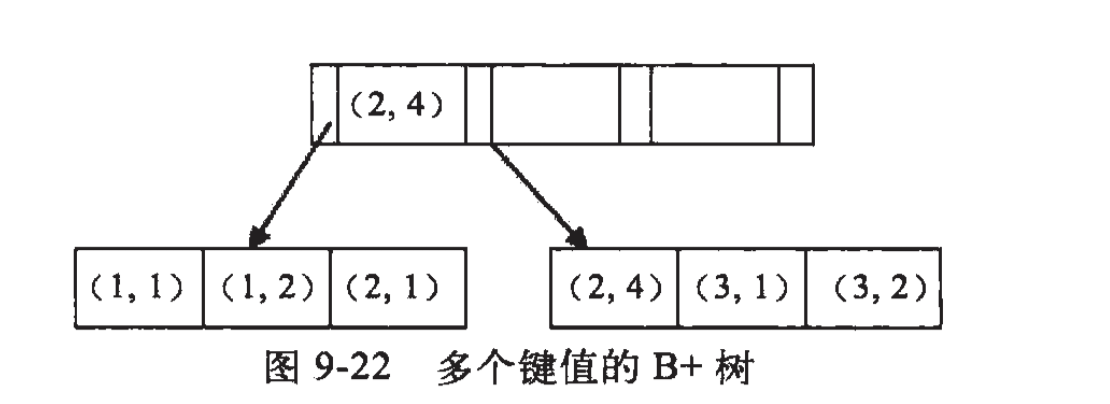
文章目录
- Jupyter Notebook 学习人工智能的好帮手
- 数据集
- 数据集下载
- 数据集调用
- 数据集应用技巧——获取不重复的编号
- 数据集应用技巧——随机采样
- 数据集应用技巧——抽取前N项进行模拟测试
- 数据集构建
- 技巧一——查看数据集构建进度
Jupyter Notebook 学习人工智能的好帮手
【Jupyter Notebook】快速上手 轻松玩明白
数据集
数据集下载
数据集下载地址
数据集调用
from sklearn.preprocessing import LabelEncoder
