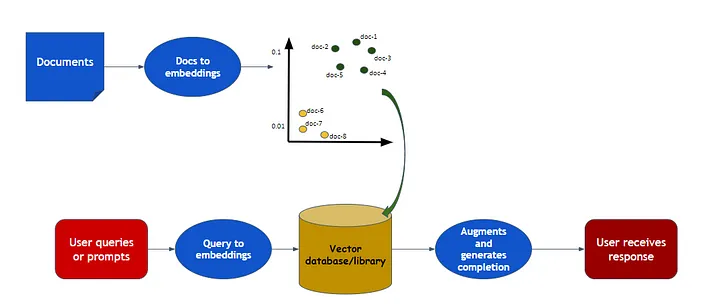
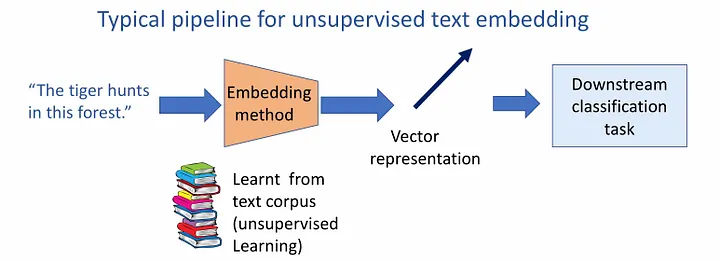
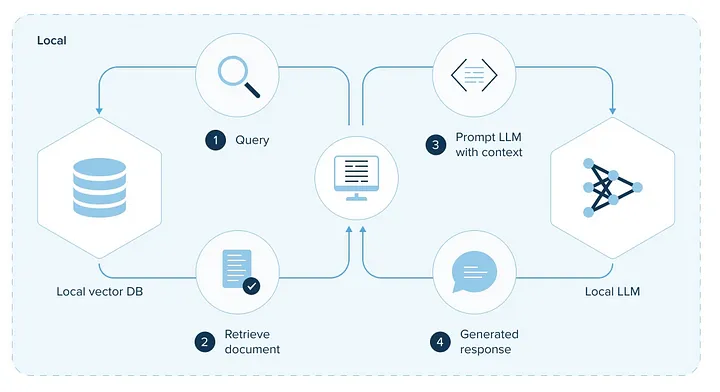
检索增强生成(RAG)是一种与预训练的大型语言模型(LLM)和自己的数据一起工作的模式,用于生成响应。
现在我将向大家介绍在代码中实现 RAG 的过程。让我们开始使用 Langchain 和 Hugging Face 实现 RAG!
文章目录
- 通俗易懂讲解大模型系列
- 技术交流&资料
- 库的导入
- 文档加载
- 文档转换器
- 文本嵌入
- 向量存储
- 准备LLM模型
- 检索器
- 检索QA链
- 结论
通俗易懂讲解大模型系列
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:一文讲清大模型 RAG 技术全流程
-
用通俗易懂的方式讲解:如何提升大模型 Agent 的能力?
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:使用 LangChain 和大模型生成海报文案
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:使用 LlamaIndex 和 Eleasticsearch 进行大模型 RAG 检索增强生成
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
-
用通俗易懂的方式讲解:使用Llama-2、PgVector和LlamaIndex,构建大模型 RAG 全流程
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型技术交流群,本文完整代码、相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流

库的导入
在开始之前,请安装所有在我们的实现中将要使用的库。
!pip install -q langchain
!pip install -q torch
!pip install -q transformers
!pip install -q sentence-transformers
!pip install -q datasets
!pip install -q faiss-cpu
导入我们在这个实现中将要使用的库:
from langchain.document_loaders import HuggingFaceDatasetLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
from transformers import AutoTokenizer, pipeline
from langchain import HuggingFacePipeline
from langchain.chains import RetrievalQA
为什么需要安装和导入这些库,一步步开始实现时将会了解到。
文档加载
在 LangChain 文档中,您可以看到它具有从多个来源加载数据的所有方法。

在这里,我将使用 Hugging Face 的数据集— databricks-dolly-15k。这个数据集是由 Databricks 生成的一个遵循指令的记录的开源数据集,包括头脑风暴、分类、封闭式问答、生成、信息提取、开放式问答和摘要。
行为类别在InstructGPT论文中有详细说明。
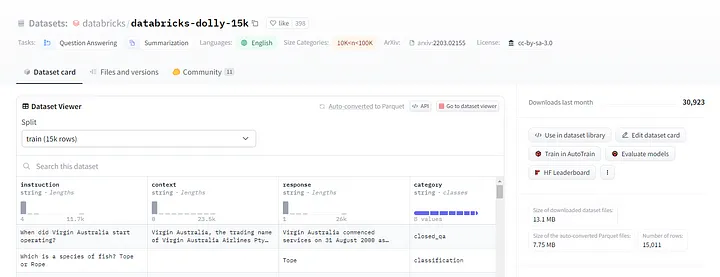
文档加载器提供了一个“load”方法,从配置的源加载数据作为文档到内存中。使用Hugging Face,加载数据。
# 指定数据集名称和包含内容的列
dataset_name = "databricks/databricks-dolly-15k"
page_content_column = "context" # 或者其他您感兴趣的列
# 创建加载器实例
loader = HuggingFaceDatasetLoader(dataset_name, page_content_column)
# 加载数据
data = loader.load()
# 显示前15个条目
data[:2]
文档转换器
一旦数据加载完成,您可以对其进行转换以适应您的应用程序,或者仅获取文档的相关部分。基本上,这涉及将长文档拆分为适合您的模型并能够准确清晰地提供结果的较小块。
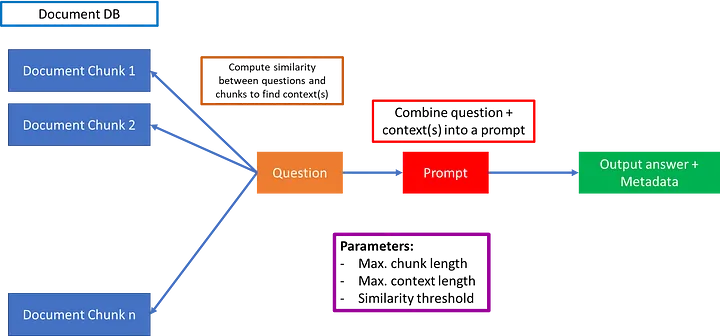
有几个“文本拆分器”在 LangChain 中,您可以根据您的选择进行选择。我选择了“RecursiveCharacterTextSplitter”。
这个文本拆分器适用于通用文本,并通过一组字符的参数进行参数化。它尝试递归地拆分长文本,直到块足够小。
# 使用特定参数创建RecursiveCharacterTextSplitter类的实例。
# 它将文本分成每个1000个字符的块,每个块有150个字符的重叠。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)
# 'data'包含您想要拆分的文本,使用文本拆分器将文本拆分为文档。
docs = text_splitter.split_documents(data)
docs[0]
结果将是:
Document(page_content="Virgin Australia, the trading name of Virgin Australia
Airlines Pty Ltd, is an Australian-based airline. It is the largest airline
by fleet size to use the Virgin brand. It commenced services on 31 August 2000
as Virgin Blue, with two aircraft on a single route.
It suddenly found itself as a major airline in Australia's domestic market
after the collapse of Ansett Australia in September 2001.
The airline has since grown to directly serve 32 cities in Australia,
from hubs in Brisbane, Melbourne and Sydney.",
metadata={'instruction': 'When did Virgin Australia start operating?',
'response': 'Virgin Australia commenced services on 31 August 2000 as Virgin
Blue, with two aircraft on a single route.',
'category': 'closed_qa'})
文本嵌入
嵌入捕捉文本的语义含义,允许您快速高效地找到其他相似的文本片段。
LangChain 的 Embeddings 类专为与文本嵌入模型进行接口设计。您可以使用其中任何一个,但我在这里使用了“HuggingFaceEmbeddings”。
# 定义要使用的预训练模型的路径
modelPath = "sentence-transformers/all-MiniLM-l6-v2"
# 创建一个包含模型配置选项的字典,指定使用CPU进行计算
model_kwargs = {'device':'cpu'}
# 创建一个包含编码选项的字典,具体设置 'normalize_embeddings' 为 False
encode_kwargs = {'normalize_embeddings': False}
# 使用指定的参数初始化HuggingFaceEmbeddings的实例
embeddings = HuggingFaceEmbeddings(
model_name=modelPath, # 提供预训练模型的路径
model_kwargs=model_kwargs, # 传递模型配置选项
encode_kwargs=encode_kwargs # 传递编码选项
)
text = "This is a test document."
