1、培训001
1
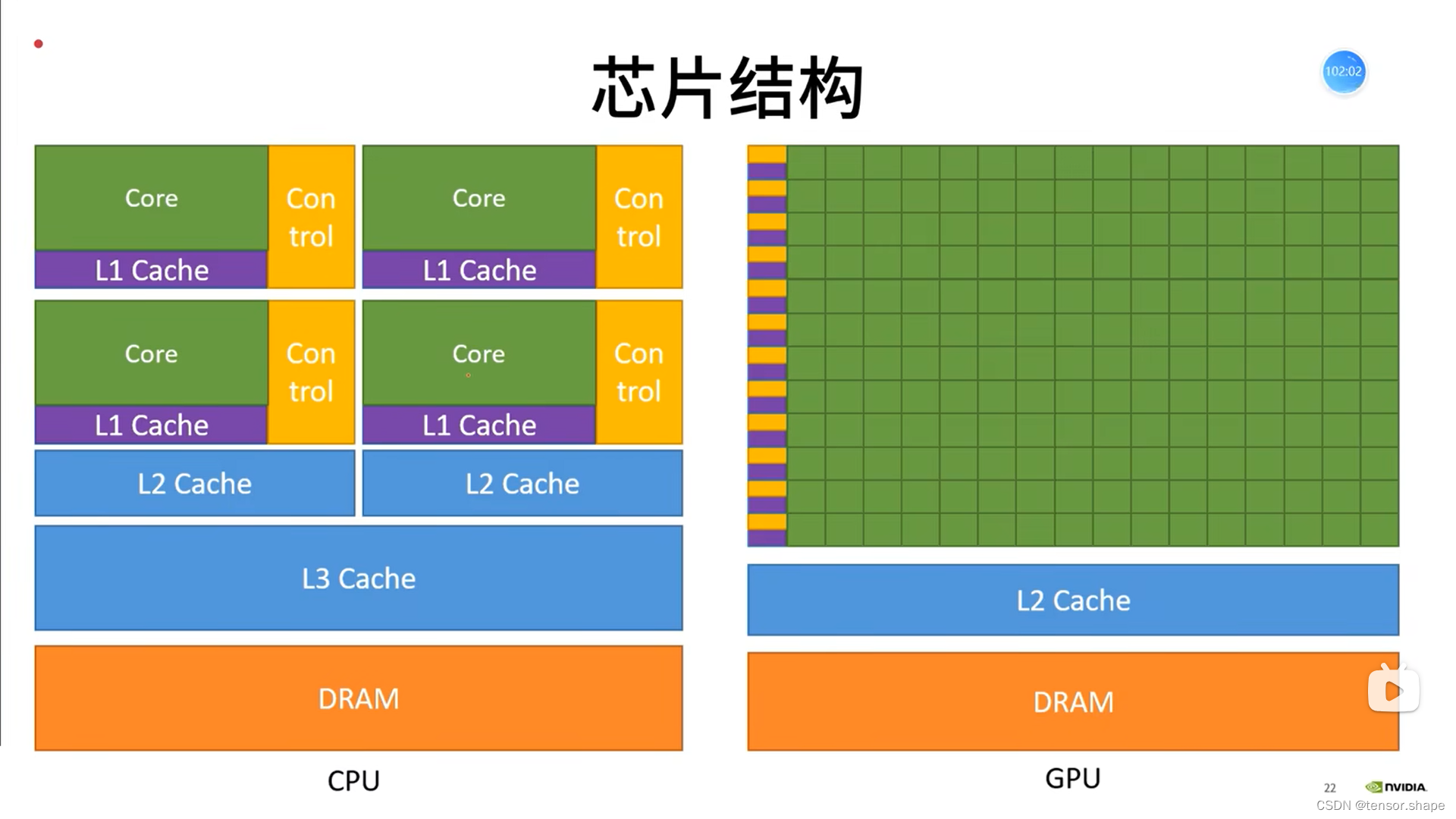
1+…+100,CPU是串行执行,GPU是分成几部分同时计算,如1+2+3,4+5+6…
2、培训002
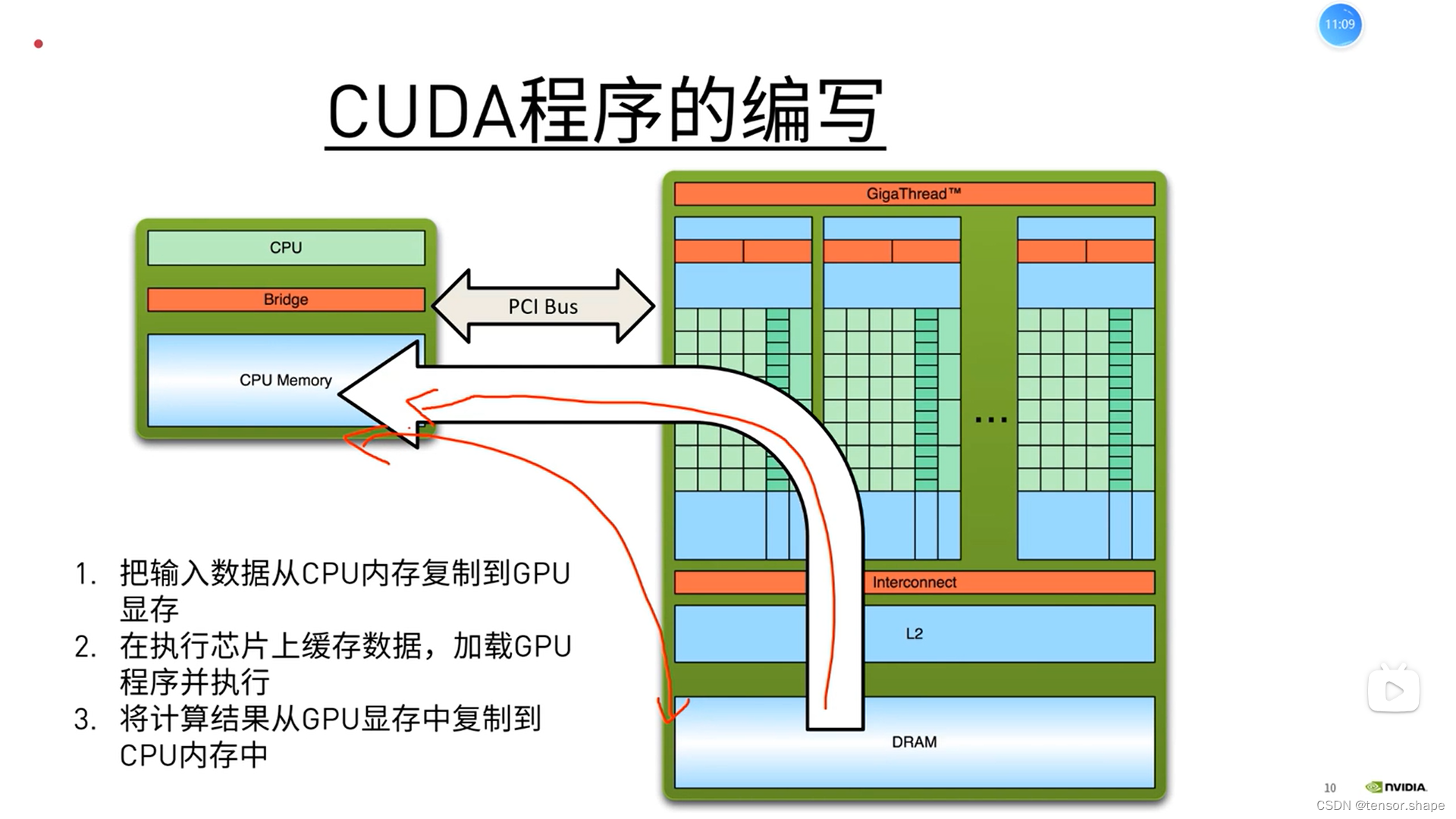
一来一回
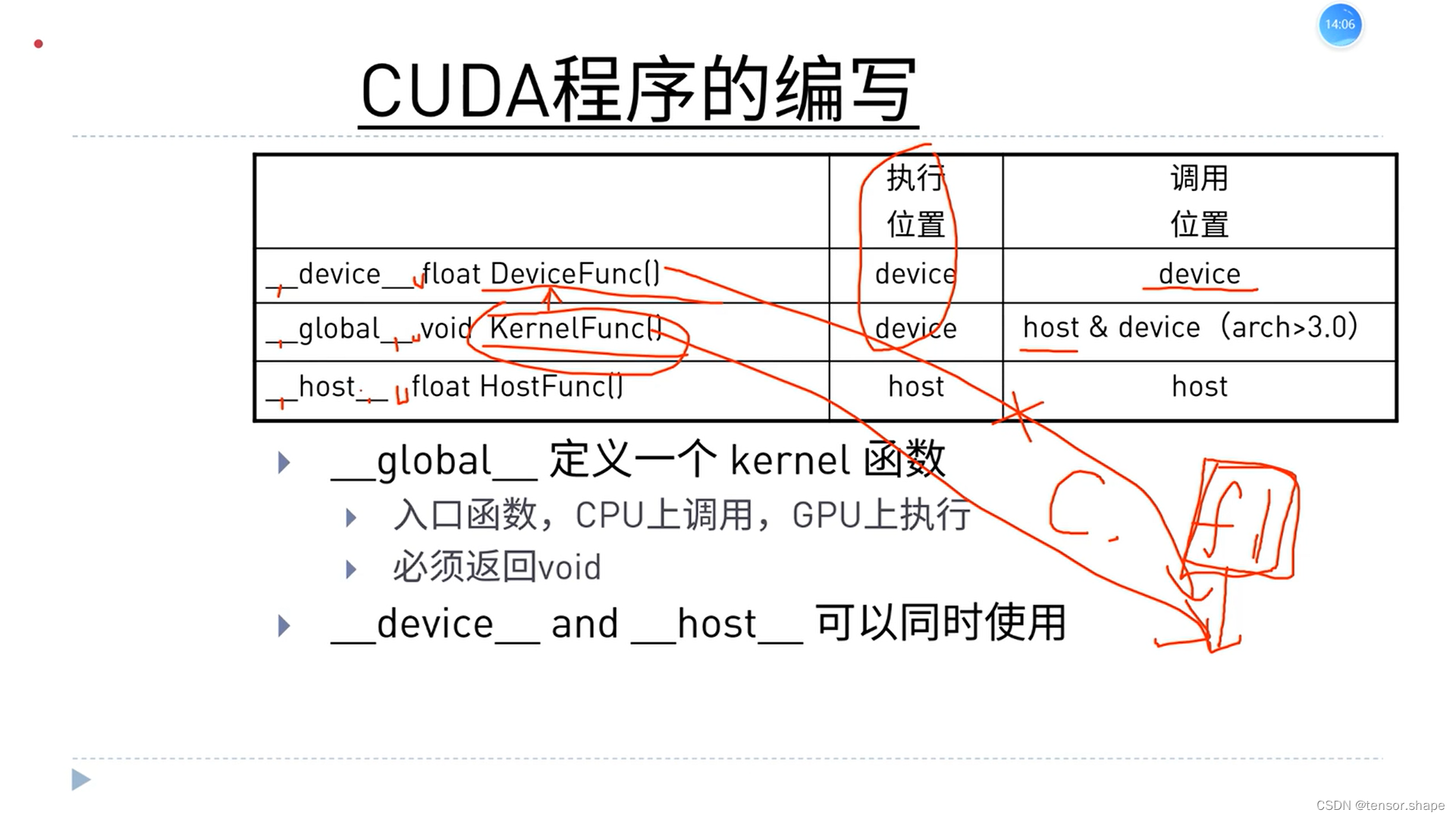
