- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
目录
- 环境
- 模型设计
- 模型效果展示
- 总结与心得体会
环境
- 系统: Linux
- 语言: Python3.8.10
- 深度学习框架: Pytorch2.0.0+cu118
- 显卡:GTX2080TI
模型设计
原始的DenseNet结构图如下:
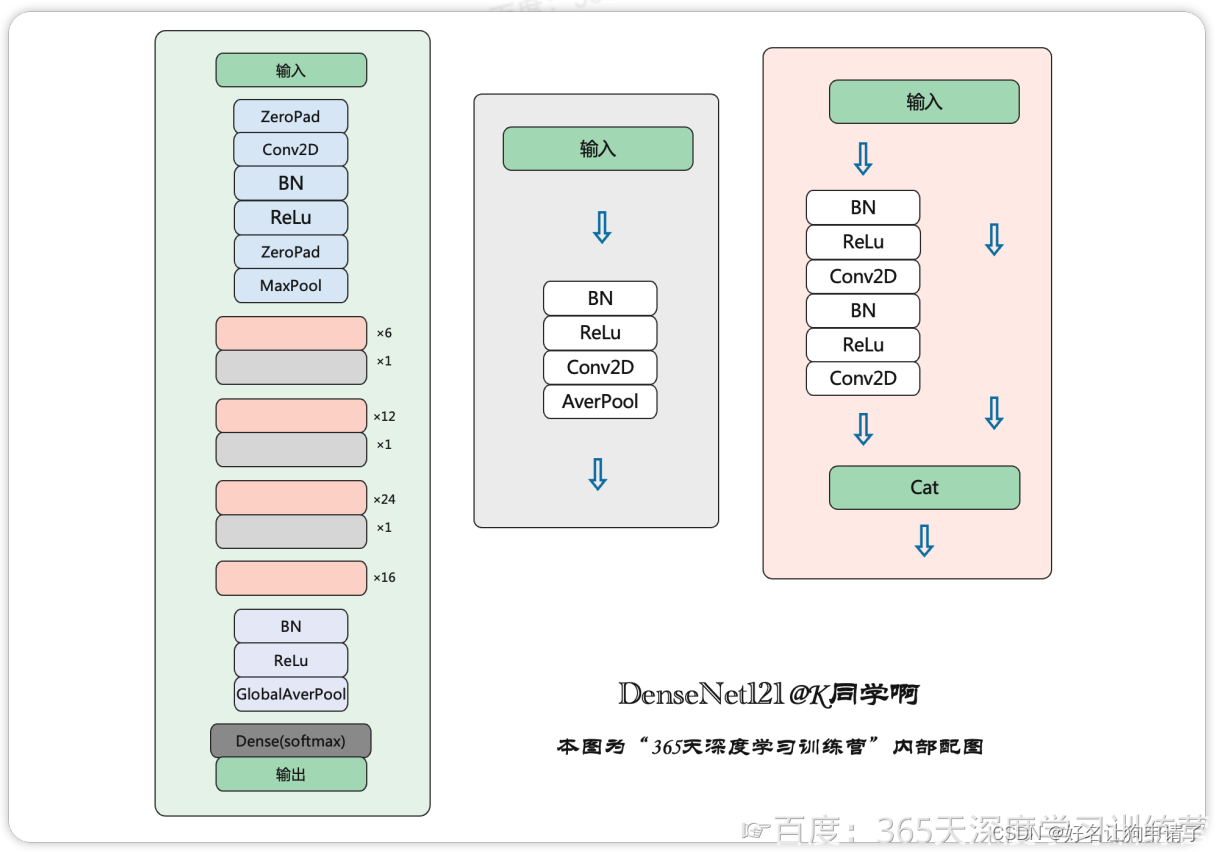
原始的ResNet结构图如下:
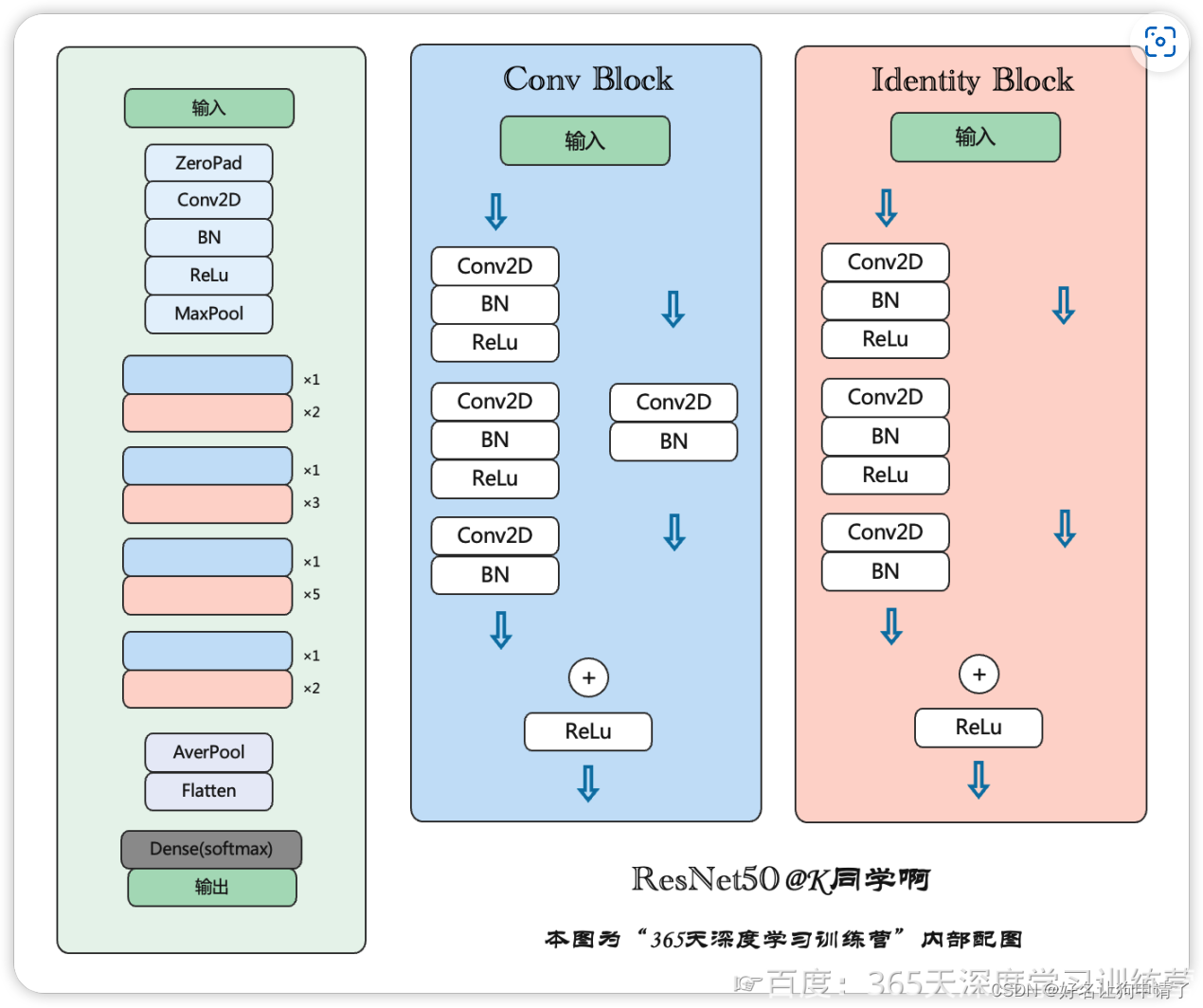
经过对比可以发现,ResNet的恒等块是经过了3个Conv层,而DenseNet只有两个,于是将DenseNet的结构修改为ResNet的风格,然后进行测试。
# BN ReLU Conv 顺序的残差块
class ResidualBlock(nn.Sequential):
def __init__(self, kernel_size, input_size, hidden_size, drop_rate):
super().__init__()
self.add_module('norm1', nn.BatchNorm2d(input_size)),
self.add_module('relu1', nn.ReLU(inplace=True)),
self.add_module('conv1', nn.Conv2d(input_size, hidden_size, kernel_size=1, bias=False))
self.add_module('norm2', nn.BatchNorm2d(hidden_size)),
self.add_module('relu2', nn.ReLU(inplace=True)),
self.add_module('conv2', nn.Conv2d(hidden_size, hidden_size, kernel_size=kernel_size, padding='same', bias=False))
self.add_module('norm3', nn.BatchNorm2d(hidden_size)),
self.add_module('relu3', nn.ReLU(inplace=True)),
self.add_module('conv3', nn.Conv2d(hidden_size, input_size, kernel_size=1, bias=False))
self.drop_rate = drop_rate
def forward(self, x):
features = super().forward(x)
if self.drop_rate > 0:
features = F.dropout(features, p = self.drop_rate, training=self.training)
return torch.concat([x, features], 1)
class DenseBlock(nn.Sequential):
def __init__(self, num_layers, input_size, drop_rate):
super().__init__()
for i in range(num_layers):
layer = ResidualBlock(3, input_size, int(input_size / 4), drop_rate)
input_size *= 2 # 每次都是上个的堆叠,每次都翻倍
self.add_module('denselayer%d'%(i+1,), layer)
# 过渡层没有任务变化
class Transition(nn.Sequential):
def __init__(self, input_size, output_size):
super().__init__()
self.add_module('norm', nn.BatchNorm2d(input_size))
self.add_module('relu', nn.ReLU())
self.add_module('conv', nn.Conv2d(input_size, output_size, kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(2, stride=2))
# 构建自定义的DenseNet
class DenseNet(nn.Module):
# 模型的规模小一点,方便测试
def __init__(self, growth_rate=32, block_config=(2,4,3, 2),
init_size=64, bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=1000):
super().__init__()
