文章目录
- 模型及预训练方式
- 模型结构
- 训练语料
- 预训练方式
- 下游任务实验结果
- 实验一:金融短讯类型分类
- 实验任务
- 数据集
- 实验结果
- 实验二:金融短讯行业分类
- 实验任务
- 数据集
- 实验结果
- 实验三:金融情绪分类
- 实验任务
- 数据集
- 实验结果
- 实验四:金融领域的命名实体识别
- 实验任务
- 数据集
- 结果展示
- 总结
FinBERT是熵简科技 AI Lab 开源的基于 BERT 架构的金融领域预训练语言模型,相比于Google发布的原生中文BERT、哈工大讯飞实验室开源的BERT-wwm 以及 RoBERTa-wwm-ext该模型在多个金融领域的下游任务中获得了显著的性能提升,在不加任何额外调整的情况下,F1-score 直接提升至少 2~5.7 个百分点。
论文地址:FinBERT: A Pre-trained Financial Language Representation Model for Financial Text Mining
github地址:https://github.com/valuesimplex/FinBERT
FinBERT-Base模型下载地址:FinBERT_L-12_H-768_A-12_pytorch.zip
论文的主要贡献:
一,FinBERT (BERT for Financial Text Mining)是第一个通过在金融语料上使用多任务学习得到的特定领域的BERT,其可以把金融领域语料上的知识传递到下游金融文本相关的应用任务上;
二,FinBERT和标准BERT采用不同的训练目标函数。本文设计或采用了6中自监督预训练任务,可以通过多任务自监督学习方法来训练,从而更有效地捕捉大规模预训练语料中的语言知识和语义信息;
三,在几个金融领域的基准集上执行了若干实验。实验结果展示,FinBERT可以显著超越sota的效果:金融句子边界检测;金融情感分析;以及金融问答;
四,使用Horovod框架实现了FinBERT,以及使用了混合精度。(目前还没有)公开代码或者预训练的模型。FinBERT可以被用于其他很多下游的金融文本挖掘任务,提升整体性能。
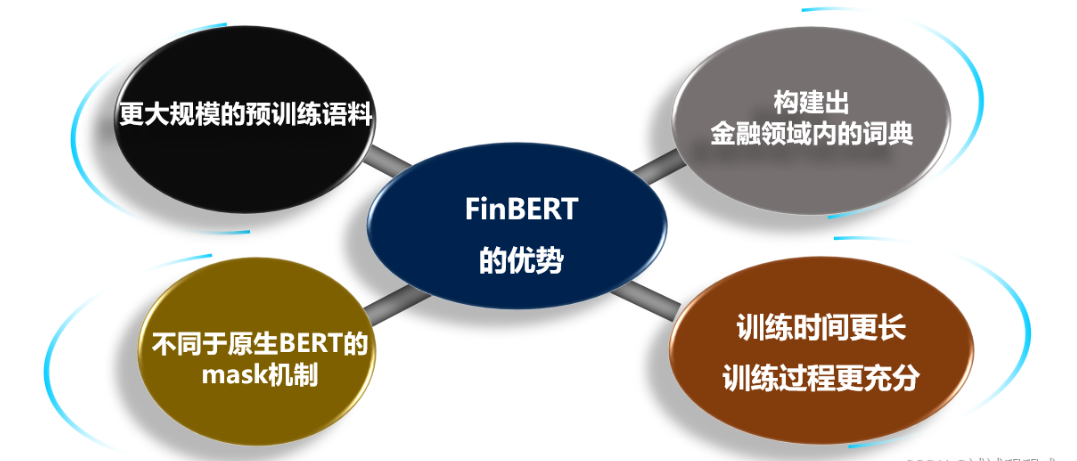
FinBERT的优势
模型及预训练方式
模型结构
熵简 FinBERT 在网络结构上采用与 Google 发布的原生BERT 相同的架构,包含了 FinBERT-Base 和 FinBERT-Large 两个版本,其中前者采用了 12 层 Transformer 结构,后者采用了 24 层 Transformer 结构。考虑到在实际使用中的便利性和普遍性,本次发布的模型是 FinBERT-Base 版本。