每种定义有对应的调用位置,和执行位置,不对会报错。

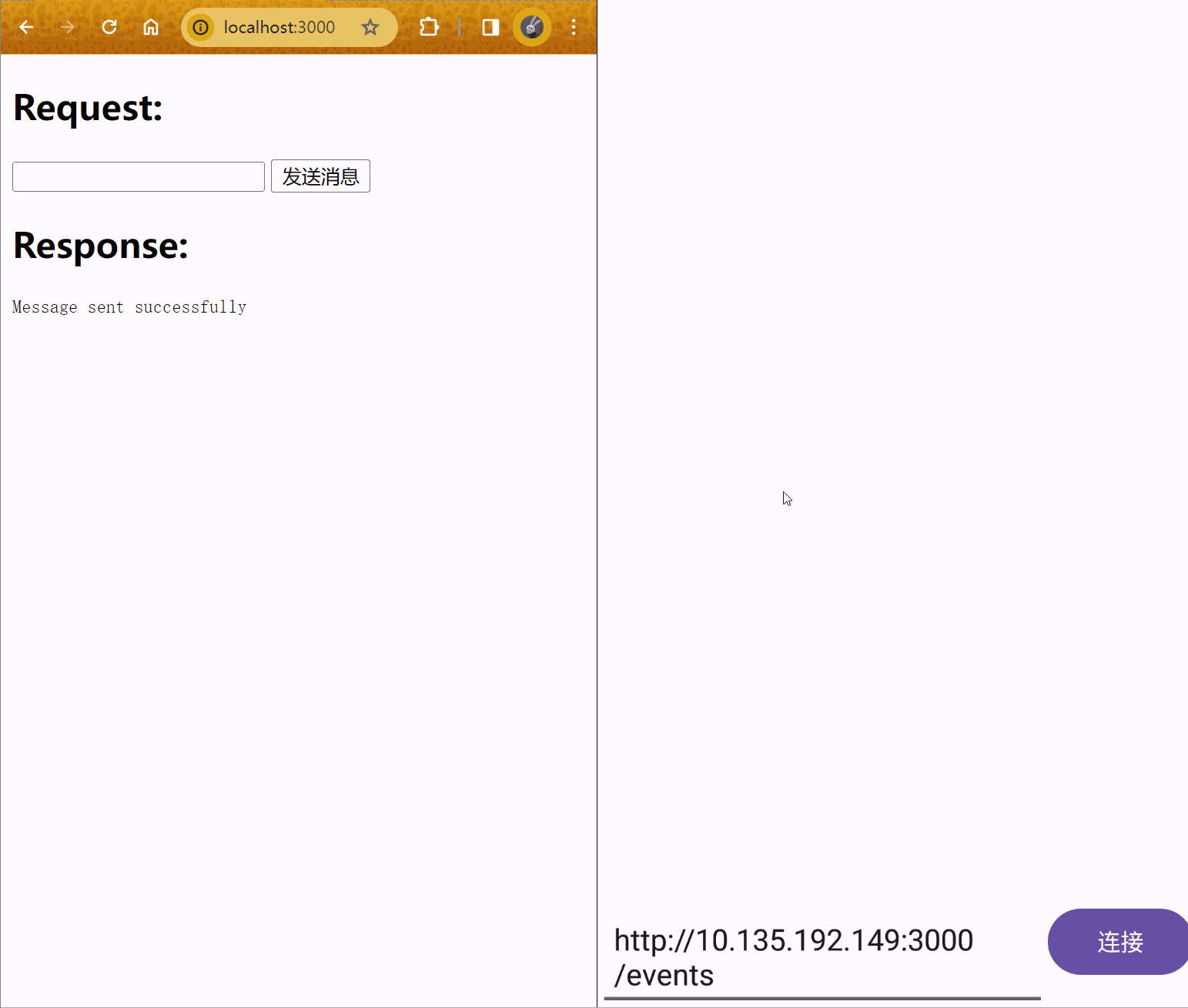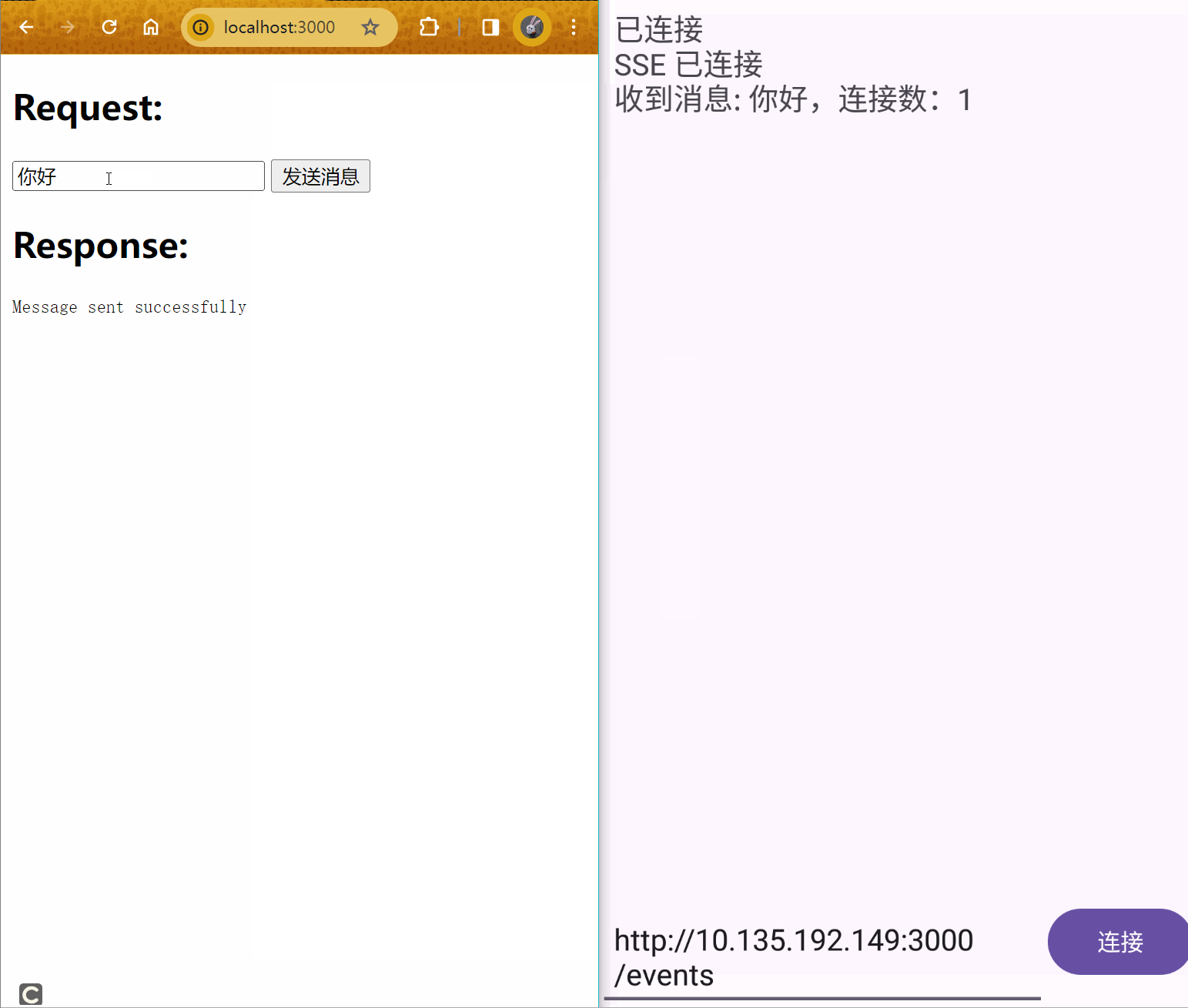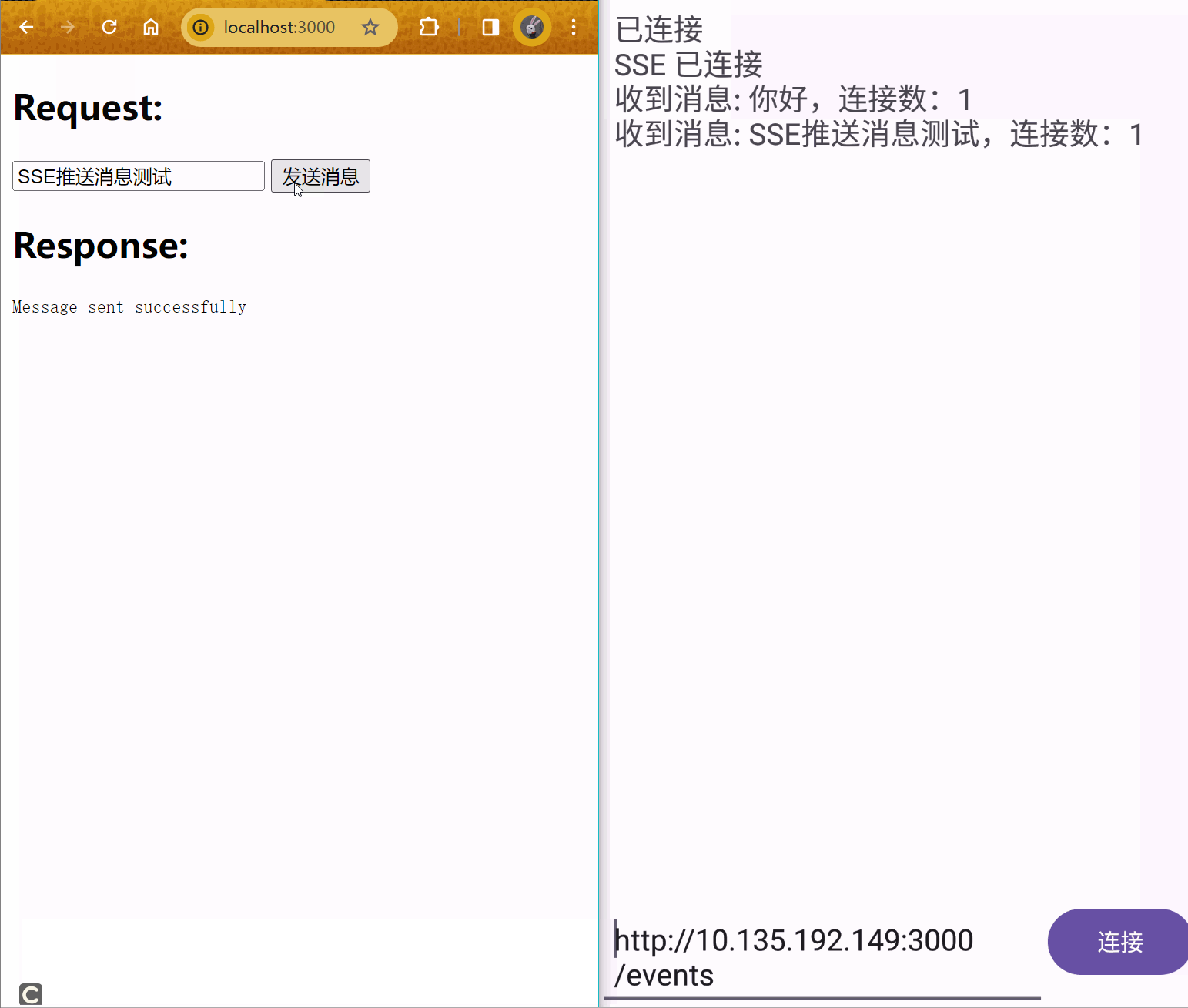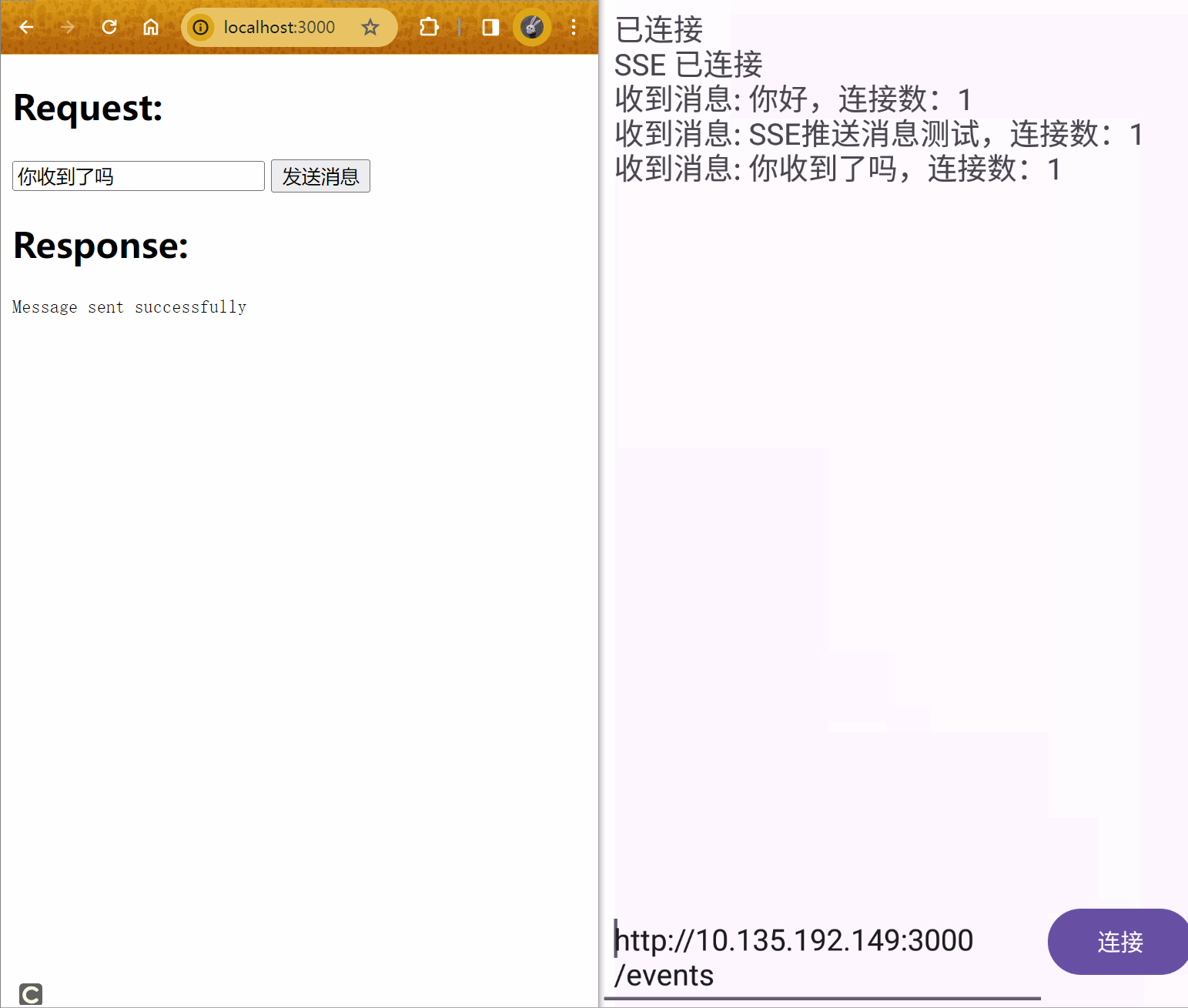
