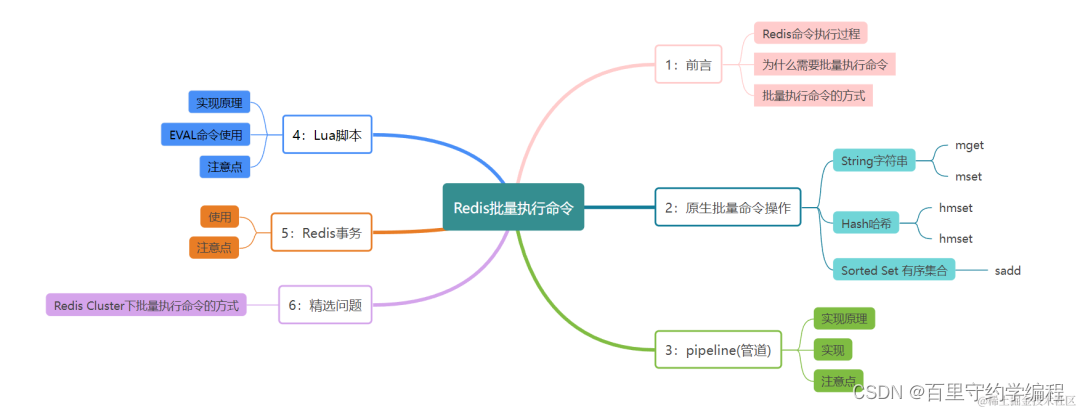
文章目录
- 前言
- 一、Redis命令执行过程
- 二、原生批量命令
- 三、pipeline(管道)
- 四、Lua脚本
- 五、Redis事务
- 六、Redis Cluster模式下该如何正确使用批量命令操作?
前言
在我们的印象中Redis命令好像都是一个个单条进行执行的,但实际上我们是可以批量执行Redis命令的。
最容易想到的是Redis的一些批量命令,例如MGET
总结而言,一共四种批量执行Redis命令的方式
一、Redis命令执行过程
在了解批量执行有哪些方式之前,我们简单回顾下Redis命令执行的过程:

为什么需要批量执行命令呢?
在了解批量执行命令有哪些方式之前,我们先简单整理下【批量执行命令】比【执行多个单Redis命令】能带来哪些好处!
通过批量执行命令好处如下:
• 提高命令执行效率:减少网络延迟,提高Redis服务器的响应速度
• 简化客户端逻辑:将多个命令封装成一个操作,简化客户端处理逻辑
• 提升事务性能:可以保证一组命令在同一时间内执行,提高事务的性能

你看单个执行命令每次都需要发送进行网络传输,同样多的执行,批量执行可以有效减小网络开销,减少 RTT(往返时间)。
批量执行命令的方式, 有以下四种常见批量执行命令的方式:
-
Redis原生命令:例如MSET、HMGET、HMSET、SADD -
pipeline(管道) -
Lua脚本 -
Redis事务
我们来给每种方式简单举个栗子,然后看看有什么需要注意的地方!
二、原生批量命令
Redis的原生命令就支持批量命令的操作,比如:HMSET、HMGET、SADD。
其实严格来说上述命令不属于批量操作,而是在一个指令中处理多个key,我们来看下具体该如何使用。
String字符串
MSET:设置一个或多个指定 key 的值
MGET:从一个或多个指定的key中获取值
MSET key value [key value ...]
MGET key [key ...]
Hash哈希
操作哈希类型时,使用HMSET和HMGET命令分别设置和获取多个字段及其值
HMSET:将一个或多个 field-value 对设置到指定哈希表中
HMGET:从指定指定哈希表中一个或者多个字段的值
HMSET key field value [field value ...]
HMGET key field [field ...]
Sorted Set 有序集合
SADD可以将多个元素添加到有序集合
SADD key member [member ...]
