Day3 - 1.数据解析概述_哔哩哔哩_bilibili
聚焦爬虫:爬取页面中指定的页面内容
编码流程:指定url -> 发起请求 -> 获取响应数据 -> 数据解析 -> 持久化存储
数据解析分类:正则、bs4、xpath(本教程的重点)
数据解析原理概述:解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储
1.进行指定标签的定位
2.标签或者标签对应的属性中存储的数据值进行提取(解析)
图片的爬取
图片是以二进制方式存储的,复制图片链接输入浏览器可以得到图片对应的url
import requests
url = 'https://img-blog.csdnimg.cn/09ad194be31144e9b628bcd26916c144.png'
# content返回二进制形式的图片数据
image_data = requests.get(url).content
with open('picture.png', 'wb') as fp:
fp.write(image_data)由于糗事百科停运了,所以找了个美女照片网站
美女写真图片大全_3g壁纸 (3gbizhi.com)
对图片进行检查,看到图片的url都是放在img标签里的,而src后面的值就是它的url
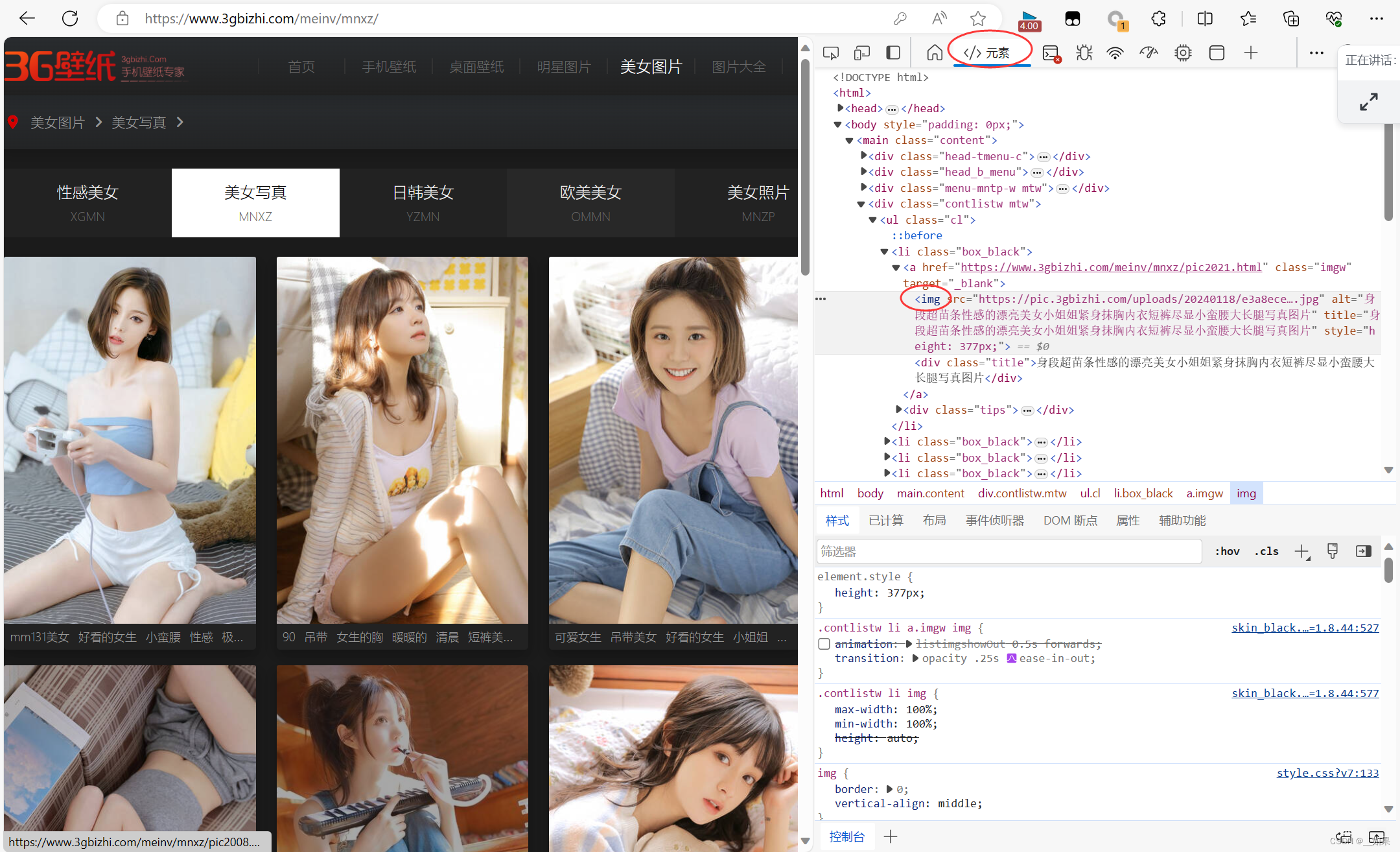
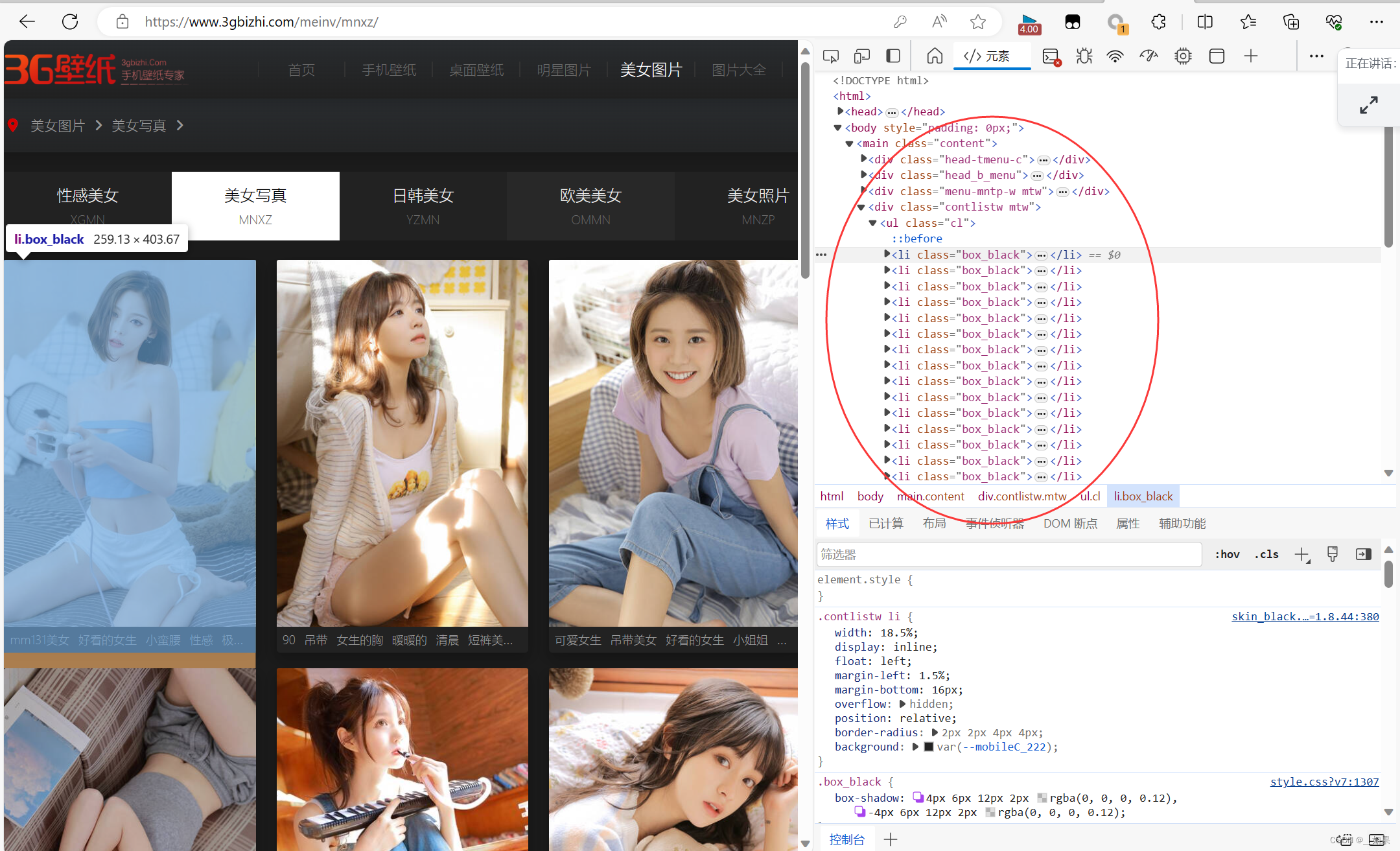
观察图片的层级关系,发现都在<ul class="cl">下,在<li class>中
import re
import requests
import os
if not os.path.exists('./girls_picture'):
os.makedirs('girls_picture')
url = 'https://www.3gbizhi.com/meinv/mnxz/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
response = requests.get(url, headers=headers)
page_text = response.text
# 使用聚焦爬虫对页面的信息进行解析
ex = '<li class="box_black">.*?<img src="(.*?)" alt.*? </li>'
img_src_list = re.findall(ex, page_text, re.S)
new_img_src_list = []
for i in img_src_list:
i = i[51:]
new_img_src_list.append(i)
print(new_img_src_list)
for src in new_img_src_list:
image_data = requests.get(src, headers=headers).content
image_name = src.split('/')[-1]
image_path = 'girls_picture' + '/' + image_name
with open(image_path, 'wb') as fp:
fp.write(image_data)
print(image_name + '下载成功')
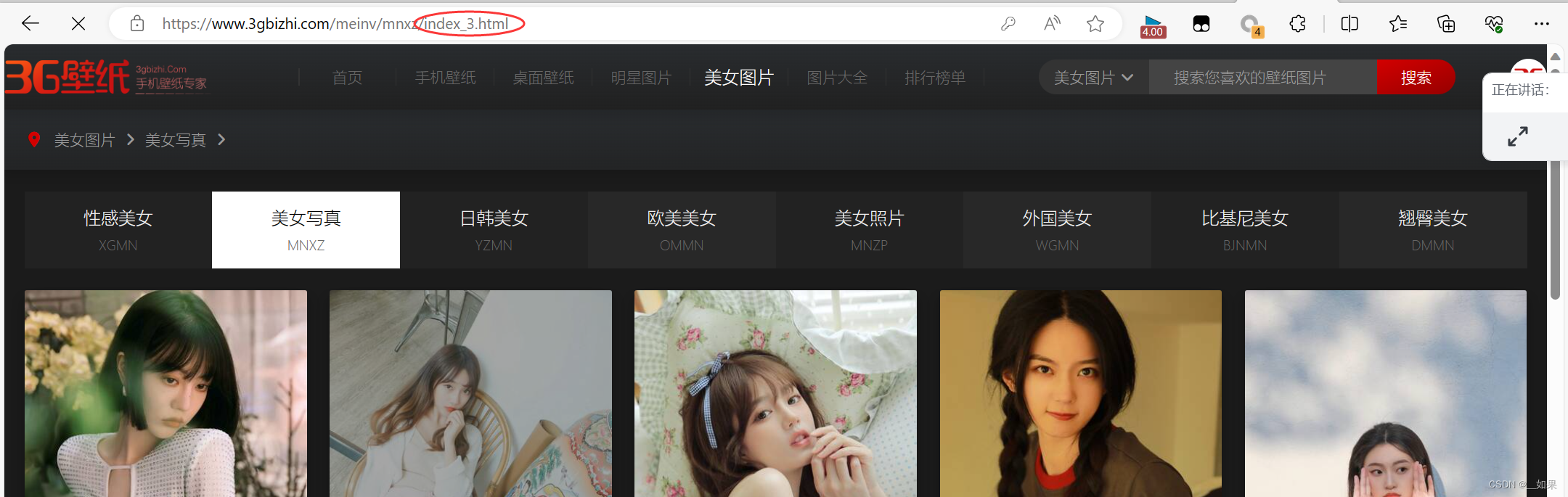
多页爬取
我们发现翻页的url变动是有规律的,因此只需for循环更改index后面的数字
import re
import requests
import os
if not os.path.exists('./girls_picture'):
os.makedirs('girls_picture')
url = 'https://www.3gbizhi.com/meinv/mnxz/index_%d.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
for i in range(1, 4):
new_url = format(url % i)
response = requests.get(new_url, headers=headers)
page_text = response.text
# 使用聚焦爬虫对页面的信息进行解析
ex = '<li class="box_black">.*?<img src="(.*?)" alt.*? </li>'
img_src_list = re.findall(ex, page_text, re.S)
new_img_src_list = []
for i in img_src_list:
i = i[51:]
new_img_src_list.append(i)
print(new_img_src_list)
for src in new_img_src_list:
image_data = requests.get(src, headers=headers).content
image_name = src.split('/')[-1]
image_path = 'girls_picture' + '/' + image_name
with open(image_path, 'wb') as fp:
fp.write(image_data)
print(image_name + '下载成功')bs4
bs4只能被应用在python中
原理:1.实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中
2.通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取
对象的实例化:1.将本地的html文档中的数据加载到该对象中
fp = open('./test.html','r',encoding=' utf-8'
soup = BeautifulSoup(fp,'Ixml')
from bs4 import BeautifulSoup
# 将本地的html文件加载倒BeautifulSoup对象中
fp = open('sogpu.html', 'r', encoding='utf-8')
soup = BeautifulSoup(fp, 'lxml')
print(soup) 2.将互联网上获取的页面源码加载到该对象中
page text = response.text
soup = BeatifulSoup(page text,'xml')
具体使用
1.soup.tagName:返回html中第一次出现tagName的标签:
print(soup.a) # 打印a标签
'''
<a href="http://weixin.sogou.com/" id="weixinch" onclick="st(this,'73141200','weixin')" uigs-id="nav_weixin">微信</a>