import pandas as pd
df = pd.read_csv("yoochoose-clicks.dat",header=None)
df.columns = ['session_id','timestamp','item_id','category']
print(df)
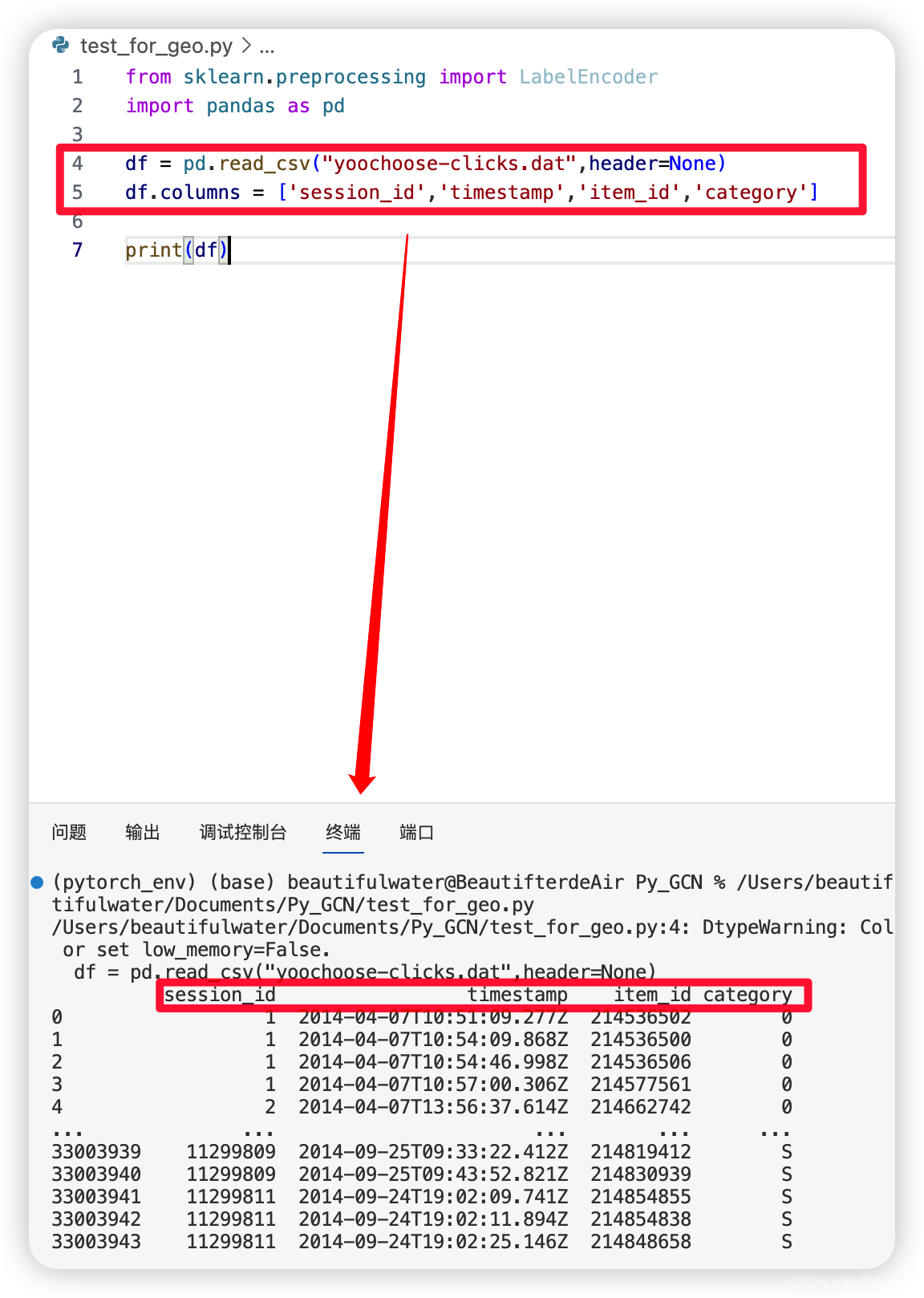
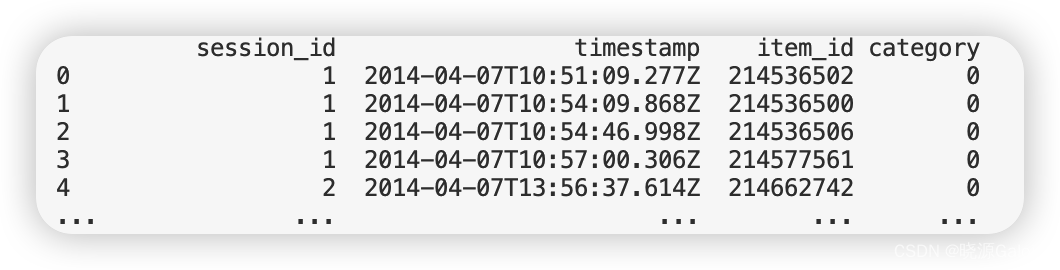
其中,session_id表示的是某次会话的编号,而item_id表示的是某次会话下的某个操作,category代表购买情况,其中0代表未购入,1代表购入。
