1 前言
1-1 简介
工作中需要对所有的实体数据进行存储构建实体知识图谱,为基于知识图谱的问答提供数据基础。选择使用Neo4j作为数据库进行存储。以下是关于Neo4j的简介。

1-2 任务背景
将处理好的实体数据(共计1100万)写入图数据库中,并且提供查询接口,供下游(KBQA)进行查询。由于数据量比较大,所以需要批量更新、批量删除。
1-3 任务难点
任务难点有两个:
(1)因为数据处理的缘故,每个实体的属性不一致。比如“芈月”这一实体,其中存在{"name": "中文名", "value": "芈月"}, {"name": "别名", "value": "月儿、月公主、太后、公主、芈夫人、芈八子、月妹妹、王妹、母后、姐姐、小霸星、小老虎"}, {"name": "饰演", "value": "孙俪(成年)、柴蔚(少年)、李景儿(童年)、刘楚恬(童年)"}, {"name": "登场作品", "value": "芈月传"}等属性。而“布巴洛”则有{"name": "中文名", "value": "布巴洛"}, {"name": "运动项目", "value": "足球"}, {"name": "所属运动队", "value": "芭提雅联足球俱乐部"}, {"name": "场上位置", "value": "前锋"}等属性。如何根据不同的属性做出个性化的Node是面临的第一个难点。经过探索,解决此问题借助了字典的方式。
(2) 因为数据量庞大,如何将创建好的Node快速写入Neo4j中成为另一个难点。经过探索,解决此问题,采用了子图写入的方式。
1-3 数据来源
数据来源于百度百科的词条数据,对百科词条进行处理。部分样例如下所示:
{"lemmaTitle": "芈月", "lemmaDesc": "电视剧《芈月传》女主角", "lemmaSummary": {"value": "芈月,古装电视剧《芈月传》中的女主角。由演员孙俪饰演。芈月的历史原型为秦国的宣太后,她是中国历史上第一位太后。"}, "basicInfo": [{"name": "中文名", "value": "芈月"}, {"name": "别名", "value": "月儿、月公主、太后、公主、芈夫人、芈八子、月妹妹、王妹、母后、姐姐、小霸星、小老虎"}, {"name": "饰演", "value": "孙俪(成年)、柴蔚(少年)、李景儿(童年)、刘楚恬(童年)"}, {"name": "登场作品", "value": "芈月传"}, {"name": "所处时代", "value": "战国时期楚国→秦国"}, {"name": "民族族群", "value": "华夏族"}, {"name": "出生地", "value": "荆州"}, {"name": "出生日期", "value": "不详"}, {"name": "逝世日期", "value": "前265年"}, {"name": "主要成就", "value": "在秦国长期执政、杀义渠王、灭义渠国、囚死楚怀王"}, {"name": "心腹", "value": "葵姑、香儿、惠儿、穆辛"}, {"name": "谥号", "value": "宣"}, {"name": "父亲", "value": "羋(熊)商(楚威王)"}, {"name": "母亲", "value": "向氏"}, {"name": "丈夫", "value": "嬴驷"}, {"name": "弟弟", "value": "芈戎(同父同母)、魏冉(同母异父)、白起(义弟)"}, {"name": "初恋", "value": "黄歇"}, {"name": "情人", "value": "翟骊(义渠王)"}, {"name": "儿子", "value": "嬴稷(和嬴驷所生)、嬴芾(和翟骊所生)"}, {"name": "姐姐", "value": "芈姝(已决裂)、羋茵(天生不和)"}, {"name": "哥哥", "value": "羋(熊)槐(楚怀王、同父异母)"}, {"name": "侄子", "value": "羋(熊)横(楚顷襄王)"}, {"name": "好姐妹", "value": "樊长使、卫良人、唐夫人、孟赢、魏美人"}, {"name": "养母", "value": "莒姬"}, {"name": "仇人", "value": "魏琰、虢美人、孟昭氏、魏颐、甘茂、玳瑁、珍珠、珊瑚、靳尚、赢荡、芈姝、羋茵、楚威后、冯甲、羋(熊)槐、羋菁、郑袖、赢华"}, {"name": "师傅", "value": "屈原"}, {"name": "男宠", "value": "魏丑夫"}, {"name": "玄孙", "value": "秦始皇嬴政"}, {"name": "身份", "value": "楚国公主→芈八子→燕国质子→秦国太后(宣太后)"}, {"name": "好友", "value": "张仪、庸睿、樗里疾"}, {"name": "入秦宫身份", "value": "八子"}, {"name": "字号", "value": "宣"}, {"name": "朝代", "value": "战国时期"}, {"name": "国籍", "value": "楚国→秦国"}, {"name": "本名", "value": "芈月"}, {"name": "饰演者", "value": "孙俪"}, {"name": "性别", "value": "女"}], "order": 0, "category": "人物,虚拟人物,影视人物,文学角色,历史人物", "tags": "文化;出版物", "synonyms_lemmaTitle": ["芈月 电视剧《芈月传》女主角", "宣太后", "芈月"], "synonyms": "芈月\t电视剧《芈月传》女主角,宣太后,芈月"}{"lemmaTitle": "布巴洛", "lemmaDesc": "塞尔维亚足球运动员", "lemmaSummary": {"value": "布巴洛是塞尔维亚足球运动员。"}, "basicInfo": [{"name": "中文名", "value": "布巴洛"}, {"name": "运动项目", "value": "足球"}, {"name": "所属运动队", "value": "芭提雅联足球俱乐部"}, {"name": "场上位置", "value": "前锋"}], "order": 0, "category": "人物", "tags": "人物", "synonyms_lemmaTitle": "布巴洛", "synonyms": "布巴洛"}
2 任务实现
2-1 安装Neo4j
安装版本为Community-4.4.8,进入到安装包目录下执行命令:
tar -xf neo4j-community-4.4.8-unix.tar.gz安装完成后会生成如下目录:
conf目录下存放配置文件,可以根据自己服务器配置进行修改。
启动:
进入bin目录执行./neo4j start2-2 引入必要的库
import jsonlines
from tqdm import tqdm
import jsonlines
import pandas as pd2-3 连接图数据库
2-3-1 连接图数据库
使用py2neo作为连接工具,完成对Neo4j的操作。引入必要的库函数,首先根据网址、用户名和密码建立连接。之后可以借助NodeMatcher方法生成查询。
#连接数据库
from py2neo import Graph, Node, Relationship,Subgraph,NodeMatcher
graph = Graph(
'http://xx.xx.xx.xxx:7474/browser/',
auth=('neo4j', 'Neo4j'))
#创建查询
node_matcher = NodeMatcher(graph)
#数据库清空
#graph.delete_all() #DatabaseError: [Statement.ExecutionFailed] Java heap space2-4 写入节点
2-4-1 创建Node
针对每条实体,将其中的key_value键值对进行整合,并生成字典。建立node,再使用node[key] = val,将每一条属性与属性值写入node中。
#读入数据
with open('/ssd/Spider/Neo4j_dataRelation1.jsonl',"r+")as reader :
entity_lines = reader.readlines()
def get_Node(entity):
test_dict = eval(entity)
test_list = []
for item_key in test_dict:
if item_key == 'basicInfo':
for basc_info in test_dict['basicInfo']:
if basc_info['name'] and basc_info['value']:
test_list.append((test_dict['lemmaTitle'],basc_info['name'],basc_info['value']))
elif item_key == 'lemmaSummary':
if test_dict['lemmaSummary']['value']:
test_list.append((test_dict['lemmaTitle'],'lemmaSummary',test_dict['lemmaSummary']['value']))
elif item_key=='synonyms_lemmaTitle' or item_key=='synonyms' :
continue
elif item_key=='category':
if test_dict[item_key] !='':
test_list.append((test_dict['lemmaTitle'],item_key,test_dict[item_key]))
else:
test_list.append((test_dict['lemmaTitle'],item_key,"None"))
elif item_key=='tags':
if test_dict[item_key] !='':
test_list.append((test_dict['lemmaTitle'],item_key,test_dict[item_key]))
else:
test_list.append((test_dict['lemmaTitle'],item_key,"None"))
elif item_key =='star_relations':
for item in test_dict[item_key]:
if item['name'] and item['value']:
test_list.append((test_dict['lemmaTitle'],item['name'],item['value']+"_"+item['lemmaId']))
elif item_key == 'lemma_relations':
for item in test_dict[item_key]:
if item['name'] and item['value']:
test_list.append((test_dict['lemmaTitle'],item['name'],item['value']+"_"+item['lemmaId']))
elif item_key == 'Relation':
continue
else:
test_list.append((test_dict['lemmaTitle'],item_key,test_dict[item_key]))
#建立字典
entity_dict = {}
for item in test_list:
#entity_dict.setdefault(item[1],[]).append(item[2])
entity_dict[item[1]] = item[2]
label = 'Common_test'
entity_name = entity_dict['lemmaTitle']
