PCIE设备透传解决的是使虚拟机直接访问PCIE设备的技术,通常情况下,为了使虚拟机能够访问Hypervisor上的资源,QEMU,KVMTOOL等虚拟机工具提供了"trap and emulate", Virtio半虚拟化等机制实现。但是这些实现都需要软件的参与,性能较低。
trap and emulate情况下,虚拟机每次访问硬件资源都要进行VMExit退出虚拟机执行相应的设备模拟或者访问设备的操作,完成后再执行VMEnter进入虚拟机。频繁的模式切换导致IO访问的低效。

而Virtio则是一种半虚拟化机制,要求虚拟机中运行的操作系统需要加载特殊的virtio前端驱动(Virtio-xxx),虚拟机通过循环命令队列和Hypervisor上运行的Virtio后端驱动进行通信,后端驱动负责适配不同的物理硬件设备,再收到命令后,后端驱动执行命令。

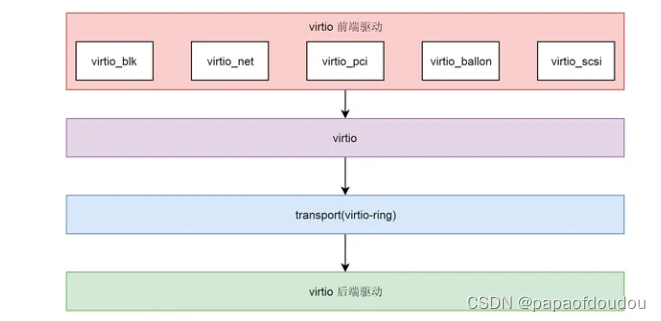
PCIE设备透传到底"透"了什么?
参考如下两篇文章搭建PCIE设备PASS-THROUGH的环境:
KVM虚拟化之小型虚拟机kvmtool的使用-CSDN博客
ubuntu18.04下pass-through直通realteck PCI设备到qemu-kvm虚拟机实践_kvm网卡直通-CSDN博客
透了HOST MEMORY
设备透传解决了让虚拟机中的驱动使用IOVA访问物理内存的问题,在KVMTOOL中,它是通过调用VFIO的VFIO_IOMMU_MAP_DMA 命令来实现的,用来将IOVA映射到具体的物理页面上(通过HVA 得到HVA对应的物理页面,再进行映射)。下图说明了一切问题:

0.映射SIZE为整个GPA大小,也就是虚拟机的整个物理内存。
1.kvm->ram_start和bank->host_addr相同,表示被映射的区域,VFIO驱动会通过bank->host_addr找到对应的PAGE页面。
2.iova为bank->guest_phys_addr,也就是虚拟机内的GPA。也就是说,IOMMU页表建立后,透传的设备驱动可以通过和CPU一致的物理地址,访问到真实的物理页面上(HPA),这样,从CPU和涉笔的角度,可以做大IOVA==GPA。
3.映射完成后,从虚拟机的角度来看,CPU看到的物理地址(GPA)和硬件看到的物理地址(IOVA)都通过各自的路径(前者通过EPT,后者通过IOMMU)访问同一个存储单元。

