKeeper而要自己实现一个NameServer来注册?
为什么要RocketMQ自己实现注册中心,而不是用Zookeeper,Nacos?
3.Consumer分组有什么用? Producer分组的作用?
- Producer Group
- 生产者组(ProducerGroup)是一类生产者地集合,这类生产者通常发送一类消息并且发送逻辑一致,所以将这些生产者分组在一起,从部署结构上看,生产者通过生产者组的名字来标识自己是一个集群
- 事务消息回查机制,可以使用到,同一个生产者组的生产消息逻辑是相同的,所以当事务消息向Broker提交本地事务不成功时,有可能是在执行完本地事务之后宕机的,那么Broker只需要向同一个Producer Group中的任意一个Producer调用事务回查就可以获取到本地事务的执行结果
- Consumer Group
- 消费者组(ConsumerGroup)是一类消费者的组合,这类消费者通常消费同一类消息并且消费逻辑一致,所以将这些消费者分组在一起,消费者组于生产者组类似,都是将相同角色的消费者分组在一起并命名的。分组是一个很精妙的概念设计,RocketMQ正是通过这种分组机制,实现了天然的消息负载均衡。
消费消息时,通过消费者组实现了将消息分发到多个消费者服务器实例,比如某个主题由9条消息,其中,一个消费者组由3个实例(3个进程或者3台机器),那么每个实例将均摊3条消息,也就意味着我们可以很方便地通过增加机器来实现水平扩容
4.哪些环节会有丢消息的可能
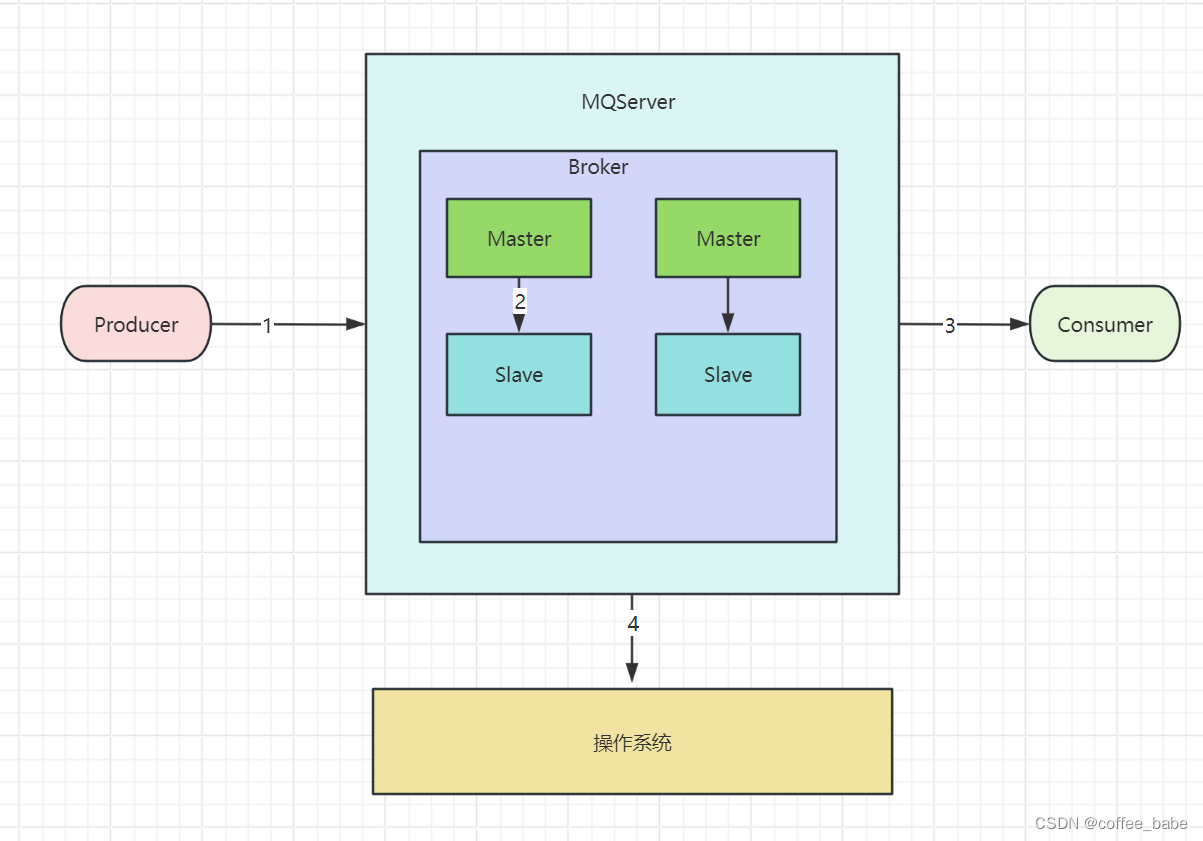
这4个环节都有丢消息的可能
5.RocketMQ消息零丢失方案
1.生产者使用事务消息机制保证消息零丢失
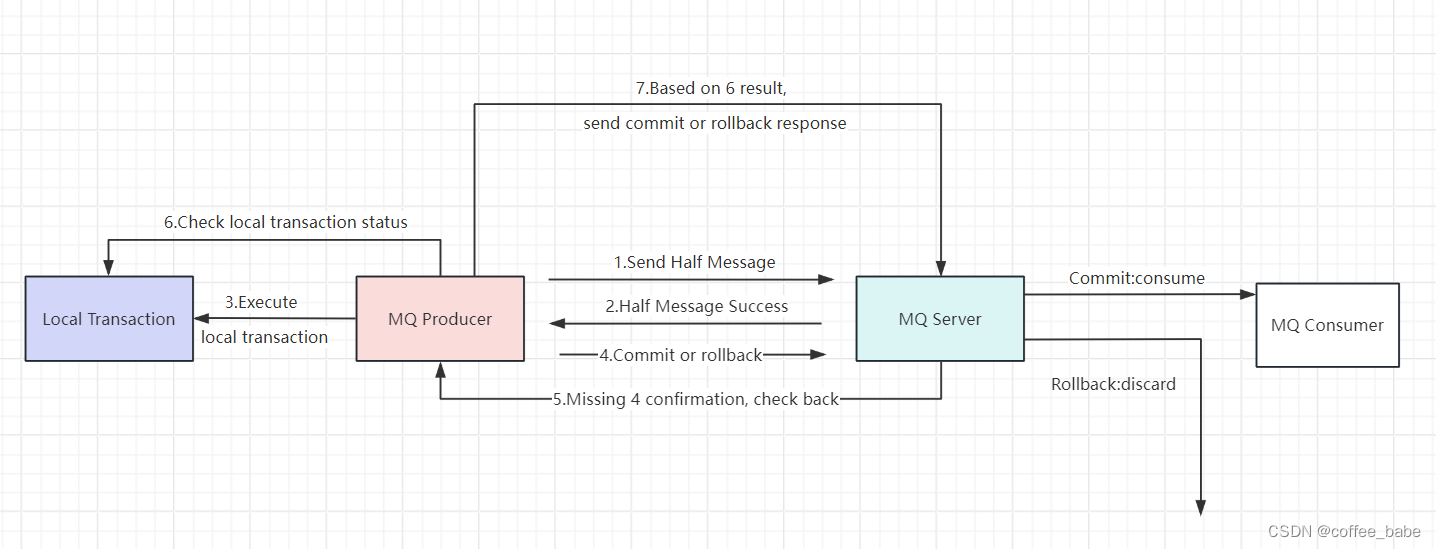
1.1.1.为什么要发送这个half消息?有什么用
这个Half消息时在订单系统进行下单操作前发送,并且对下游服务的消费者是不可见的。
那这个消息的作用更多的体现在确认RocketMQ的服务是否正常。相当于嗅探下RocketMQ
服务是否正常,并且通知RocketMQ,我马上就要发一个很重要的消息了,你做好准备
1.1.2.half消息如果写入失败了怎么办?
如果没有half消息这个流程,那我们通常是会在订单系统中先完成下单,再发送消息给MQ.
这时候写入消息到MQ如果失败就会非常尴尬了,而Half消息如果写入失败,我们就可以认为MQ的服务,是有问题的,这时就不能通知下游服务了,我们可以在下单时给订单一个状态标记,然后等待MQ服务,正常后再进行补偿操作,等MQ服务正常后重新下单通知下游服务
1.1.3.订单系统写数据库失败了怎么办?