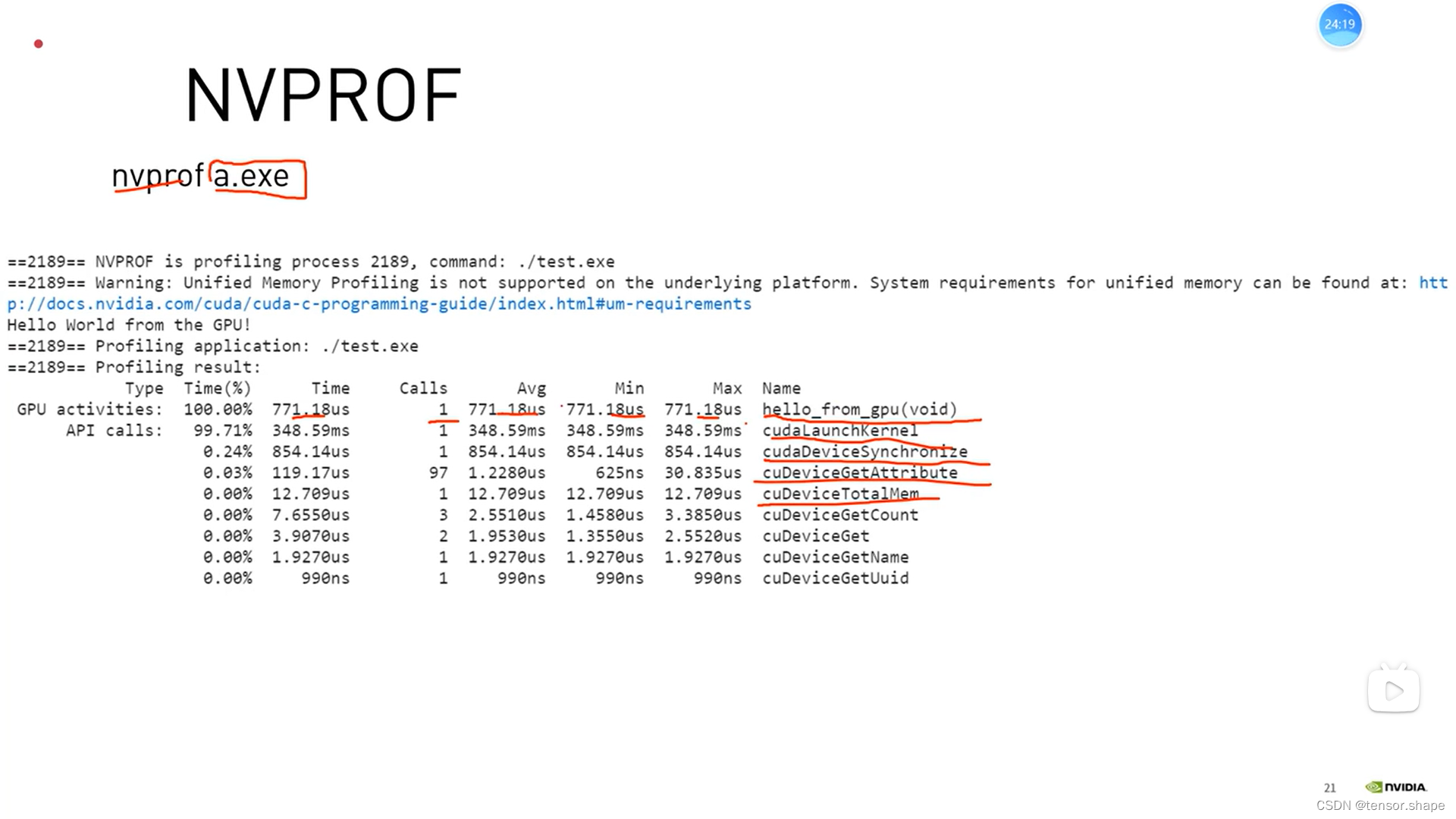
下图是用NVPROF时间分析
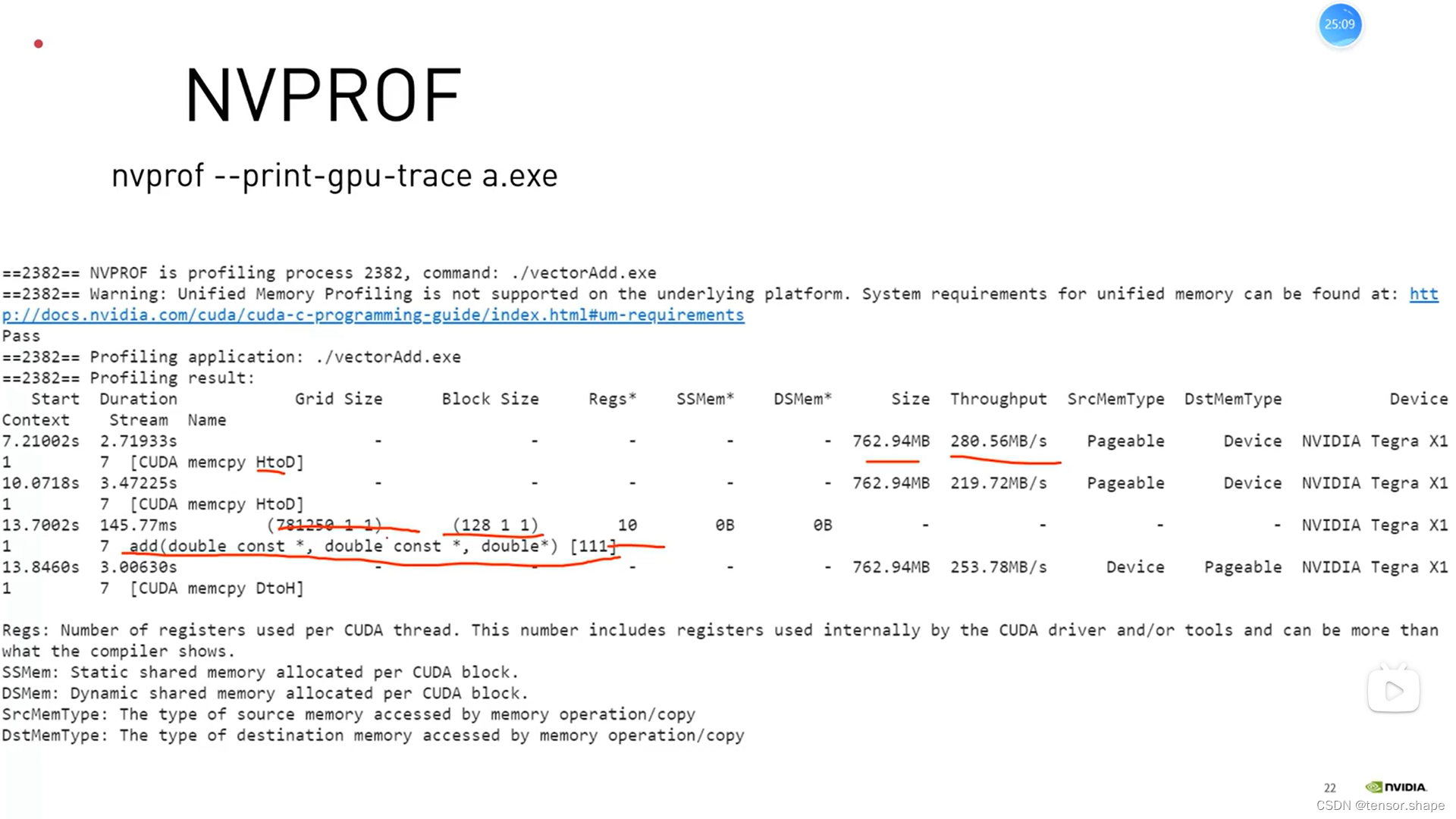
下图是资源分析
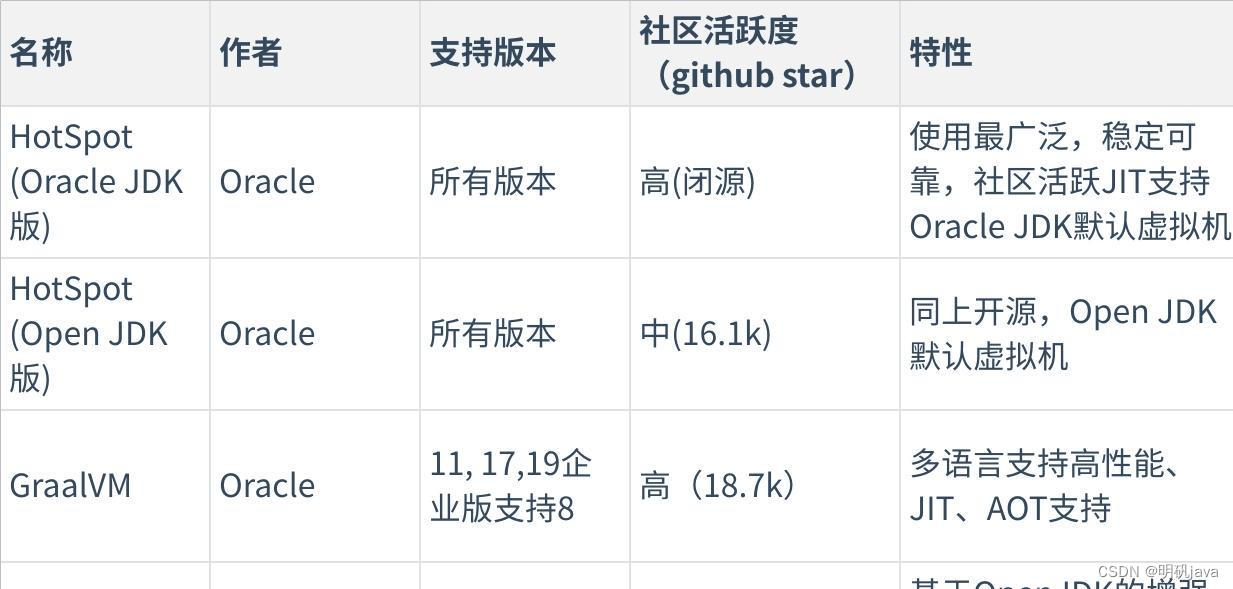