训练语料
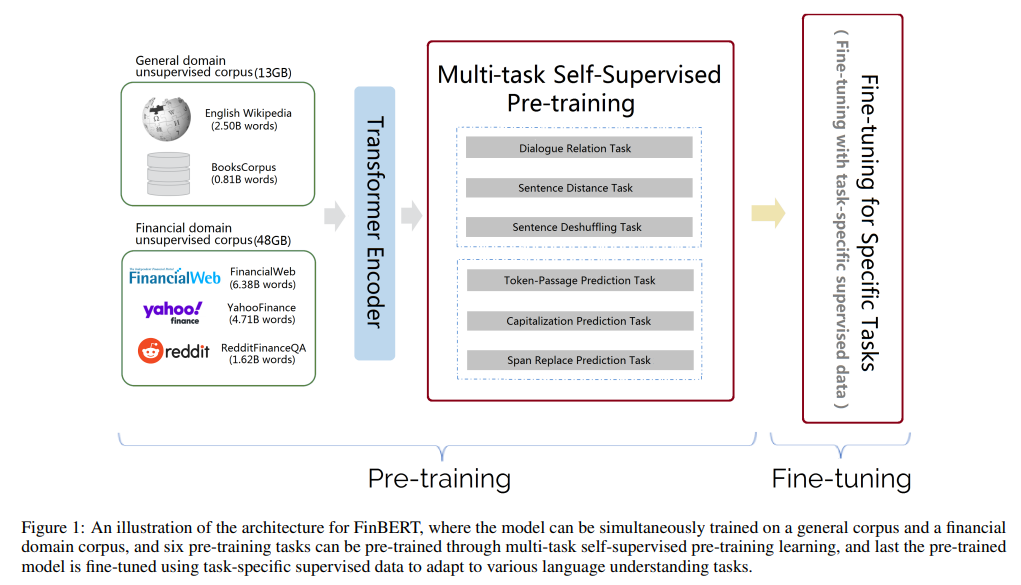
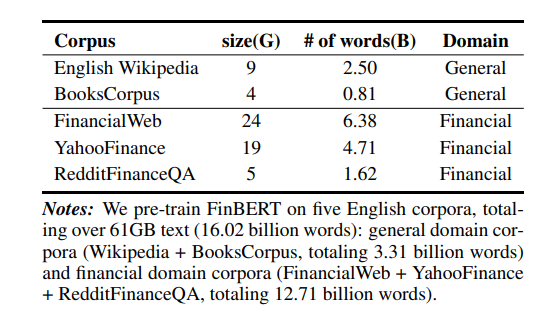
FinBERT 1.0 所采用的预训练语料主要包含三大类金融领域的语料,分别如下:
- 金融财经类新闻: 从公开渠道采集的最近十年的金融财经类新闻资讯,约 100 万篇;
- 研报/上市公司公告: 从公开渠道收集的各类研报和公司公告,来自 500 多家境内外研究机构,涉及 9000 家上市公司,包含 150 多种不同类型的研报,共约 200 万篇;
- 金融类百科词条: 从 Wiki 等渠道收集的金融类中文百科词条,约 100 万条。
对于上述三类语料,在金融业务专家的指导下,我们对于各类语料的重要部分进行筛选、预处理之后得到最终用于模型训练的语料,共包含 30亿 Tokens,这一数量超过了原生中文BERT的训练规模。
预训练方式
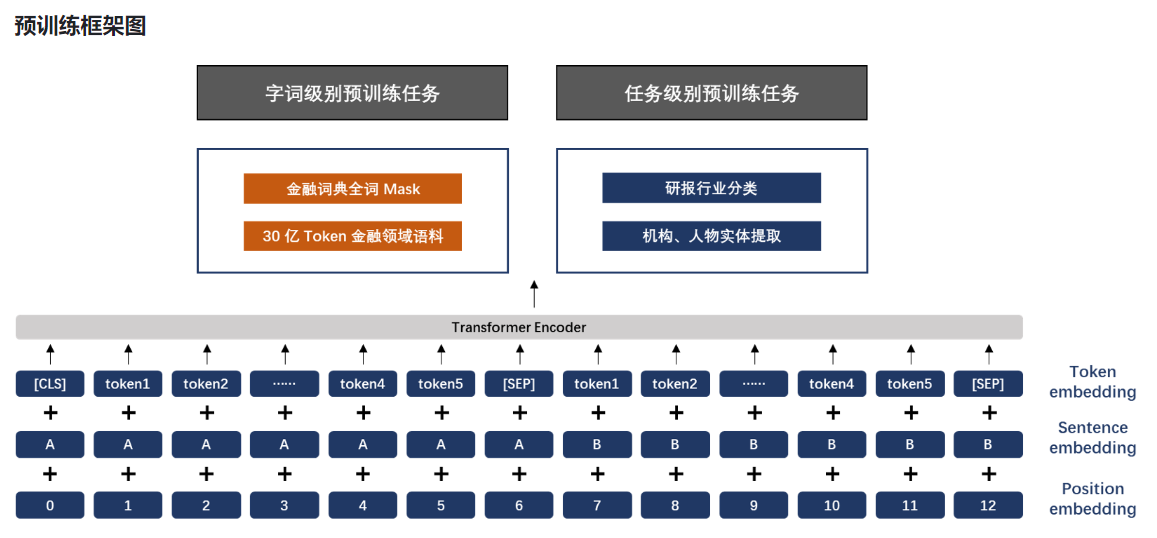
如上图所示,FinBERT 采用了两大类预训练任务,分别是字词级别的预训练和任务级别的预训练。两类预训练任务的细节详述如下:
(1)字词级别的预训练
字词级别的预训练首先包含两类子任务,分别是 Finnacial Whole Word MASK(FWWM)、Next Sentence Prediction(NSP)。同时,在训练中,为了节省资源,我们采用了与 Google 类似的两阶段预训练方式,第一阶段预训练最大句子长度为128,第二阶段预训练最大句子长度为 512。两类任务具体形式如下:
Finnacial Whole Word MASK(FWWM)
Whole Word Masking (wwm),一般翻译为全词 Mask 或整词 Mask,出是 Google 在2019年5月发布的一项升级版的BERT中,主要更改了原预训练阶段的训练样本生成策略。简单来说,原有基于WordPiece的分词方式会把一个完整的词切分成若干个子词,在生成训练样本时,这些被分开的子词会随机被mask。 在全词Mask中,如果一个完整的词的部分WordPiece子词被 Mask,则同属该词的其他部分也会被 Mask,即全词Mask。
谷歌原生的中文 BERT :输入是以字为粒度进行切分,没有考虑到领域内共现单词或词组之间的关系,从而无法学习到领域内隐含的先验知识,降低了模型的学习效果。
例如单词:“投资”,字由“投”“资”构成,按照全词Mask的方式,不会仅掩盖“投‘或”资“,会掩盖整个单词“投资”。考虑中文的字和词之间关系,相比于恢复单个字,恢复整个单词对模型更具有挑战性。
在谷歌原生的中文 BERT 中,输入是以字为粒度进行切分,没有考虑到领域内共现单词或词组之间的关系,从而无法学习到领域内隐含的先验知识,降低了模型的学习效果。我们将全词Mask的方法应用在金融领域语料预训练中,即对组成的同一个词的汉字全部进行Mask。首先我们从金融词典、金融类学术文章中,通过自动挖掘结合人工核验的方式,构建出金融领域内的词典,约有10万词。然后抽取预语料和金融词典中共现的单词或词组进行全词 Mask预训练,从而使模型学习到领域内的先验知识,如金融学概念、金融概念之间的相关性等,从而增强模型的学习效果。
Next Sentence Prediction(NSP)
为了训练一个理解句子间关系的模型,引入一个下一句预测任务。具体方式可参考BERT原始文献,Google的论文结果表明,这个简单的任务对问答和自然语言推理任务十分有益,我们在预训练过程中也发现去掉NSP任务之后对模型效果略有降低,因此我们保留了NSP的预训练任务,学习率采用Google 官方推荐的2e-5,warmup-steps为 10000 steps。
(2)任务级别的预训练
为了让模型更好地学习到语义层的金融领域知识,更全面地学习到金融领域词句的特征分布,我们同时引入了两类有监督学习任务,分别是研报行业分类和财经新闻的金融实体识别任务,具体如下:
研报行业分类
对于公司点评、行业点评类的研报,天然具有很好的行业属性,因此我们利用这类研报自动生成了大量带有行业标签的语料。并据此构建了行业分类的文档级有监督任务,各行业类别语料在 5k~20k 之间,共计约40万条文档级语料。
财经新闻的金融实体识别
与研报行业分类任务类似,我们利用已有的企业工商信息库以及公开可查的上市公司董监高信息,基于金融财经新闻构建了命名实体识别类的任务语料,共包含有 50 万条的有监督语料。
整体而言,为使 FinBERT 1.0 模型可以更充分学习到金融领域内的语义知识,我们在原生 BERT 模型预训练基础上做了如下改进:
- 训练时间更长,训练过程更充分。 为了取得更好的模型学习效果,我们延长模型第二阶段预训练时间至与第一阶段的tokens总量一致;
- 融合金融领域内知识。引入词组和语义级别任务,并提取领域内的专有名词或词组,采用全词 Mask的掩盖方式以及两类有监督任务进行预训练;
- 为了更充分的利用预训练语料,采用类似Roberta模型的动态掩盖mask机制,将dupe-factor参数设置为10。
dupe-factor参数:训练过程中会对文档多次重复随机产生训练集,这个参数是指重复的次数。
6种自监督预训练任务:
| 预训练任务名称 | Encoder输入 | 预测输出 | 类型 |
|---|---|---|---|
| 1. 范围替换 | 一个句子,局部phrase/n-gram被遮掩 | 预测被遮掩的n-gram | word-aware/phrase-ware |
| 2. 大写单词预测 | 一个句子,全小写 | 预测哪些词是大写的,二分类 | word-aware |
| 3.单词-段落预测 | 一个单词,一个段落片段/segment | 单词是否出现在该段落中,二分类 | word-aware |
| 4. 句子位置复原 | 若干乱序后的句子 | 他们的原始的序号 | structure-aware |
| 5. 句子距离 | 两个句子 | 三分类,00, 01, 11 | structure-aware |
| 6. 对话关系 | 多轮对话Query-Response,其中若干词被遮掩 | 被遮掩的词的预测 | semantic-aware (QA) |
1、span replace prediction pre-training task - 范围替换预测(预训练任务)
思想来自于spanBERT和T5,随机把输入的文本中的15%给扔掉,然后使用一个[mask]来替换掉一个连续的phrase。这点和原本的bert中,每个词都被替换成一个[mask]不同。
2、capitalization prediction pre-training task 大写单词预测(预训练任务)
一个单词是否是大小写,具有一定的意义,特别是大写word,或者连续多个大写的phrase,在句子中往往有重要的语义含义。
3、token-passage prediction pre-training task 单词-段落预测(预训练任务)
识别片段中出现的关键词是否也在原始段落的其他片段中。
4、sentence deshuffling pre-training task 句子位置复原(预训练任务)
这个来自ERNIE2和T5。
一个段落里面有n个片段segments,随机打乱其顺序,一共有n!种排列。任务就是从被打乱顺序的序列中,恢复原来的正确顺序的序列。
5、sentence distance pre-training task 句子距离(预训练任务)
两个句子的“距离”的多分类任务:
三类,00, 01, 11,其中00表示的是两个句子在同一个段落中而且相邻;01表示两个句子在一个段落中,但是不相邻;11表示他们不在一个段落中。
这个也和ERNIE2.0中的有一定的相近性。ERNIE2.0中,也有sentence distance task,而且也是3类的:0表示两个句子在文档中是相邻的;1表示他们在一个文档中,但是不相邻;2表示他们来自两个不同的文档。
6、dialogue relation pre-training task 对话关系(预训练任务)
对一些单轮或多轮对话数据 mask 掉输入的一些 token, 然后让模型去预测这些被 mask 掉的 token。
下游任务实验结果
为了对比基线效果,从熵简科技实际业务中抽象出了四类典型的金融领域典型数据集,包括句子级和篇章级任务。在此基础上,将 FinBERT 与 Google 原生中文 BERT、哈工大讯飞实验室开源的 BERT-wwm 和 RoBERTa-wwm-ext 这三类在中文领域应用广泛的模型进行了下游任务的对比测试。在实验中,为了保持测试的公平性,没有进一步优化最佳学习率,对于四个模型均直接使用了 BERT-wwm 的最佳学习率:2e-5。
所有实验结果均为五次实验测试结果的平均值,括号内为五次测试结果的最大值,评价指标为 F1-score。
实验一:金融短讯类型分类
实验任务
此任务来自于熵简科技信息流相关的产品,其核心任务是对金融类短文本按照文本内容进行类型分类,打上标签,从而方便用户更及时、更精准地触达感兴趣的内容。
我们对原任务进行了简化,从原始的 15个类别中抽离出难度最大的 6个类别进行实验。
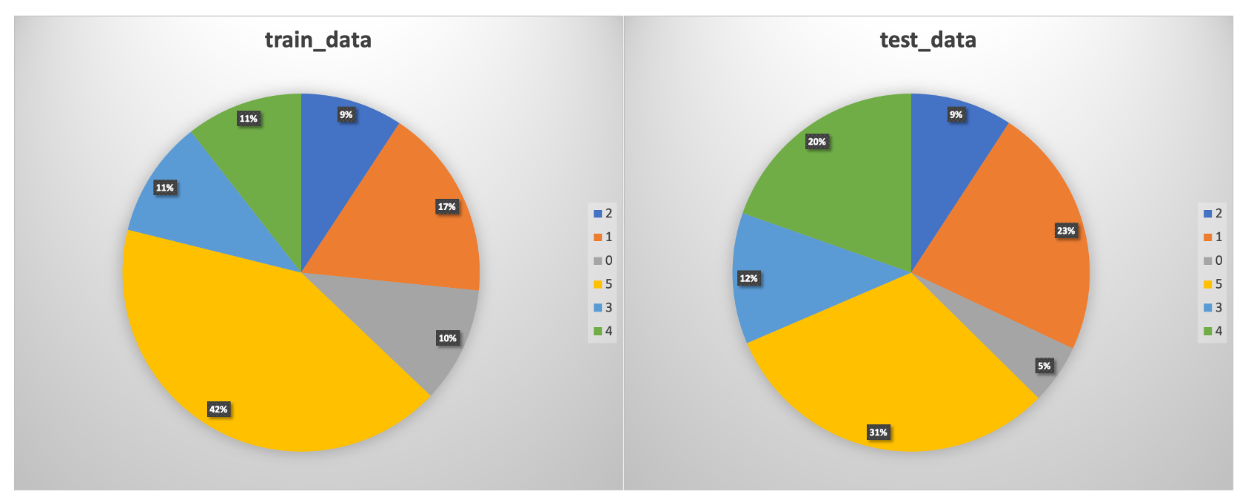
数据集
该任务的数据集共包含 3000 条样本,其中训练集数据约 1100 条,测试集数据约 1900条,各类别分布情况如下:
实验结果
| TASK\MODEL | BERT | BERT-wwm | RoBERTa-wwm-ext | FinBERT |
|---|---|---|---|---|
| 金融短讯类型分类 | 0.867(0.874) | 0.867(0.877) | 0.877(0.885) | 0.895(0.897) |
实验二:金融短讯行业分类
实验任务
此任务核心任务是对金融类短文本按照文本内容进行行业分类,以中信一级行业分类作为分类基准,包括餐饮旅游、商贸零售、纺织服装、农林牧渔、建筑、石油石化、通信、计算机等 29 个行业类别,可以用在金融舆情监控、研报/公告智能搜索等多个下游应用中。
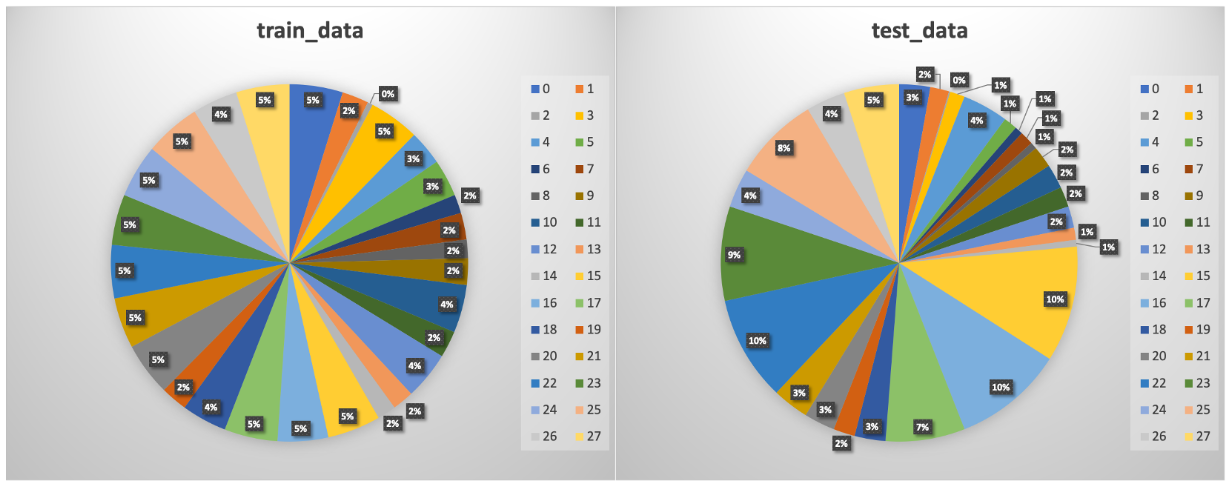
数据集
