文章目录
- 1 写在前面
- 2 遇到问题
- 3 解决方案
- 4 探索过程
- 4.1 方案一
- 4.2 方案二
- 4.3 方案三
- 5 疑惑与思考
- 5.1 Q1
- 5.2 Q2
1 写在前面
在前面的文章中,笔者与小伙伴们分享了对 MODNet 主干网络部分以及其余分支分别剪枝的探索历程,即先分解、再处理、后融合的手法。然而,
马克思曾深刻地思考社会的全面性,强调社会是一个复杂而相互关联的整体。在他的《资本论》中,他突显了社会结构的总体性,认为理解社会现象需要考虑各个层面的相互作用。正如马克思强调的那样,我们不能孤立地看待社会中的一部分,而是应该以全面、整体的视角去考虑其内在关系和矛盾。
在这个思想的启发下,笔者将 MODNet 作为一个整体,直接做剪枝处理。同样,我们还是借助 NNI 工具库实现模型剪枝与加速。
2 遇到问题

由于 MODNet 中计算维度较大,超出了PyCharm默认的内存限制。
3 解决方案
- 修改 PyCharm 最大内存限制;
- 降低输入图像的分辨率;
- 对 MODNet 中的少部分层进行剪枝;
4 探索过程
4.1 方案一
打开 PyCharm 中的 VM options:

修改 XMX,即运用程序运行时的可用内存大小,本机的运行内存为12G,这里先对半设置 6002M。然而,运行后依旧提示内存不足,当设置为7000时,在运行中,PyCharm 自动关闭。因此,该方法无效,而且属于高危行为!
💥注意:不能绝对设置大小,考虑到计算机除 PyCharm 以外也有其他进程占用内存,因此,设置上限时需要综合考虑计算机的状况。
4.2 方案二
将 MODNet 输入尺寸从 512 降低为 256,成功剪枝!
由于使用 DataParallel 加载以后,在 GPU 上剪枝会提示显存不足!因此,笔者先将 MODNet 加载到 CPU 上,取消 DataParallel 加载,可以完成剪枝与模型加速!!
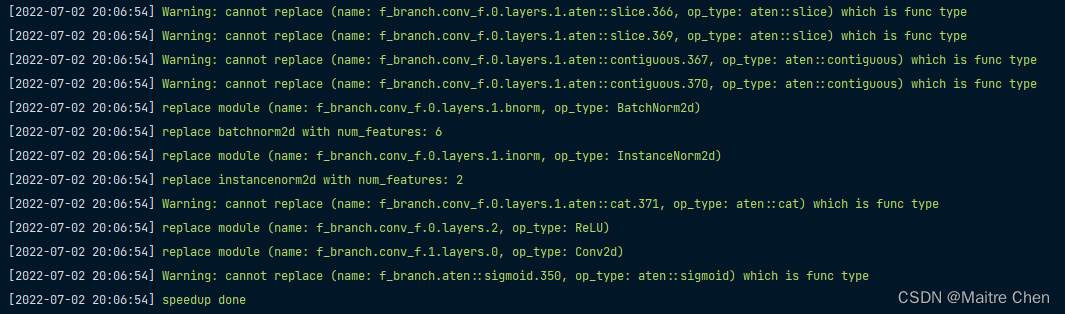
实际上,尽管模型是通过多卡训练保存得到,在使用 DataParallel 加载后,也可以直接转换到 CPU 上:
from src.models import modnet
import torch
model = modnet.MODNet(backbone_pretrained=False)
model = torch.nn.DataParallel(model).to('cpu')
pretrained_ckpt = torch.load('modnet_photographic_portrait_matting.ckpt')
model.load_state_dict(pretrained_ckpt, strict=False)
print(next(model.parameters()).device) # CPU
然而,剪枝出现了问题,即 module 的参数必须是在 CUDA 上操作,在 CPU 上无效:

该问题表明:利用to.(‘cpu’)的方式从 CUDA 转移到 CPU 本身是没问题的,但这不被 module 接受。换句话说,在 MODNet 模型外面,包裹着 module 模块。因此,如果要在 CPU 上完成剪枝,module 是首要解决的问题!