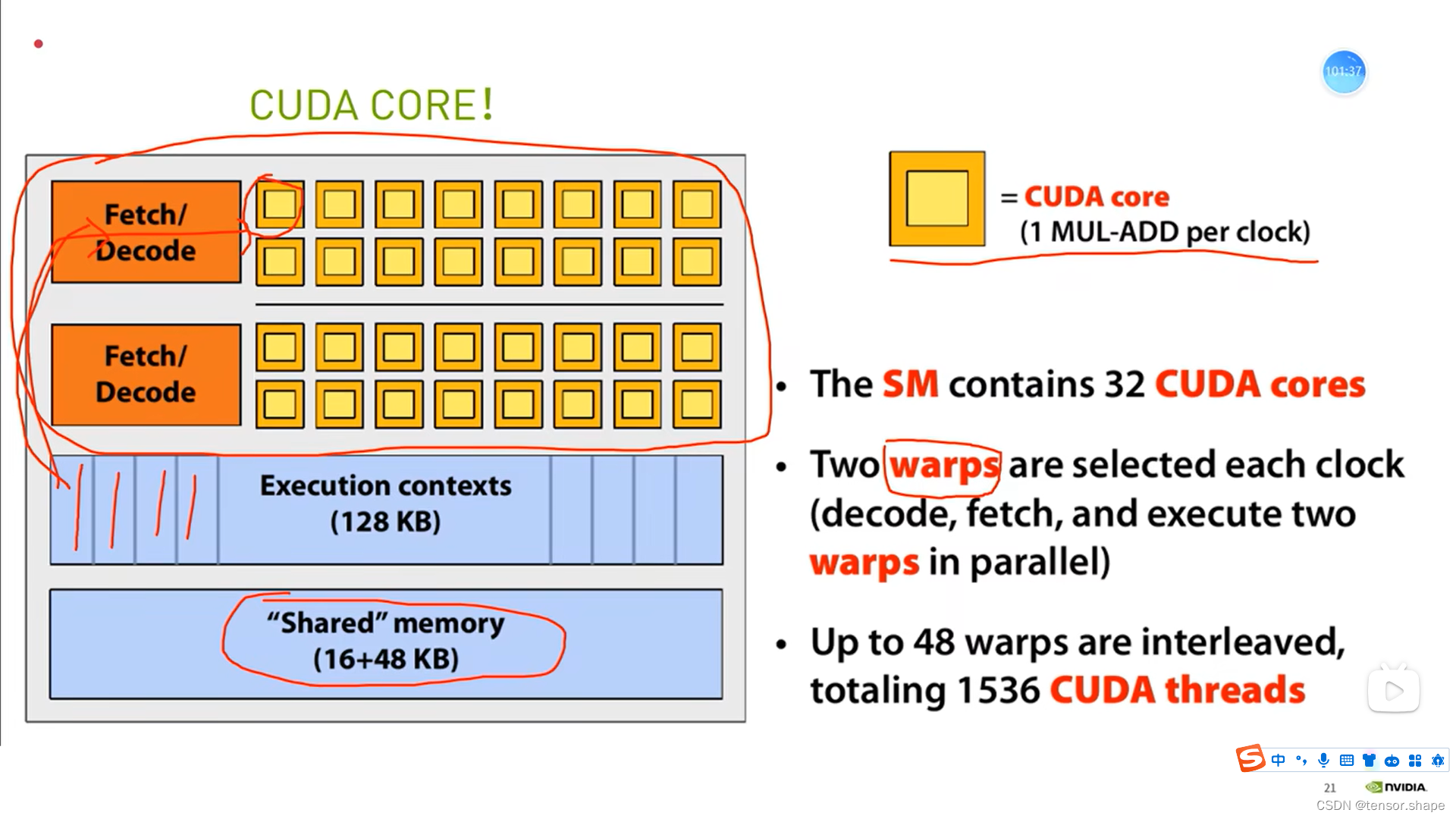
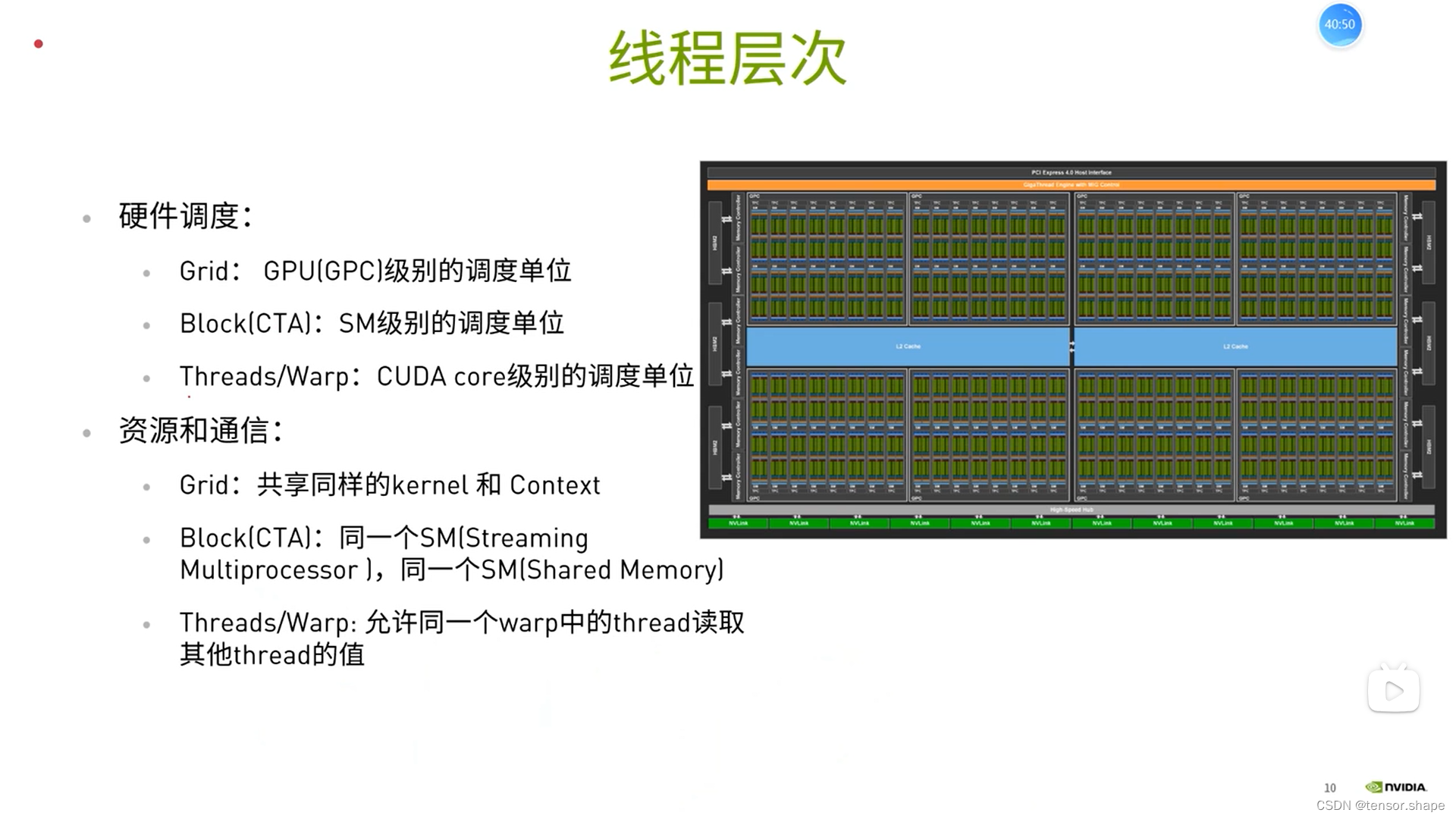
1) CUDA线程层次

一个SM执行多个block

所有线程执行同一个kernel,每个线程处理的数据不一样
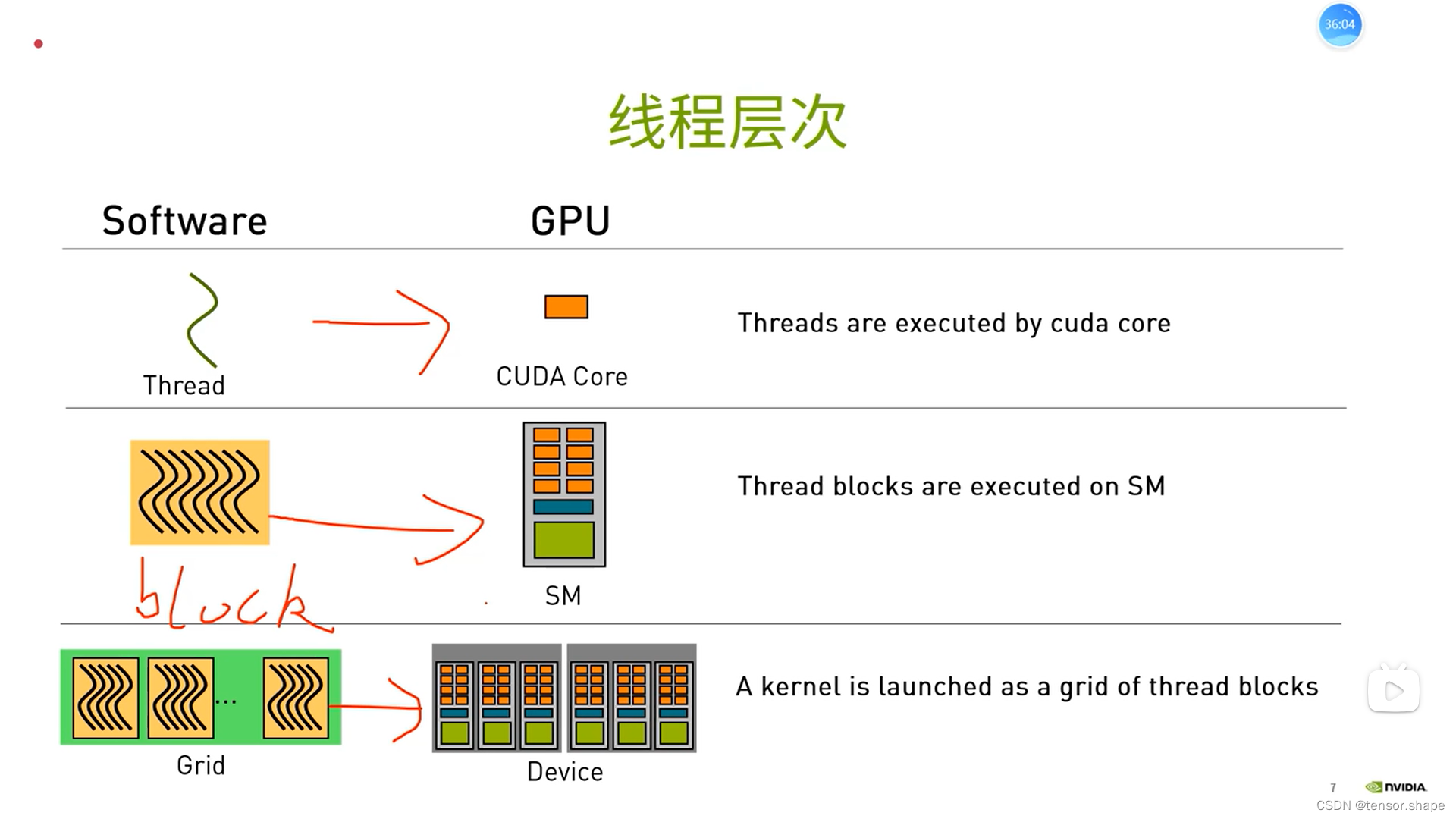
