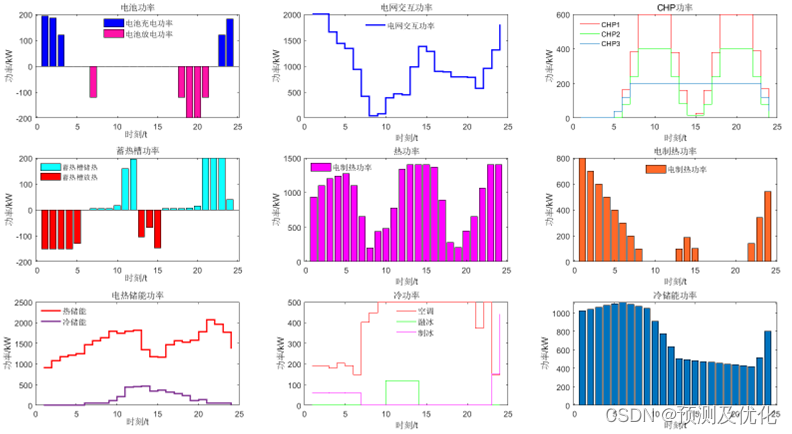
- 流处理基础概念(一):Dataflow 编程基础、并行流处理
- 流处理基础概念(二):时间语义(处理时间、事件时间、水位线)
- 流处理基础概念(三):状态和一致性模型(任务故障、结果保障)
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 💖💖💖 将激励 🔥 博主输出更多优质内容!!!
流处理基础概念(二):时间语义
- 1.流处理场景下一分钟的含义
- 2.处理时间
- 3.事件时间
- 4.水位线
- 5.处理时间与事件时间
本篇博客,我们将介绍流式场景中时间语义和不同的时间概念。我们将讨论流处理引擎如何基于乱序事件产生精确结果,以及如何使用数据流进行历史事件处理并实现 时间旅行。
1.流处理场景下一分钟的含义
当处理一个持续到达且可能无穷的事件流时,时间便成了应用中最为核心的要素。假如你想持续计算结果,比如每分钟计算一次,那么一分钟在流式应用环境中的含义到底是什么?
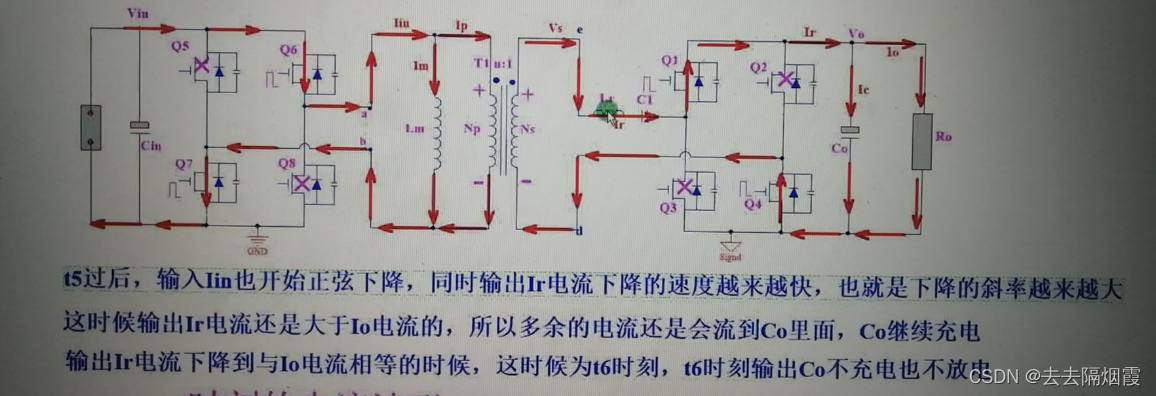
假设有某个应用程序会分析用户玩在线手游时产生的事件。该应用将用户组织成不同团队,并会收集每个团队的活动信息,这样就能基于团队成员完成游戏目标的速度,提供诸如额外生命或等级提升的游戏奖励(例如,如果团队所有成员在一分钟内消除了 500 个泡泡,他们就会提升一级)。皮皮是个铁杆玩家,每天早晨上班路上都会玩这个游戏。但是有个问题:皮皮住在上海,每天乘地铁上班。而众所周知,上海地铁上手机上网信号很差。因此考虑如下情况:皮皮开始消泡泡的时候手机还能联网向分析应用发送事件,突然地铁开进隧道,手机断网了。皮皮继续玩他的,此时游戏产生的事件会缓存在手机里。在地铁离开隧道,皮皮重新上线后,之前缓存的事件才会发送给应用。此时应用该怎么办呢?在上述示例中,一分钟的含义又是什么?需要把皮皮离线的时间考虑在内吗?