node = Node(label,name=entity_name)
#graph.create(node)
for key, val in entity_dict.items():
node[key] = val
#graph.push(node)
return node2-4-2 建立子图
在写入时,选择了开销最小并且最为稳妥的子图写入方式, subgraph = Subgraph(node_ls, relation_ls),需要对Subgraph()传入两个参数,node_ls表示节点列表,relation_ls表示关系列表,如果只是想写入节点,那就将relation_ls用[]代替。
def write_neo4j(node_ls):
#构建子图
subgraph = Subgraph(node_ls, [])
#构建事务
Transaction = graph.begin()
Transaction.create(subgraph)
#提交
graph.commit(Transaction)2-4-3 子图写入
使用子图的方式写入节点,本次写入中以1万为一个批次写入,写入之后将节点列表清空。 写入100万数据用时9分钟。
Node_list = []
for entity in tqdm(entity_lines[:1000000]):
node = get_Node(entity)
Node_list.append(node)
if len(Node_list) == 10000:
write_neo4j(Node_list)
Node_list = []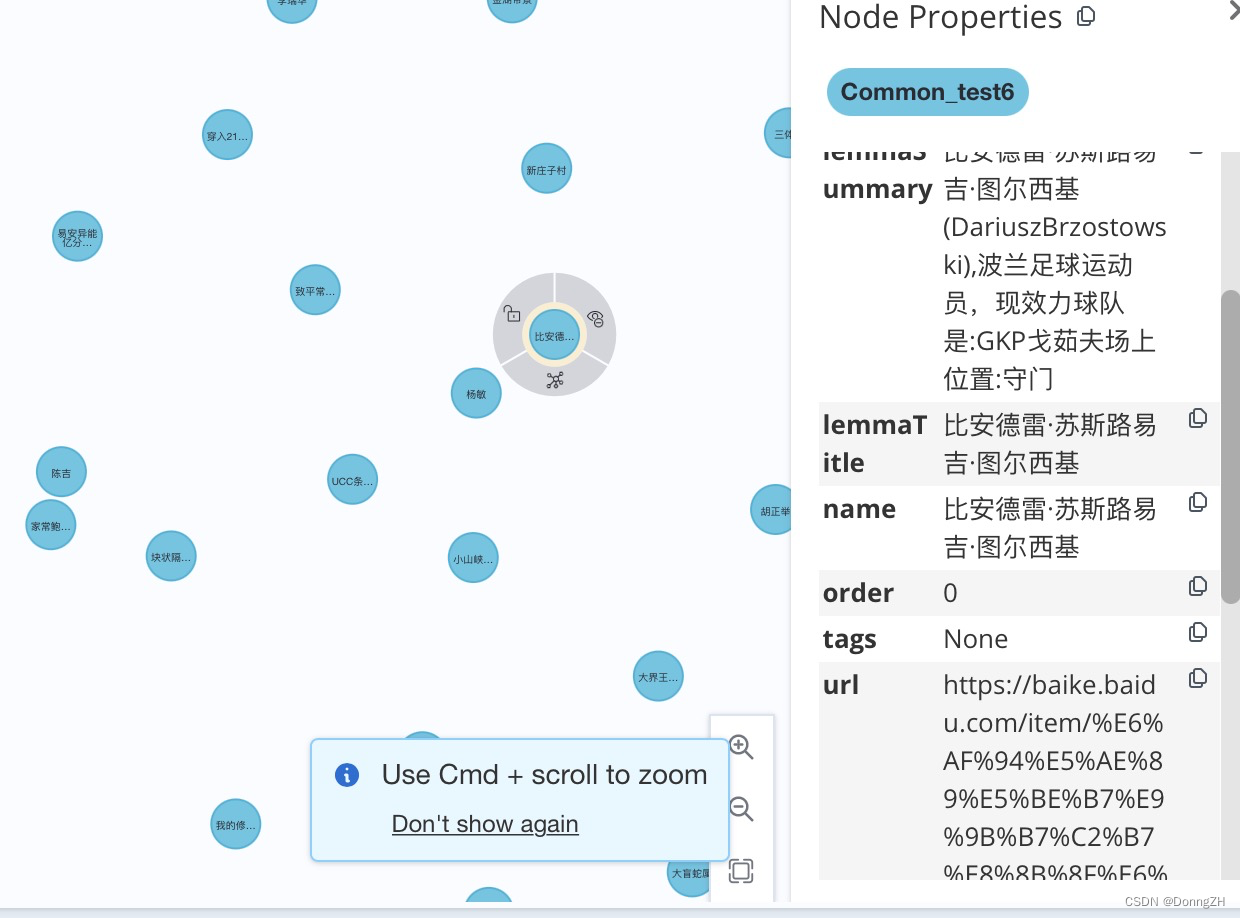
2-5 创建索引
说明:为label是Common_test的实体的lemmaTitle创建索引,
#index_command = 'create index on:Common(lemmaTitle)'
index_command = 'create index on:Common_test(lemmaTitle)'
result = graph.run(index_command)2-6 查询
说明:创建索引后,在100万节点的库中查询单实体,查询一条用时59ms
#查询
search_result = graph.nodes.match("Common_test").where(lemmaTitle='中国').all() # [0].items()
#search_result
#search_result[0].items()3 后记
在处理数据时,每条实体数据的存储形式都是以key:value的形式存储,每条实体数据都有不同的key和value。所以做数据导入时,要根据每一条实体数据做’个性化处理‘。将数据中的属性写到列表中,然后再通过key、value的方式push到节点中。初次写入时,每个实体都单独处理,首先create node,然后再形成字典,进行push,这样的方法效率非常慢,因为每次创建节点再进行push都需要进行查库,并且随着库中数据量大增多,导致写入速度越来越慢。后面尝试够使用Load CSV 的方式写入,但是由于实体数量庞大,每个实体会有不同的属性,从而导致csv的维度有60W维,并且csv的维度及其稀疏,写入都需要占用巨大的内存,后遂放弃。最后了解到使用子图的方式可以写入,先将node存放到列表中,当然也可以存放关系形成subgraph = Subgraph(node_ls, relation_ls)的形式,如果relation_ls为空则写成ubgraph = Subgraph(node_ls, [])。随后可以控制节点列表的长度,文中在写入时设置的大小为1万,当列表的长度到达1万之后,便一次性提交。将一万多节点批次写入。这样既满足了节点数据个性化的要求,又实现了批量写入。
写入数据后,便是创建索引,因为每个实体节点在写入时,为其贴上了标签(label),本次写入时的label设置为Common_test,所以在创建索引时,需要用到标签信息。之后就可以为实体的具体属性创建索引。创建索引后查询速度提升80%。