'''2.soup.find('tagName'):等同于soup.tagName
print(soup.find('a'))
'''
<a href="http://weixin.sogou.com/" id="weixinch" onclick="st(this,'73141200','weixin')" uigs-id="nav_weixin">微信</a>
'''属性定位:soup.find('tagName', 属性='')
print(soup.find('div', class_='wrapper'))
'''
<div class="wrapper" id="wrap">
<div class="header">
<div class="top-nav">
<ul>
<li class="cur"><span>网页</span></li>
<li><a href="http://weixin.sogou.com/" id="weixinch" onclick="st(this,'73141200','weixin')" uigs-id="nav_weixin">微信</a></li>
<li><a href="http://zhihu.sogou.com/" id="zhihu" onclick="st(this,'40051200','zhihu')" uigs-id="nav_zhihu">知乎</a></li>
<li><a href="http://pic.sogou.com" id="pic" onclick="st(this,'40030500','pic')" uigs-id="nav_pic">图片</a></li>
<li><a href="https://v.sogou.com/" id="video" onclick="st(this,'40030600','video')" uigs-id="nav_v">视频</a></li>
......
'''3.soup.find_all('tagName'):返回所有的标签,以列表的形式
print(soup.find_all('a'))
'''
[<a href="http://weixin.sogou.com/" id="weixinch" onclick="st(this,'73141200','weixin')" uigs-id="nav_weixin">微信</a>, <a href="http://zhihu.sogou.com/" id="zhihu" onclick="st(this,'40051200','zhihu')" uigs-id="nav_zhihu">知乎</a>, <a href="http://pic.sogou.com" id="pic" onclick="st(this,'40030500','pic')" uigs-id="nav_pic">图片</a>, <a href="https://v.sogou.com/" id="video" onclick="st(this,'40030600','video')" uigs-id="nav_v">视频</a>, <a href="http://mingyi.sogou.com?fr=common_index_nav" id="mingyi" onclick="st(this,'','myingyi')" uigs-id="nav_mingyi">医疗</a>, <a href="http://hanyu.sogou.com?fr=pcweb_index_nav" id="hanyu" onclick="st(this,'','hanyu')" uigs-id="nav_hanyu">汉语</a>, <a href="http://fanyi.sogou.com?fr=common_index_nav_pc" id="fanyi" onclick="st(this,'','fanyi')" uigs-id="nav_fanyi">翻译</a>, <a href="https://wenwen.sogou.com/?ch=websearch" id="index_more_wenwen" onclick="st(this,'web2ww','wenwen')" uigs-id="nav_wenwen">问问</a>, <a href="http://baike.sogou.com/Home.v" id="index_baike" onclick="st(this,'web2ww','baike')" uigs-id="nav_baike">百科</a>, <a href="http://map.sogou.com" id="map" onclick="st(this,'40031000')" uigs-id="nav_map">地图</a>, <a href="javascript:void(0);" id="more-product">更多<i class="m-arr"></i></a>, <a href="http://zhishi.sogou.com" id="index_more_zhishi" onclick="st(this)" uigs-id="nav_zhishi">知识</a>, <a href="http://as.sogou.com/" id="index_more_appli" onclick="st(this,'40051205')" uigs-id="nav_app">应用</a>, <a href="http://www.sogou.com/docs/more.htm?v=1" onclick="st(this,'40051206')" target="_blank" uigs-id="nav_all">全部</a>, <a href="javascript:void(0)" id="cniil_wza" style="float:left;text-decoration:none;color:#000;opacity:.75;padding-left:8px;margin-right:20px;line-height:14px;position:relative;top:5px">无障碍</a>, <a href="//e.qq.com?from=sougou01" target="_blank" uigs-id="footer_tuiguang">企业推广</a>, <a href="http://www.sogou.com/docs/terms.htm?v=1" target="_blank" uigs-id="footer_disclaimer">免责声明</a>, <a