打印结构发现:
和原先进行对比:
多了 module 模块,这是一个值得思考的地方!🙄
再次了解 torch.nn.DataParallel():
在使用多卡训练时,该函数能够将 input 数据划分,进而送进不同的卡上训练;而模型的 module 会复制到不同的卡上。换句话说,具有相同 module 的不同卡会处理划分到的数据,当然,这是 forward 部分。而在 backpropagation 部分,不同卡的梯度会累加到原始的 module 上,被 cuda:0 计算。当训练完成,保存时也会采用model.module.state_dict(),而非单卡训练时的model.state_dict();在将参数加载时,结构中也必然存在module。
因此,这也就对 NNI 中看似排除某些层,实际上没有排除解释通了:原先并未在 torch.nn.DataParallel() 加载后观察结构情况,同时也因为GPU显存不够直接将模型转到了 CPU 上,导致在剪枝的 config_list 中没有指定正确的参数名。
用 NNI 输出 flops 进行对比:
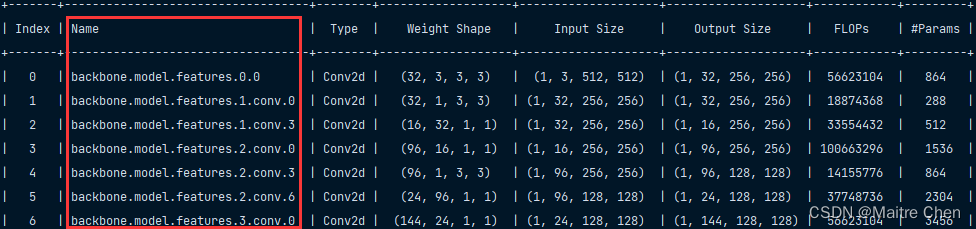
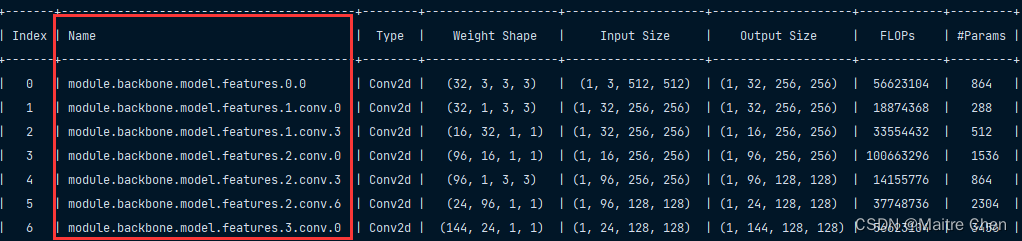
结构中的 module 模块如何处理,笔者考虑了两种方案:
- 修改 NNI 的config_list 为 module. 进行剪枝;
- 去除 module;
由于第一种方案会涉及到上述提及的问题:从 CUDA 转到 CPU 不会被 module 接受。因此我们选择方案2。
加载的 ckpt 类型为 dict,因此,通过 items 获得 key 以及 value 后可以通过 replace 替换,如下:
model = modnet.MODNet(backbone_pretrained=False)
pretrained_ckpt = 'modnet_photographic_portrait_matting.ckpt'
# model = torch.nn.DataParallel(model)
model.load_state_dict({k.replace('module.', ''):v for k, v in torch.load(pretrained_ckpt).items()})
print(model)
print(list(model.named_parameters()))
此时,module 模块成功去除,且惊奇发现,即使不通过 DataParallel 加载 model,每次打印得到的权重参数也保持一致了!至此,module 问题解决,在 CPU 上的剪枝也就顺其自然了~~
4.3 方案三
不论如何排除某些层,从 NNI 在控制台输出的 info 来看,每次都会从头到尾计算每一层的信息,并进行更新。此外,尽管排除了某些层,由于上一层的通道数变化会影响下一层的变化,因此还是会进行计算。
所以,通过排除某些层,或者是指定某些层进行剪枝的作法,就解决内存限制问题而言,并不合理!
