目录
1、介绍
1.1、痛点
1.2、程序介绍
2、安装方式
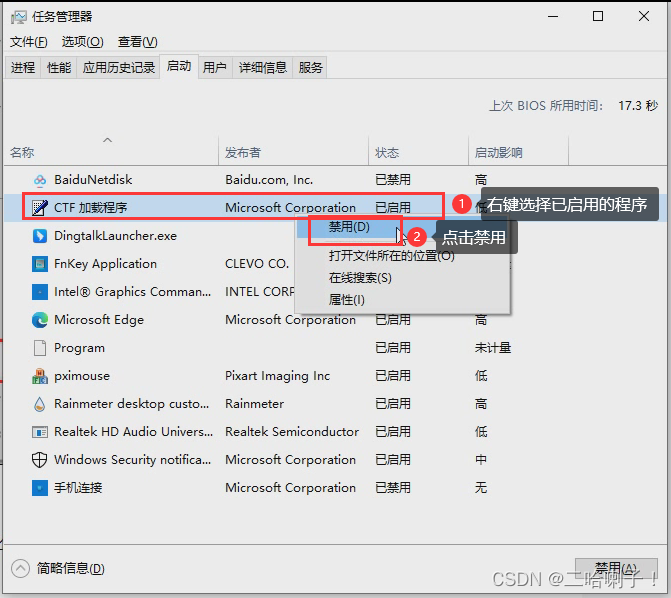
2.1、🔺必要环节
2.2、脚本安装
2.2.1、不太推荐的方式
2.2.2、节约内存的方式
2.3、⭐完整版安装
3、使用
3.1、最终文件目录
3.2、主程序
3.2.1、绝对路径
3.2.2、是否为书籍
3.2.3、⭐截取区域
3.2.4、⭐进程数
3.3、运行完成
3.4、保存路径
4、代码详解
4.1、思路
4.2、交互
4.3、提取图片
4.4、裁剪图片
4.5、删除不必要的内容
4.5、⭐OCR处理
4.5.1、处理裁剪后的图片
4.5.2、写入文件
5、⭐完整源代码
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎Python人工智能开发和前端开发。
🦅主页:@逐梦苍穹📕所属专栏:项目
🍔您的一键三连,是我创作的最大动力🌹
1、介绍
程序下载:
链接:https://pan.baidu.com/s/1kK1cBRwPMgnWBP2L43rs9Q?pwd=1234
提取码:1234
1.1、痛点
这是一个处理图片式PDF文件转换为可搜索的文字式word文档的程序,该程序是为了解决如下痛点:
①各软件的识别付费
②网页在线转换有大小限制
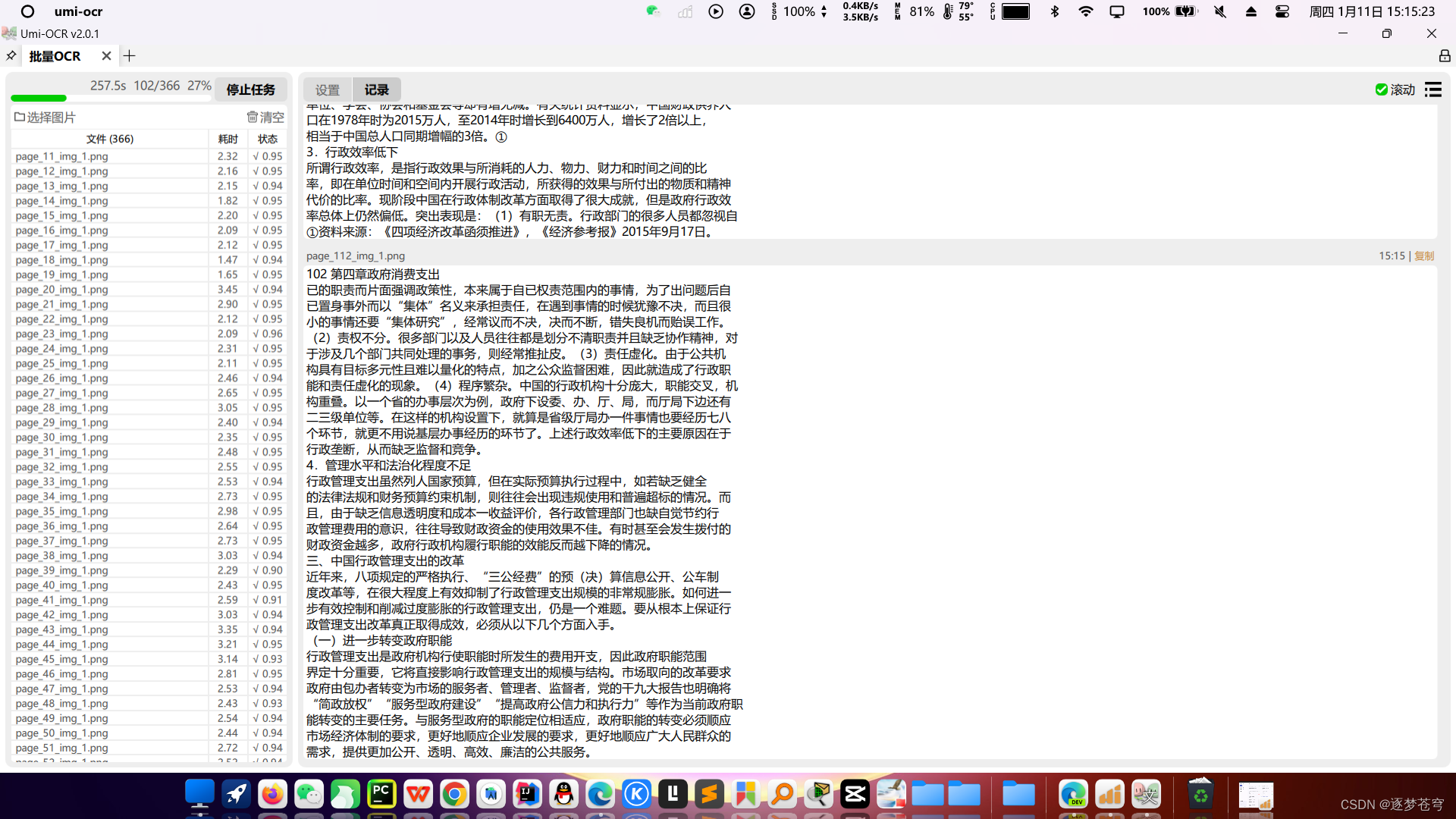
③开源的程序识别准确率略有不足(这个是比较有名的开源软件umi-ocr,准确率能达到百分之95)
1.2、程序介绍
这个程序最终是打包成了exe可执行程序(后面会详细讲解),没有做GUI图形化界面,用户和程序的交互在命令行窗口执行。
这个项目涉及的技术点包括:
- 文件操作:使用Python的os和shutil模块进行文件夹和文件的创建、删除和操作。这些模块提供了对文件系统的访问和操作,允许您在项目中进行文件和文件夹的管理。
