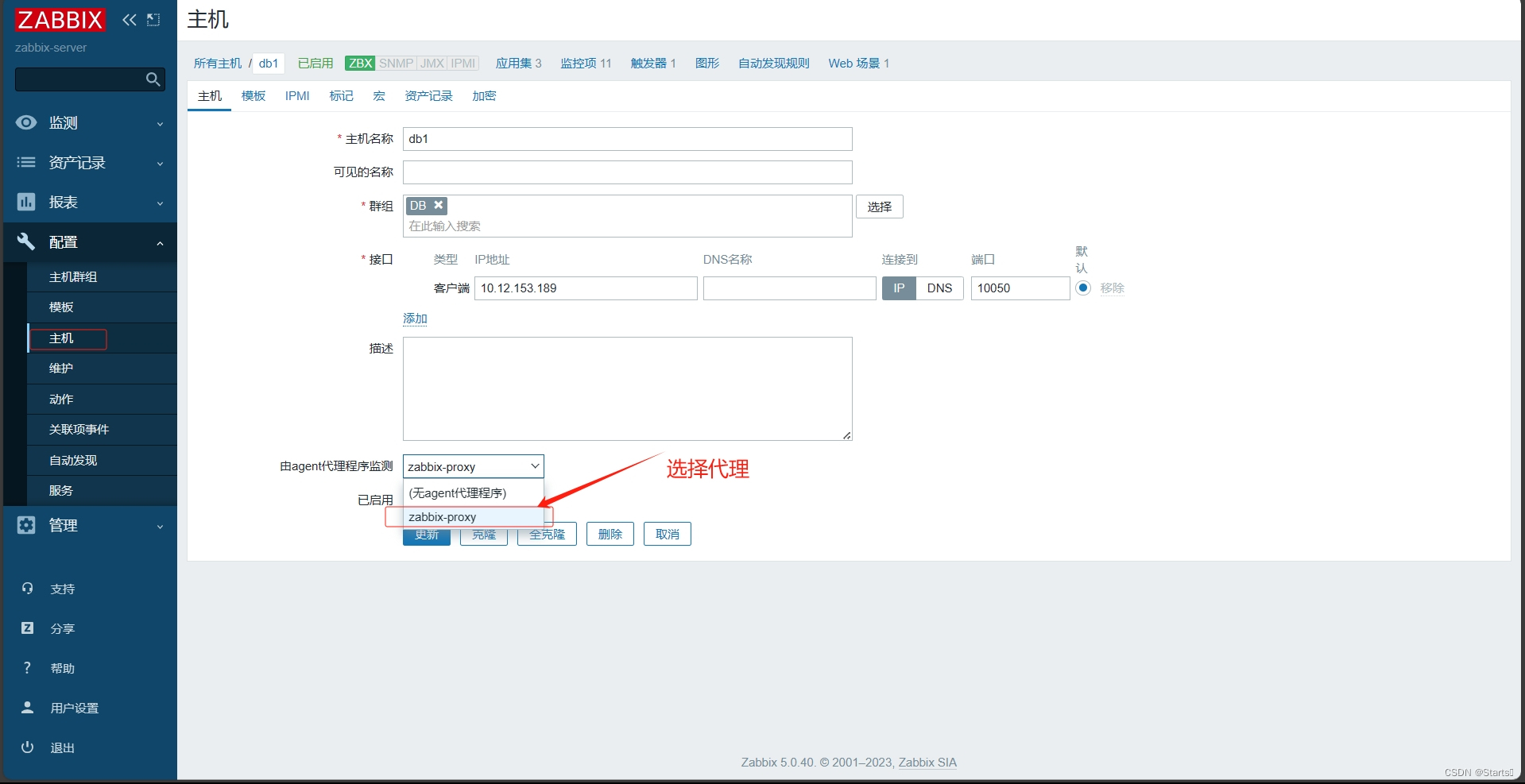
Architecture Lab 对应CS:APP的Chap 4——处理器体系结构。Part A要实现三个函数,分别为sum_list/rsum_list/copy_block。建议先得到x86-64指令,然后再转换为Y86-64指令。
准备工作
在misc目录下,键入以下命令用来生成汇编代码。命令执行完毕后会生成examples.o。
gcc -S examples.csum_list的Y86-64实现
在examples.o中找到第一个要实现的函数sum_list,如下
sum_list:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movq %rdi, -24(%rbp)
movq $0, -8(%rbp)
jmp .L2
.L3:
movq -24(%rbp), %rax
movq (%rax), %rax
addq %rax, -8(%rbp)
movq -24(%rbp), %rax
movq 8(%rax), %rax
movq %rax, -24(%rbp)
.L2:
cmpq $0, -24(%rbp)
jne .L3
movq -8(%rbp), %rax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc可见,这个代码是将局部变量存在栈帧上,而书上的x86代码并不是这么复杂,而是直接把值存在某寄存器中,进行加减操作。那么我们也来做一些等价转换,转换后的结果如下代码:
sum_list:
.LFB0:
movq $0, %rax
jmp .L2
.L3:
addq (%rdi), %rax
movq 8(%rdi), %rdi
.L2:
cmpq $0, %rdi
jne .L3
ret
然后根据Y86-64的规则,进行改写。
sum_list:
.LFB0:
movq $0, %rax -> irmovq $0, %rax
jmp .L2
.L3:
addq (%rdi), %rax -> mrmovq (%rdi), %r8 addq %r8, %rax
movq 8(%rdi), %rdi ->mrmovq 8(%rdi), %rdi
.L2:
cmpq $0, %rdi ->andq %rdi, %rdi
jne .L3
ret
即为
sum_list:
.LFB0:
irmovq $0, %rax
jmp .L2
.L3:
mrmovq (%rdi), %r8