这个问题我们同样比较下没有使用事务消息机制时会怎么办?如果没有使用事务消息,我们只能判断
下单失败,抛出了异常,那就不往MQ发消息了,这样至少保证不会对下游服务进行错误的通知。但是这样的话,如果过一段时间数据库恢复过来了,这个消息就无法再次发送了,当然也可以设计另外的补偿机制,例如将订单数据缓存起来,再启动一个线程定时尝试往数据库写。如果使用事务机制,就可以有一种更优雅的方案,如果下单时,写数据库失败了(可能是数据库崩了,需要等待
一段时间才能恢复),那我们可以另外找个地方把订单消息先缓存起来(Redis、文本或者其他方式),
然后给RocketMQ返回一个UNKNOWN状态,这样RocketMQ就会过一段时间来回查事务状态,我们就可以在回查事务状态时再尝试把订单数据写入数据库,如果数据库这时候已经恢复了,那就能完成正常的下单,再继续后面的业务。这样这个订单的消息就不会因为数据库临时崩了而丢失
1.1.4.Half消息写入成功后RocketMQ挂了怎么办?
在事务消息的处理机制中,未知状态的事务状态回查是由RocketMQ的Broker主动发起的,也就是如果出现了这种情况,那RocketMQ就不会回调到事务消息中回查事务状态的服务,这时,我们就可以将订单一直标记为"新下单"的状态。而等RocketMQ恢复后,只要存储的消息
没有丢失,RocketMQ就会再次继续状态回查的流程
1.1.5.下单成功后如何优雅地等待支付成功?
-
数据库方案.
在订单场景下,通常会要求下单完成后,客户在一定时间内,例如10分钟内完成订单支付,支付完成
后才会通知下游服务进行进一步地营销补偿?
如果不适用事务消息,那通常会怎么办?
最简单地方式是启动一个定时任务,每隔一段时间扫描订单表,比对未支付的订单的下单时间,将超时的
订单进行回收,这种方式显然有很大问题的,需要定时扫描很庞大的一个订单信息,这对系统是个不小
的压力。 -
延迟消息方案.
更进一步的方案是什么呢?是不是就可以使用RocketMQ提供的延迟消息机制,往MQ发一个延迟一分钟的
消息,消费到这个消息后去检查订单的支付状态,如果订单已经支付,就往下游发送下单的通知,而如果
没有支付,就再发一个延迟1分钟的消息,最终在第是个消息时把订单回收,这个方案就不用对全部的订单
表进行扫描,而只需要每次处理一个单独的订单消息 -
事务消息方案.
利用事务消息的状态回查机制来替代定时的任务。在下单时,给Broker返回一个UNKNOWN的位置状态。
而在状态回查的方法中去查询订单的支付状态。这样整个业务逻辑就会简单很多。只需要配置RocketMQ的