- 图像处理:使用OpenCV和PIL库进行图像的裁剪、保存和处理。OpenCV是一个广泛用于计算机视觉任务的开源计算机视觉库,而PIL(Python Imaging Library)则提供了处理图像的基本功能,例如打开、保存、裁剪和调整图像大小。
- PDF处理:使用PyMuPDF(fitz)库进行PDF文档的处理和图像提取。PyMuPDF是一个用于处理PDF文件的Python库,可以用于提取PDF中的文本、图像等内容,并对PDF文档进行各种操作。
- 并发编程:使用Python的线程和线程池进行并发处理,加快图像处理和OCR识别速度。线程和线程池允许程序在同一时间执行多个任务,提高了程序的效率,尤其在需要处理大量图像或进行OCR识别时尤为重要。
- OCR识别:使用cnocr库进行中文OCR识别,并将识别结果写入Word文档。cnocr是一个用于中文OCR识别的Python库,能够对中文文本进行识别,这对于处理包含中文的文档或图像非常有用。
- 用户输入处理:使用Python的input函数接收用户输入,根据用户输入执行不同的处理逻辑。这样可以使程序更加灵活,能够根据用户需求进行不同的操作。
- 异常处理:使用try-except结构进行异常处理,确保程序在出现异常时能够正常处理并给出相应提示。这有助于提高程序的稳定性和可靠性,尤其在处理文件和网络请求时非常重要。
这个项目主要用于将PDF文档中的图片提取出来,并对提取的图片进行裁剪、OCR识别,最后将识别结果写入Word文档。通过结合多种技术,实现了从PDF文档到图像处理再到文本识别的全流程自动化。
2、安装方式
这个程序一共有两种安装方式。
无论哪种安装方式,都是即装即用,也就是说,当年不需要的时候,把这个程序所在的文件夹整个删除即可,不会有残留。
需要的内容都存入百度网盘了。下载对应的zip压缩包解压即可。
OCR-program-transition-all.zip是完整版,直接就可以用!
OCR-program-transition-empty-bat.zip是脚本安装版,需要用户按照指引来操作,才可使用。
推荐使用完整版
2.1、🔺必要环节