href="http://fankui.help.sogou.com/index.php/web/web/index/type/4" target="_blank" uigs-id="footer_feedback">意见反馈及投诉</a>, <a href="https://www.sogou.com/docs/privacy.htm?v=1" target="_blank" uigs-id="footer_private">隐私政策</a>, <a class="g" href="http://www.12377.cn" target="_blank">网上有害信息举报专区</a>, <a class="g" href="https://beian.miit.gov.cn/" target="_blank">京ICP证050897号</a>, <a class="g" href="https://beian.miit.gov.cn/" target="_blank">京ICP备11001839号-1</a>, <a class="ba" href="http://www.beian.gov.cn/portal/registerSystemInfo?recordcode=11000002000025" target="_blank">京公网安备11000002000025号</a>, <a href="http://pinyin.sogou.com/" target="_blank" uigs-id="mid_pinyin"><i class="i1"></i>搜狗输入法</a>, <a href="http://ie.sogou.com/" target="_blank" uigs-id="mid_liulanqi"><i class="i2"></i>浏览器</a>, <a href="http://123.sogou.com/" target="_blank" uigs-id="mid_daohang"><i class="i3"></i>网址导航</a>, <a class="g" href="//e.qq.com?from=sougou01" target="_blank">企业推广</a>, <a class="g" href="http://www.sogou.com/docs/terms.htm?v=1" target="_blank">免责声明</a>, <a class="g" href="http://fankui.help.sogou.com/index.php/web/web/index/type/4" target="_blank">意见反馈及投诉</a>, <a class="g" href="https://www.sogou.com/docs/privacy.htm?v=1" target="_blank" uigs-id="footer_private">隐私政策</a>, <a class="g" href="http://www.12377.cn" target="_blank">网上有害信息举报专区</a>, <a class="g" href="https://beian.miit.gov.cn/" target="_blank">京ICP证050897号</a>, <a class="g" href="https://beian.miit.gov.cn/" target="_blank">京ICP备11001839号-1</a>, <a class="ba" href="http://www.beian.gov.cn/portal/registerSystemInfo?recordcode=11000002000025" target="_blank">京公网安备11000002000025号</a>, <a href="javascript:void(0);" id="miniQRcode"></a>, <a class="back-top" href="javascript:void(0);" id="back-top"></a>]
'''4.soup.select('某种选择器(id,class,标签......)'):返回一个列表
print(soup.select('a'))
'''
[<a href="http://weixin.sogou.com/" id="weixinch" onclick="st(this,'73141200','weixin')" uigs-id="nav_weixin">微信</a>, <a href="http://zhihu.sogou.com/" id="zhihu" onclick="st(this,'40051200','zhihu')" uigs-id="nav_zhihu">知乎</a>, <a href="http://pic.sogou.com" id="pic" onclick="st(this,'40030500','pic')" uigs-id="nav_pic">图片</a>, <a href="https://v.sogou.com/" id="video" onclick="st(this,'40030600','video')" uigs-id="nav_v">视频</a>, <a href="http://mingyi.sogou.com?fr=common_index_nav" id="mingyi" onclick="st(this,'','myingyi')" uigs-id="nav_mingyi">医疗</a>, <a href="http://hanyu.sogou.com?fr=pcweb_index_nav" id="hanyu" onclick="st(this,'','hanyu')" uigs-id="nav_hanyu">汉语</a>, <a href="http://fanyi.sogou.com?fr=common_index_nav_pc" id="fanyi" onclick="st(this,'','fanyi')" uigs-id="nav_fanyi">翻译</a>, <a href="https://wenwen.sogou.com/?ch=websearch" id="index_more_wenwen" onclick="st(this,'web2ww','wenwen')" uigs-id="nav_wenwen">问问</a>, <a href="http://baike.sogou.com/Home.v" id="index_baike" onclick="st(this,'web2ww','baike')" uigs-id="nav_baike">百科</a>, <a href="http://map.sogou.com" id="map" onclick="st(this,'40031000')" uigs-id="nav_map">地图</a>, <a