事务消息回查次数(默认15此)和事务回查间隔时间(messageDelayLevel)就可以更优雅的完成这个支付状态
检查的需求
1.1.6.事务消息机制的作用
整体来说,在订单这个场景下,消息不丢失的问题实际上就还是转化成了下单这个业务与下游服务
的业务的分布式事务一致性问题,而事务一致性问题一直依赖都是一个非常复杂的问题。而RocketMQ
的事务消息机制,实际上只保证了整个事务消息的一半,他保证的是订单系统下单和发消息这两个事件
的事务一致性,而对下游服务的事务并没有保证,但是即便如此,也是分布式事务的一个很好的降级方案,
目前来看,也是业内最好的降级方案
2.RocketMQ配置同步刷盘+(Dledger)Broker主从架构保证MQ主从同步时不会丢消息
2.1.1.同步刷盘
可以简单的把RocketMQ的刷盘方式flushDiskType配置成同步刷盘就可以保证消息在刷盘过程中不会丢失了
2.1.2.Dledger的文件同步
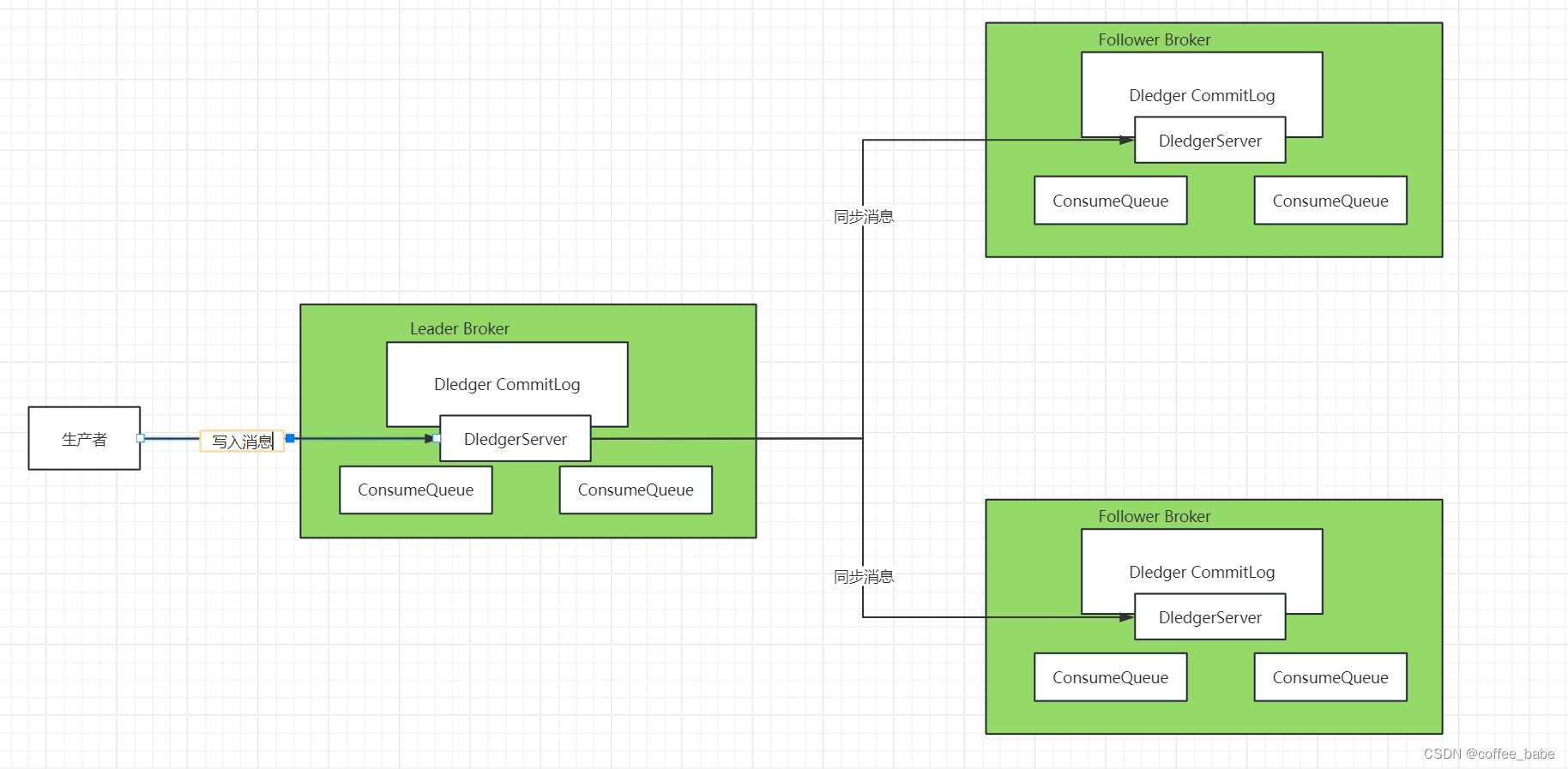
- 在使用Dledger技术搭建的RocketMQ集群中,Dledger会通过两阶段提交的方式抱着呢个文件在主从之间成功同步
- 简单来说,数据同步会通过两个阶段,一个是uncommited阶段,一个是commiitted阶段Leader Broker上的Dledger收到一条消息后,会标记为uncommitted状态,然后他通过自己的DledgerServer组件把这个uncommitted数据发送给Follower Broker的DledgerServer组件。接着Follower Broker的DledgerServer收到uncommitted消息之后,必须返回一个ack给Leader Broker的Dledger,如果Leader Broker收到超过半数的Follower Broker返回的ack之后,
就会把消息标记为committed状态,再接下来,Leader Broker上的DledgerServer就会发送committed消息给Follower Broker上的DledgerServer,让它们把消息也标记为committed状态,这样,就基于Raft协议完成了两阶段的数据同步
2.1.3.消费者端不要使用异步消费机制
- 正常情况下,消费者端都是需要先处理本地事务,然后再给MQ一个ACK相应,这时MQ
就会修改Offset,将消息标记为已消费,从而不再往其他消费者推送消息。所以在Broker的
这种情况会造成服务端消息丢失,这种异步消费的方式,就有可能造成消息状态返回后消费者
本地业务逻辑处理失败造成消息丢失的可能
2.1.4.RocketMQ特有的问题,NameServer挂了如何保证消息不丢失
- NameServer在RocketMQ中,扮演一个路由中心的角色,提供到Broker的路由功能。
但是其实这样的路由中心这样的功能,在所有的MQ中都是需要的,Kafka使用ZooKeeper
和一个作为Controller的Broker一起来提供路由服务的,整个功能是相当复杂纠结的。而
RabbitMQ是由每一个Broker来提供路由服务,只有RocketMQ把这个路由中心单独抽取了
出来,并独立部署,每一个NameServer都是独立的,集群中任意多的节点挂掉,都不会影响
它提供的路由功能,如果集群中所有的NameServer节点都挂了呢? - 有很多人就会认为生产者和消费者中都会有全部路由信息的缓存副本,那整个服务可以正常工作
一段时间,当NameServer全部挂了后,胜场这和消费者是立即就无法工作了的 - 回到消息不丢失的问题。在这种情况下,RocketMQ相当于整个服务都不可用了,那它本身肯定无法给我们
保证消息不丢失了。我们只能自己设计一个降级方案来处理这个问题了。例如再订单系统中,如果多次尝试
发送RocketMQ不成功,那就只能另找地方(Redis、文件或者内存等)把订单消息缓存下来,然后起一个线程
定时地扫描这些失败地订单消息,尝试往RocketMQ发送,这样等RocketMQ的服务恢复过来后,就能第一
时间把这些消息重新发送出去。整个这套降级的机制,在大型互联网项目中,都是必须要有的
2.1.5.RocketMQ消息零丢失方案总结
- 1.生产者使用事务消息机制
- 2.Broker配置同步刷盘+Dledger主从架构
- 3.消费者不要使用异步消费
- 4.整个MQ挂了之后准备降级方案
- 这套方案在各个环节都大量地降低了系统地处理性能以及吞吐量。在很多场景下,这套方案带来的性能损失
的代价可能远大于部分消息丢失的代价。所以在使用这套方案时,要根据实际的业务情况来考虑,
例如,如果针对所有服务器都在同一个机房的场景,完全可以把Broker配置成异步刷盘来提升吞吐量。
而在有些对消息可靠性要求没有那么高的场景,在生产者端就可以采用其他一些更简单的方案来提升吞吐,
而采用定时对账、补偿的机制来提高消息的可靠性。而如果消费者不需要进行消息存盘,
那使用异步消费的机制带来的性能提升也是非常显著的。
3.使用RocketMQ如何保证消息顺序
3.1.为什么要保证消息有序?
比如,下单完之后,需要支付成功,才会进行物流快递,不能先让物流服务执行,再支付成功
3.2.如何保证消息有序?