这个程序有两个依赖项,需要手动安装!(也在网盘内)。即:

安装过程一路默认即可。
安装后:

2.2、脚本安装
目录结构如下:
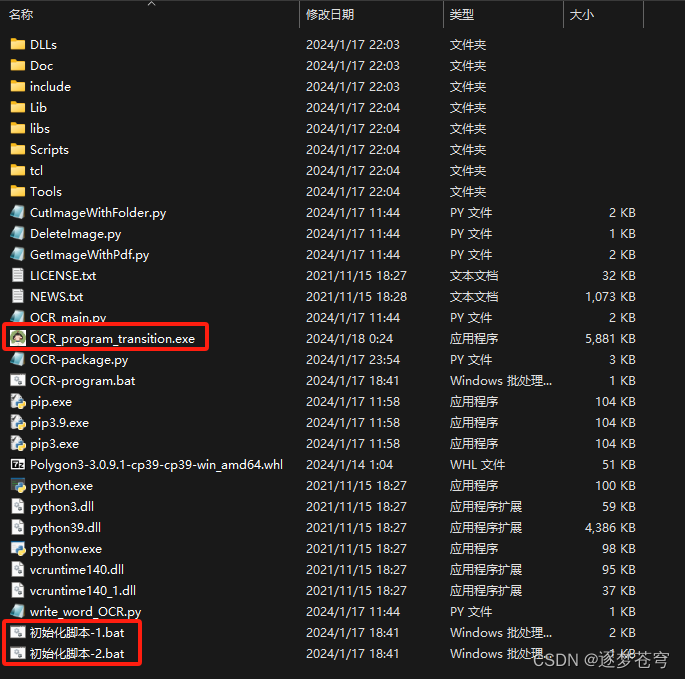
2.2.1、不太推荐的方式
这个项目需要依赖到C++的一些库,根据报错信息,是建议直接安装C++编译器Visual Studio:
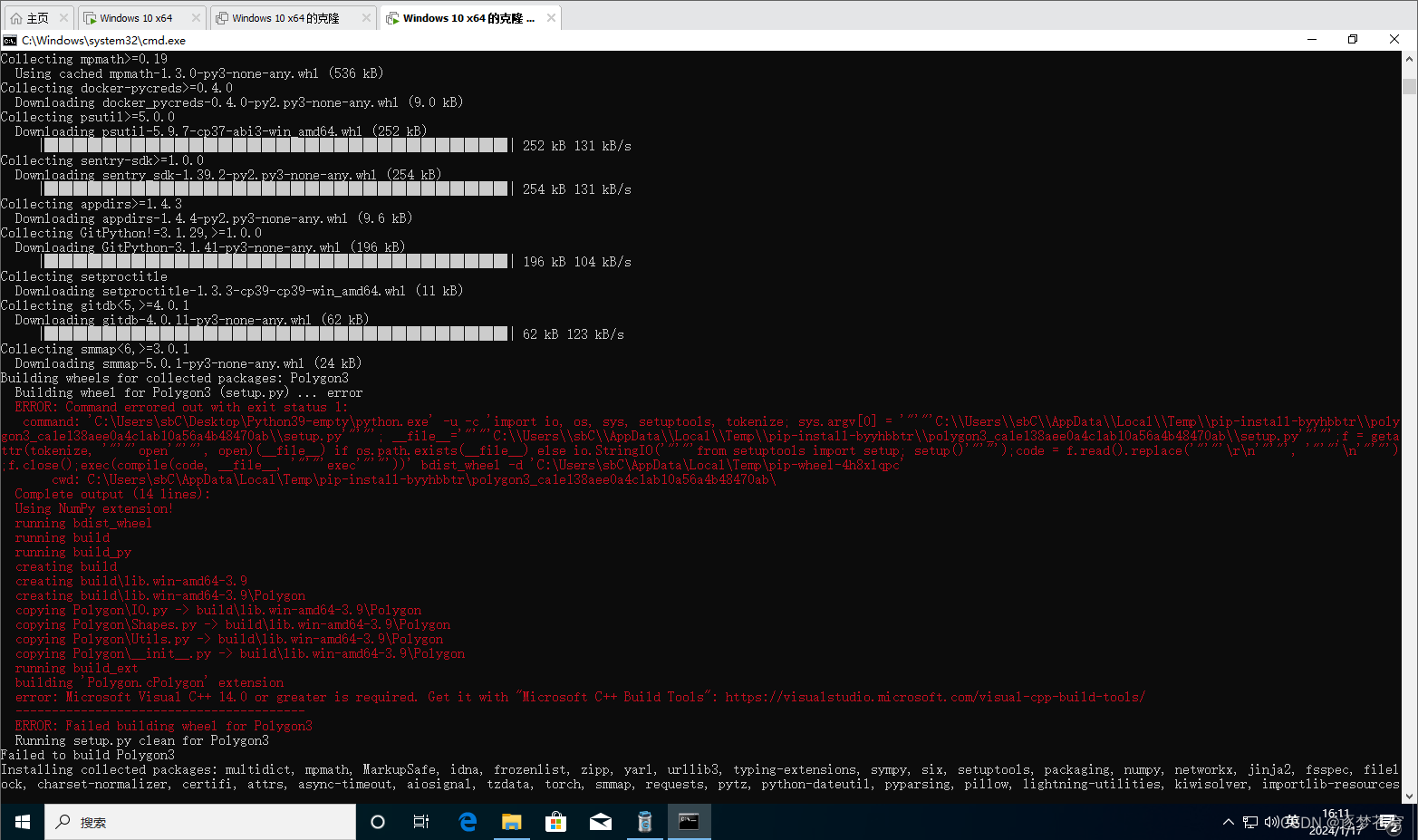
虽然能做到完全解决这个报错,但是很大的缺点是:这玩意太大了……
2.2.2、节约内存的方式
这种方式,能不能成功,看点运气…
第一步:先安装上文提到的两个exe文件
第二步:运行“初始化脚本-1”文件
第三步:运行“初始化脚本-2”文件,此文件运行过程会非常久,因为这是在该文件夹下面安装项目所需依赖环境。不出意外的话,第三步安装到最后一个的时候,会报错,提示缺少C++ 14.0。
第四步:此时需要点开上文提到的两个装好的程序,右键,选择修改:
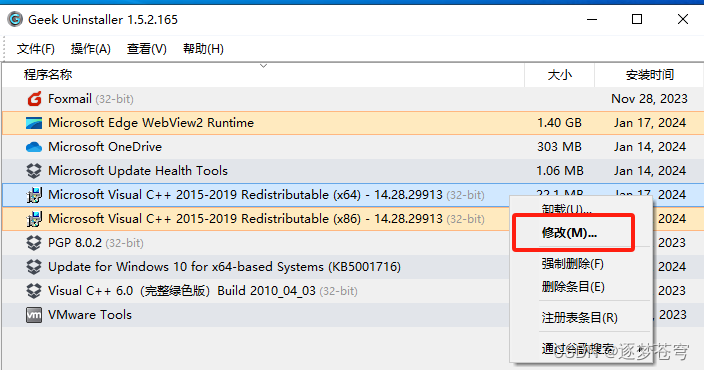
点击修复:
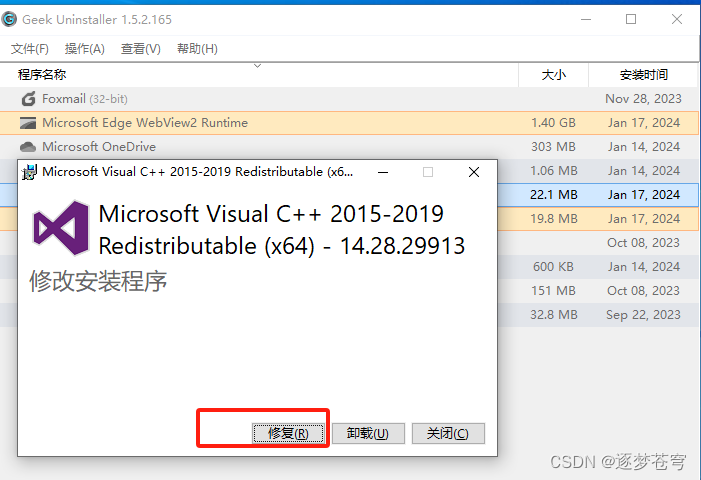
然后重启。
第五步:重启后,重复第三步到第五步的操作(此时第三步的运行速度会很快了),连续操作超过三次,就…建议直接下载完整版吧…(这地方有点玄学,不是百分百能解决…程序作者本人整了三天了!程序就像捉摸不透的人一样,有时成功有时失败)
2.3、⭐完整版安装
完整版的目录,即是下文的最终文件目录。完整版则非常简单,下载-解压-运行主程序一气呵成。
请看下文分解。
3、使用
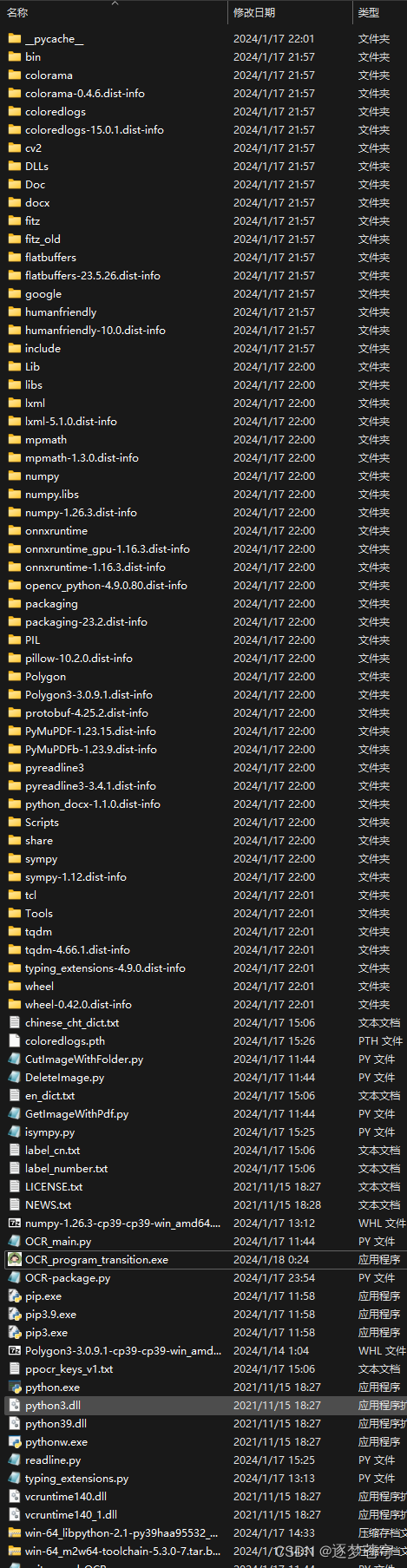
3.1、最终文件目录
3.2、主程序
找到主程序:

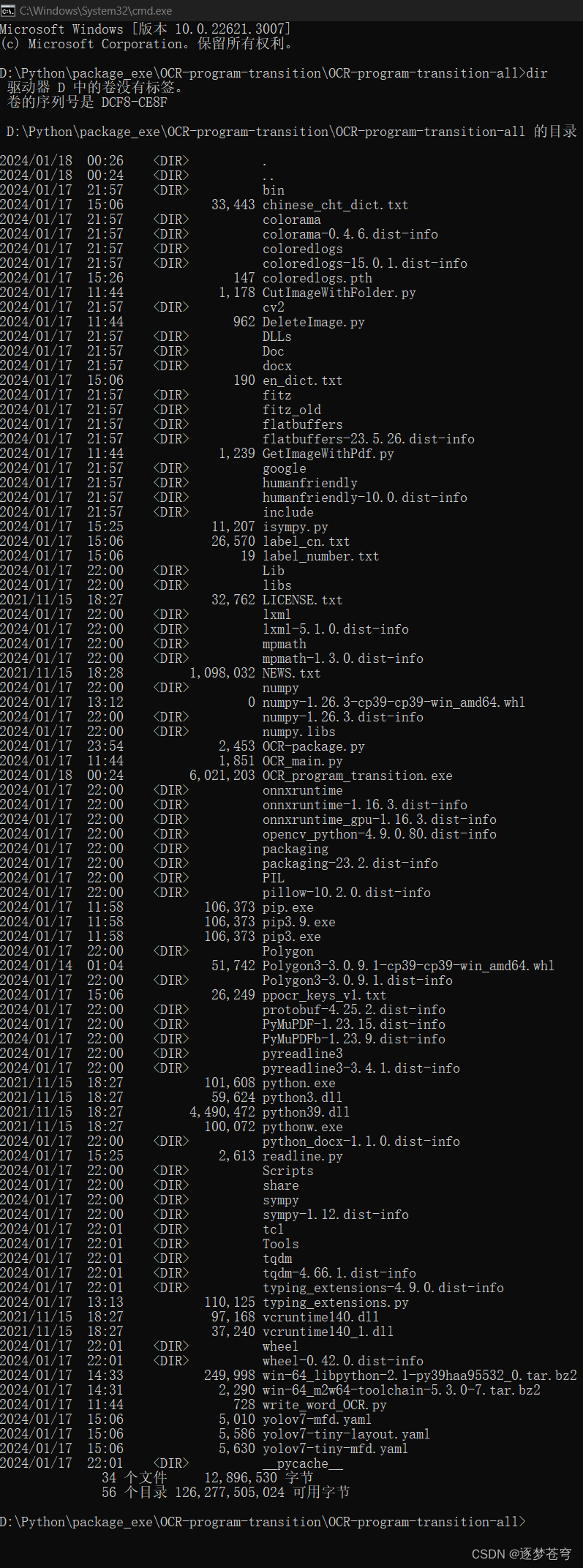
双击运行,按照交互窗口填写对应的内容(如果长时间没有响应,请按一下空格键即可):
3.2.1、绝对路径