query_result = embeddings.embed_query(text)
query_result[:3]
生成的向量将是:
[-0.038338545709848404, 0.1234646886587143, -0.02864295244216919]
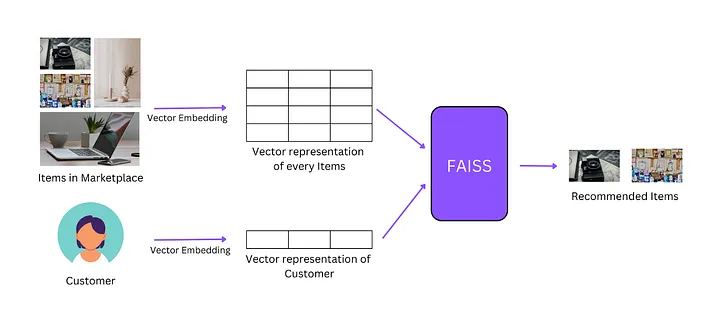
向量存储
我们需要数据库来存储这些嵌入向量并进行高效搜索。因此,为了存储和搜索的目的,我们需要向量存储。您可以检索“最相似”的嵌入向量。
LangChain 集成了许多向量存储,但我在这里使用了“FAISS”向量存储。
db = FAISS.from_documents(docs, embeddings)
以上代码的运行时间取决于数据集的长度。我的运行时间为5分钟32秒。
如果您使用"SQUAD"数据集,可能需要65分钟。看到差异了吧!
现在,搜索您的问题。
question = "What is cheesemaking?"
searchDocs = db.similarity_search(question)
print(searchDocs[0].page_content)
结果将是:
The goal of cheese making is to control the spoiling of milk into cheese.
The milk is traditionally from a cow, goat, sheep or buffalo, although,
in theory, cheese could be made from the milk of any mammal.
Cow's milk is most commonly used worldwide.
The cheesemaker's goal is a consistent product with specific characteristics
(appearance, aroma, taste, texture). The process used to make a Camembert will
be similar to, but not quite the same as, that used to make Cheddar.
Some cheeses may be deliberately left to ferment from naturally airborne
spores and bacteria; this approach generally leads to a less consistent
product but one that is valuable in a niche market.
这是最相似的搜索结果!
准备LLM模型
您可以从Hugging Face中选择任何模型,使用一个标记器对文本进行预处理,使用一个问答模型根据输入文本和问题提供答案。
我使用了Intel/dynamic_tinybert,这是一个针对问答目的进行微调的模型。
# 通过加载预训练的"Intel/dynamic_tinybert"标记器创建标记器对象。
tokenizer = AutoTokenizer.from_pretrained("Intel/dynamic_tinybert")
# 通过加载预训练的"Intel/dynamic_tinybert"模型创建问答模型对象。
model = AutoModelForQuestionAnswering.from_pretrained("Intel/dynamic_tinybert")
创建一个使用预训练模型和标记器的问答管道,然后通过创建带有额外模型特定参数的LangChain管道来扩展其功能。
# 指定要使用的模型名称
model_name = "Intel/dynamic_tinybert"
# 加载与指定模型关联的标记器
tokenizer = AutoTokenizer.from_pretrained(model_name, padding=True, truncation=True, max_length=512)
# 使用模型和标记器定义一个问答管道
question_answerer = pipeline(
"question-answering",
model=model_name,
tokenizer=tokenizer,
return_tensors='pt'
)
# 创建HuggingFacePipeline的实例,该实例包装了问答管道,并带有额外的模型特定参数(温度和max_length)
llm = HuggingFacePipeline(
pipeline=question_answerer,
model_kwargs={"temperature": 0.7, "max_length": 512},
)
检索器
一旦数据在数据库中,LLM模型准备好,管道创建完成,我们需要检索数据。检索器是一个接口,用于从查询中返回文档。

检索器实际上无法存储文档,只能返回或检索它们。基本上,向量存储是检索器的支柱。LangChain中有许多检索器算法。
# 使用'as_retriever'方法从'db'创建一个检索器对象。
# 这个检索器可能用于从数据库中检索数据或文档。
retriever = db.as_retriever()
搜索与问题相关的文档:
docs = retriever.get_relevant_documents("What is Cheesemaking?")
print(docs[0].page_content)
结果将是:
The goal of cheese making is to control the spoiling of milk into cheese.