self.features = nn.Sequential(OrderedDict([
("conv0", nn.Conv2d(3, init_size, kernel_size=7, stride=2, padding=3, bias=False)),
('norm0', nn.BatchNorm2d(init_size)),
('relu0', nn.ReLU()),
('pool0', nn.MaxPool2d(3, stride=2, padding=1))
]))
num_features = init_size
for i, num_layers in enumerate(block_config):
block = DenseBlock(num_layers, num_features, drop_rate)
self.features.add_module('denseblock%d' % (i + 1), block)
num_features = num_features*(2**num_layers)
if i != len(block_config) - 1:
transition = Transition(num_features, int(num_features*compression_rate))
self.features.add_module('transition%d' % (i + 1), transition)
num_features = int(num_features * compression_rate)
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
self.features.add_module('relu5', nn.ReLU())
self.classifier = nn.Linear(num_features, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.avg_pool2d(features, 7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out
打印一下模型的结构
DenseNet(
(features): Sequential(
(conv0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(norm0): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu0): ReLU()
(pool0): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(denseblock1): DenseBlock(
(denselayer1): ResidualBlock(
(norm1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(64, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=same, bias=False)
(norm3): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(16, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(denselayer2): ResidualBlock(
(norm1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=same, bias=False)
(norm3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(transition1): Transition(
(norm): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock2): DenseBlock(
(denselayer1): ResidualBlock(
(norm1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=same, bias=False)
(norm3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(denselayer2): ResidualBlock(
(norm1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=same, bias=False)
(norm3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(denselayer3): ResidualBlock(