addq %r8, %rax
mrmovq 8(%rdi), %rdi
.L2:
andq %rdi, %rdi
jne .L3
ret这只是一个函数,现需要把它写为完整的程序。根据书上page 252的代码4-7,补上main函数、调用main函数的语段、数据段即可。如下:
.pos 0
irmovq stack,%rsp
call main
halt
# 这是archlab.pdf中给出的测试样例
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
main:
irmovq ele1, %rdi
call sum_list
ret
sum_list:
LFB0:
irmovq $0, %rax
jmp L2
L3:
mrmovq (%rdi), %r8
addq %r8, %rax
mrmovq 8(%rdi), %rdi
L2:
andq %rdi, %rdi
jne L3
ret
.pos 0x200
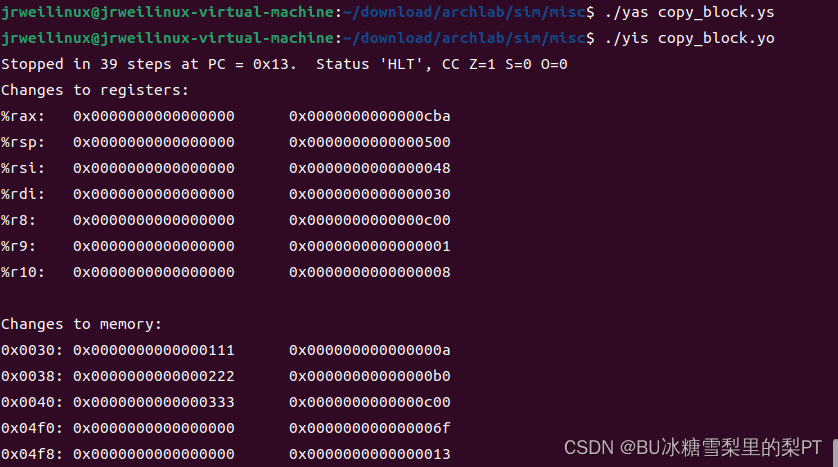
stack:用yas得到.yo文件,再用yis运行.yo文件,得到各个寄存器运行后的值,如下。
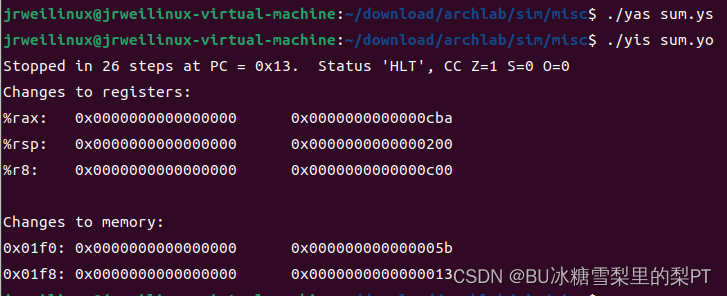
sum_list函数完成。
rsum_list的Y86-64实现
在examples.o中找到第二个要实现的函数rsum_list,如下:
rsum_list:
.LFB1:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $32, %rsp
movq %rdi, -24(%rbp)
cmpq $0, -24(%rbp)
jne .L6
movl $0, %eax
jmp .L7
.L6:
movq -24(%rbp), %rax
movq (%rax), %rax
movq %rax, -16(%rbp)
movq -24(%rbp), %rax
movq 8(%rax), %rax
movq %rax, %rdi
call rsum_list
movq %rax, -8(%rbp)
movq -16(%rbp), %rdx
movq -8(%rbp), %rax
addq %rdx, %rax
.L7:
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc同样,递归产生的n个栈帧中存了两个参数和求得的和。由于是递归,是否寄存器不可简化?