href="javascript:void(0);" id="more-product">更多<i class="m-arr"></i></a>, <a href="http://zhishi.sogou.com" id="index_more_zhishi" onclick="st(this)" uigs-id="nav_zhishi">知识</a>, <a href="http://as.sogou.com/" id="index_more_appli" onclick="st(this,'40051205')" uigs-id="nav_app">应用</a>, <a href="http://www.sogou.com/docs/more.htm?v=1" onclick="st(this,'40051206')" target="_blank" uigs-id="nav_all">全部</a>, <a href="javascript:void(0)" id="cniil_wza" style="float:left;text-decoration:none;color:#000;opacity:.75;padding-left:8px;margin-right:20px;line-height:14px;position:relative;top:5px">无障碍</a>, <a href="//e.qq.com?from=sougou01" target="_blank" uigs-id="footer_tuiguang">企业推广</a>, <a href="http://www.sogou.com/docs/terms.htm?v=1" target="_blank" uigs-id="footer_disclaimer">免责声明</a>, <a href="http://fankui.help.sogou.com/index.php/web/web/index/type/4" target="_blank" uigs-id="footer_feedback">意见反馈及投诉</a>, <a href="https://www.sogou.com/docs/privacy.htm?v=1" target="_blank" uigs-id="footer_private">隐私政策</a>, <a class="g" href="http://www.12377.cn" target="_blank">网上有害信息举报专区</a>, <a class="g" href="https://beian.miit.gov.cn/" target="_blank">京ICP证050897号</a>, <a class="g" href="https://beian.miit.gov.cn/" target="_blank">京ICP备11001839号-1</a>, <a class="ba" href="http://www.beian.gov.cn/portal/registerSystemInfo?recordcode=11000002000025" target="_blank">京公网安备11000002000025号</a>, <a href="http://pinyin.sogou.com/" target="_blank" uigs-id="mid_pinyin"><i class="i1"></i>搜狗输入法</a>, <a href="http://ie.sogou.com/" target="_blank" uigs-id="mid_liulanqi"><i class="i2"></i>浏览器</a>, <a href="http://123.sogou.com/" target="_blank" uigs-id="mid_daohang"><i class="i3"></i>网址导航</a>, <a class="g" href="//e.qq.com?from=sougou01" target="_blank">企业推广</a>, <a class="g" href="http://www.sogou.com/docs/terms.htm?v=1" target="_blank">免责声明</a>, <a class="g" href="http://fankui.help.sogou.com/index.php/web/web/index/type/4" target="_blank">意见反馈及投诉</a>, <a class="g" href="https://www.sogou.com/docs/privacy.htm?v=1" target="_blank" uigs-id="footer_private">隐私政策</a>, <a class="g" href="http://www.12377.cn" target="_blank">网上有害信息举报专区</a>, <a class="g" href="https://beian.miit.gov.cn/" target="_blank">京ICP证050897号</a>, <a class="g" href="https://beian.miit.gov.cn/" target="_blank">京ICP备11001839号-1</a>, <a class="ba" href="http://www.beian.gov.cn/portal/registerSystemInfo?recordcode=11000002000025" target="_blank">京公网安备11000002000025号</a>, <a href="javascript:void(0);" id="miniQRcode"></a>, <a class="back-top" href="javascript:void(0);" id="back-top"></a>]
'''print(soup.select('.user-box'))
'''
[<div class="user-box">
<div class="local-weather" id="local-weather">
<div class="wea-box" id="cur-weather" style="display:none"></div>
<div class="pos-more" id="detail-weather" style="top:40px;left:-110px"></div>
</div>
<span class="line" id="user-box-line" style="display:none"></span> <a href="javascript:void(0)" id="cniil_wza" style="float:left;text-decoration:none;color:#000;opacity:.75;padding-left:8px;margin-right:20px;line-height:14px;position:relative;top:5px">无障碍</a>