5 疑惑与思考
5.1 Q1
在剪枝过后,模型精度相应也会降低,为了能恢复到原来的精度,或者是达到可接受的精度,应当进行微调(fine-tune),其中需要调整训练超参数,包括 epoch、learning rate、momentum 等;
🚩说明:剪枝模型重训练不光可以采用微调,也可从头训练。这一观点在《Rethinking the value of network pruning》一文中表明。另外,文章中通过实验说明了从头训练的效果优于微调,原因是模型剪枝后重要的是紧凑的结构,而不是原来的那些重要的权重。
笔者以 LeNet 为例做了一个剪枝后微调的实验,对比如下:
| 原模型 | 剪枝后 | 微调后 | |
|---|---|---|---|
| Accuracy | 91% | 85% | 94% |
为什么剪枝模型在 fine-tune 后精度更高?
有这样一种解释,大模型提供了一个包含最优解的大的解空间,而对于小模型来说,这样的解空间较小,因此更容易找到 optimal solution,故精度会比大模型更高。
但是,有些时候或许 fine-tune 后精度还是很差,这是为什么?
注意,这里笔者思考的事为啥很差,而不是差,如果下降比例不大的话,其实是因为剪枝本身导致的信息损失,这和评价指标有关,是很难避免的。
- 过度剪枝: 剪枝了太多的参数,导致模型容量不足,无法捕获数据中的复杂模式,以至于模型欠拟合,表现较差。
- 超参数调整不当: 超参数的调整本身并不容易,不同的任务和数据集需要不同的超参数配置。笔者在调参时遇到不同的随机种子可以带来10%准确率差异!所以,模型可能无法收敛到良好的解决方案。
- 数据不足: 如果 fine-tuning 阶段的训练数据量不足,模型可能无法充分学习新任务的特征,导致性能下降。(这里又有一个问题,大模型小数据训练会如何?也不好训练,因为大模型可能会过于复杂,难以泛化到新的数据)
- 任务不适合: 原始模型可能不适合进行剪枝和 fine-tuning 的任务,某些任务可能需要更大的模型,或者可以考虑使用从头训练。(但一般fine-tune和从头训练不会差异巨大)
另外,笔者也抛出一个有意思的问题:剪枝时,我们通常会采用某一种评价准则去衡量权重的重要程度,如果重要程度低,我们认为是冗余权重,所以去除;而重要权重我们选择保留,那么,冗余权重真的冗余吗?是否也会对整个模型的评估起“支撑”作用?但笔者再想想,既然都是冗余了,那为啥还要保留?说明一定是对模型不再起作用的。所以问题就回到了这个评价准则,到底如何去设计评价准则,一直是模型剪枝的一个挑战。
5.2 Q2
在只保存剪枝后模型参数的情况下,需要修改相应的网络结构才能将参数填入结构中,那为何不可参考剪枝后的结构修改原先的结构,并进行训练?
解释:因为大模型要比小模型好训练。
- 更多的参数: 这意味着更大的模型可以学习更复杂的特征和模式,更多的参数允许模型更好地适应训练数据,捕获更多的细节和复杂性。
- 更好的表示能力: 大模型有更大的容量来表示数据的复杂关系,能够学习更抽象、更深层次的特征,使其在处理复杂任务时更为有效。
- 更好的泛化能力: 大模型在训练中可以学到更多的信息,从而提高了其在未见数据上的泛化能力,这意味着它们更有可能在面对新的、未知的数据时表现良好。
当然,由于训练大模型需要的训练时间长,计算资源和内存消耗也更大,所以需要根据实际的情况找到 trade-off!