看几篇中文的学习一下别人的思路
- 基于全局-局部自注意力网络的视频异常检测方法
- 主要贡献:
- 网络结构
- 注意力模块结构:
- 融合自注意力和自编码器的视频异常检测
- 主要贡献:
- 网络结构
- Transformer模块
- 动态图
- 融合门控自注意力机制的生成对抗网络视频异常检测
- 贡献
- 网络结构
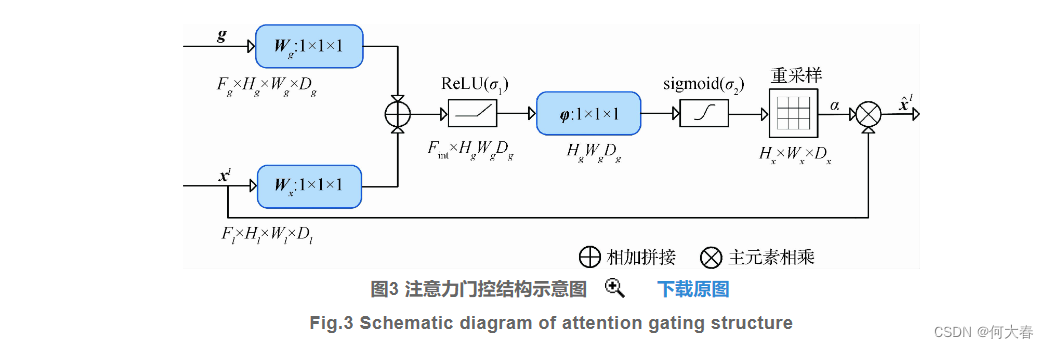
- 门控注意力机制
基于全局-局部自注意力网络的视频异常检测方法
文章信息:

链接:https://kns.cnki.net/kcms2/article/abstract?v=FY8FZShUIjGtR3ED9H4lwnExLaJ3z-kfwPv1HujOqotZMfpdRr-ETlKpVGwgsyGVblKfsr1kFyunmlxIeOIbLKc5dQB9iBqMESsg4AsfheeiZ1OQCWHX8K54W8OIaAeWuAxkpGlU5grzU6EtO2hBfA==&uniplatform=NZKPT&language=CHS
主要贡献:
- 采用“双编码器-单解码器”的编解码混合结构,充分利用原始视频的多维信息,并通过自注意力模块实现有效的解码,从而使模型能够准确表示和理解视频数据。
- 使用多源数据作为输入,充分利用运动和外观信息的互补,并综合考虑不同信息源以全面分析视频数据,从而更加准确地识别异常行为。
- 提出一种基于全局-局部自注意力机制的视频异常检测方法,通过全局-局部自注意力机制综合考虑整体和局部的时序相关性,能够更好地理解视频序列中不同时间尺度的连续性,并保持局部上下文信息的一致性。
- 对UCSD Ped2、CUHK Avenue和Shanghai Tech数据集进行测试,实验结果表明,本文方法的检测精度分别达到97.4%、86.8%和73.2%,而且与现有方法相比,本文方法明显提升了视频异常检测的能力和鲁棒性,为视频异常检测的深入研究和实际应用提供了一定支撑。
