目录
前言
相关链接
摘要
方法
效果展示
为各种角色制作动画
比较
更多应用
前言
2024年一开年,社交媒体和朋友圈就被一系列惊艳舞蹈视频占领了。钢铁侠跳起了科目三,马斯克也在摆着网红舞步,这些大约10秒的视频都是借助大模型技术制作的,轻松让任何人或角色变成舞蹈达人,掀起了一阵斗舞狂潮。
2023年11月以来,阿里发布了Animate Anyone,只需一张人物照片,结合骨骼动画,就能生成人体动画视频。这个让图片动起来的创新工具在Twitter和YouTube上相关视频的播放量都突破了1亿次,而且在GitHub上的关注度也飙升,超过了1万Star。


相关链接
论文链接:https://arxiv.org/pdf/2311.17117.pdf
项目链接:https://humanaigc.github.io/animate-anyone
体验地址:https://huggingface.co/spaces/HumanAIGC/OutfitAnyone
摘要
角色动画旨在通过驱动信号从静止图像生成角色视频。目前,扩散模型因其强大的生成能力已成为视觉生成研究的主流。然而,图像到视频领域仍然存在挑战,特别是在角色动画中,暂时保持与角色详细信息的一致性仍然是一个艰巨的问题。在本文中,我们利用扩散模型的力量,提出了一个为角色动画量身定制的新颖框架。为了保持参考图像中复杂外观特征的一致性,Animate Anyone设计了 ReferenceNet 通过空间注意力来合并细节特征。为了确保可控性和连续性,我们引入了高效的姿势引导器来指导角色的运动,并采用有效的时间建模方法来确保视频帧之间平滑的帧间过渡。通过扩展训练数据,我们的方法可以对任意角色进行动画处理,与其他图像到视频方法相比,在角色动画方面产生更好的结果。此外,我们还根据时尚视频和人类舞蹈合成的基准评估了我们的方法,取得了最先进的结果。

方法
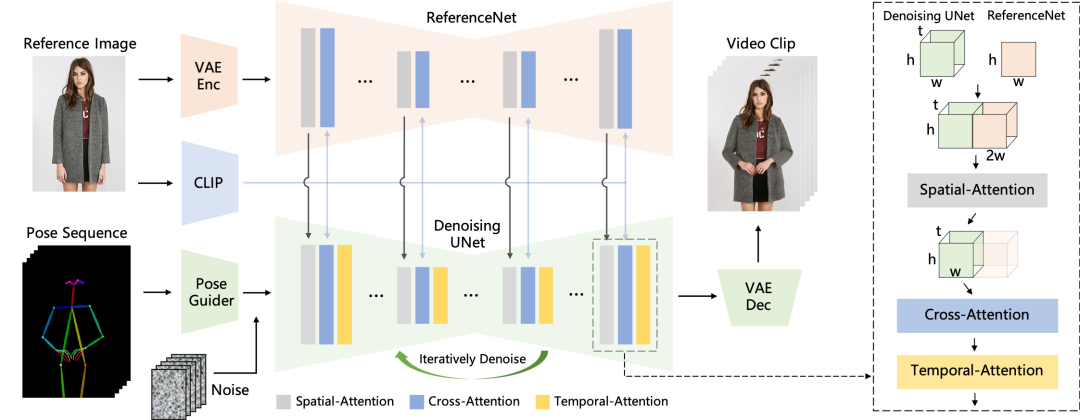
方法概述:姿势序列最初使用 Pose Guider 进行编码,并与多帧噪声融合,然后由 Denoising UNet 进行视频生成的去噪过程。Denoising UNet 的计算模块由 Spatial-Attention、Cross-Attention 和 Temporal-Attention 组成,如右侧虚线框所示。参考图像的集成涉及两个方面。首先,通过ReferenceNet提取详细特征并用于空间注意力。其次,通过CLIP图像编码器提取语义特征进行交叉注意力。时间注意力在时间维度上运作。最后,VAE解码器将结果解码为视频剪辑。
效果展示
为各种角色制作动画
人类


人形

动漫/卡通
结合Animate Anyone技术,AI动漫人物绘画生成的门槛被大大降低,让普通人也能轻松创作出多样化的动漫角色。用户可以根据自己的偏好,自由搭配角色的面部、服装、配饰和背景,创造出具有个性和魅力的二次元角色。

与之前工作效果比较
时尚视频合成

时尚视频合成旨在使用驾驶姿势序列将时尚照片变成逼真的动画视频。使用相同的训练数据在 UBC 时尚视频数据集上进行实验。
人类舞蹈生成

Human Dance Generation 专注于在现实世界的舞蹈场景中制作动画图像。使用相同的训练数据在 TikTok 数据集上进行实验。
更多应用
结合在上篇博客中介绍的虚拟试衣间Outfit Anyone搭配上Animate Anyone,这款虚拟试衣间技术不仅使得个性化服装搭配变得易如反掌,这也意味着无论你是谁,无论你喜欢的风格如何,都可以找到适合你的虚拟试穿体验。而且它还能适应各种体型,从健身型到曲线型,甚至是娇小型,让每个人都能在这个虚拟试衣间找到适合自己的特色风格。


适合任何服装和任何人的超高质量虚拟试穿
有兴趣的小伙伴快去体验一下吧,感谢你看到这里,也欢迎关注我的个人公众号:小白学AIGC,一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、Stable Diffusion等相关技术。