(norm1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=same, bias=False)
(norm3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(denselayer4): ResidualBlock(
(norm1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=same, bias=False)
(norm3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(transition2): Transition(
(norm): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock3): DenseBlock(
(denselayer1): ResidualBlock(
(norm1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=same, bias=False)
(norm3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(denselayer2): ResidualBlock(
(norm1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=same, bias=False)
(norm3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(denselayer3): ResidualBlock(
(norm1): BatchNorm2d(4096, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(4096, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=same, bias=False)
(norm3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(1024, 4096, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(transition3): Transition(
(norm): BatchNorm2d(8192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv): Conv2d(8192, 4096, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock4): DenseBlock(
(denselayer1): ResidualBlock(
(norm1): BatchNorm2d(4096, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(4096, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=same, bias=False)
(norm3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(1024, 4096, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(denselayer2): ResidualBlock(
(norm1): BatchNorm2d(8192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(8192, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(2048, 2048, kernel_size=(3, 3), stride=(1, 1), padding=same, bias=False)
(norm3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(conv3): Conv2d(2048, 8192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(norm5): BatchNorm2d(16384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu5): ReLU()
)
(classifier): Linear(in_features=16384, out_features=2, bias=True)
)
# 使用torchinfo打印
summary(model, input_size=(32, 3, 224, 224))
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