网络结构
主要是双编码器、注意力模块、解码器
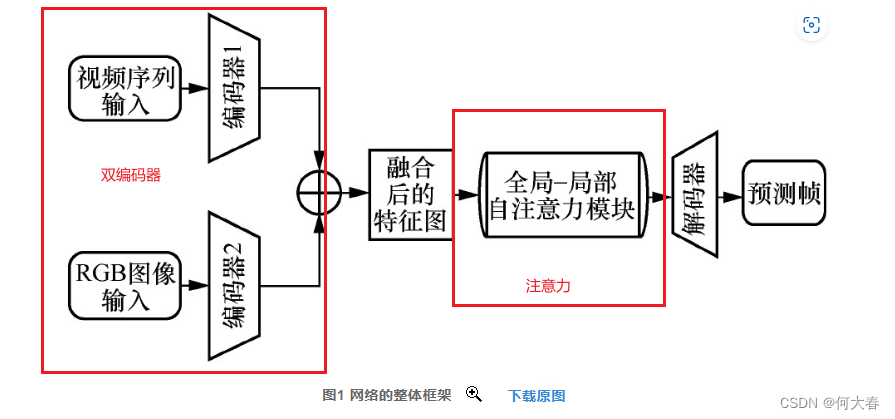
注意力模块结构:
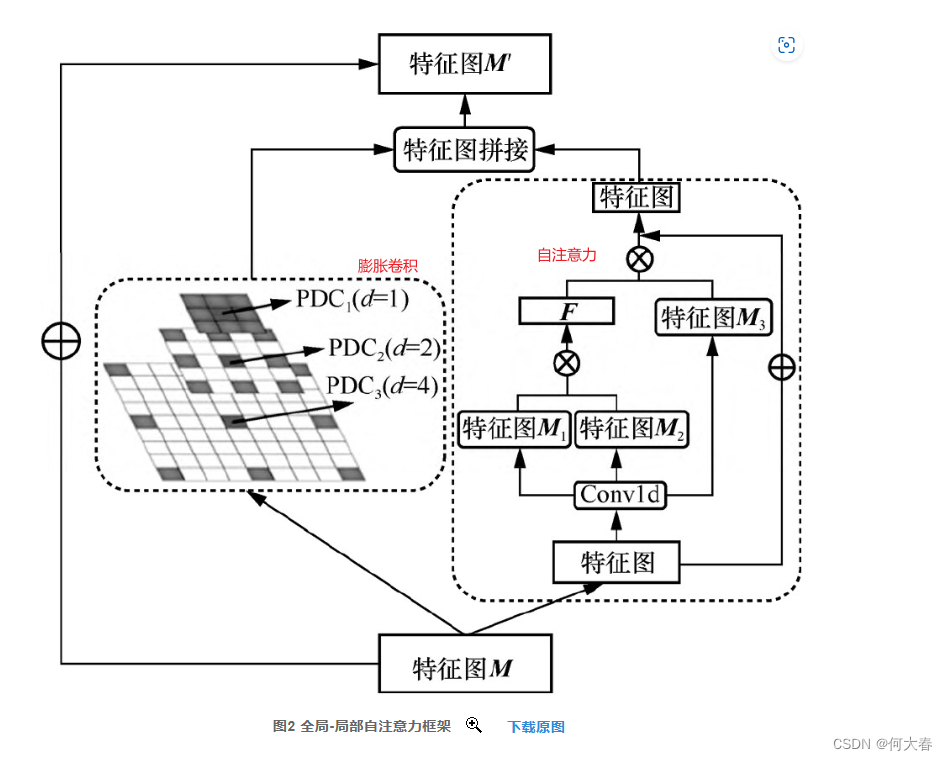
融合自注意力和自编码器的视频异常检测
文章信息:

文章链接:https://kns.cnki.net/kcms2/article/abstract?v=FY8FZShUIjGm28qSIBRR5HDmMGuL1Feyl67y-wYwJ7nUXtdTVPSuX1vlTzLmRbNr19nM_RgUgZ8iummOVivtWsEB3RYYntv9F_eHFlXMljXSQIw_VGFiLHjiWXJp5tpRbYb6ldGrw0V5wrJuHAYsgw==&uniplatform=NZKPT&language=CHS
主要贡献:
- 提出了基于Transformer和U-Net混合网络的视频异常检测算法,将基于自注意力机制的Transformer嵌入U-Net网络学习正常事件的局部和全局时空信息,捕捉更丰富的特征信息。
- 现有的异常检测数据集大多基于室外远景运动信息,本文进一步收集了针对异常分析的室内动作数据集。针对周期性的近景手部动作,除了传统的重建损失外,本文进一步引入动态图约束引导网络关注运动轨迹区域。
- 本文在4个室外和1个室内数据集上进行了实验,与现有方法相比本文方法的异常检测性能更好。
网络结构
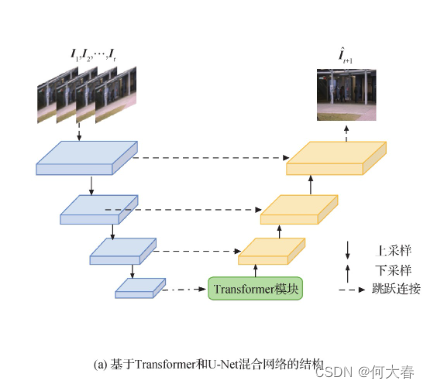
Transformer模块
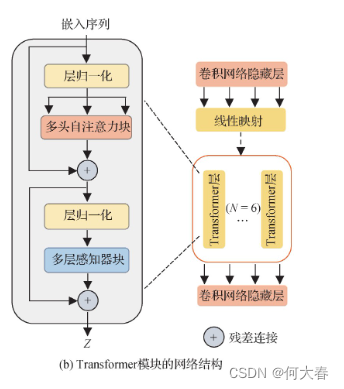