该任务的数据集共包含 1200 条样本,其中训练集数据约 400 条,测试集数据约 800条。训练集中的各类别数目在 5~15 条之间,属于典型的小样本任务。 各类别分布情况如下:
实验结果
| TASK\MODEL | BERT | BERT-wwm | RoBERTa-wwm-ext | FinBERT |
|---|---|---|---|---|
| 金融短讯行业分类 | 0.939(0.942) | 0.932(0.942) | 0.938(0.942) | 0.951(0.952) |
实验三:金融情绪分类
实验任务
此任务来自于熵简科技金融质控类相关产品,其核心任务是针对金融事件或标的的评述性文本按照文本内容进行金融情感分类,并用在后续的市场情绪观察和个股相关性分析中。
该任务共有 4个类别,对应不同的情绪极性和强度。
数据集
该任务的数据集共包含 2000 条样本,其中训练集数据约 1300 条,测试集数据约 700条,各类别分布情况如下:
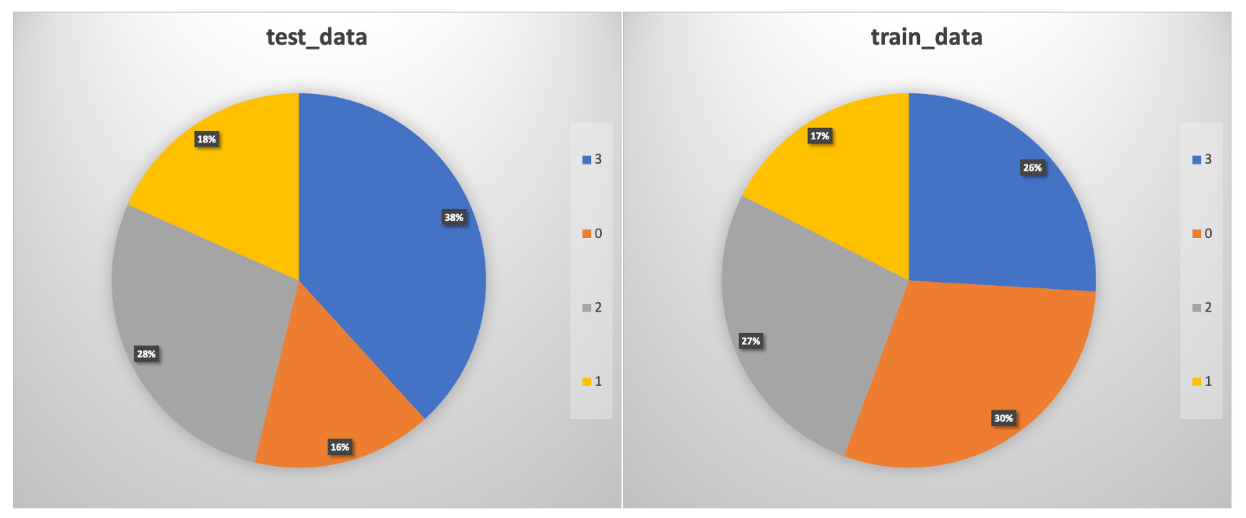
实验结果
| TASK\MODEL | BERT | BERT-wwm | RoBERTa-wwm-ext | FinBERT |
|---|---|---|---|---|
| 金融情绪分类 | 0.862(0.866) | 0.850(0.860) | 0.867(0.867) | 0.895(0.896) |
实验四:金融领域的命名实体识别
实验任务
此任务来自于熵简科技知识图谱相关的产品,其核心任务是对金融类文本中出现的实体(公司或人名)进行实体识别和提取,主要用在知识图谱的实体提取和实体链接环节。
数据集
数据集共包含 24000 条样本,其中训练集数据共3000条,测试集数据共21000条。
结果展示
| TASK\MODEL | BERT | BERT-wwm | RoBERTa-wwm-ext | FinBERT |
|---|---|---|---|---|
| 公司名称实体识别 | 0.865 | 0.879 | 0.894 | 0.922 |
| 人物名称实体识别 | 0.887 | 0.887 | 0.891 | 0.917 |
总结
在本次基线测试中,我们以金融场景中所遇到四类实际业务问题和数据入手进行对比实验,包括金融类短讯类型分类任务、金融文本行业分类、金融情绪分析任务以及金融类实体识别任务。对比 FinBERT 和 Google 原生中文BERT、 BERT-wwm、RoBERTa-wwm-ext 这三种通用领域的预训练模型
可知,FinBERT 效果提升显著,在 F1-score 上平均可以提升 2~5.7 个百分点。