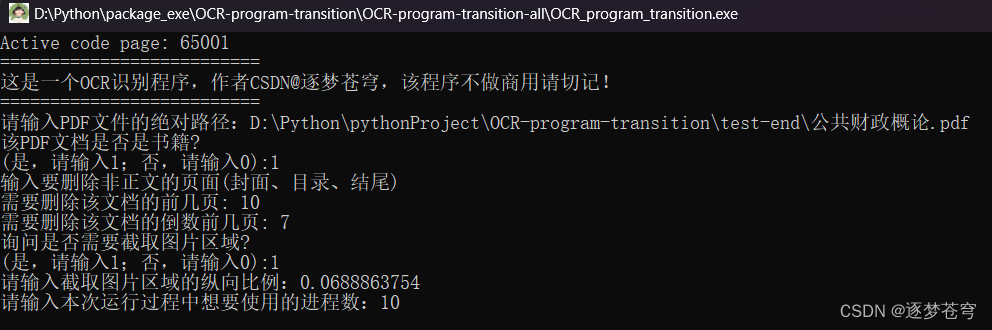
目标文档,鼠标右键,点击安全,即可看见绝对路径:
3.2.2、是否为书籍
作者认为,如果是书籍的话,最好把文档前面的"封面+目录"以及末尾倒数几页的"致谢"内容去除,以提高正确率和可阅读性。该程序不识别格式,所以这样能最大化得到文字信息。
3.2.3、⭐截取区域
如果这是一个电子书的PDF文档,为了识别文字的结果更加准确,方便读者搜索查阅内容,作者认为可以把每一页书的顶部区域的标注去掉,例如这种区域:

这种区域与正文内容无关,可以去掉。
那么如何确定好去掉区域的所占比例呢?下面细说:
使用微信截图功能,确定这个图片的“最大高度”,再确定截取区域的“高度”,二者相除,即可得到比例,图解如下:

3.2.4、⭐进程数
进程数决定了这个多线程程序的执行速度,但也不是数字填的越高越好。
下面给出几个数值参考:
游戏本->20线程
全能本->10-18线程
轻薄本->建议12线程以下
3.3、运行完成
运行完成的结果显示:转换后的文字列表内容+提示信息:

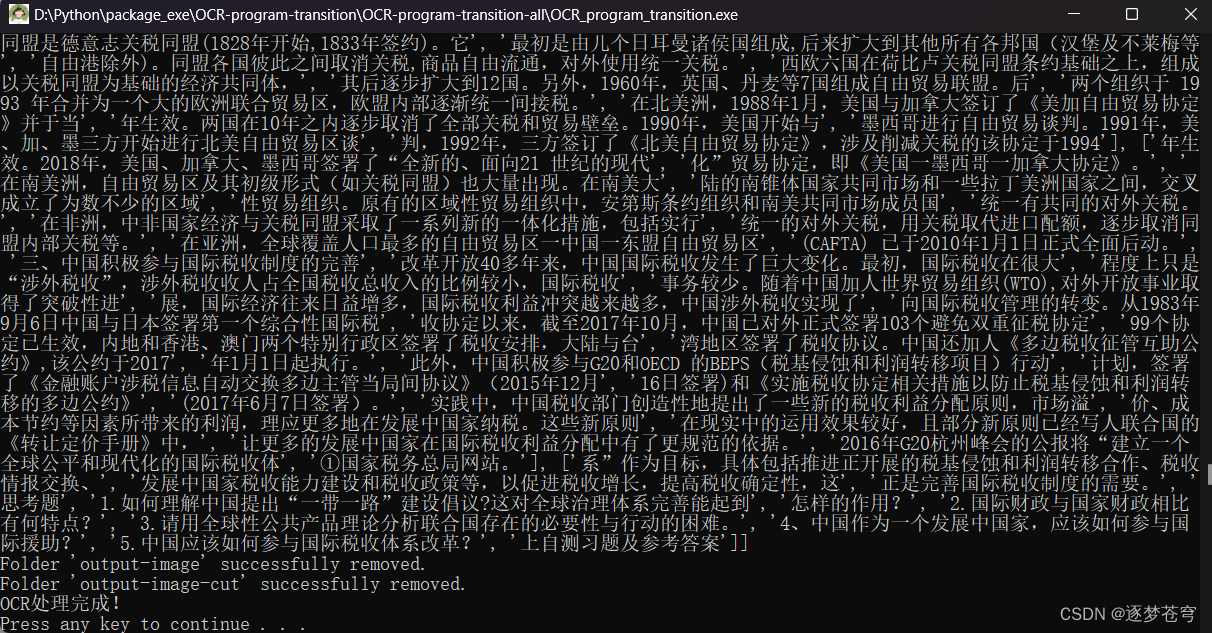
3.4、保存路径
程序运行完成后,默认的保存路径为PDF文件的同目录下。
4、代码详解
4.1、思路
需求是图片式PDF识别转换为文字式可搜索word:
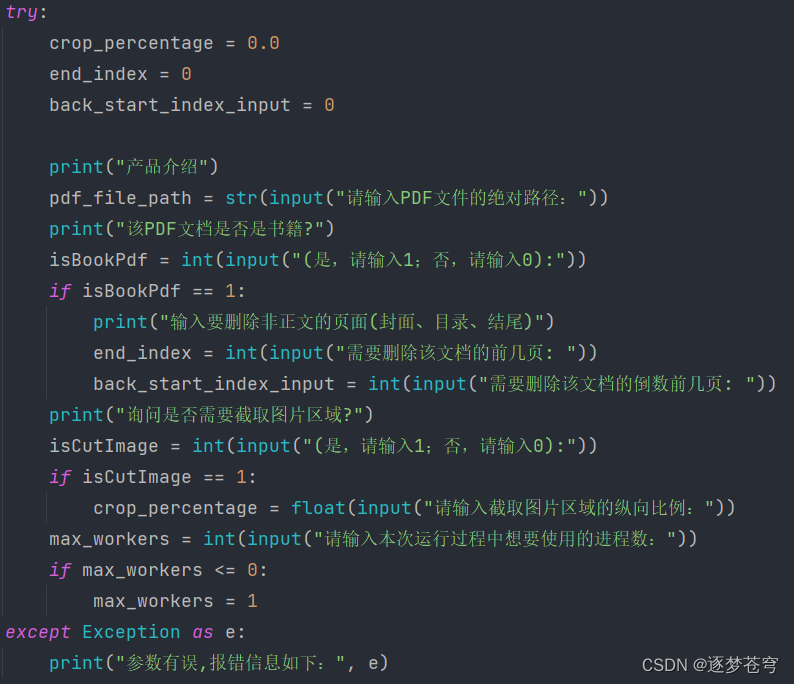
第一步:告诉用户这个产品->介绍
第二步:用户输入图片式PDF的路径(需要的是绝对路径)
第三步:该PDF文档是否是书籍,是:删除非正文的页面(封面、目录、结尾)->在后续步骤执行删除;否,不执行删除操作
第四步:询问是否需要截取图片区域(是,输入截取的比例;否,截取比例制为0)->立即执行->提取到新的文件夹
第五步:用户输入本次运行过程中用到的进程数(游戏本可以输入20,全能本10-15,其他建议10甚至是8以下)
第六步:删除不要的图片区域
第七步:开始处理,把结果写入到PDF同路径下删除过程性文件