</div>]
'''5.soup.select('... > ... > ...'):层级选择
print(soup.select('.wrapper > .header > .top-nav > ul > li > a'))
'''
[<a href="http://weixin.sogou.com/" id="weixinch" onclick="st(this,'73141200','weixin')" uigs-id="nav_weixin">微信</a>, <a href="http://zhihu.sogou.com/" id="zhihu" onclick="st(this,'40051200','zhihu')" uigs-id="nav_zhihu">知乎</a>, <a href="http://pic.sogou.com" id="pic" onclick="st(this,'40030500','pic')" uigs-id="nav_pic">图片</a>, <a href="https://v.sogou.com/" id="video" onclick="st(this,'40030600','video')" uigs-id="nav_v">视频</a>, <a href="http://mingyi.sogou.com?fr=common_index_nav" id="mingyi" onclick="st(this,'','myingyi')" uigs-id="nav_mingyi">医疗</a>, <a href="http://hanyu.sogou.com?fr=pcweb_index_nav" id="hanyu" onclick="st(this,'','hanyu')" uigs-id="nav_hanyu">汉语</a>, <a href="http://fanyi.sogou.com?fr=common_index_nav_pc" id="fanyi" onclick="st(this,'','fanyi')" uigs-id="nav_fanyi">翻译</a>, <a href="https://wenwen.sogou.com/?ch=websearch" id="index_more_wenwen" onclick="st(this,'web2ww','wenwen')" uigs-id="nav_wenwen">问问</a>, <a href="http://baike.sogou.com/Home.v" id="index_baike" onclick="st(this,'web2ww','baike')" uigs-id="nav_baike">百科</a>, <a href="http://map.sogou.com" id="map" onclick="st(this,'40031000')" uigs-id="nav_map">地图</a>, <a href="javascript:void(0);" id="more-product">更多<i class="m-arr"></i></a>]
'''
空格可以表示多层级,例如ul下的a标签全在li中,这时可以
print(soup.select('.wrapper > .header > .top-nav > ul a'))
'''
[<a href="http://weixin.sogou.com/" id="weixinch" onclick="st(this,'73141200','weixin')" uigs-id="nav_weixin">微信</a>, <a href="http://zhihu.sogou.com/" id="zhihu" onclick="st(this,'40051200','zhihu')" uigs-id="nav_zhihu">知乎</a>, <a href="http://pic.sogou.com" id="pic" onclick="st(this,'40030500','pic')" uigs-id="nav_pic">图片</a>, <a href="https://v.sogou.com/" id="video" onclick="st(this,'40030600','video')" uigs-id="nav_v">视频</a>, <a href="http://mingyi.sogou.com?fr=common_index_nav" id="mingyi" onclick="st(this,'','myingyi')" uigs-id="nav_mingyi">医疗</a>, <a href="http://hanyu.sogou.com?fr=pcweb_index_nav" id="hanyu" onclick="st(this,'','hanyu')" uigs-id="nav_hanyu">汉语</a>, <a href="http://fanyi.sogou.com?fr=common_index_nav_pc" id="fanyi" onclick="st(this,'','fanyi')" uigs-id="nav_fanyi">翻译</a>, <a href="https://wenwen.sogou.com/?ch=websearch" id="index_more_wenwen" onclick="st(this,'web2ww','wenwen')" uigs-id="nav_wenwen">问问</a>, <a href="http://baike.sogou.com/Home.v" id="index_baike" onclick="st(this,'web2ww','baike')" uigs-id="nav_baike">百科</a>, <a href="http://map.sogou.com" id="map" onclick="st(this,'40031000')" uigs-id="nav_map">地图</a>, <a href="javascript:void(0);" id="more-product">更多<i class="m-arr"></i></a>]
'''6. .text/.string/.get_text:text和get_text是获取标签下所有的文本内容,可以跨层级
string只能获取本标签中的文本内容
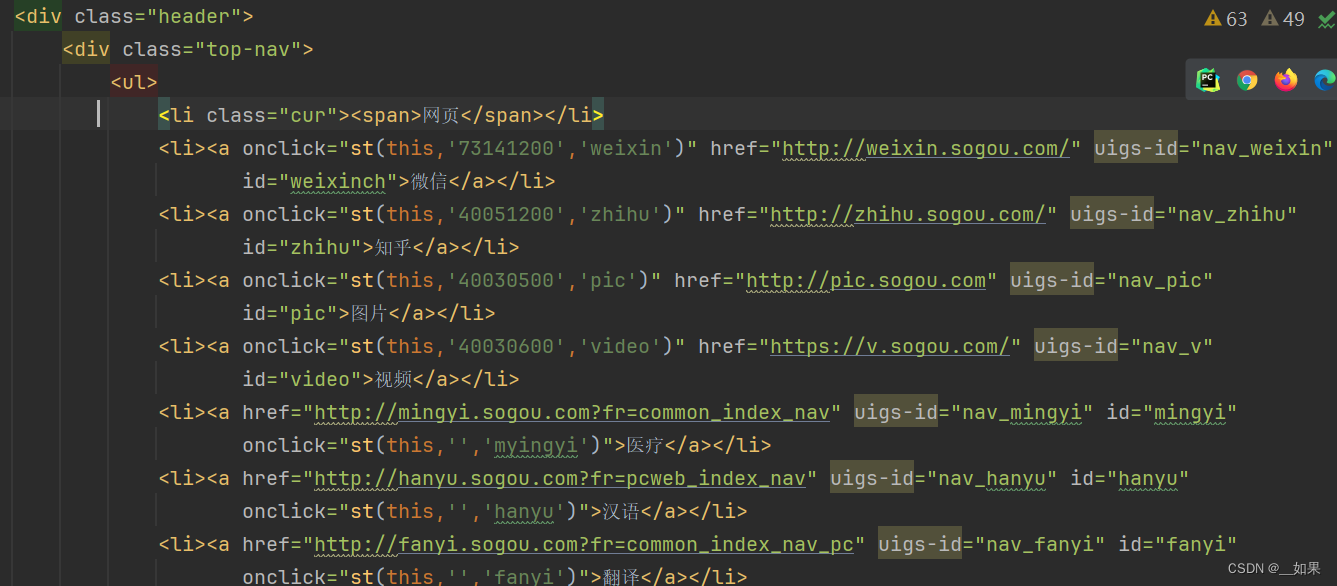
print(soup.select('.header')[0].text)
'''
网页
微信
知乎
图片
视频
医疗
汉语
翻译
问问
百科
地图
更多
知识应用全部
......