线程在cuda core里面,block以块为单位分配到sm中,grid在device中

如图描述的是:9个block分给3个sm
这张ppt的流程与下面这个图其实是一回事
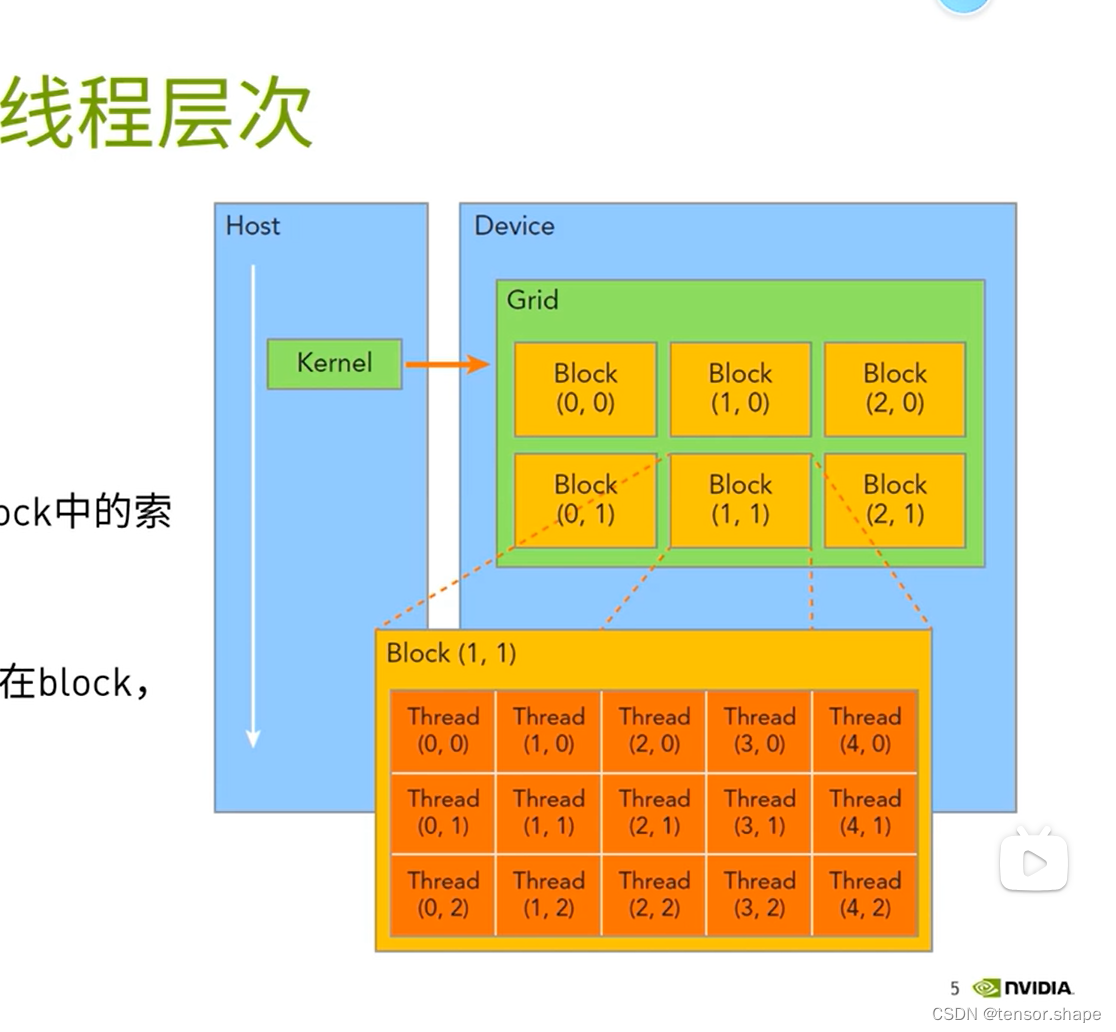

理由:层层分级便于管理,和企业或government管理有点相似。还有个协作,通过共享内存使thread block协作。
