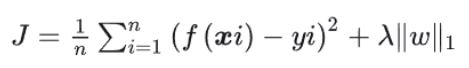简介
论文原址:https://arxiv.org/pdf/1709.01507.pdf
在深度学习领域,提升模型的表征能力一直是一个关键的研究方向。SE(Squeeze-and-Excitation)模块是一种引入通道注意力机制的方法,旨在让神经网络更加关注对当前任务重要的特征。本文将介绍SE模块的原理、实现以及在深度学习中的应用。
SE模块结构

SE模块主要的两个操作就是Squeeze与Excitation操作。
首先是Squeeze操作,通过聚合跨空间维度(H × W)的特征映射来产生通道描述符,怎么理解呢?
假设有一个输入的特征映射,它的维度是H × W × C,对于每个通道,执行全局平均池化操作,具体来说,对于第i个通道,计算该通道上所有空间位置的平均值。可以通过对每个通道的所有元素取平均来实现,其中每个元素表示相应通道上的平均值,在对输入特征映射中的所有通道,都执行上述的操作,就会得到C个平均值,形成一个长度为C的向量。由此,Squeeze操作将输入的H × W × C特征映射压缩成一个C维的向量,其中每个元素表示对应通道上的平均值。这个向量可以被看作是对整个特征映射在通道维度上的"描述符"。
接着是Excitation操作,它是SE模块中的第二步,其主要目的是对上一步Squeeze得到的通道描述符进行加权,以强调重要的通道。
接着是将Squeeze得到的C维向量输入到一个全连接层(FC层),其目的是学习通道权重。这个全连接层包括一个非线性激活函数,如ReLU,以引入非线性变换。通过学习,全连接层得到的通道权重经过一个Sigmoid激活函数,将其范围限制在0到1之间。学到的权重可以被视为每个通道的激活程度。最后,将原始的C维向量与这学到的通道权重相乘,得到加权后的向量。这个加权后的向量反映了每个通道在任务中的重要性和贡献程度。这一过程使得网络能够动态调整通道的关注度,从而更有效地利用信息来完成任务。
"""
Original paper addresshttps: https://arxiv.org/pdf/1709.01507.pdf
Code originates from https://github.com/moskomule/senet.pytorch/blob/master/senet/se_module.py
"""
import torch
from torch import nn
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
if __name__ == '__main__':
input = torch.randn(1, 64, 64, 64)
se = SELayer(channel=64, reduction=8)
output = se(input)
print(output.shape)
关于这一部分的理解,我也是看了许多博主的博客,很多都是一步带过,我也是综合着才理解到原来是这样的,最后会过头来再看代码似乎有一点明悟,我的理解可以与其对的上。
这里还涉及到了一个超参数reduction,指的是 SE 模块的缩减比例。据作者论文里面说的是16是一个效果比较好的值,它表示的是通道数缩减的比例为 1/16。这个比例用于控制全连接层的通道数缩减,从而影响 SE 模块的参数量和计算复杂度,通过调整 reduction 参数,可以灵活控制通道数的缩减程度。
SE-Resnet网络
由于我也是刚学完这部分的知识,应用上面还需要进行实验,所以,还是来看看原作者提供的torch版本的网络。
import torch.nn as nn
from torchvision.models import ResNet
__all__ = ["se_resnet18", "se_resnet34", "se_resnet50", "se_resnet101", "se_resnet152"]
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
def conv3x3(in_planes, out_planes, stride=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False)
class SEBasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None,
*, reduction=16):
super(SEBasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes, 1)
self.bn2 = nn.BatchNorm2d(planes)
self.se = SELayer(planes, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.se(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class SEBottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None,
*, reduction=16):
super(SEBottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.se = SELayer(planes * 4, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.se(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
def se_resnet18(num_classes):
model = ResNet(SEBasicBlock, [2, 2, 2, 2], num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
def se_resnet34(num_classes):
model = ResNet(SEBasicBlock, [3, 4, 6, 3], num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
def se_resnet50(num_classes):
model = ResNet(SEBottleneck, [3, 4, 6, 3], num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
def se_resnet101(num_classes):
model = ResNet(SEBottleneck, [3, 4, 23, 3], num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
def se_resnet152(num_classes):
model = ResNet(SEBottleneck, [3, 8, 36, 3], num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
if __name__=="__main__":
import torchsummary
import torch
input = torch.ones(2, 3, 224, 224).cuda()
net = se_resnet50(num_classes=4)
net = net.cuda()
out = net(input)
print(out)
print(out.shape)
torchsummary.summary(net, input_size=(3, 224, 224))
# Total params: 26,031,172这里面基本上是与torchvision中的源码相同的,只是对原本的BasicBlock与Bottleneck在最后的卷积层后加入了SE模块。
ResNet与SE-ResNet分类性能比较实验
这一部分我是在自己的数据集上进行分类的,一共四个类,每个类别大约在300张左右,ResNet添加了官方的预训练权重,SE-Resnet是重头开始训练。(本来是预计都跑50轮的,但是在跑ResNet的时候忘记了)
下面是ResNet50的训练损失记录:

下面是SE_ResNet50的训练损失记录:

这里还记录了se_resnet的错误率记录,因为是后加的功能,所以resnet50没有。
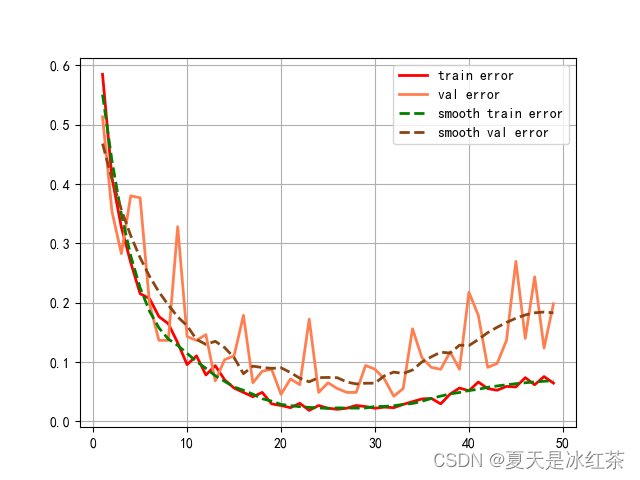
这里出现了过拟合的情况,不过也没关系,本身这个数据量在这里,这里我也只是想要测试它的性能效果而已。