The milk is traditionally from a cow, goat, sheep or buffalo, although,
in theory, cheese could be made from the milk of any mammal. Cow's milk
is most commonly used worldwide. The cheesemaker's goal is a consistent
product with specific characteristics (appearance, aroma, taste, texture).
The process used to make a Camembert will be similar to, but not quite the
same as, that used to make Cheddar.
Some cheeses may be deliberately left to ferment from naturally airborne
spores and bacteria; this approach generally leads to a less consistent
product but one that is valuable in a niche market.
这与我们通过相似性搜索获得的结果相同。
检索QA链
现在,我们将使用 RetrievalQA 链来找到问题的答案。
为此,我们使用了具有“temperature = 0.7”和“max_length = 512”的LLM模型。您可以根据需要设置温度。
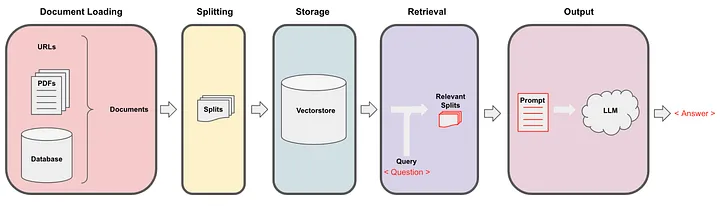
RetrievalQA 链将问答与检索步骤结合在一起。要创建它,我们使用语言模型和一个向量数据库作为检索器。
默认情况下,我们将所有数据放在单个批次中,其中链类型为“stuff”当询问语言模型时。但如果我们有很多信息且一次无法全部容纳,我们可以使用MapReduce、Refine和MapRerank等方法。
# 从'db'创建一个带有搜索配置的检索器对象,其中检索最多4个相关的拆分/文档。
retriever = db.as_retriever(search_kwargs={"k": 4})
# 使用RetrievalQA类创建一个带有检索器、链类型“refine”和不返回源文档选项的问答实例(qa)。
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="refine", retriever=retriever, return_source_documents=False)
最后,我们使用要问的问题调用这个QA链。
question = "Who is Thomas Jefferson?"
result = qa.run({"query": question})
print(result["result"])
结果将是:
Thomas Jefferson (April 13, 1743 – July 4, 1826) was an American statesman,
diplomat, lawyer, architect, philosopher, and Founding Father who served as
the third president of the United States from 1801 to 1809.
Among the Committee of Five charged by the Second Continental Congress with
authoring the Declaration of Independence, Jefferson was the Declaration's
primary author. Following the American Revolutionary War and prior to becoming
the nation's third president in 1801, Jefferson was the first United States
secretary of state under George Washington and then the nation's second vice
president under John Adams.
使用开源模型可能会遇到一些挑战,包括在运行查询时可能会出现ValueError,要求您将输入作为字典。确保在最终的代码中按照要求以字典的形式提供输入。
使用 OpenAI API 进行相同的方法和流程,您将不会遇到这样的错误。有关如何在LangChain中使用OpenAI的更多信息,请参阅此手册。
结论
除了在使用开源库时面临挑战之外,通过代码实现了解RAG是一件有趣的事情。

LangChain 是一个用于构建大型语言模型(LLM)应用程序的开源开发者框架。
当您想要针对特定文档(例如PDF、视频等)提出问题或与您自己的数据进行交流时,LangChain 尤其有用。
对于那些经常使用Hugging Face的人来说,使用它会更容易,因为它用户友好。在Hugging Face Model上,您可以找到一个RAG模型。
![[小程序]样式与配置](https://img-blog.csdnimg.cn/direct/b8bdaca0e23b40f6bd94293e359ea003.png)