当地铁进入隧道断网时,应用接收游戏事件会中断一会儿,此时事件会缓存在玩家手机中,并在网络恢复后发出。
在线游戏这个简单场景展示了算子语义应该依赖事件实际发生时间,而非应用收到事件的时间。在这个手游例子中,后果可能非常糟糕,以至于皮皮和他团队的其他玩家失望透底,再也不想碰这个游戏。但其实还有更多时间敏感应用,需要我们对其处理语义进行保障。如果我们仅考虑现实时间一分钟内收到多少数据,那结果可能会随网络连接速度或处理速度而改变,而事实上每分钟收到的事件数目是由数据本身的时间来定义的。
在上面的例子中,流式应用可以使用两个不同概念的时间,即 处理时间(processing time)和 事件时间(event time)。
2.处理时间
处理时间是当前流处理算子所在机器上的本地时钟时间。基于处理时间的窗口会包含那些恰好在一段时间内到达窗口算子的事件,这里的时间段是按照机器时间测量的。如下图所示,在上述皮皮的例子中,处理时间窗口在他手机离线后会继续计时,因此不会把他离线那段时间的活动考虑在内。

3.事件时间
事件时间是数据流中事件实际发生的时间,它以附加在数据流中事件的时间戳为依据。这些时间戳通常在事件数据进入流处理管道之前就存在(例如事件的生成时间)。如下图所示,即便事件有延迟,事件时间窗口也能准确的将事件分配到窗口中,从而反映出真实发生的情况。

事件时间将处理速度和结果内容彻底解耦。基于事件时间的操作是可预测的,其结果具有确定性。无论数据流的处理速度如何、事件到达算子的顺序怎样,基于事件时间的窗口都会生成同样的结果。
使用事件时间要克服的挑战之一是如何处理延迟事件。普遍存在的无序问题也可以借此解决。
依靠事件时间,我们可以保证在数据乱序的情况下结果依然正确,而且结合可重放的数据流,时间戳所带来的确定性允许你对历史数据 “快进”。这意味着你可以通过重放数据流来分析历史数据,就如同它们是实时产生的一样。
此外,你可以把计算 “快进” 到现在,这样一旦你的程序赶上了当前事件产生的进度,它能够以完全相同的程序逻辑作为实时应用继续运行。
4.水位线
在到目前为止有关事件时间窗口的讨论中,我们一直忽略了一个非常重要的方面。怎样决定事件时间窗口的触发机制?换言之,我们需要等多久才能确定已经收到了所有发生在某个特定时间点之前的事件?此外,我们如何得知数据会产生延迟?鉴于分布式系统现实的不确定性以及外部组件可能引发任意延迟,这两个问题都没有完美的答案。我们将了解如何利用水位线(Watermarks)来设定事件时间窗口的行为。
水位线是一个全局进度指标,表示我们确信不会再有延迟事件到来的某个时间点。本质上,水位线提供了一个逻辑时钟,用来通知系统当前的事件时间。当一个算子接收到时间为 T 的水位线,就可以认为不会再收到任何时间戳小于或等于 T 的事件了。水位线无论对于事件时间窗口还是处理乱序事件的算子都很关键。算子一旦收到某个水位线,就相当于接收到信号:某个特定时间区间的时间戳已经到齐,可以触发窗口计算或对接收的数据进行排序了。
水位线允许我们在结果的 准确性 和 延迟 之间做出取舍。激进的水位线策略保证了低延迟,但随之而来的是低可信度。该情况下,延迟事件可能会在水位线之后到来,我们必须额外加一些代码来处理它们。反之,如果水位线过于保守,虽然可信度得以保证,但可能会无谓地增加处理延迟。
在很多现实应用中,系统无法获取足够多的信息来完美地确定水位线。以手游场景为例,现实中根本无法得知用户会离线多久。他们可能正在过隧道,可能正在上飞机,也可能直接退坑不玩了。无论水位线是由用户定义还是自动生成,只要存在 “拖后腿” 的任务,追踪分布式系统中的全局进度就可能出现问题。因此简单地依赖水位线并不总是可以高枕无忧。而流处理系统很关键的一点是能够提供某些机制来处理那些可能晚于水位线的迟到事件。根据应用需求的不同,你可能想直接忽略这些事件,将他们写入日志或利用他们去修正之前的结果。
5.处理时间与事件时间
此刻你可能心存疑惑:既然事件时间能够解决所有问题,为何还要去关心处理时间?事实上,处理时间的确有其特定的适用场景。处理时间窗口能够将延迟降至最低,由于无需考虑迟到或乱序的事件,窗口只需简单地缓冲事件,然后在达到特定时间后立即触发窗口计算即可。因此对于那些更重视处理速度而非准确度的应用,处理时间就会派上用场。另一种情况是,你需要周期性地实时报告结果,而无论其准确性如何。一个常见示例应用是实时监控仪表盘,它会接收并展示事件聚合结果。最后,处理时间窗口能够表示数据流自身的真实情况,这可能会在某些用例中派上用场。例如,你可能想观察数据流的接入情况,通过计算每秒事件数来检测数据中断。
总而言之,虽然处理时间提供了很低的延迟,但它的结果依赖处理速度具有不确定性,事件时间则与之相反,能保证结果的准确性,并允许你处理延迟甚至无序的事件。