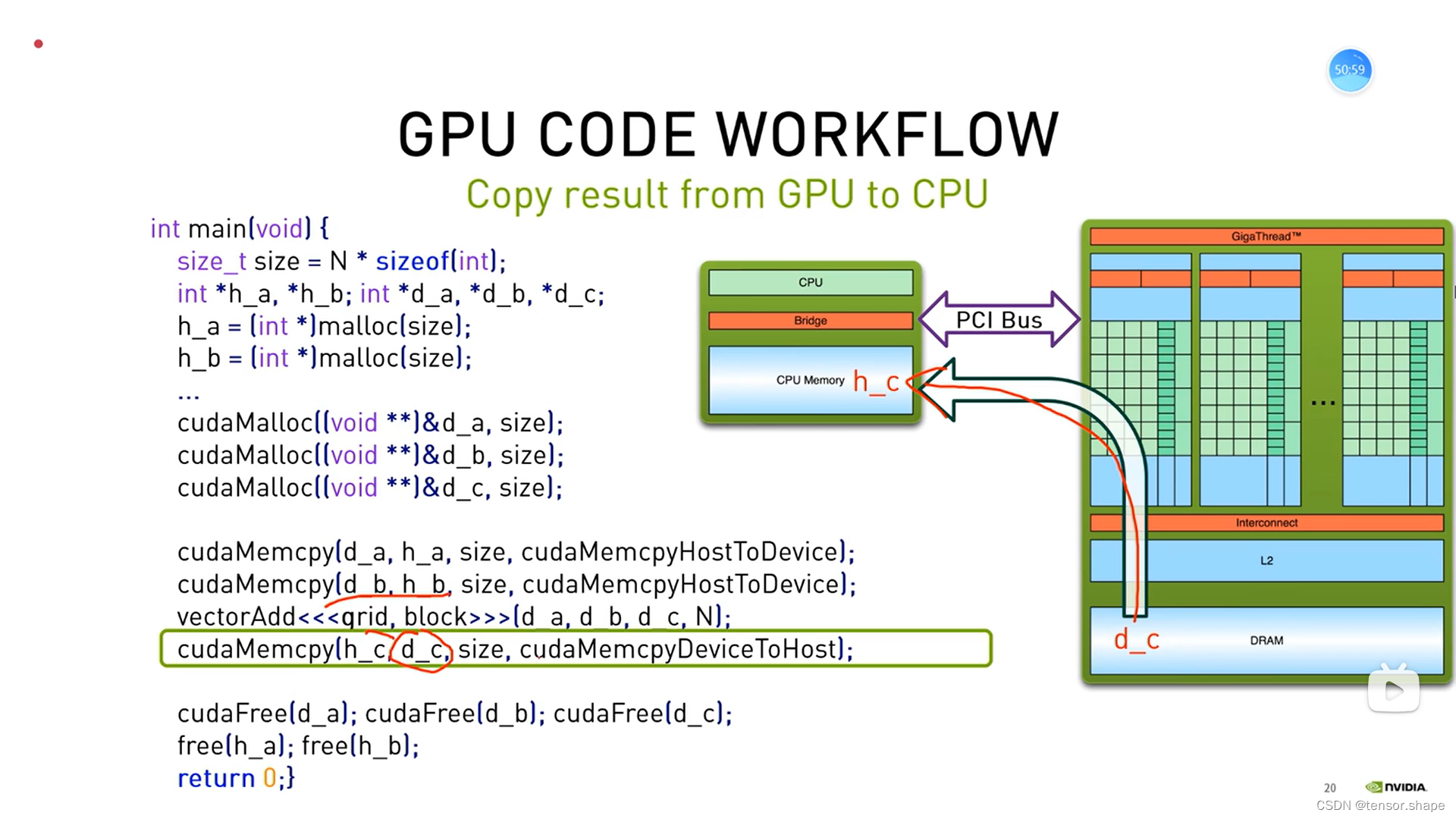
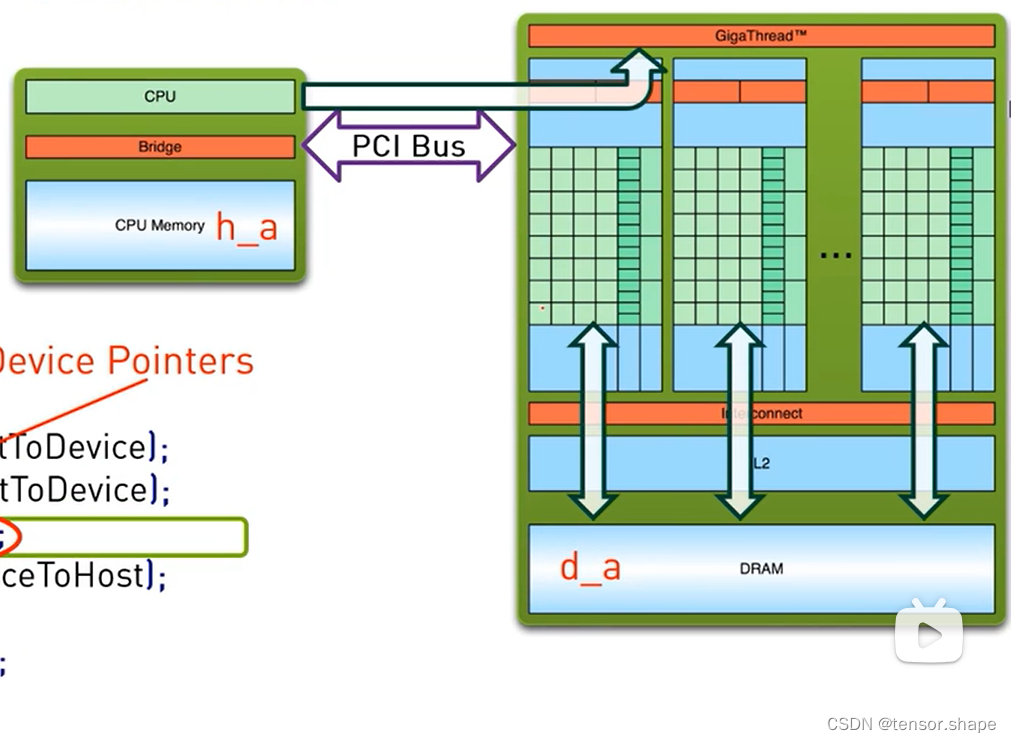
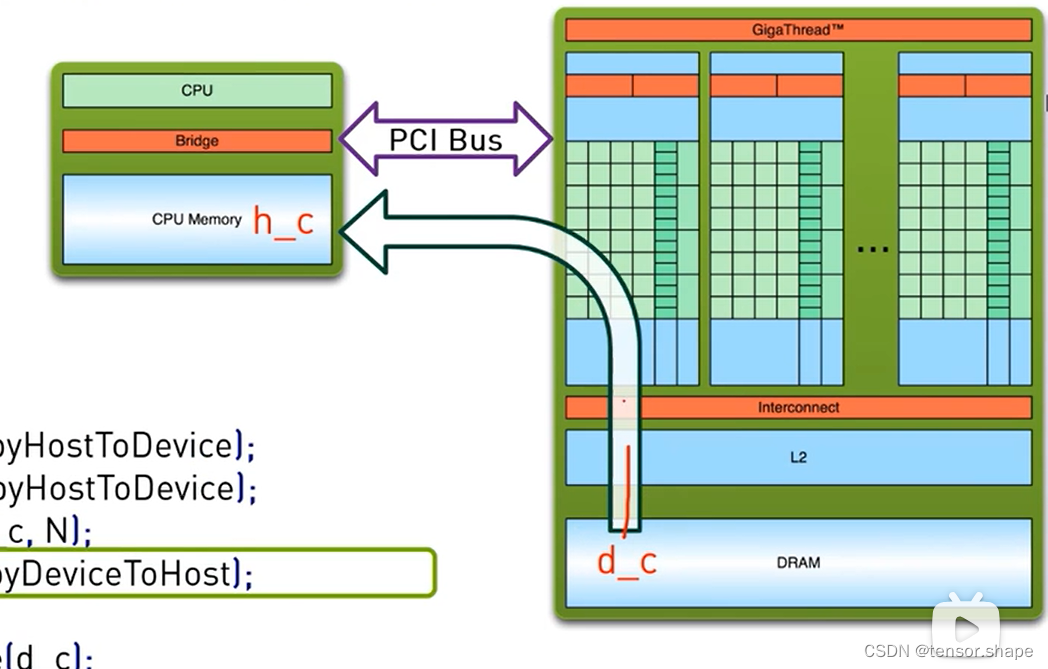
h_a,h_b指CPU的变量,d_a等指GPU的变量,申请各自的空间。
