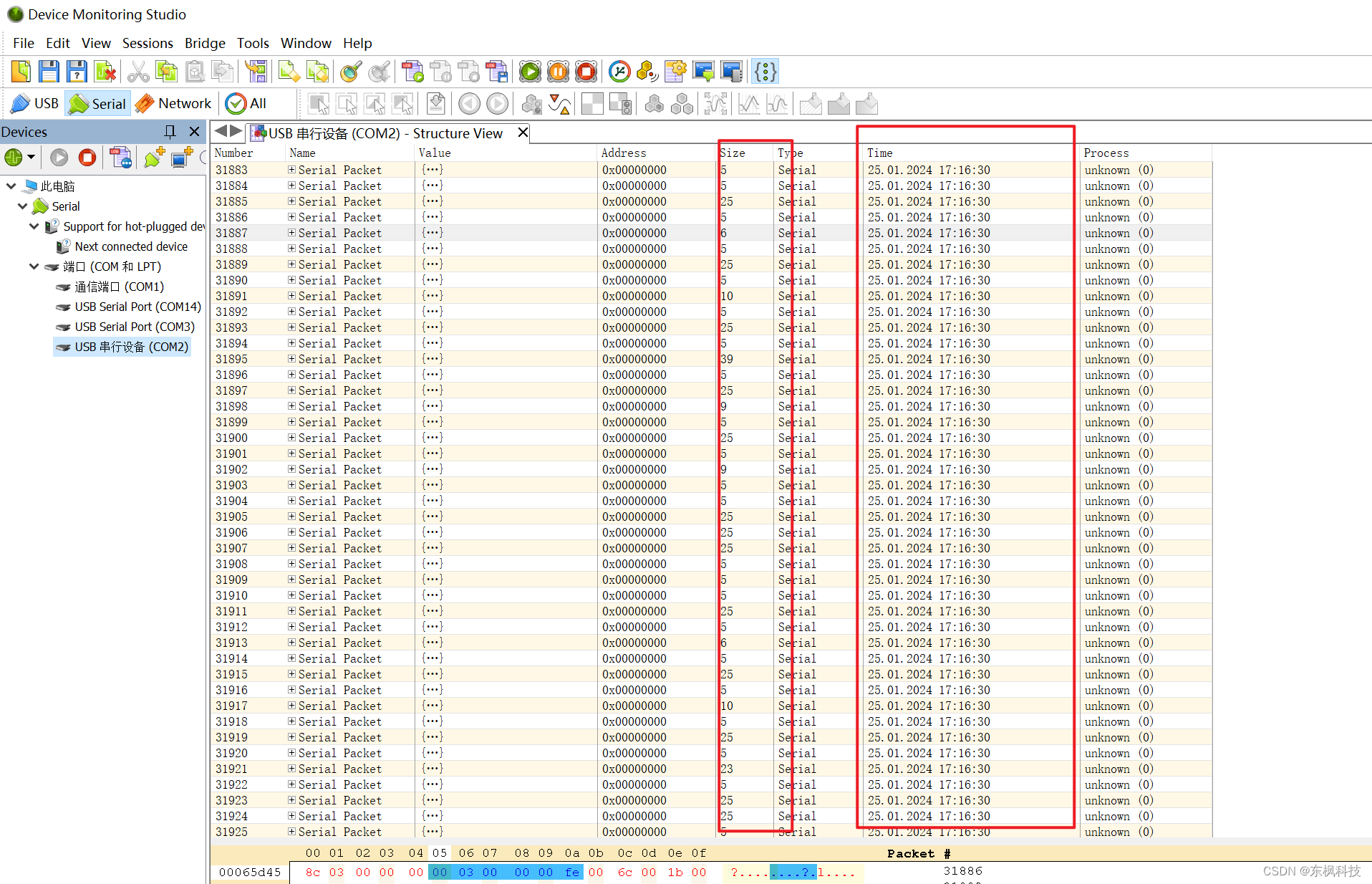
目录
思想
代码如下
一些解释
1.基数P的选择
2.unsigned long long类型
可能需要看的文章博客

思想
咳咳,感觉这个刚开始第一遍接触的时候很抽象,,,还好网友们很强,有很通俗的解释办法hh。
字符串的哈希核心思想是:我们把字符串当做一个P进制的数,有点像通过前缀和的思想得到两段字符串的哈希值,在判断两段字符串所映射的哈希值是否相同即可。
ha数组的每一位存的都是字符串的前 i 位映射之后的哈希值(这个哈希值的计算方式就是以P进制计算所得的数)。这里的P一般取131,13331 ,可以尽量避免冲突。(这个结论是在大量实践中得出的,我们平时使用直接记住就好。)
由于在进制数的运算中,通常需要求取次方,因此我们建立一个p数组,提前预处理出以P为基数的次方。方便后续的使用。
其实我们这里ha数组其实并不是哈希表,因为其元素表示的是哈希值,其下标表示的其实可以当作是字符串(因为下标是几表示的就是前缀到第几个字符的字符串)
也就是相比普通的哈希表:下标表示哈希值,元素表示数据(回想一下840的散列表),也就是反过来了。
也就是说字符串哈希其实是运用到了哈希表的思想,其实实际的实现过程并不一定需要使用哈希表。
哈希函数会将字符串映射到一个数字,这个过程并不需要哈希表。然而,如果想要存储和查找字符串,哈希表就可能会被用到,因为哈希表可以提供快速的查找速度。
下面这张图也对解决字符串哈希的方式与我们所熟悉的十进制放在一起进行对照,相信可以理解哈。(这个英文字体好漂亮hh)
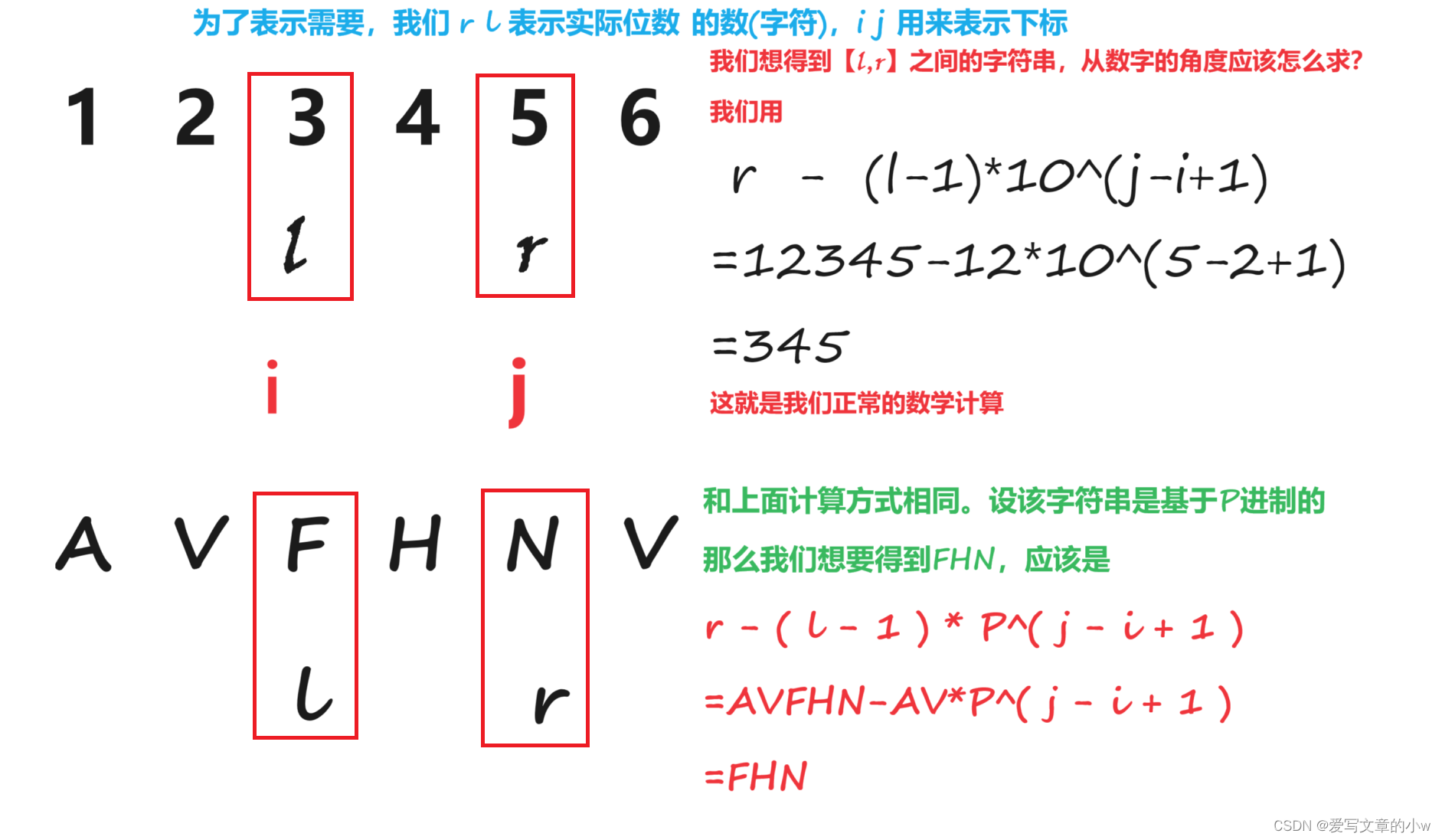