第八步:删除过程性文件,把处理结果和处理后的文件路径告诉用户
4.2、交互
4.3、提取图片
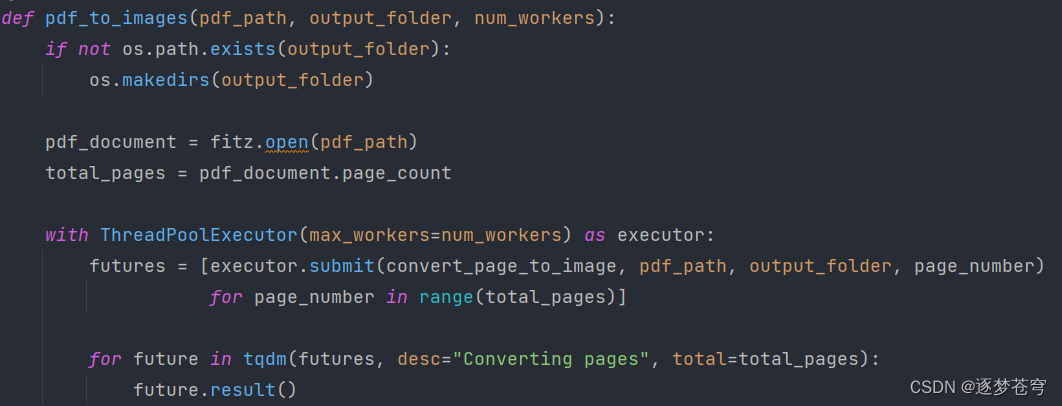
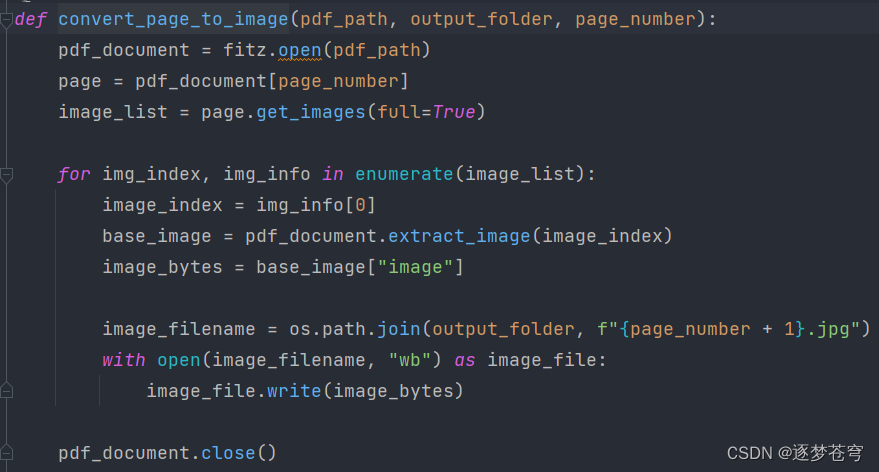
提取图片式PDF文件的每一页,保存到一个临时图片文件夹下面:
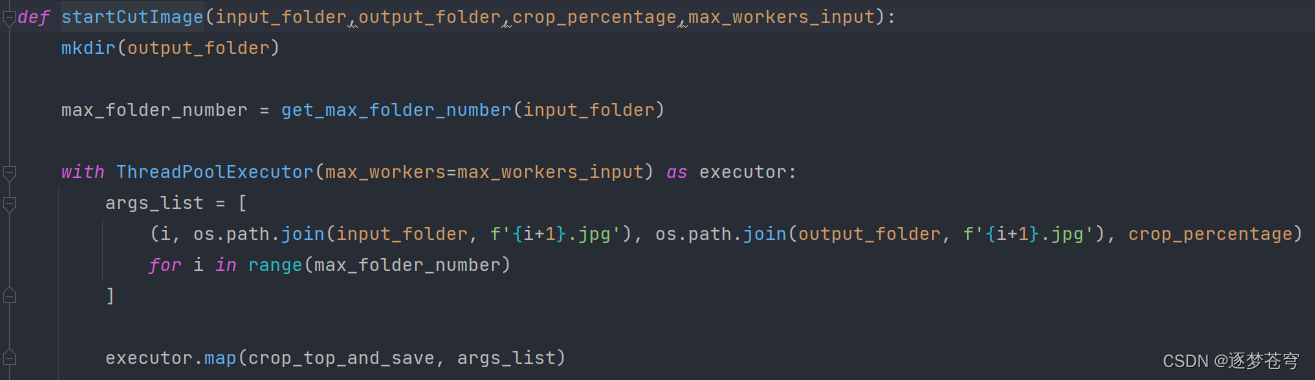
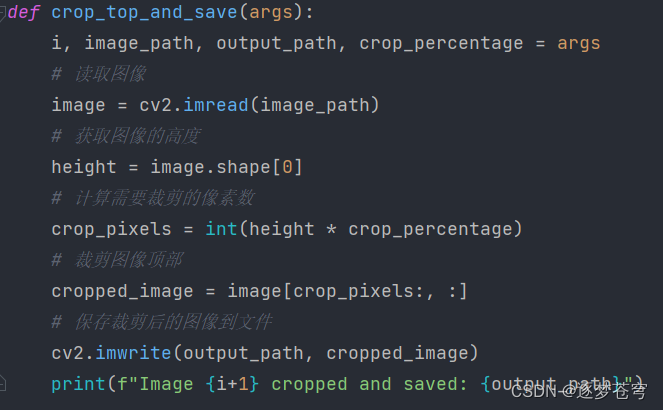
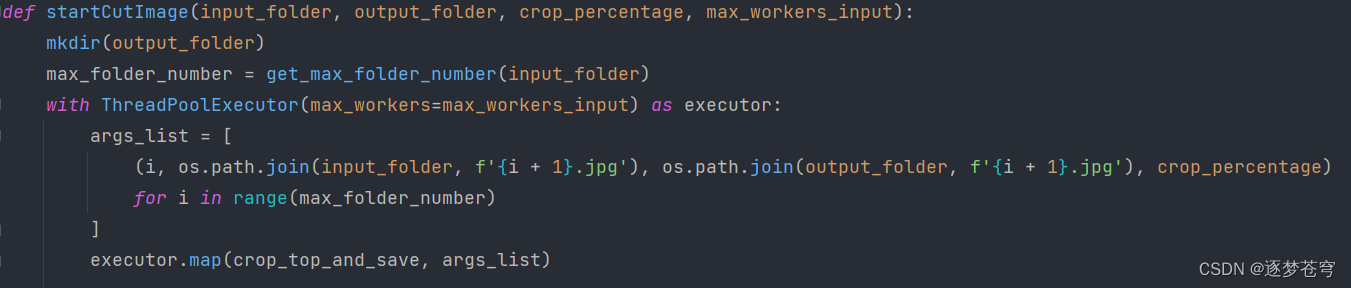
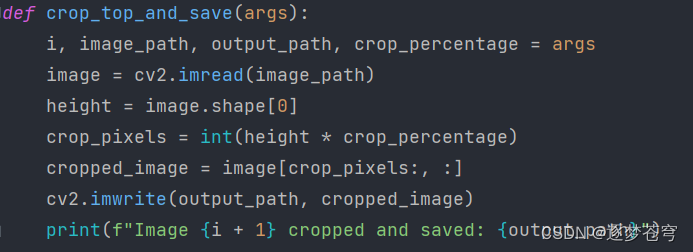
4.4、裁剪图片
4.5、删除不必要的内容
4.5、⭐OCR处理
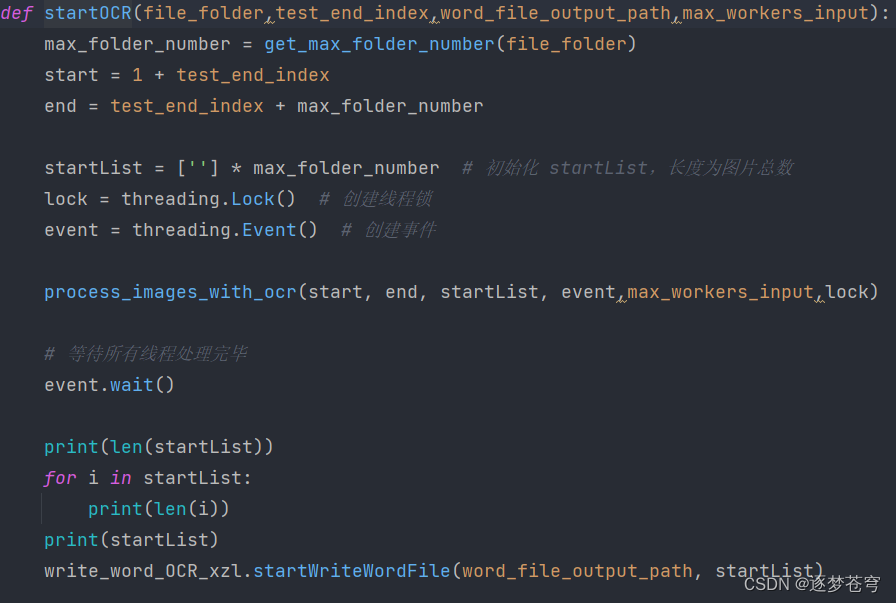
4.5.1、处理裁剪后的图片

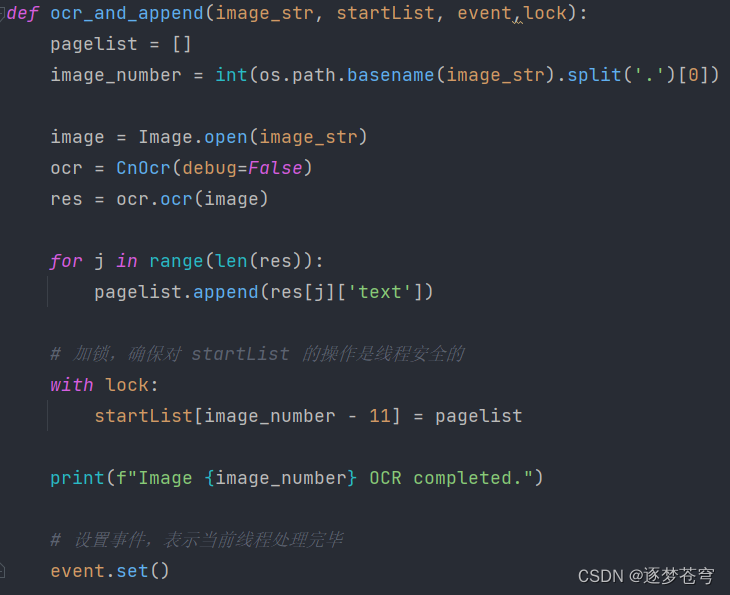
4.5.2、写入文件
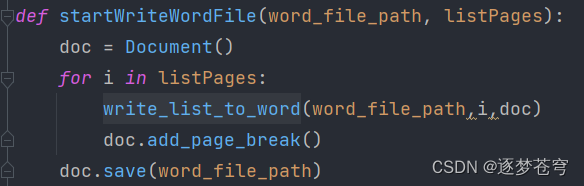
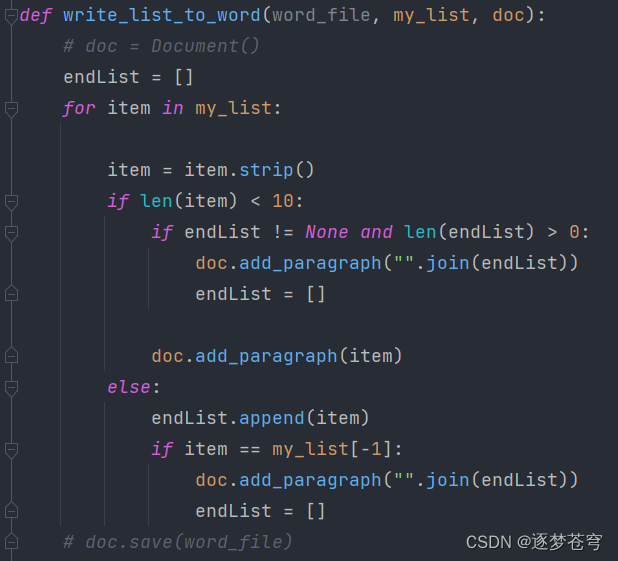
5、⭐完整源代码
代码即注释:
# -*- coding: utf-8 -*-
# @Author:逐梦苍穹
# @Time: 2024/1/18 1:23
import os
import cv2
import fitz
import shutil
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed
from cnocr import CnOcr
from tqdm import tqdm
from PIL import Image
from docx import Document
def mkdir(folder_path):
os.makedirs(folder_path, exist_ok=True)