使用cudaMemcpy函数将cpu的变量传给gpu,然后使用kernel函数计算。
然后将结果送回去给CPU,最后释放
第一步
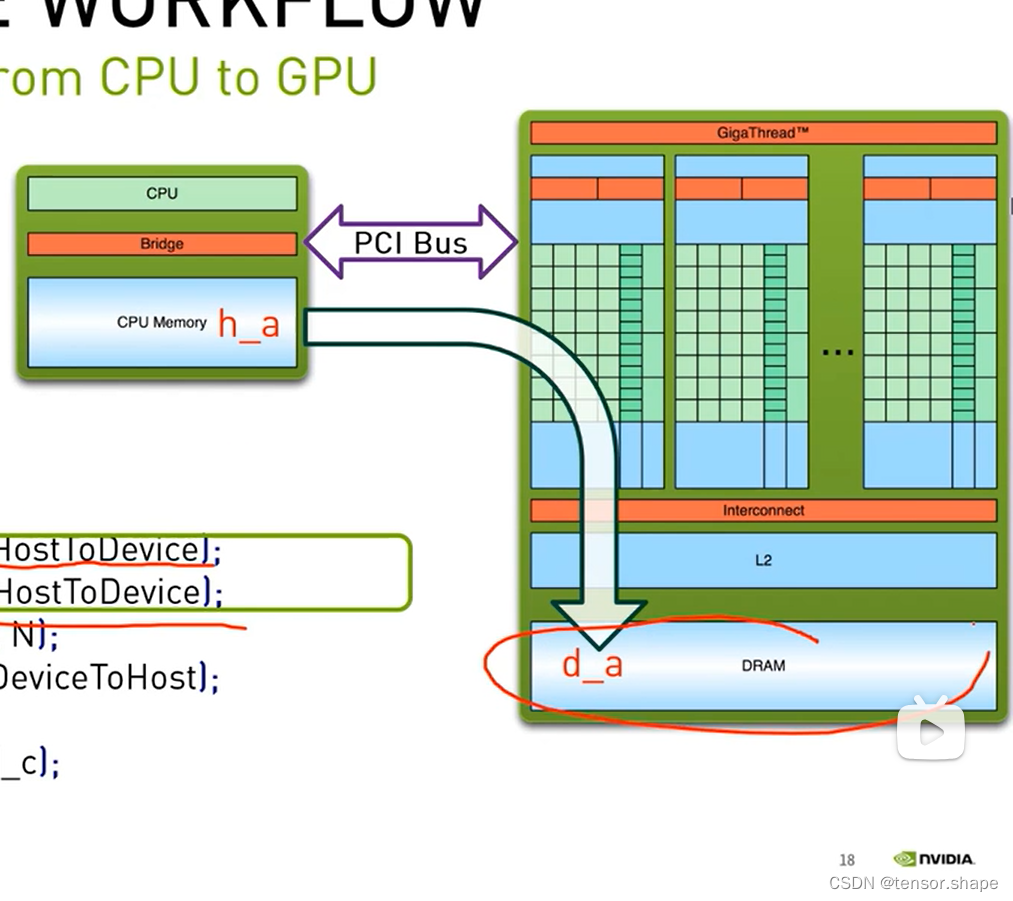
第二步,还有个步骤是,cpu通过giga thread将block分配给sm中
第三步
2)CUDA线程索引
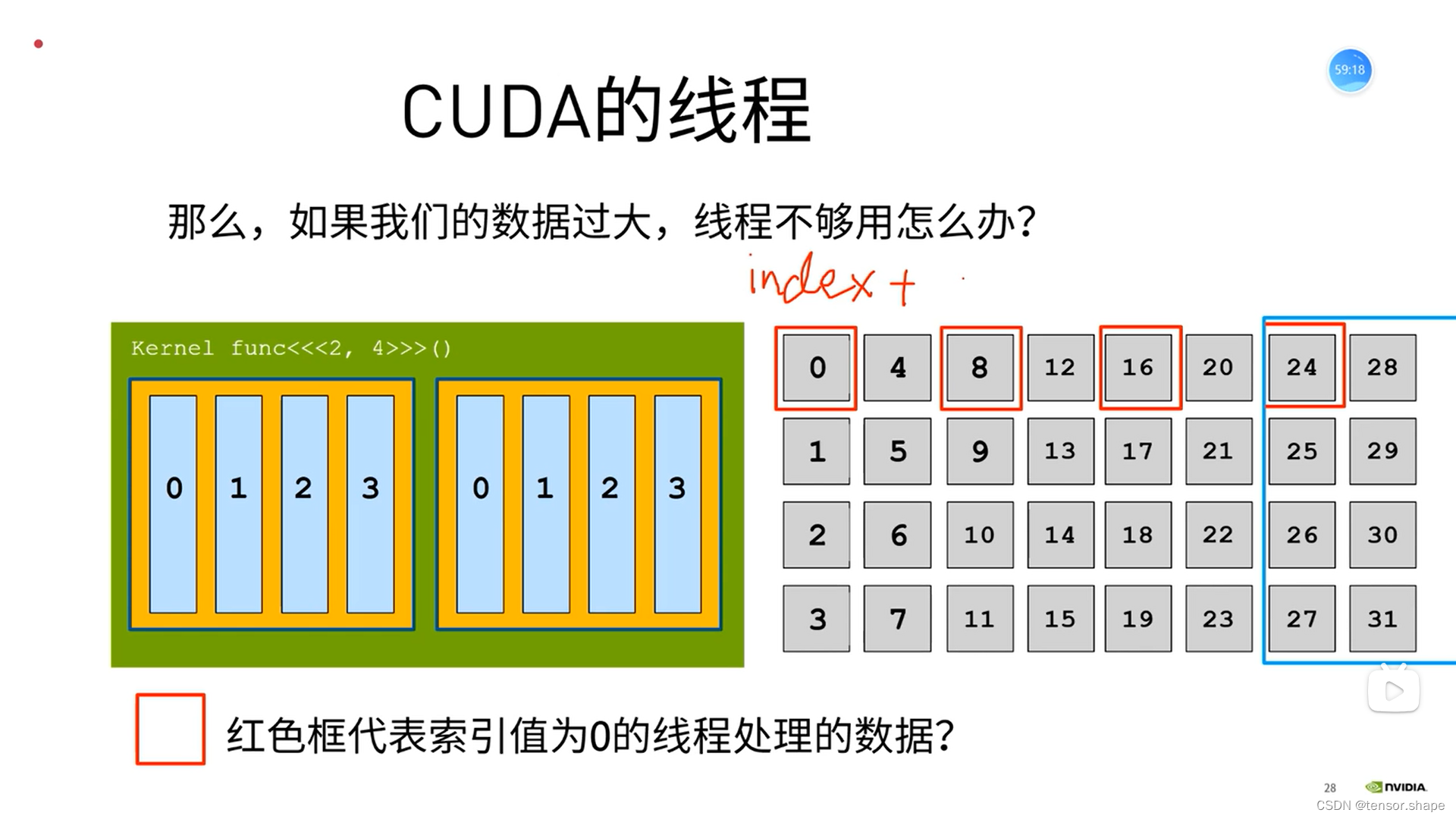
