作者:庄宇
在现代的软件开发和数据处理领域,批处理作业(Batch)扮演着重要的角色。它们通常用于数据处理,仿真计算,科学计算等领域,往往需要大规模的计算资源。随着云计算的兴起,阿里云批量计算和 AWS Batch 等云服务提供了管理和运行这些批处理作业的平台。
随着云原生和 Kubernetes 生态的发展,越来越多的应用运行在 Kubernetes 之上,例如在线应用,中间件,数据库。那对离线任务和批量计算是否可以在 Kubernetes 这个统一平台之上运行,答案是肯定的,分布式工作流 Argo 集群 [ 1] ,基于开源 Argo Workflows [ 2] 项目,完全符合开源工作流标准,可以编排和运行离线任务和批量计算,并使用 Serverless 方式运行,降低运维复杂度,节省运行成本。
通过分布式工作流 Argo 集群,您可以轻松编排工作流,每个工作流步骤使用容器运行,可以在短时间内轻松运行大规模机器学习、仿真计算和数据处理等计算密集型作业,也可以快速运行 CI/CD 流水线。

本文介绍主流 Batch 批量计算系统和分布式工作流 Argo 集群的区别,并讨论如何将离线任务和批量计算迁移到分布式工作流 Argo 集群。
Batch 批量计算的相关概念

作业(Jobs)
一个任务单元(例如 shell 脚本、Linux 可执行文件或 Docker 容器镜像),可以提交给 Batch 批量计算系统,批量计算系统会在计算环境中分配计算资源并运行作业。
Array Jobs
Array Job 是指一系列相似或相同的作业(Jobs),这些作业作为一个数组批量提交并运行。每一个作业都有相同的作业定义,但可以通过索引来区分,每个作业实例处理不同的数据集或执行稍有差异的任务。
作业定义(Job Definitions)
作业定义指定了作业的运行方式。运行作业前需要先创建作业定义。作业定义一般包含:作业运行所使用的镜像,具体命令与参数,需要的 CPU/Memory 资源,环境变量,磁盘存储等。
作业队列(Job Queues)
向 Batch 批量计算系统提交作业时,会提交到指定的作业队列中排队,直到被调度运行。作业队列可以设置优先级,并指定关联的计算环境。
计算环境(Compute Environment)
计算环境是一组计算资源,可以运行作业。对计算环境需要指定虚拟机的机型,环境的最小、最大 vCPU 数量,以及 Spot 竞价实例的价格。
总结
-
用户需要学习 Batch 批量计算作业定义规范与用法,有厂商绑定风险;
-
还需要管理计算环境,设置机型和规模等,非 Serverless 方式,运维高;
-
由于计算环境规模的限制,需要管理作业队列以设置作业的优先级,复杂度高。
分布式工作流 Argo 集群的相关概念
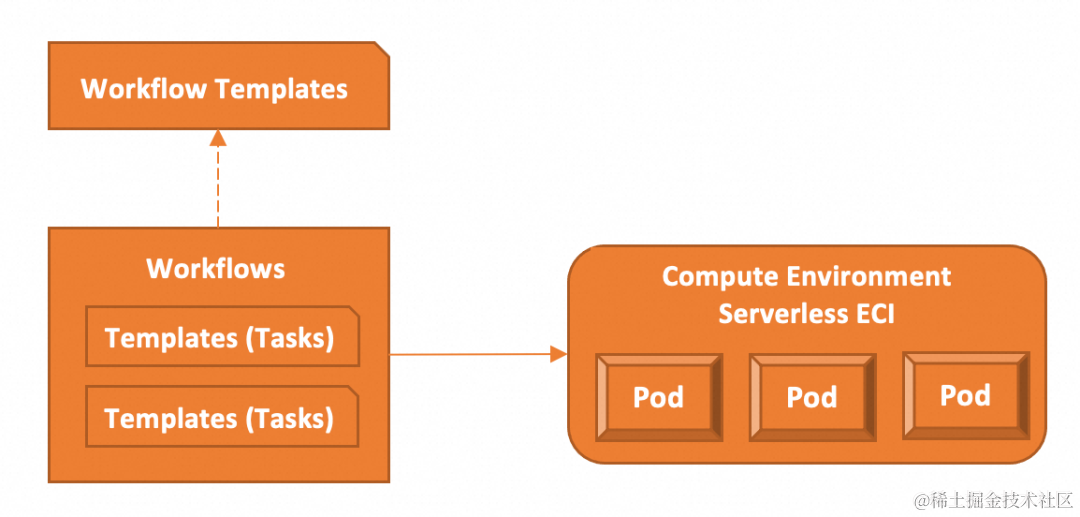
模版(Templates)
模版定义了一个任务(作业),是工作流的组成部分,一个工作流至少要包含一个模版。模版中包含要运行的 Kubernetes 容器和相应的输入输出参数。
工作流(Workflows)
工作流包含一个或者多个任务(模版),并可以编排多个任务,支持定义复杂的任务流程,如序列化、并行化任务,以及在条件满足时执行特定的任务。创建工作流后,工作流中的任务,会在 Kubernetes 集群中以 Pod 形式运行。
工作流模版(Workflow Templates)
工作流模版是可复用的工作流的静态定义,类似于函数,可以在多个工作流中被引用并运行。在定义复杂工作流时可以复用已有的工作流模版,减少重复性定义。
无服务器 Kubernetes 集群
分布式工作流 Argo 集群自带计算环境,不需要手工创建和管理。提交工作流后,使用阿里云弹性容器 ECI,以 Serverless 方式运行工作流中的任务,不需要维护 Kubernetes 节点。利用阿里云的弹性能力,可以运行大规模工作流(数万任务 Pod),同时使用数十万核 CPU 的算力资源,在工作流运行完成后自动释放资源。加快工作流运行速度,并节省计算成本。
总结
-
基于 Kubernetes 集群和开源 Argo Workflows 构建,以云原生的方式编排运行工作流,无厂商绑定风险;
-
复杂工作流任务的编排,可以应对数据处理、仿真计算,科学计算的复杂业务场景;
-
计算环境采用阿里云弹性容器 ECI,不需要维护节点;
-
大规模算力的按需使用,按量计费,避免工作流排队等待,提高效率,节省计算成本。
Batch 批量计算和 Argo 工作流功能映射
| 能力分类描述 | Batch批量计算 | Argo Workflows |
|---|---|---|
| 用户体验 | 批量计算CLI | Argo Workflows CLI |
| Json定义作业 | Yaml定义作业 | |
| SDK | SDK | |
| 核心能力 | 作业(Jobs) | 工作流(Workflows) |
| Array jobs | 工作流(Workflows)Loops | |
| Job dependencies | 工作流(Workflows)DAG | |
| Job Environments Variables | 工作流(Workflows)Parameters | |
| Automated Job retries | 工作流(Workflows)Retrying | |
| Job timeouts | 工作流(Workflows)Timeouts | |
| 无 | 工作流(Workflows)Artifacts | |
| 无 | 工作流(Workflows)Conditions | |
| 无 | 工作流(Workflows)Recursion | |
| 无 | 工作流(Workflows)Suspending/Resuming | |
| GPU jobs | 工作流(Workflows)指定GPU机型运行工作流 | |
| Volumes | Volumes | |
| Job priority | 工作流(Workflows)Priority | |
| 作业定义(JobDefinition) | 工作流模版(Workflows Templates) | |
| 计算环境 | Job queues | 无,云上Serverless弹性,作业无需排队 |
| 计算环境(Compute Environment) | 无服务器Kubernetes集群 | |
| 生态集成 | 事件驱动 | 事件驱动 |
| 可观察性 | 可观测性 |
Argo 工作流示例
简单工作流
cat > helloworld.yaml << EOF
apiVersion: argoproj.io/v1alpha1
kind: Workflow # new type of k8s spec
metadata:
generateName: hello-world- # name of the workflow spec
spec:
entrypoint: main # invoke the main template
templates:
- name: main # name of the template
container:
image: registry.cn-hangzhou.aliyuncs.com/acs/alpine:3.18-update
command: [ "sh", "-c" ]
args: [ "echo helloworld" ]
EOF
argo submit helloworld.yaml
在这个实例中,我们启动了一个任务 Pod,使用 alpine 镜像,运行 shell 命令 echo helloworld。在这个工作流基础上,可以在 args 中,指定多个 shell 命令并执行,也可以使用自定义镜像运行镜像中的命令。
Loops 工作流
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: loops-
spec:
entrypoint: loop-example
templates:
- name: loop-example
steps:
- - name: print-pet
template: print-pet
arguments:
parameters:
- name: job-index
value: "{{item}}"
withSequence: # loop to run print-pet template with parameter job-index 1 ~ 5 respectively.
start: "1"
end: "5"
- name: print-pet
inputs:
parameters:
- name: job-index
container:
image: acr-multiple-clusters-registry.cn-hangzhou.cr.aliyuncs.com/ack-multiple-clusters/print-pet
command: [/tmp/print-pet.sh]
args: ["{{inputs.parameters.job-index}}"] # input parameter job-index as args of container
在示例中,镜像 print-pet 中打包了 pets.input 文本文件和 print-pet.sh 脚本文件,print-pet.sh 以 job-index 为输入参数,打印 pets.input 文件行号为 job-index 的 pet。具体文件内容请访问 GitHub 仓库 [ 3] 。
在工作流中,会同时启动 5 个 Pod,并分别传入参数 job-index 1~5,每个 pod 根据输入的 job-index 的值,打印相应行的 pet。通过 Loops 工作流可以实现数据分片和并行处理,加快海量数据的处理速度。更多 Loops 示例可以参考工作流(Workflows)Loops [ 4] 。
DAG 工作流(MapReduce)
真实的批处理场景中,往往需要多个 Job 配合完成,所以需要指定 Job 间的依赖关系,DAG 是指定依赖关系的最佳方式。但主流的 Batch 批处理系统,需要通过 Job ID 指定 Job 依赖,由于 Job ID 需要在 Job 提交后才能获取,因此需要编写脚本实现 Job 间依赖(伪代码如下),Job 较多时依赖关系不直观维护代价高。
//Batch批处理系统Job间依赖,JobB 依赖 JobA,在JobA完成后运行。
batch submit JobA | get job-id
batch submit JobB --dependency job-id (JobA)
Argo 工作流可以通过 DAG 定义子任务间的依赖关系,示例如下:
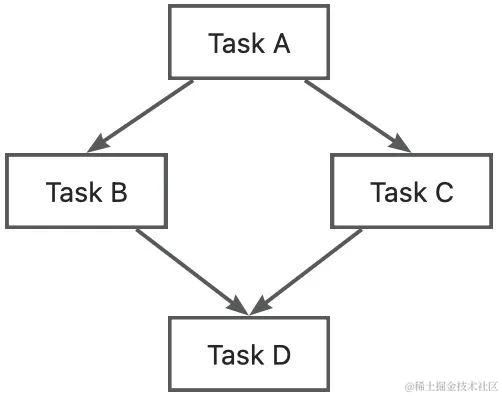
# The following workflow executes a diamond workflow
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: dag-diamond-
spec:
entrypoint: diamond
templates:
- name: diamond
dag:
tasks:
- name: A
template: echo
arguments:
parameters: [{name: message, value: A}]
- name: B
depends: "A"
template: echo
arguments:
parameters: [{name: message, value: B}]
- name: C
depends: "A"
template: echo
arguments:
parameters: [{name: message, value: C}]
- name: D
depends: "B && C"
template: echo
arguments:
parameters: [{name: message, value: D}]
- name: echo
inputs:
parameters:
- name: message
container:
image: alpine:3.7
command: [echo, "{{inputs.parameters.message}}"]
在 Git 仓库 [ 5] 中,提供了一个 MapReduce 工作流示例,分片处理数据,并聚合计算结果。
如何迁移 Batch 批处理系统到 Argo 工作流
1. 评估与规划
评估现有 Batch 批处理作业,包括依赖关系,资源需求,参数配置等。了解 Argo Workflows 的特性和最佳实践,并根据本文选择 Argo workflows 的功能以替代 Batch 批处理作业。另外,由于分布式工作流 Argo 集群的 Serverless ECI 能力,您可以跳过规划 Compute Environment 和管理优先级队列。
2. 创建分布式工作流 Argo 集群
参考文档:工作流集群快速入门 [ 6]
3. 转换作业定义
根据 Batch 批量计算到 Argo 工作流的功能映射,重写 Batch 批量计算作业为 Argo 工作流,也可以通过调用 Argo 工作流 SDK [ 7] ,以自动化方式创建工作流,并接入业务系统。
4. 数据存储
确保分布式工作流 Argo 集群可以访问工作流运行所需要的数据,工作流集群可以挂在访问阿里云 OSS,NAS,CPNS,云盘等存储资源。参考使用存储卷 [ 8] 。
5. 测试验证
验证工作流运行正常,数据访问,结果输出正常,资源用量符合预期。
6. 运维:监控和日志
开启分布式工作流 Argo 集群可观察能力 [ 9] ,查看工作流运行状态和日志。
总结
-
在用户体验、核心能力、计算环境和生态集成方面,Argo 工作流可以覆盖主流 Batch 批处理系统的功能,同时在复杂工作流编排和计算环境管理方面强于 Batch 批处理系统。
-
分布式工作流 Argo 集群基于 Kubernetes 构建,工作流定义符合 Kubernetes Yaml 规范,子任务定义符合 Kubernetes Container 规范。如果您已经在使用 Kubernetes 运行在线应用,可以快速上手编排工作流集群,统一使用 Kubernetes 作为在线应用和离线应用的技术底座。
-
计算环境采用阿里云弹性容器 ECI,不需要维护节点,同时提供大规模算力的按需使用,按量计费,避免工作流排队等待,提高运行效率,节省计算成本。
-
结合使用阿里云 Spot 示例,可以大幅降低计算成本。
-
分布式工作流适合 CICD,数据处理、仿真计算,科学计算等业务场景。
相关链接:
[1] 分布式工作流 Argo 集群
https://help.aliyun.com/zh/ack/distributed-cloud-container-platform-for-kubernetes/user-guide/overview-12?spm=a2c4g.11186623.0.0.3b33309fEXoH3j
[2] Argo Workflows
https://argoproj.github.io/argo-workflows/
[3] GitHub 仓库
https://github.com/AliyunContainerService/argo-workflow-examples/tree/main/loops
[4] 工作流(Workflows)Loops
https://argo-workflows.readthedocs.io/en/latest/walk-through/loops/
[5] Git 仓库
https://github.com/AliyunContainerService/argo-workflow-examples/tree/main/map-reduce
[6] 工作流集群快速入门
https://help.aliyun.com/zh/ack/distributed-cloud-container-platform-for-kubernetes/user-guide/workflow-cluster-quickstart?spm=a2c4g.11186623.0.0.20555492DR5MCM
[7] SDK
https://argoproj.github.io/argo-workflows/client-libraries/
[8] 使用存储卷
https://help.aliyun.com/zh/ack/distributed-cloud-container-platform-for-kubernetes/user-guide/use-volumes?spm=a2c4g.11186623.0.0.12011428eDYQH1
[9] 可观察能力
https://help.aliyun.com/zh/ack/distributed-cloud-container-platform-for-kubernetes/user-guide/observability/