def get_max_folder_number(folder_path):
image_files = [f for f in os.listdir(folder_path) if f.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp'))]
return len(image_files)
def crop_top_and_save(args):
i, image_path, output_path, crop_percentage = args
image = cv2.imread(image_path)
height = image.shape[0]
crop_pixels = int(height * crop_percentage)
cropped_image = image[crop_pixels:, :]
cv2.imwrite(output_path, cropped_image)
print(f"Image {i + 1} cropped and saved: {output_path}")
def startCutImage(input_folder, output_folder, crop_percentage, max_workers_input):
mkdir(output_folder)
max_folder_number = get_max_folder_number(input_folder)
with ThreadPoolExecutor(max_workers=max_workers_input) as executor:
args_list = [
(i, os.path.join(input_folder, f'{i + 1}.jpg'), os.path.join(output_folder, f'{i + 1}.jpg'), crop_percentage)
for i in range(max_folder_number)
]
executor.map(crop_top_and_save, args_list)
def get_max_folder_number(folder_path):
image_files = [f for f in os.listdir(folder_path) if f.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp'))]
return len(image_files)
def delete_images(folder_path, start_index, end_index):
for i in range(start_index, end_index + 1):
imageStr = str(i) + ".jpg"
file_path = os.path.join(folder_path, imageStr)
os.remove(file_path)
print(f"Deleted: {file_path}")
def startDeleteImage(folder_path, end_index, back_start_index_input):
max_folder_number = get_max_folder_number(folder_path)
if max_folder_number > 0:
start_index = 1
back_start_index = max_folder_number - back_start_index_input + 1
back_end_index = max_folder_number
delete_images(folder_path, start_index, end_index)
delete_images(folder_path, back_start_index, back_end_index)
else:
print("No valid image files found.")