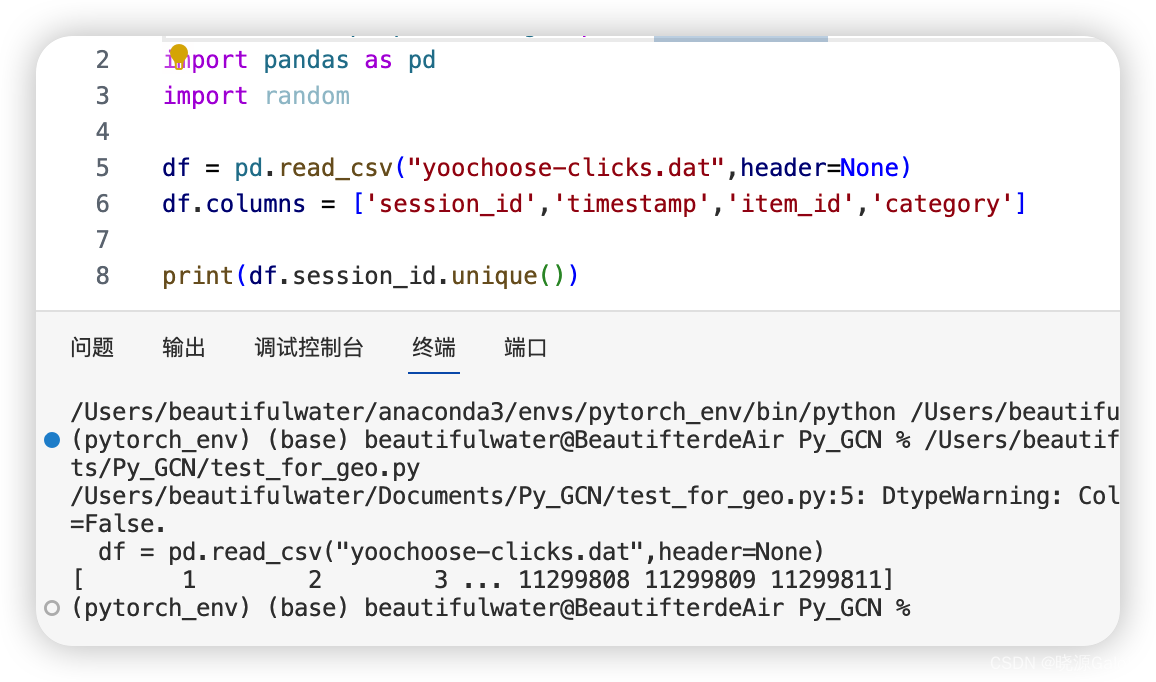
数据集应用技巧——获取不重复的编号
可以对某一个关键字采用unique()。
数据集应用技巧——随机采样
应用场景:数据集过多,抽取部分数据进行观察。
工具:采用random中的choice进行提取(numpy库也有random包,也有choice方法)。
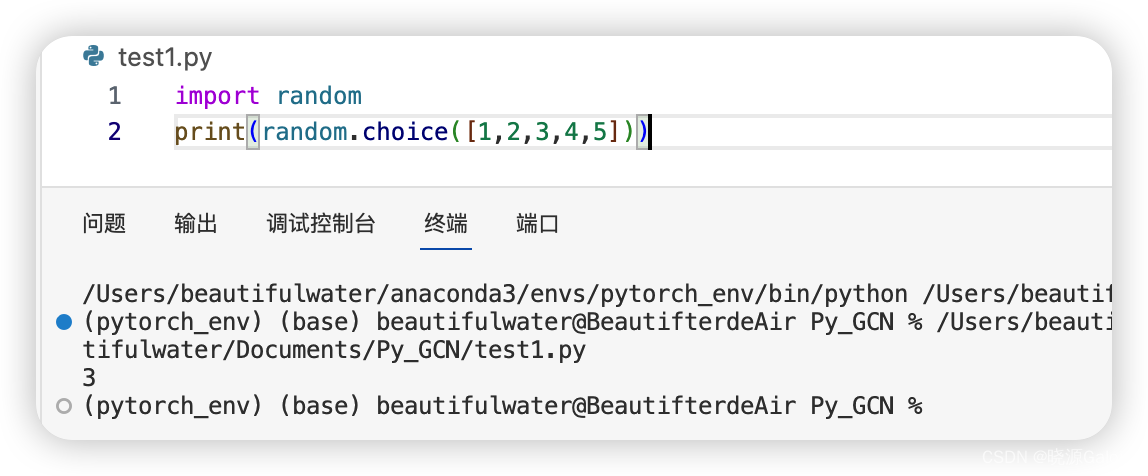
choice可以选取出列表/集合中的其中一项
数据集应用技巧——抽取前N项进行模拟测试
应用场景:可用于熟悉操作。
工具:使用分片进行操作。
分片的具体操作可见于分片链接