Transformer模块的结构如图2(b)所示,其中Transformer编码器由N层多头自注意力块(multi-head self-attention)和多层感知器块(multi-layer perceptron,MLP)组成,通过对远距离依赖建模从而提高网络的特征表达能力。每个块前后都应用了层归一化(layer norm)和残差连接。最后,将Transformer模块得到的隐藏特征z调整为U-Net编码器原来的尺寸,解码器对编码特征进行上采样,并与编码器中相同分辨率的低层特征融合,将全局空间信息与局部细节信息结合,从而捕捉更丰富的特征信息。
动态图
引入了动态图作为损失函数的注意力图,如下公式所示,作者将动态图引入到了损失函数中:

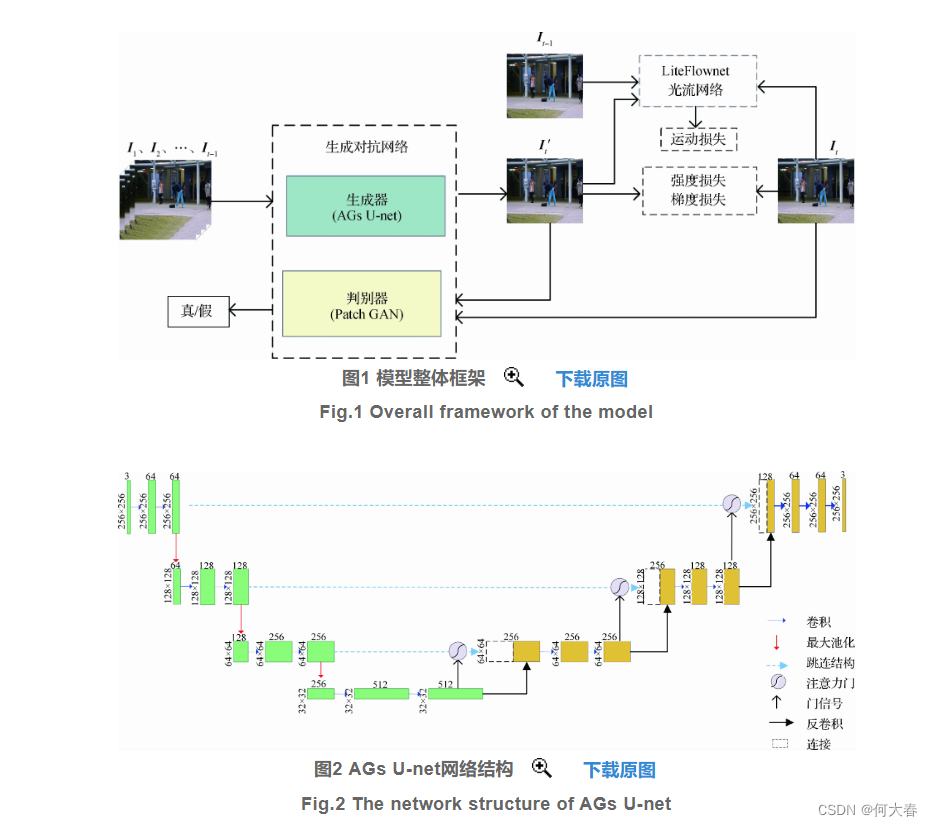
融合门控自注意力机制的生成对抗网络视频异常检测
文章信息:
链接:https://kns.cnki.net/kcms2/article/abstract?v=FY8FZShUIjFwKn5KHOciqgG5THwAEGgaTBLxJ92Zpr0dZoYvsOg2EekwJInek5ONBguXDE9m-DDN5MIj_se3HnRznWkQf-0-qlJM_qXO8NU2536G3JBBj4IsgnAvskYTq99tlFpxTlJUhbz8hw-Rqg==&uniplatform=NZKPT&language=CHS
贡献
- 考虑视频序列帧之间的时间和空间2维关系,提出一种改进的异常行为检测模型。利用生成对抗网络中的生成模块对视频中的空间特征进行提取,利用LiteFlownet光流网络对运动信息的时间特征进行提取,引入门控自注意力机制对特征图进行加权处理,实现了视频序列之间时空特征更有效的表达。
- 引入门控自注意力机制,逐层对U-net采样过程中的特征进行加权计算。该自注意力机制在视频帧的单层特征中对远距离且具有空间相关性的特征进行建模,可自动寻找图像特征中的相关部分,提高对视频帧中时间和空间两个维度的特征响应。
- 选用LiteFlownet光流网络对运动信息进行提取,得到视频帧之间的时间关联,进一步提高了该模型的检测性能。
网络结构
门控注意力机制