📢 注意
🚩Redis Cluster中MGET操作可能无法保证原子性!因为在
Redis Cluster中,MGET操作涉及多个键的读取操作,并且这些键无法保证所有的key都在同一个
hash slot(哈希槽)上。而
Redis Cluster的节点间可能会有网络延迟和不同的负载情况,MGET操作不能保证在同一时刻原子地获取所有键的值。不过相较于非批量操作,这些指令可以节省不少网络传输次数,毕竟不用发送一次命令,服务器响应一次。
三、pipeline(管道)
Redis Pipeline(管道)命令是一种优化网络通信的技术,可以将多个命令一次性发送给Redis服务器,可以减少客户端与Redis服务器之间的网络通信次数。
客户端将多个命令发送到Redis服务器,Redis服务器将这些命令缓存起来,然后一次性执行,最后将执行结果一次性返回给客户端。
使用Redis Pipeline好处很明显,可以避免在每个命令执行时都进行一次网络通信,时间开销变为:
🚩 1 次 pipeline(n条命令) = 1 次网络时间 + 执行n 条命令时间
这里用Golang语言看看如何使用pipeline , 从代码中可以看出需要服务端和客户端的共同实现,不像原生批量命令一样Redis直接支持实现。
package main
import (
"github.com/go-redis/redis"
)
func main() {
pipe := client.Pipeline()
defer pipe.Close()
// 封装 pipeline待执行命令
set := pipe.Set("key", "value", 0)
get := pipe.Get("key")
// 执行 pipeline
_, err := pipe.Exec()
if err != nil {
panic(err)
}
// 获取 pipeline执行结果
val, err := get.Result()
if err != nil {
panic(err)
}
}
📢 注意
🚩 1:Redis Cluster中Pipeline命令操作可能无法保证原子性!因为Redis Cluster采用的分片机制,这些键无法保证所有的key都在同一区域hash slot(哈希槽)上,所以不同的命令可能会发送到不同的节点上。 这意味着即使你使用Pipeline,每个命令仍然在不同的节点上进行处理,可能会导致多个命令的执行不是在同一时刻进行的。🚩 2:
pipeline能执行有依赖关系的命令吗?答案是不可以的,如果
pipeline中后一个命令的执行需要依赖前一个命令的执行结果,就没办法满足需求了。🚩 3:
pipeline对发送的命令有数量限制吗?虽然命令可以一次性发给
Redis服务端,但是考虑带宽等情况,建议不多于500个命令,或者根据实际命令的数据类型定。为了保证更高的一致性和原子性,就需要考虑使用其他方式,比如
Lua脚本、事务的方式了,我们继续往下看!
四、Lua脚本
我们知道Redis支持使用Lua脚本来执行自定义的复杂逻辑,因此使用Lua脚本,我们可以在Redis服务器端执行多个命令。而且Lua脚本具有原子性,即脚本中的所有命令会在同一时间内执行,不会被其他命令打断。
在Redis中使用EVAL命令,使用 Lua 解释器执行脚本,语法如下:
redis 127.0.0.1:6379> EVAL script numkeys key [key ...] arg [arg ...]
• script:要执行的Lua脚本
• numkeys:脚本中涉及到的键的数量
• key和arg:脚本中的键和参数
📢 注意
Redis Cluster下Lua脚本的原子操作同样无法操作,原因也是无法保证所有的key都在同一个hash slot(哈希槽)上。
Go样例: 68. redis计数与限流中incr+expire的坑以及解决办法(Lua+TTL)
// 执行ocr调用
func (o *ocrSvc)doOcr(ctx context.Context,uid int)(interface,err){
// 如果调用次数超过了指定限制,就直接拒绝此次请求
ok,err := o.checkMinute(uid)
if err != nil {
return nil,err
}
if !ok {
return nil,errors.News("frequently called")
}
// 执行第三方ocr调用((伪代码:模拟一个rpc接口))
ocrRes,err := doOcrByThird()
if err != nil {
return nil,err
}
// 调用成功则执行 incr操作
if err := o.incrCount(ctx,buildUserOcrCountKey(uid));err!=nil{
return nil,err
}
return ocrRes,nil
}
func (o *ocrSvc) incrCount(ctx context.Context, uid int64) error {
/*
此段lua脚本的作用:
第一步,先执行incr操作
local current = redis.call('incr',KEYS[1])
第二步,看下该key的ttl
local t = redis.call('ttl',KEYS[1]);
第三步,如果ttl为-1(永不过期)
if t == -1 then
则重新设置过期时间为 「一分钟」
redis.call('expire',KEYS[1],ARGV[1])
end;
*/
script := redis.NewScript(
`local current = redis.call('incr',KEYS[1]);
local t = redis.call('ttl',KEYS[1]);
if t == -1 then
redis.call('expire',KEYS[1],ARGV[1])
end;
return current
`)
var (
expireTime = 60 // 60 秒
)
_, err := script.Run(ctx, b.redis.Client(), []string{buildUserOcrCountKey(uid)}, expireTime).Result()
if err != nil {
return err
}
return nil
}
// 校验每分钟调用次数是否超过
func (o *ocrSvc)checkMinute (ctx context.Context,uid int) (bool, error) {
minuteCount, err := o.redis.Get(ctx, buildUserOcrCountKey(uid))
if err != nil && !errors.Is(err, eredis.Nil) {
elog.Error("checkMinute: redis.Get failed", zap.Error(err))
return false, constx.ErrServer
}
if errors.Is(err, eredis.Nil) {
// 第二版代码中在check时不进行初始化操作
// 过期了,或者没有该用户的调用次数记录(设置初始值为0,过期时间为1分钟)
// o.redis.Set(ctx, buildUserOcrCountKey(uid),0,time.Minute)
return true, nil
}
// 已经超过每分钟的调用次数
if cast.ToInt(minuteCount) >= config.UserOcrMinuteCount() {
elog.Warn("checkMinute: user FrequentlyCalled", zap.Int64("uid", uid), zap.String("minuteCount", minuteCount))
return false, nil
}
return true, nil
}
五、Redis事务
Redis事务(Transaction)通过将多个Redis操作封装为一个原子性的操作序列,确保在事务执行过程中,不会受到其他客户端的干扰。
🚩 比起原生命令和pipeline批量执行方式,事务的执行具备原子性,即全部被执行或全部不执行,并且在持久化时也具备原子性。
Redis事务使用以下三个命令进行操作:
• MULTI:标记事务开始
• EXEC:执行所有在MULTI之后的命令
• DISCARD:取消事务
用过数据库事务的对这几个命令也很容易理解,MULTI和EXEC之间的所有命令将作为一个整体被执行。这些命令会被放入队列中,等待EXEC命令的调用,一旦EXEC命令被调用,所有的命令将按照顺序被执行。
📢 注意
Redis Cluster支持transaction,但是前提是transaction涉及的所有key都属于同一hash slot, 所有需要被事务处理的键必须分布在同一个节点上
六、Redis Cluster模式下该如何正确使用批量命令操作?
通过对上面四种方式的总结,可以发现在Redis Cluster模式下会存在key可能不属于同一个节点的hash slot(哈希槽)上,导致不能按实际想的方式去执行。
查了下也有一些解决方式,看下是否适合你。
✏️ hash-tag方式:
Redis Cluster模式一般都是支持hash-tag功能,它可以将多个 key 强制分配到一个节点上,它的操作时间 =1 次网络时间 +n 次命令时间。这种方式虽然性能高,可能会因为不均衡问题导致Redis Cluster部分节点负载过高。
✏️ 维护Hash Slot映射关系:
因为主要问题在于,不能让所有的key在同一个节点上执行,那么我们在客户端维护一个key和slot的映射关系,是不是就让key固定在了一个节点的hash slot执行了!
原文地址:https://mp.weixin.qq.com/s?__biz=MzkwNjMwMTgzMQ==&mid=2247513143&idx=2&sn=fe80b0eff9f941295b11ae577183873b&chksm=c0e86cdff79fe5c96e3b5f1dfdbf835b38506cb22a5ceb86272b0ad5ebb7fd5fd0de93bdc6aa&mpshare=1&scene=23&srcid=0121HYDndibxEbSg4PKNw9hh&sharer_shareinfo=04fbc4e4cc3d0214db08d42e8edde5d1&sharer_shareinfo_first=7c6b39333ace6b853d3c3b1fcb9263aa#rd











](https://img-blog.csdnimg.cn/direct/7f634ecff0ce46799c2ddc6dd630a3be.png)