相信到这里,这种方法的思路应该是可以明白的.。
代码如下
#include<iostream>
using namespace std;
const int N=1e5+10,P=131;
typedef unsigned long long ULL;
int n,m;
char str[N];
ULL ha[N],p[N];//ha存储所有子串映射的哈希值 p数组存储 以 P 为进制数 的P的次方,方便加权求和
//ha数组的下标表示的就是前多少个字符 p数组的下标表示的就是对应多少次方
ULL get(int l,int r)
{
return ha[r]-ha[l-1]*p[r-l+1];
}
int main()
{
scanf("%d%d%s",&n,&m,str+1);
p[0]=1;
for(int i=1;i<=n;i++)
{
p[i]=p[i-1]*P;
ha[i]=ha[i-1]*P+str[i];//加权求值
}
while(m--)
{
int l1,r1,l2,r2;
scanf("%d%d%d%d",&l1,&r1,&l2,&r2);
if(get(l1,r1)==get(l2,r2))puts("Yes");
else puts("No");
}
return 0;
}一些解释
1.基数P的选择
选择P=131作为基数的原因与ASCII码表有关。在字符串哈希中,我们通常会将字符串中的每个字符转换为其对应的ASCII码,然后使用这些ASCII码来计算哈希值(这个理解哈)。ASCII码的范围是0到127,因此我们需要选择一个大于127的数作为基数,以确保不同的字符串能够映射到不同的哈希值。