def convert_page_to_image(pdf_path, output_folder, page_number):
pdf_document = fitz.open(pdf_path)
page = pdf_document[page_number]
image_list = page.get_images(full=True)
for img_index, img_info in enumerate(image_list):
image_index = img_info[0]
base_image = pdf_document.extract_image(image_index)
image_bytes = base_image["image"]
image_filename = os.path.join(output_folder, f"{page_number + 1}.jpg")
with open(image_filename, "wb") as image_file:
image_file.write(image_bytes)
pdf_document.close()
def pdf_to_images(pdf_path, output_folder, num_workers):
if not os.path.exists(output_folder):
os.makedirs(output_folder)
pdf_document = fitz.open(pdf_path)
total_pages = pdf_document.page_count
with ThreadPoolExecutor(max_workers=num_workers) as executor:
futures = [executor.submit(convert_page_to_image, pdf_path, output_folder, page_number)
for page_number in range(total_pages)]
for future in tqdm(futures, desc="Converting pages", total=total_pages):
future.result()
def get_max_folder_number(folder_path):
image_files = [f for f in os.listdir(folder_path) if f.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp'))]
return len(image_files)
def ocr_and_append(image_str, startList, event, lock):
pagelist = []
image_number = int(os.path.basename(image_str).split('.')[0])
image = Image.open(image_str)
ocr = CnOcr(debug=False)
res = ocr.ocr(image)
for j in range(len(res)):
pagelist.append(res[j]['text'])
with lock:
startList[image_number - 11] = pagelist
print(f"Image {image_number} OCR completed.")
event.set()
def process_images_with_ocr(start, end, startList, event, max_workers_input, lock):
with ThreadPoolExecutor(max_workers=max_workers_input) as executor:
futures = [executor.submit(ocr_and_append, f'output-image-cut/{i}.jpg', startList, event, lock) for i in
tqdm(range(start, end + 1), desc="OCR Processing")]
for future in as_completed(futures):
future.result()
def startOCR(file_folder, test_end_index, word_file_output_path, max_workers_input):
max_folder_number = get_max_folder_number(file_folder)
start = 1 + test_end_index
end = test_end_index + max_folder_number
startList = [''] * max_folder_number
lock = threading.Lock()
event = threading.Event()
process_images_with_ocr(start, end, startList, event, max_workers_input, lock)
event.wait()
print(len(startList))
for i in startList:
print(len(i))
print(startList)
startWriteWordFile(word_file_output_path, startList)
def startWriteWordFile(word_file_path, listPages):
doc = Document()
for i in listPages:
write_list_to_word(word_file_path, i, doc)
doc.add_page_break()
doc.save(word_file_path)
def write_list_to_word(word_file, my_list, doc):
endList = []
for item in my_list:
item = item.strip()
if len(item) < 10:
if endList != None and len(endList) > 0:
doc.add_paragraph("".join(endList))
endList = []
doc.add_paragraph(item)
else:
endList.append(item)
if item == my_list[-1]:
doc.add_paragraph("".join(endList))
endList = []
def main():
try:
crop_percentage = 0.0
end_index = 0
back_start_index_input = 0
print("==========================")
print("这是一个OCR识别程序,作者CSDN@逐梦苍穹,该程序不做商用请切记!")
print("==========================")
pdf_file_path = str(input("请输入PDF文件的绝对路径:"))
print("该PDF文档是否是书籍?")
isBookPdf = int(input("(是,请输入1;否,请输入0):"))
if isBookPdf == 1:
print("输入要删除非正文的页面(封面、目录、结尾)")
end_index = int(input("需要删除该文档的前几页: "))
back_start_index_input = int(input("需要删除该文档的倒数前几页: "))
print("询问是否需要截取图片区域?")
isCutImage = int(input("(是,请输入1;否,请输入0):"))
if isCutImage == 1:
crop_percentage = float(input("请输入截取图片区域的纵向比例:"))
max_workers = int(input("请输入本次运行过程中想要使用的进程数:"))
if max_workers <= 0:
max_workers = 1
except Exception as e:
print("参数有误,报错信息如下:", e)
try:
pdf_to_images(pdf_file_path, 'output-image', max_workers)
if isCutImage == 1:
startCutImage('output-image', 'output-image-cut', crop_percentage, max_workers)
if isBookPdf == 1:
startDeleteImage('output-image-cut', end_index, back_start_index_input)
file_name = os.path.splitext(os.path.basename(pdf_file_path))[0]
directory_path = os.path.dirname(pdf_file_path)
word_file_path = directory_path + '\\' + file_name + '(OCR_XZL).docx'
startOCR(r'output-image-cut', end_index, word_file_path, max_workers)
except Exception as e:
print("处理过程出错,报错信息如下:", e)
try:
delete_path_1 = r"output-image"
delete_path_2 = r"output-image-cut"
shutil.rmtree(delete_path_1)
shutil.rmtree(delete_path_2)
print(f"Folder '{delete_path_1}' successfully removed.")
print(f"Folder '{delete_path_2}' successfully removed.")
print("OCR处理完成!")
except Exception as e:
print("删除过程性文件出错,原因如下:", e)
if __name__ == '__main__':
main()