DenseNet [32, 2] --
├─Sequential: 1-1 [32, 16384, 7, 7] --
│ └─Conv2d: 2-1 [32, 64, 112, 112] 9,408
│ └─BatchNorm2d: 2-2 [32, 64, 112, 112] 128
│ └─ReLU: 2-3 [32, 64, 112, 112] --
│ └─MaxPool2d: 2-4 [32, 64, 56, 56] --
│ └─DenseBlock: 2-5 [32, 256, 56, 56] --
│ │ └─ResidualBlock: 3-1 [32, 128, 56, 56] 4,544
│ │ └─ResidualBlock: 3-2 [32, 256, 56, 56] 17,792
│ └─Transition: 2-6 [32, 128, 28, 28] --
│ │ └─BatchNorm2d: 3-3 [32, 256, 56, 56] 512
│ │ └─ReLU: 3-4 [32, 256, 56, 56] --
│ │ └─Conv2d: 3-5 [32, 128, 56, 56] 32,768
│ │ └─AvgPool2d: 3-6 [32, 128, 28, 28] --
│ └─DenseBlock: 2-7 [32, 2048, 28, 28] --
│ │ └─ResidualBlock: 3-7 [32, 256, 28, 28] 17,792
│ │ └─ResidualBlock: 3-8 [32, 512, 28, 28] 70,400
│ │ └─ResidualBlock: 3-9 [32, 1024, 28, 28] 280,064
│ │ └─ResidualBlock: 3-10 [32, 2048, 28, 28] 1,117,184
│ └─Transition: 2-8 [32, 1024, 14, 14] --
│ │ └─BatchNorm2d: 3-11 [32, 2048, 28, 28] 4,096
│ │ └─ReLU: 3-12 [32, 2048, 28, 28] --
│ │ └─Conv2d: 3-13 [32, 1024, 28, 28] 2,097,152
│ │ └─AvgPool2d: 3-14 [32, 1024, 14, 14] --
│ └─DenseBlock: 2-9 [32, 8192, 14, 14] --
│ │ └─ResidualBlock: 3-15 [32, 2048, 14, 14] 1,117,184
│ │ └─ResidualBlock: 3-16 [32, 4096, 14, 14] 4,462,592
│ │ └─ResidualBlock: 3-17 [32, 8192, 14, 14] 17,838,080
│ └─Transition: 2-10 [32, 4096, 7, 7] --
│ │ └─BatchNorm2d: 3-18 [32, 8192, 14, 14] 16,384
│ │ └─ReLU: 3-19 [32, 8192, 14, 14] --
│ │ └─Conv2d: 3-20 [32, 4096, 14, 14] 33,554,432
│ │ └─AvgPool2d: 3-21 [32, 4096, 7, 7] --
│ └─DenseBlock: 2-11 [32, 16384, 7, 7] --
│ │ └─ResidualBlock: 3-22 [32, 8192, 7, 7] 17,838,080
│ │ └─ResidualBlock: 3-23 [32, 16384, 7, 7] 71,327,744
│ └─BatchNorm2d: 2-12 [32, 16384, 7, 7] 32,768
│ └─ReLU: 2-13 [32, 16384, 7, 7] --
├─Linear: 1-2 [32, 2] 32,770
==========================================================================================
Total params: 149,871,874
Trainable params: 149,871,874
Non-trainable params: 0
Total mult-adds (G): 595.94
==========================================================================================
Input size (MB): 19.27
Forward/backward pass size (MB): 5317.85
Params size (MB): 599.49
Estimated Total Size (MB): 5936.61
==========================================================================================
模型效果展示
Epoch: 1, Train_acc:83.8, Train_loss: 0.392, Test_acc: 86.8, Test_loss: 0.324, Lr: 1.00E-04
Epoch: 2, Train_acc:86.8, Train_loss: 0.327, Test_acc: 88.5, Test_loss: 0.291, Lr: 1.00E-04
Epoch: 3, Train_acc:88.1, Train_loss: 0.290, Test_acc: 87.7, Test_loss: 0.415, Lr: 1.00E-04
Epoch: 4, Train_acc:88.1, Train_loss: 0.287, Test_acc: 89.8, Test_loss: 0.249, Lr: 1.00E-04
Epoch: 5, Train_acc:89.7, Train_loss: 0.251, Test_acc: 90.5, Test_loss: 0.235, Lr: 1.00E-04
Epoch: 6, Train_acc:90.2, Train_loss: 0.241, Test_acc: 90.7, Test_loss: 0.253, Lr: 1.00E-04
Epoch: 7, Train_acc:90.6, Train_loss: 0.227, Test_acc: 90.5, Test_loss: 0.236, Lr: 1.00E-04
Epoch: 8, Train_acc:91.5, Train_loss: 0.212, Test_acc: 90.5, Test_loss: 0.228, Lr: 1.00E-04
Epoch: 9, Train_acc:91.7, Train_loss: 0.207, Test_acc: 91.0, Test_loss: 0.247, Lr: 1.00E-04
Epoch:10, Train_acc:92.0, Train_loss: 0.206, Test_acc: 91.2, Test_loss: 0.290, Lr: 1.00E-04
Epoch:11, Train_acc:92.0, Train_loss: 0.203, Test_acc: 88.2, Test_loss: 0.283, Lr: 1.00E-04
Epoch:12, Train_acc:92.5, Train_loss: 0.185, Test_acc: 91.3, Test_loss: 0.232, Lr: 1.00E-04
Epoch:13, Train_acc:93.2, Train_loss: 0.172, Test_acc: 90.7, Test_loss: 0.247, Lr: 1.00E-04
Epoch:14, Train_acc:93.3, Train_loss: 0.177, Test_acc: 90.2, Test_loss: 0.238, Lr: 1.00E-04
Epoch:15, Train_acc:93.8, Train_loss: 0.166, Test_acc: 90.1, Test_loss: 0.357, Lr: 1.00E-04
Epoch:16, Train_acc:94.6, Train_loss: 0.146, Test_acc: 91.2, Test_loss: 0.255, Lr: 1.00E-04
Epoch:17, Train_acc:95.4, Train_loss: 0.119, Test_acc: 90.2, Test_loss: 0.270, Lr: 1.00E-04
Epoch:18, Train_acc:95.5, Train_loss: 0.116, Test_acc: 81.7, Test_loss: 0.752, Lr: 1.00E-04
Epoch:19, Train_acc:95.6, Train_loss: 0.117, Test_acc: 89.3, Test_loss: 0.339, Lr: 1.00E-04
Epoch:20, Train_acc:95.5, Train_loss: 0.120, Test_acc: 91.0, Test_loss: 0.285, Lr: 1.00E-04
Done
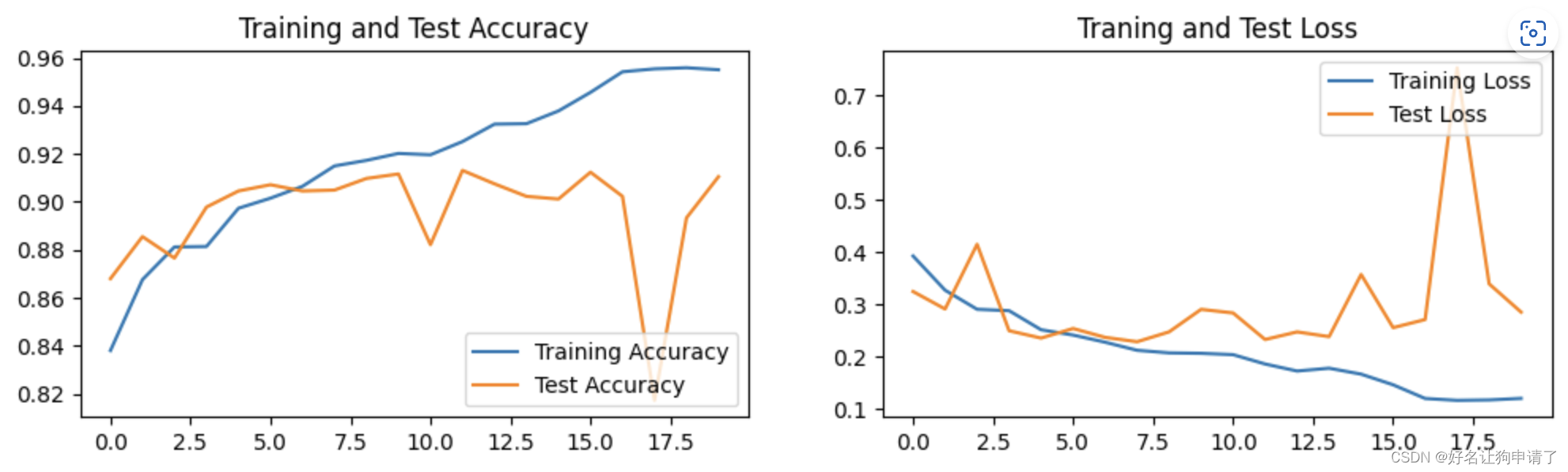
总结与心得体会
虽然大幅度的降低了模型的规模,实际的总参数还是数倍于DenseNet121。然而,模型似乎比DenseNet121的泛化性能好不少,训练和验证的Gap比DenseNet121小很多,甚至有的时候验证集上的表现比训练集还好。直接使用ResNet的ResidualBlock实现DenseNet会让参数量迅速的膨胀。接下来再改进,应该从如何压缩DenseNet的参数量的角度来考虑。