GPA和IOVA建立后的效果如下,设备和CPU通过一个地址,访问到同一个物理单元,这样虚拟机系统不需通过VMM就可以直接访问到设备,这就是设备“透传”的本质吧。
下面是一个演示设备透传的程序:
#include <stdio.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <unistd.h>
#include <string.h>
#include <sys/mman.h>
#include <errno.h>
#include <linux/vfio.h>
#define IOVA_DMA_MAPSZ (1*1024UL*1024UL)
#define IOVA_START (0UL)
#define VADDR 0x400000000000
// refer https://www.cnblogs.com/dream397/p/13546968.html
// container fd: the container provides little functionality, with all but a couple vrson and extension query interfaces.
// 1. first identify the group associated wth the desired device.
// 2. unbinding the device from the host driver and binding it to a vfio driver, then a new group would appear for the group as /dev/vfio/$group.
// make sure all the devices belongs to the group are all need to do the unbind and binding operations or error will got for next group ioctl.
// 3. group is ready, then add to the caontainer by opening the vfio group character device and use VFIO_GROUP_SET_CONTAINER ioctl to add the group
// fd to container.depending the iommu, multi group can be set to one container.
// 4. after group adding to container, the remaning ioctls became available. enable the iommu device access.now you can get each device belongs the
// iommu group and get the fd.
// 5. the vfio device ioctls includes for describing the device, the IO regions, and their read/write/mmap operations, and others such as describing
// and registering interrupt notificactions.
/*
* #1:echo vfio-pci > /sys/bus/pci/devices/0000:02:00.0/driver_override
* #2:echo 10de 1d13 > /sys/bus/pci/drivers/vfio-pci/new_id
*root@zlcao-RedmiBook-14:~# ls -l /dev/vfio/
*总用量 0
*crw------- 1 root root 243, 0 11月 8 12:40 12
*crw-rw-rw- 1 root root 10, 196 11月 8 12:31 vfio
*/
int main(void)
{
int container, group, device, i;
void *maddr = NULL;
struct vfio_group_status group_status = { .argsz = sizeof(group_status) };
struct vfio_iommu_type1_info *iommu_info = NULL;
size_t iommu_info_size = sizeof(*iommu_info);
struct vfio_device_info device_info = { .argsz = sizeof(device_info) };
struct vfio_iommu_type1_dma_map dma_map;
struct vfio_iommu_type1_dma_unmap dma_unmap;
container = open("/dev/vfio/vfio", O_RDWR);
if (container < 0) {
printf("%s line %d, open vfio container error.\n", __func__, __LINE__);
return 0;
}
if (ioctl(container, VFIO_GET_API_VERSION) != VFIO_API_VERSION) {
printf("%s line %d, vfio api version check failure.\n", __func__, __LINE__);
return 0;
}
if (ioctl(container, VFIO_CHECK_EXTENSION, VFIO_TYPE1_IOMMU) == 0) {
printf("%s line %d, vfio check extensin failure.\n", __func__, __LINE__);
return 0;
}
group = open("/dev/vfio/9", O_RDWR);
if (group < 0) {
printf("%s line %d, open vfio group error.\n", __func__, __LINE__);
return 0;
}
if (ioctl(group, VFIO_GROUP_GET_STATUS, &group_status)) {
printf("%s line %d, failed to get vfio group status.\n", __func__, __LINE__);
return 0;
}
if ((group_status.flags & VFIO_GROUP_FLAGS_VIABLE) == 0) {
printf("%s line %d, vfio group is not viable.\n", __func__, __LINE__);
return 0;
}
if (ioctl(group, VFIO_GROUP_SET_CONTAINER, &container)) {
printf("%s line %d, vfio group set conatiner failure.\n", __func__, __LINE__);
return 0;
}
if (ioctl(container, VFIO_SET_IOMMU, VFIO_TYPE1_IOMMU) != 0) {
printf("%s line %d, vfio set type1 mode failure %s.\n", __func__, __LINE__, strerror(errno));
return 0;
}
iommu_info = malloc(iommu_info_size);
if (iommu_info == NULL) {
printf("%s line %d, vfio alloc iommu info failure %s.\n", __func__, __LINE__, strerror(errno));
return 0;
}
memset(iommu_info, 0x00, iommu_info_size);
iommu_info->argsz = iommu_info_size;
if (ioctl(container, VFIO_IOMMU_GET_INFO, iommu_info)) {
printf("%s line %d, vfio failed to get iomu info, %s.\n", __func__, __LINE__, strerror(errno));
return 0;
}
// todo
// collect available iova regions from VFIO_IOMMU_GET_INFO.
// 0000:02:00.0 must in this group.
device = ioctl(group, VFIO_GROUP_GET_DEVICE_FD, "0000:02:00.0");
if (device < 0) {
printf("%s line %d, get vfio group device error.\n", __func__, __LINE__);
return 0;
}
ioctl(device, VFIO_DEVICE_RESET);
if (ioctl(device, VFIO_DEVICE_GET_INFO, &device_info)) {
printf("%s line %d, get vfio group device info error.\n", __func__, __LINE__);
return 0;
}
{
struct vfio_region_info region = {
.index = VFIO_PCI_CONFIG_REGION_INDEX,
.argsz = sizeof(struct vfio_region_info),
};
if (ioctl(device, VFIO_DEVICE_GET_REGION_INFO, ®ion)) {
printf("%s line %d, get vfio group device region info error.\n", __func__, __LINE__);
return 0;
}
}
maddr = mmap((void *)VADDR, IOVA_DMA_MAPSZ, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS | MAP_FIXED, -1, 0);
if (maddr == MAP_FAILED) {
printf("%s line %d, faild to map buffer, error %s.\n", __func__, __LINE__, strerror(errno));
return -1;
}
memset(&dma_map, 0x00, sizeof(dma_map));
dma_map.argsz = sizeof(dma_map);
dma_map.flags = VFIO_DMA_MAP_FLAG_READ | VFIO_DMA_MAP_FLAG_WRITE;
dma_map.iova = IOVA_START;
dma_map.vaddr = (unsigned long)maddr;
dma_map.size = IOVA_DMA_MAPSZ;
if (ioctl(container, VFIO_IOMMU_MAP_DMA, &dma_map)) {
printf("%s line %d, faild to do dma map on this conatainer.\n", __func__, __LINE__);
return -1;
}
printf("%s line %d, do vfio dma mamp 1M memory buffer success, the iova is 0x%llx, dmaavddr 0x%llx, userptr %p.\n",
__func__, __LINE__, dma_map.iova, dma_map.vaddr, maddr);
memset(&dma_unmap, 0x00, sizeof(dma_unmap));
dma_unmap.argsz = sizeof(dma_unmap);
dma_unmap.iova = IOVA_START;
dma_unmap.size = IOVA_DMA_MAPSZ;
if (ioctl(container, VFIO_IOMMU_UNMAP_DMA, &dma_unmap)) {
printf("%s line %d, faild to do dma unmap on this conatainer.\n", __func__, __LINE__);
return -1;
}
munmap((void *)maddr, IOVA_DMA_MAPSZ);
close(device);
close(group);
close(container);
return 0;
}测试程序在IOMMU上影射了1M的空间,IOVA范围为[0, 0x100000],我们DUMP PCIE连接IOMMU其页表为:

然后DUMP HOST HVA[0x400000000000,0x400000100000]范围的页表映射:

仔细对比两张截图,会发现他们的物理页框顺序完全一致,这样,在虚拟机中CPU通过GPA访问得到的数据和设备通过同样的IOVA访问的数据会保持一致,就像在真实的硬件上执行时的情况一样,这就是透传的效果,IOMMU功不可没,它让GUEST OS中具备了越过VMM直接访问设备的能力。
透了PCIE BAR空间
PCIE BAR空间的透传,有空在分析!
参考文章
基于virtio的半虚拟化概述 - 知乎

![[小程序]样式与配置](https://img-blog.csdnimg.cn/direct/b8bdaca0e23b40f6bd94293e359ea003.png)