书接前文
前文链接:用BEVformer来卷自动驾驶-3 (qq.com)
上文书介绍了BEVformer是个啥,以及怎么实现Deformable-attention
我们继续
BEVformer的输入数据格式:
-
输入张量(batachsize,queue,cam,C,H,W)
-
queue表示连续帧的个数,主要解决遮挡问题
-
cam表示图像数量/per 帧
-
C,H,W就是chw也就是图片通道数(3),高度,宽度
其他都好理解,可能queue和cam不好理解
比如你当前时刻是t,那么queue我想设置成3,就意味着,除了当前时刻以外,t-1和t-2时刻的信息我要一并拿来计算
cam:可以简单理解成摄像头的数量,比如按我前几章的逻辑图画的 样子,那么cam<=6
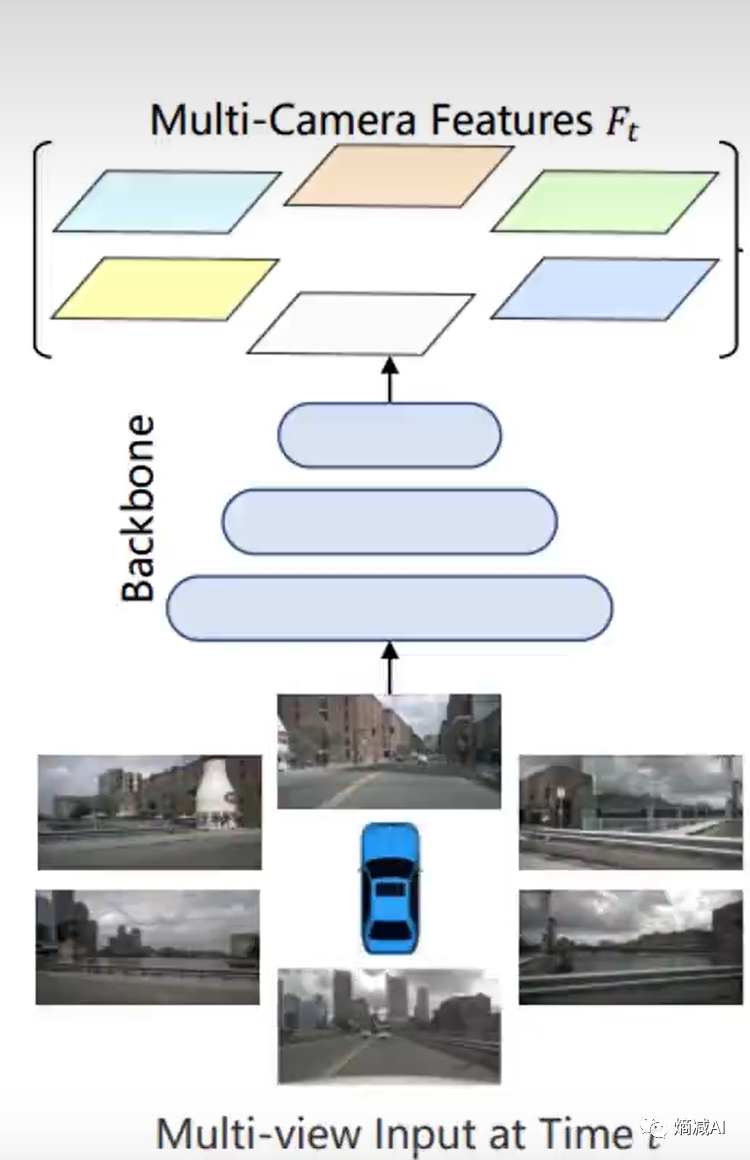
BEVformer Backbone:
-
Backbone就是提取特征的网络
-
啥网络都行,最好要速度快,比如Resnet,也可以VIT(带Transformer的都得优化)
-
按上图来说就抽6个摄像头的特征,给空间注意力用
-
BEV的特征空间里面的每个点,都要在这些特征里采样(可以参见上节课讲的逻辑)
回顾一下上节课我们时间注意力的时候,采样采了4个点,可以理解为4N
那么是不是有点少呢,比如我可以采8N或者N^2,是不是特征值摘取的更多,我的结果越和现实拟合呢?

论文上的结果和大家理解的大相径庭,可以看到采样为global的大家可以简单理解为跟所有的点都做attention计算,就是N^2,而Local就是4N,就是我们之前讲过的方式,明显看到在NDS和mAP的这些数据里都是Local(4N)更有优势,当然FLOPs算力效率更高,Memory也占用更小
这个东西怎么解释,没法解释...