'''
print(soup.select('.header')[0].string)
'''
None
'''7.['属性']:获取标签中的属性内容
print(soup.select('.top-nav > ul > li > a')[0]['href'])
'''
http://weixin.sogou.com/
'''
bs4实战
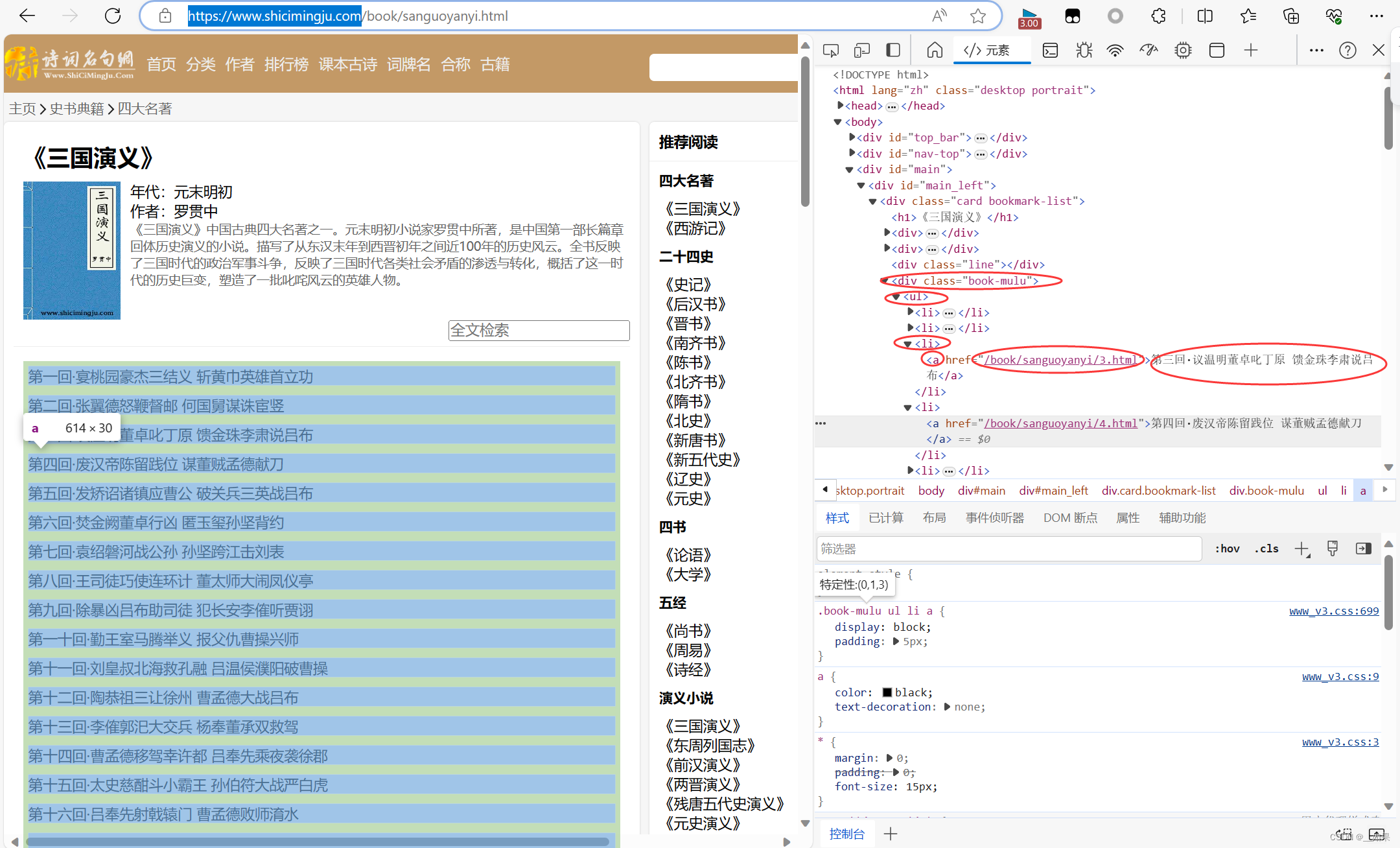
爬取三国演义中所有的章节标题和章节内容
《三国演义》全集在线阅读_史书典籍_诗词名句网 (shicimingju.com)

由于是获取所有内容,因此不用一个个去p标签里面循环提取文字,而是之间用text或get_text
import requests
from bs4 import BeautifulSoup
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
page_text = requests.get(url, headers=headers).text
soup = BeautifulSoup(page_text, 'lxml')
li_list = soup.select('.book-mulu > ul > li')
fp = open('sanguoyanyi.txt', 'w', encoding='utf-8')
for li in li_list:
title = li.a.string
detail_url = 'https://www.shicimingju.com/' + li.a['href']
# 对详情页发起请求
detail_page_text = requests.get(detail_url, headers=headers).text
detail_soup = BeautifulSoup(detail_page_text, 'lxml')
div_tag = detail_soup.find('div', class_='chapter_content')
content = div_tag.text
fp.write(title + ': ' + content + '\n')
print(title + '爬取成功\n')报错是因为现在这个网站对文字加密了,找不到chapter_content和p的内容,但代码是没问题的
xpath
最常用、编写最高效、最通用的数据解析方式
原理:1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中
2.调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获
如何实例化一个etree对象:from Lxml import etree
- 1.将本地的html文档中的源码数据加载到etree对象中:
etree.parse(filePath)
- 2.可以将从互联网上获取的源码数据加载到该对象中:
etree.HTML('page_text' )
from lxml import etree
# 实例化一个etree对象
tree = etree.parse('sogou.html', etree.HTMLParser())
# 层级关系,由外到内
trs = tree.xpath('/html/head/meta')
print(trs)
'''
[<Element meta at 0x25a08a8d600>, <Element meta at 0x25a08a8d5c0>, <Element meta at 0x25a08a8d800>, <Element meta at 0x25a08a8d900>, <Element meta at 0x25a08a8d8c0>, <Element meta at 0x25a08a8d9c0>, <Element meta at 0x25a08a8da00>]
'''返回一个列表,里面放着Element类型的对象;/表示从根节点开始定位,表示一个层级