设置多大?没有规矩,要通过实验!!!
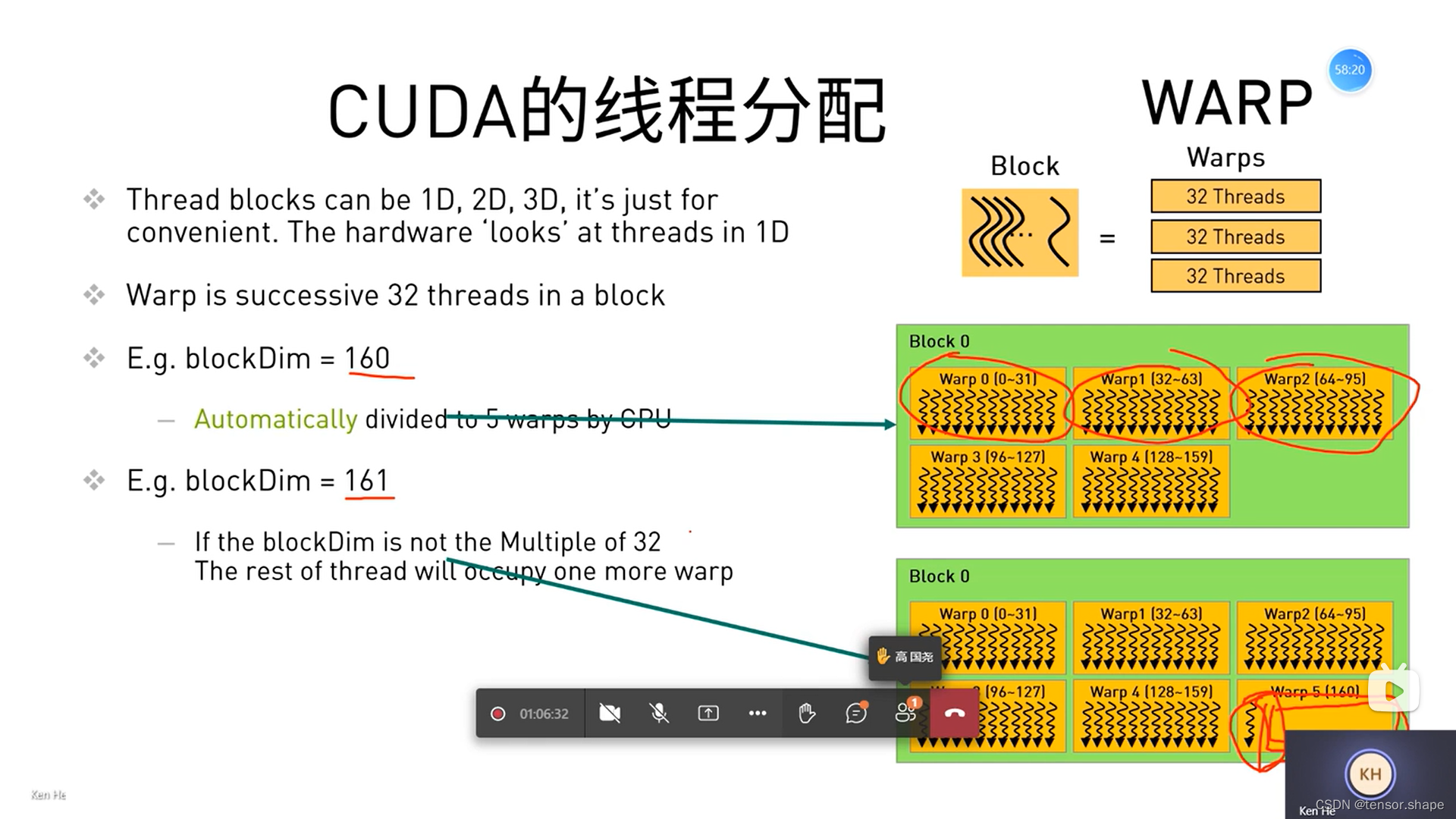
3)CUDA线程分配

每个线程块的xyz维度最大申请1024,1024,64

参考链接:https://www.bilibili.com/video/BV1dq4y1k7RD?p=1《NVIDIA-CUDA-冬令营》