如果强解释,我个人认为,和数据采样有关,因为你的BEV高维空间上的点(向量),在计算attetion的时候,实际上跟你有关的可能就那么几个点,如果你把所有的点都引入,也许带来了不必要的噪音,使结果反而没有就几个点的计算方式好
那我们总结一下:

在不考虑空间注意力机制的情况,我们用DeformableAttetion单靠时间注意力机制,在没有和其他的摄像头特征融合的时候,我已经有了先验数据,这部分先验数据哪来的?就是历史上t-2时刻和t-1时刻给我拿来init用的
下面讨论空间注意力机制:
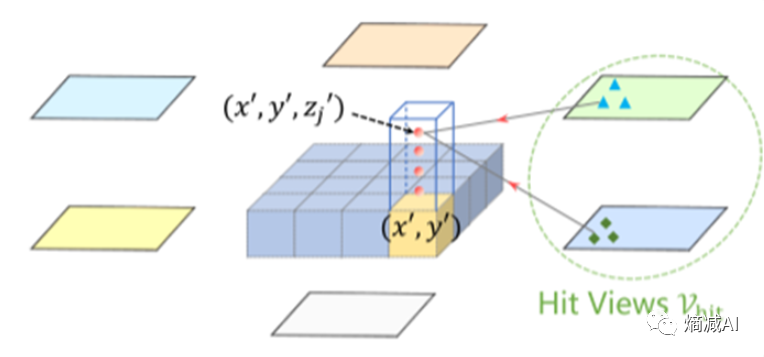
从时间维度的注意力,我已经得到了先验的特征的向量(t-1,t-2带过来算出来的)然后我这个点(向量)相当于一个query,这个query要和周边的几个带颜色(cam)一起算空间注意力了
这就引入了一个新的概念Cross-attetion,因为x'y'这个向量它要和其他的特征空间(摄像头)里的不同的点做attetion计算,所以叫Cross
BEV是个3D空间,摄像头出来的是2D空间,所以要做3D到2D的投影
如上图所示,和时间注意力一样,我也不能和所有的点都做attetion,所以我又找出来个4N,依旧是DeformableAttention的思想,4N>8N>N^2
找出来一个摄像头就给我贡献了4个特征,剩下就是考虑到几个摄像头给我贡献了(参见第二章,第三章的逻辑),然后把所有的拿到的特征一起计算
最后一个需要注意的,论文里提出来需要考虑的一个特征"高度",因为在现实社会里,我们实际上的物体是有高矮的区分,所以如上图所示,其实并不是一个向量,比如图里画了4个向量,就是不同高度的向量分别去和跟它们相关的摄像头去计算。
心细的读者已经有想法了,这是啥啊?是不是就是和Transformer里的多头注意力MHA机制很像啊?我个人也很倾向于把这个当多头注意力机制去理解,因为高度这个东西就更抽象了,多高算高呢,怎么把一个合理的高度空间分成4份呢?
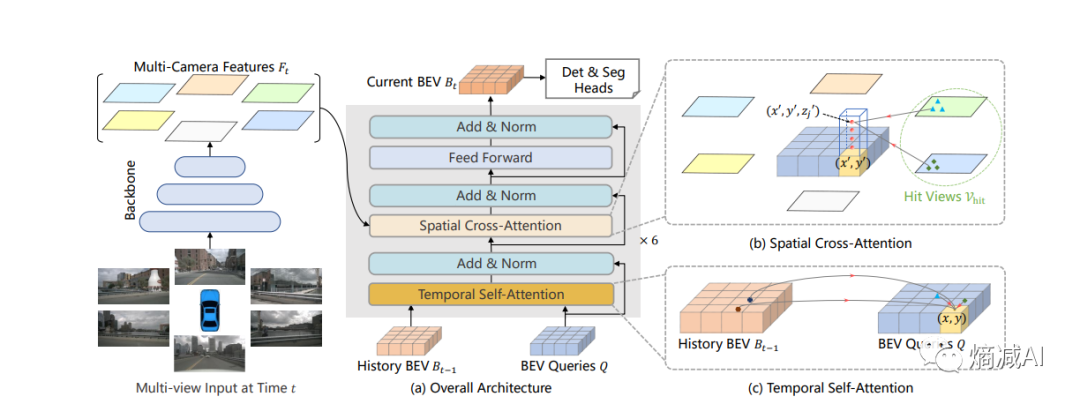
整体流程就如上图所示了,在回忆一下我们前面的学习的知识串讲一下
-
首先,有一个backbone,确定自己有几个视角
-
其次,生成一个BEV的3D(4D加入了时间的概念)特征空间
-
再次,做基于时间的attention,主要一定是先做基于时间的,因为有了先验数据(比如t-2,t-1)
-
最后,做空间(和几个摄像头做attetion,cam的取值)的cross-attetion
后来又出了一系列的feature优化,看看就行
-
Corner pooling(针对性检测)
-
多尺度特征图
-
偏移量的预测增大卷积核(比如1*1换成3*3)
-
做好的BEV空间可以集成多检测器,比如基于Anchor的收敛速度快,适合检测大物体,基于DETR的,对小物体更友好,给了更多的选择
以上这些可能在下一篇或者后续新开连载再讲
BEV和BEVformer理论部分就到此结束了,其实方法没那么复杂,挺简单的,但是思路很棒,基本也会成为纯视觉自动驾驶的标配
本节完