from lxml import etree
# 实例化一个etree对象
tree = etree.parse('sogou.html', etree.HTMLParser())
# 层级关系,由外到内
trs = tree.xpath('/html//meta')
print(trs)
'''
[<Element meta at 0x25a08a8d600>, <Element meta at 0x25a08a8d5c0>, <Element meta at 0x25a08a8d800>, <Element meta at 0x25a08a8d900>, <Element meta at 0x25a08a8d8c0>, <Element meta at 0x25a08a8d9c0>, <Element meta at 0x25a08a8da00>]
'''//表示多个层级,类似于bs4中的空格
from lxml import etree
# 实例化一个etree对象
tree = etree.parse('sogou.html', etree.HTMLParser())
# 层级关系,由外到内
trs = tree.xpath('//meta')
print(trs)
'''
[<Element meta at 0x249b03e0500>, <Element meta at 0x249b03e0600>, <Element meta at 0x249b03e05c0>, <Element meta at 0x249b03e0480>, <Element meta at 0x249b03e06c0>, <Element meta at 0x249b03e0740>, <Element meta at 0x249b03e0780>]
'''//也表示从任意层级开始匹配,可以获取全部的标签
from lxml import etree
# 实例化一个etree对象
tree = etree.parse('sogou.html', etree.HTMLParser())
# 层级关系,由外到内
trs = tree.xpath('//div[@class="content"]')
print(trs)
'''
[<Element div at 0x1c44c380640>]
'''[@...]属性定位
from lxml import etree
# 实例化一个etree对象
tree = etree.parse('sogou.html', etree.HTMLParser())
# 层级关系,由外到内
trs = tree.xpath('//div[@class="top-nav"]/ul/li')
print(trs)
'''
[<Element li at 0x1852260ac00>, <Element li at 0x1852260abc0>, <Element li at 0x1852260aa80>, <Element li at 0x1852260acc0>, <Element li at 0x1852260ad00>, <Element li at 0x1852260ad80>, <Element li at 0x1852260adc0>, <Element li at 0x1852260ae00>, <Element li at 0x1852260ae40>, <Element li at 0x1852260ad40>, <Element li at 0x1852260ae80>, <Element li at 0x1852260aec0>]
'''
trs = tree.xpath('//div[@class="top-nav"]/ul/li[1]')
print(trs)
'''
[<Element li at 0x1852260ac00>]
'''[num]索引定位,num不是下标,而是索引偏移量,因此1就是第1个
from lxml import etree