通过下面的例子也很清楚。

2.unsigned long long类型
求每个前缀字符串的哈希值的方法明白了之后,我们就要想,求的时候一直在乘次方,将会导致这个映射的数特别大,也就是我们将要存进ha数组中的数会很大,为了避免数据溢出,我们当然可以定义一个特别大的数据类型来避免溢出,只是再大也会有超限的时候,因此要完成取模工作,关于对谁取模,这里又是一个经验值,一般是2^64,而恰好unsigned long long有溢出自动取模的功能,因此我们就采用了这种定义数据类型的方式。
也就是说我们完整的求出哈希值的步骤就是:按照进制算出数字,再进行取模操作,这才完成了一个哈希值的运算。
关于取模这里也有一个简化:就是我们定义unsigned long long类型的变量,它可以存储0到2^64−1之间的整数。当一个unsigned long long类型的变量的值超过2^64−1时,它会自动溢出,也就是说,它会自动对2^取余。
3.不能将一个字符串映射成0,要从1开始映射
从0开始映射的话会增加冲突概率。因此我们从1开始
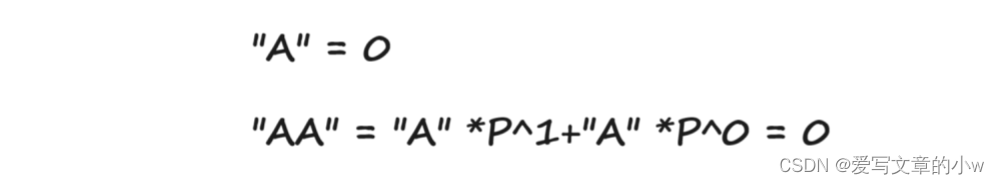
4.str数组要从1开始,为的是方便前缀和计算。
可能需要看的文章博客
讲的很好的文章,这个平台好像是有很系统的算法的文章。非常推荐
字符串哈希
这个博主写了哈希专题,也很清晰。
哈希专题
之前写的普通的哈希算法
【第十六课】哈希表上篇
可能需要回顾的kmp算法
kmp算法
字符串哈希写的汗流浃背(bushi),感觉不太好理解,把抽象的理解了之后发现还有很多细节需要琢磨。
有问题欢迎指出!一起加油!!