- 全局有序。整个MQ系统的所有消息岩哥按照队列先入先出顺序进行消费
- 局部有序。只保证一部分关键消息的消费顺序
- 首先我们需要分析下这个问题,在通常的业务场景中,全局有序和局部有序哪个更重要?其实在大部分的MQ业务场景,我们只需要保证局部有序就可以了,对于电商订单场景,只要保证一个订单的所有消息是有序的就可以了,全局消息的顺序并不会太关心
- 落地到RocketMQ。通常情况下,发送者发送消息时,会通过MessageQueue轮询的方式
保证消息尽量均匀地分布到所有的MessageQueue上,而消费者也就同样需要从多个MessageQueue
上消费消息。而MessageQueue是RocketMQ存储消息的最小单元,它们之间的消息都是互相隔离的,
在这种情况下,是无法保证消息全局有序的,而对于局部有序的要求,只需要将有序的一组消息都存入
同一个MessageQueue里,这样MessageQueue的FIFO设计天生就可以保证这一组消息的有序。
RocketMQ中,剋在发送者发送消息时指定一个MessageSelector对象,让这个对象来决定消息发到
哪一个MessageQueue。这样就可以保证一组有序的消息能够发到同一个MessageQueue里。 - 另外,通常所谓的保证Topic全局消息有序的方式,就是将Topic配置成只有一个MessageQueue队列(默认是4个)。这样天生就能保证消息全局有序,这种方式对整个Topic的消息吞吐影响是非常大的,如果这样用,基本上就没有用MQ的必要了
4.使用RocketMQ如何快速处理积压消息
4.1.1.如何确定RocketMQ有大量的消息积压?
-
在正常情况下,使用MQ都会要尽量保证它的消息生产速度和消费速度整体上是平衡的,但是如果部分消费者系统出现故障,就会造成大量的消息积累。这类问题通常在实际工作中会出现得比较隐蔽。例如某一天一个数据库突然挂了,大家大概率就会集中处理数据库得问题,等好不容易把数据库恢复过来了,这时基于这个数据库服务得消费者程序就会积累大量的消息。或者网络波动等情况,也会导致消息大量的积累。这在一些大型的互联网项目中,消息积压的速度是相当恐怖的,所以消息积压是个需要时时关注的问题
-
对于消息积压,如果是RocketMQ或者Kafka还好,它们的消息积压不会对性能造成
很大的影响,而如果是RabbitMQ的话,那就不太好了,大量的消息积压可以瞬间造成
性能直线下滑。对于RocketMQ来说,有个最简单的方式来确定消息是否有积压。那就是使用web控制台,就能直接看到消息的积压情况,另外也可以通过mqadmin指令在后台检查各个Topic的消息延迟情况,还可以在它的${sotrePathRootDir}/config目录下落地一系列
的json文件,也可以用来跟踪消息积压情况
4.1.2.如何处理大量积压的消息
- 如果Topic下的MessageQueue配置得是足够多的,那每个Consumer实际上会分配
多个MessageQueue来进行消费。这个时候,就可以简单地通过增加Consumer的服务节点数量来加快消息的消费,等积压消息消费完了,再恢复成正常情况。最极限的情况是把Consumer的节点个数设置成MessageQueue的个数相同。但是如果此时再继续增加Consumer的服务节点就没有用了 - 如果Topic下的MessageQueue配置不够多的话,那就不能用上面这种增加Consumer节点个数的方法了
这时如果要快速处理积压的消息,可以创建一个新的Topic,配置足够的多MessageQueue.然后把所有
消费者节点的目标Topic转向新的Topic,并紧急上线一组新的消费者,只负责消费旧Topic中的消息,
并转储到新的Topic中,这个速度是可以很快的,然后在新的Topic上,就可以通过增加消费者个数来提高
消费速度了.之后再根据情况恢复成正常的情况
5.RocketMQ的消息轨迹
RocketMQ默认提供了消息轨迹的功能,这个功能在排查问题时是非常有用的
5.1.RocketMQ消息轨迹数据的关键属性
5.1.1 Producer
- 生产实例信息
- 发送消息时间
- 消息是否发送成功
- 发送耗时
5.1.2 Consumer
- 消费实例信息
- 投递时间,投递轮次
- 消息是否消费成功
- 消费耗时
5.1.3 Broker
- 消息的Topic
- 消息存储位置
- 消息的Key值
- 消息的Tag值
5.2.消息轨迹配置
broker.conf打开一个关键配置
traceTopicEnable=true,默认是false,关闭的
5.3 消息轨迹数据存储
默认情况下,消息轨迹数据是存于一个系统级别的Topic
RMQ_SYS_TRACE_TOPIC,这个Topic在Broker节点启动时
会自动创建出来,当然也可以自定义