# 实例化一个etree对象
tree = etree.parse('sogou.html', etree.HTMLParser())
# 层级关系,由外到内
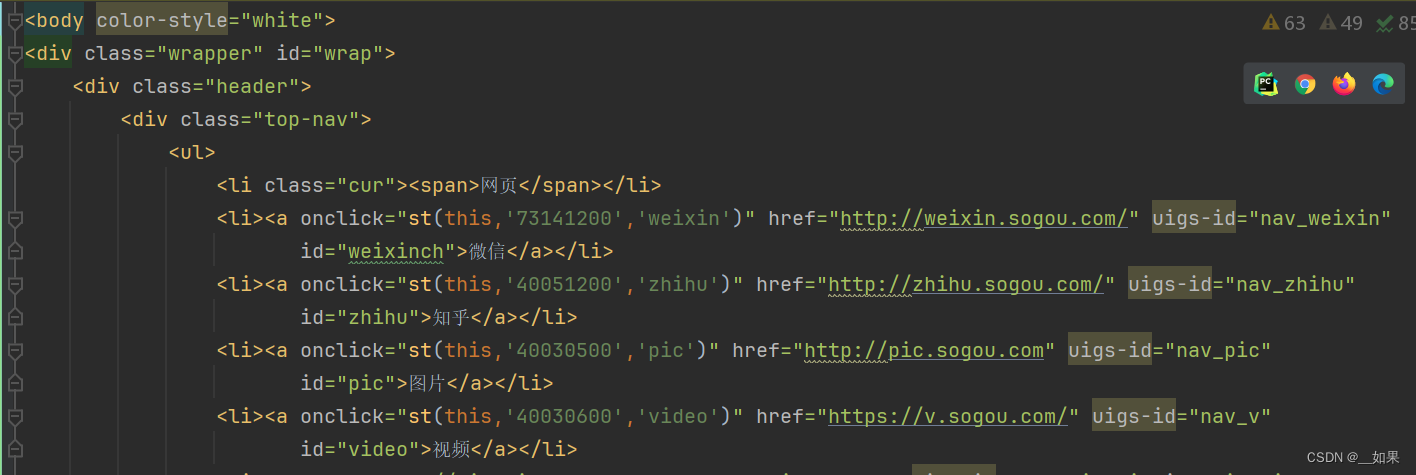
trs = tree.xpath('//div[@class="top-nav"]/ul/li[2]/a/text()')
print(trs)
'''
['微信']
'''
/text():只取本标签中的文字内容
from lxml import etree
# 实例化一个etree对象
tree = etree.parse('sogou.html', etree.HTMLParser())
# 层级关系,由外到内
trs = tree.xpath('//div[@class="top-nav"]//text()')
print(trs)
'''
['\r\n ', '\r\n ', '网页', '\r\n ', '微信', '\r\n ', '知乎', '\r\n ', '图片', '\r\n ', '视频', '\r\n ', '医疗', '\r\n ', '汉语', '\r\n ', '翻译', '\r\n ', '问问', '\r\n ', '百科', '\r\n ', '地图', '\r\n ', '\r\n ', '更多', '\r\n ', '知识', '应用', '全部', '\r\n ', '\r\n ', '\r\n ']
'''//text():可以取到非直系的文字内容
from lxml import etree
# 实例化一个etree对象
tree = etree.parse('sogou.html', etree.HTMLParser())
# 层级关系,由外到内
trs = tree.xpath('//div[@class="top-nav"]//@href')
print(trs)
'''
['http://weixin.sogou.com/', 'http://zhihu.sogou.com/', 'http://pic.sogou.com', 'https://v.sogou.com/', 'http://mingyi.sogou.com?fr=common_index_nav', 'http://hanyu.sogou.com?fr=pcweb_index_nav', 'http://fanyi.sogou.com?fr=common_index_nav_pc', 'https://wenwen.sogou.com/?ch=websearch', 'http://baike.sogou.com/Home.v', 'http://map.sogou.com', 'javascript:void(0);', 'http://zhishi.sogou.com', 'http://as.sogou.com/', 'http://www.sogou.com/docs/more.htm?v=1']
'''/@属性:获取标签中属性的值
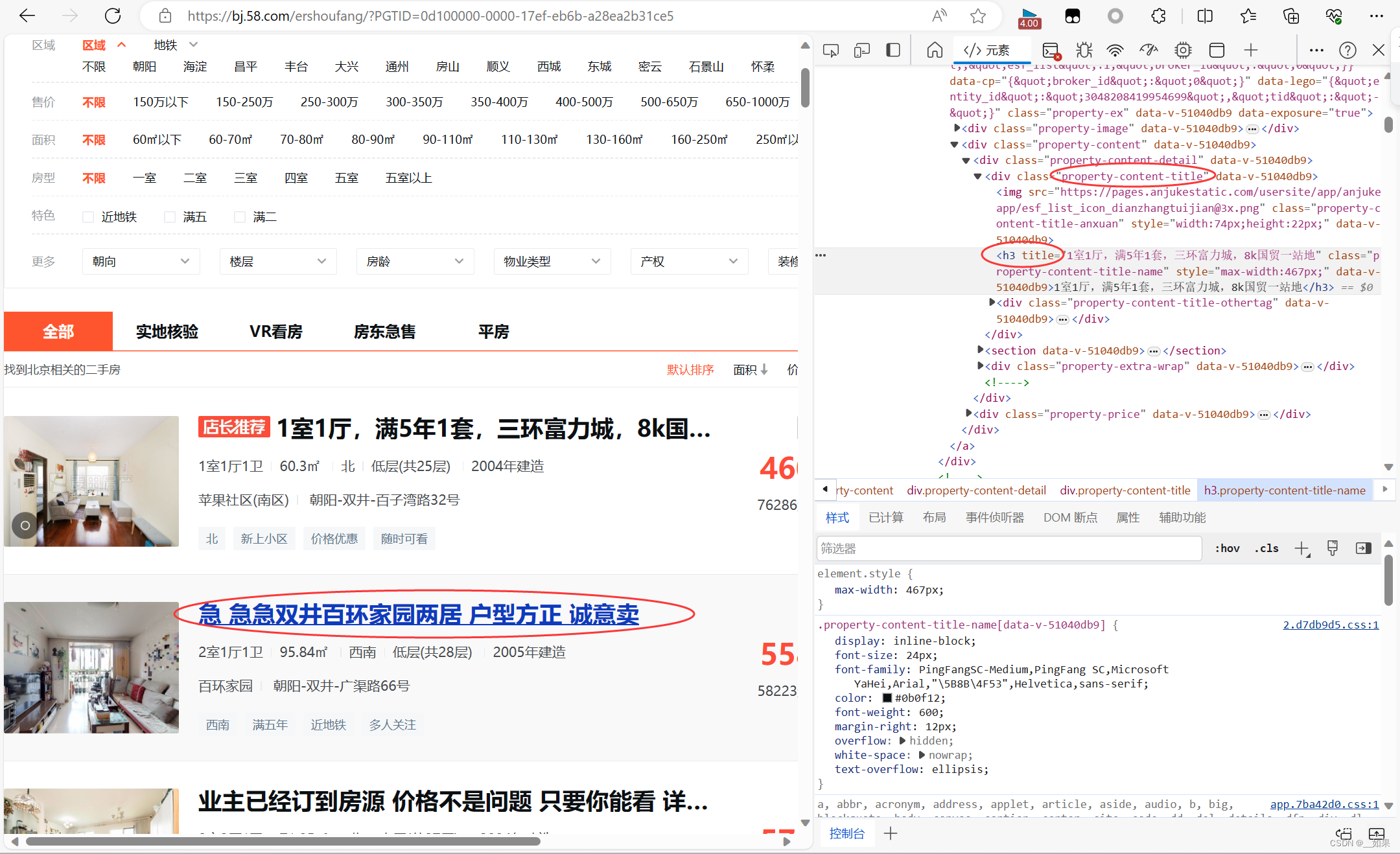
58二手房房源
爬取并解析出二手房房源的名称
北京二手房网,北京房产网,北京二手房买卖出售交易信息-北京58同城
import requests
from lxml import etree
url = 'https://bj.58.com/ershoufang'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
page_text = requests.get(url, headers=headers).text
tree = etree.HTML(page_text)
trs = tree.xpath('//div[@class="property-content-title"]/h3/@title')
fp = open('./2hand_house.txt', 'w', encoding='utf-8')
for i in trs:
fp.write(i + '\n')未完待续...