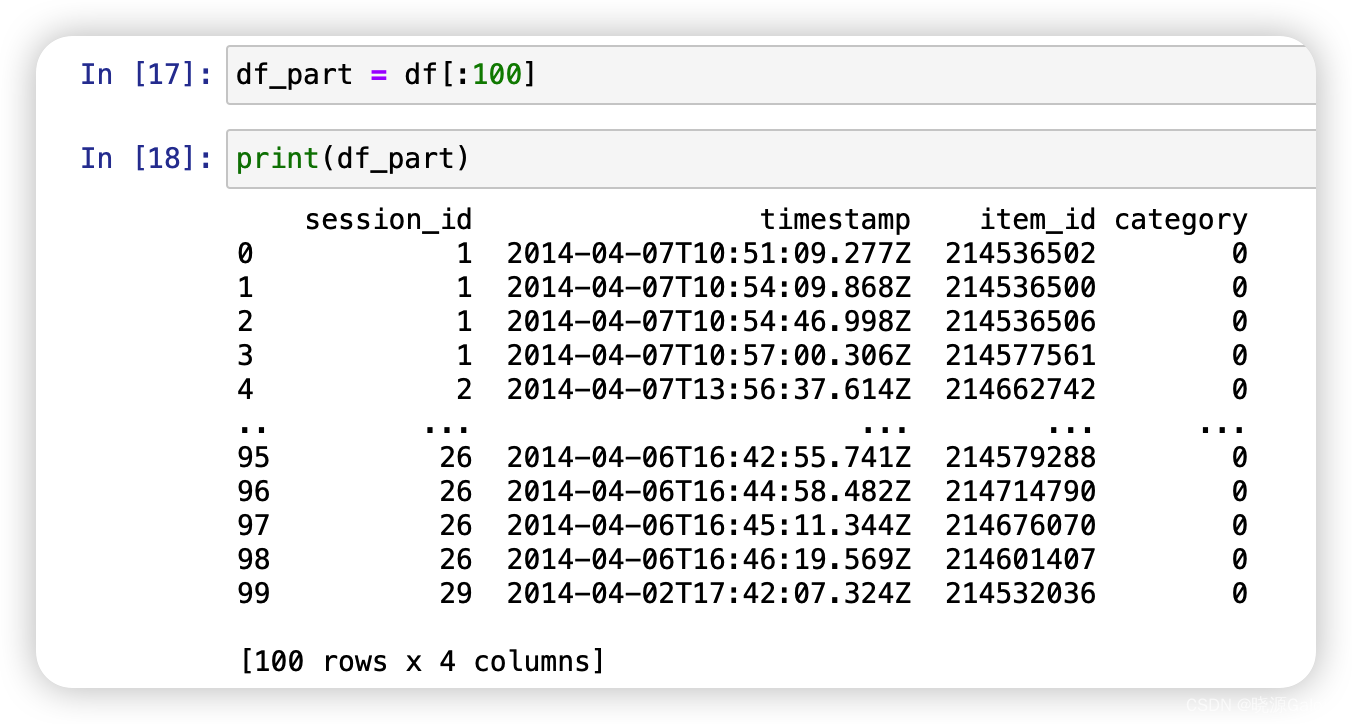
数据集构建

第二步,刚开始这些点并没有图的编号(有session_id,但并不是一个方便建图的编号),于是可以采取按某一个关键字进行排序的方法,按大小给图上的节点进行重新编号。

后几步,开始制作边集。
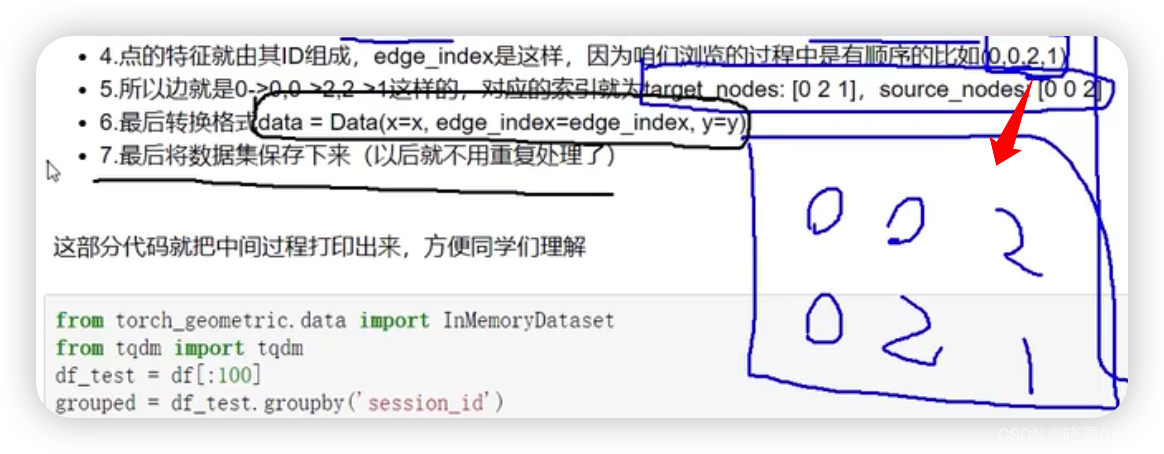
考虑复用性的话,记得将构造出来的数据集进行保存。
技巧一——查看数据集构建进度
应用场景:可以可视化进度





![[小程序]页面事件](https://img-blog.csdnimg.cn/direct/85c945f208674f2587ddc4c2be957496.png)