答案是可以简化的,栈帧上只存求得的和,不存两个参数。
rsum_list:
.LFB1:
cmpq $0, %rdi
jne .L6
movl $0, %eax
jmp .L7
.L6:
movq (%rdi), %rax
push %rax
movq 8(%rdi), %rdi
call rsum_list
pop %r8
addq %r8, %rax
.L7:
ret把这个简化之后的x86-64代码转换为Y86-64
rsum_list:
.LFB1:
andq %rdi, %rdi
jne .L6
irmovq $0, %rax
jmp .L7
.L6:
mrmovq (%rdi), %rax
push %rax
mrmovq 8(%rdi), %rdi
call rsum_list
pop %r8
addq %r8, %rax
.L7:
ret放到刚刚写的框架中即可。
copy_block的Y86-64实现
在examples.o中找到第三个要实现的函数copy_block,如下:
copy_block:
.LFB2:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movq %rdi, -24(%rbp)
movq %rsi, -32(%rbp)
movq %rdx, -40(%rbp)
movq $0, -16(%rbp)
jmp .L9
.L10:
movq -24(%rbp), %rax
leaq 8(%rax), %rdx
movq %rdx, -24(%rbp)
movq (%rax), %rax
movq %rax, -8(%rbp)
movq -32(%rbp), %rax
leaq 8(%rax), %rdx
movq %rdx, -32(%rbp)
movq -8(%rbp), %rdx
movq %rdx, (%rax)
movq -8(%rbp), %rax
xorq %rax, -16(%rbp)
subq $1, -40(%rbp)
.L9:
cmpq $0, -40(%rbp)
jg .L10
movq -16(%rbp), %rax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc简化代码
copy_block:
.LFB2:
movq $0, %rax
jmp .L9
.L10:
movq (%rdi), %r8
leaq 8(%rdi), %rdi
movq %r8, (%rsi)
leaq 8(%rsi), %rsi
xorq %r8, %rax
subq $1, %rdx
.L9:
cmpq $0, %rdx
jg .L10
ret改为Y86-64代码
copy_block:
.LFB2:
irmovq $1, %r9 # const value
irmovq $8, %r10 # const value
irmovq $0, %rax
jmp .L9
.L10:
mrmovq (%rdi), %r8
addq %r10, %rdi
rmmovq %r8, (%rsi)
addq %r10, %rsi
xorq %r8, %rax
subq %r9, %rdx
.L9:
andq %rdx, %rdx
jg .L10
ret新建copy_block.ys
.pos 0
irmovq stack,%rsp
call main
halt
.align 8
# Source block
src:
.quad 0x00a
.quad 0x0b0
.quad 0xc00
# Destination block
dest:
.quad 0x111
.quad 0x222
.quad 0x333
main:
irmovq src, %rdi
irmovq dest, %rsi
irmovq $3, %rdx
call copy_block
ret
copy_block:
LFB2:
irmovq $1, %r9 # const value
irmovq $8, %r10 # const value
irmovq $0, %rax
jmp L9
L10:
mrmovq (%rdi), %r8
addq %r10, %rdi
rmmovq %r8, (%rsi)
addq %r10, %rsi
xorq %r8, %rax
subq %r9, %rdx
L9:
andq %rdx, %rdx
jg L10
ret
.pos 0x500
stack: