目录
前言
Create(创建)
单行数据+全列插入:
多行数据+指定列插入:
插入否则更新:
替换:
Retrieve(读取)
SELECT 列:
全列查询:
指定列查询:
查询字段为表达式:
表达式包含一个字段:
表达式包含多个字段:
为查询结果指定别名 :
结果去重:
WHRER条件:
基本比较 :
语文成绩在[80,90]分的同学及语文成绩:
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩:
性孙 的同学及孙某同学:
语文成绩好于英语成绩的同学:
NULL的查询:
结果排序:
同学及数学成绩,按数学成绩升序显示:
同学及 qq 号,按 qq 号排序显示:
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示:
查询同学及总分,由高到低:
筛选分页结果:
按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页:
Update(更新)
将孙悟空同学的数学成绩变更为 80 分:
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分:
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分:
Delete(删除)
删除数据:
删除孙悟空同学的考试成绩:
删除整张表数据:
截断表:
插入查询结果
聚合函数
前言
如果没看过对于表的操作可以看一下下面这篇博客-->https://mp.csdn.net/mp_blog/creation/editor/135658650![]() https://mp.csdn.net/mp_blog/creation/editor/135658650
https://mp.csdn.net/mp_blog/creation/editor/135658650
本篇博客主要分享的是对于表的增删查改,也就是大名鼎鼎的CRUD:Create(创建)、Retrieve(读取)、Update(更新)、Delete(删除)
Create(创建)
语法:
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...
value_list: value, [, value] ...案例:
创建一张学生表:
-- 创建一张学生表
CREATE TABLE students (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
sn INT NOT NULL UNIQUE COMMENT '学号',
name VARCHAR(20) NOT NULL,
qq VARCHAR(20)
);单行数据+全列插入:
--插入的记录,要跟表的value_list 数量必须和定义表的数量和顺序一致
INSERT INTO students VALUES (100, 10000, '唐三藏', NULL);
Query OK, 1 row affected (0.02 sec)
INSERT INTO students VALUES (101, 10001, '孙悟空', '11111');
Query OK, 1 row affected (0.02 sec)
-- 查看插入结果
SELECT * FROM students;
+-----+-------+-----------+-------+
| id | sn | name | qq |
+-----+-------+-----------+-------+
| 100 | 10000 | 唐三藏 | NULL |
| 101 | 10001 | 孙悟空 | 11111 |
+-----+-------+-----------+-------+
2 rows in set (0.00 sec)多行数据+指定列插入:
这时候指定列的插入也要和value_list的数量、顺序保持一致
INSERT INTO students (id, sn, name) VALUES
(102, 20001, '曹孟德'),
(103, 20002, '孙仲谋');
Query OK, 2 rows affected (0.02 sec)
Records: 2 Duplicates: 0 Warnings: 0查看插入结果:
SELECT * FROM students;
+-----+-------+-----------+-------+
| id | sn | name | qq |
+-----+-------+-----------+-------+
| 100 | 10000 | 唐三藏 | NULL |
| 101 | 10001 | 孙悟空 | 11111 |
| 102 | 20001 | 曹孟德 | NULL |
| 103 | 20002 | 孙仲谋 | NULL |
+-----+-------+-----------+-------+
4 rows in set (0.00 sec)插入否则更新:
由于主键 或者 唯一键对应的值已经存在而导致的插入失败
-- 主键冲突
INSERT INTO students (id, sn, name) VALUES (100, 10010, '唐大师');
ERROR 1062 (23000): Duplicate entry '100' for key 'PRIMARY'
-- 唯一键冲突
INSERT INTO students (sn, name) VALUES (20001, '曹阿瞒');
ERROR 1062 (23000): Duplicate entry '20001' for key 'sn'可以选择的进行同步更新操作语法:
INSERT ... ON DUPLICATE KEY UPDATE
column = value [, column = value] ...INSERT INTO students (id, sn, name) VALUES (100, 10010, '唐大师')
ON DUPLICATE KEY UPDATE sn = 10010, name = '唐大师';
Query OK, 2 rows affected (0.47 sec)- 0 row affecter:表中有冲突,但重读数据的值和update的值相等(自己插入自己)
- 1 row affected 表中没有冲突数据,数据被插入
- 2 row affected 表中有冲突数据,并且数据已经被更新
0、1、2代表收到影响的行,代入进去很好理解
通过MySQL函数获取收到影响的数据行数:
SELECT ROW_COUNT();
+-------------+
| ROW_COUNT() |
+-------------+
| 2 |
+-------------+
1 row in set (0.00 sec)
-- ON DUPLICATE KEY 当发生重复key的时候替换:
- 主键 或者 唯一键 没有冲突,就直接插入
- 主键 或者 唯一键 有冲突,就删除后再插入
REPLACE INTO students (sn, name) VALUES (20001, '曹阿瞒');
Query OK, 2 rows affected (0.00 sec)- 1 row affected 表中没有冲突数据,数据被插入
- 2 row affected 表中有冲突数据,删除后重新插入
Retrieve(读取)
语法:
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...案例:
-- 创建表结构
CREATE TABLE exam_result (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL COMMENT '同学姓名',
chinese float DEFAULT 0.0 COMMENT '语文成绩',
math float DEFAULT 0.0 COMMENT '数学成绩',
english float DEFAULT 0.0 COMMENT '英语成绩'
);
-- 插入测试数据
INSERT INTO exam_result (name, chinese, math, english) VALUES
('唐三藏', 67, 98, 56),
('孙悟空', 87, 78, 77),
('猪悟能', 88, 98, 90),
('曹孟德', 82, 84, 67),
('刘玄德', 55, 85, 45),
('孙权', 70, 73, 78),
('宋公明', 75, 65, 30);
Query OK, 7 rows affected (0.00 sec)
Records: 7 Duplicates: 0 Warnings: 0SELECT 列:
全列查询:
- 查询的列越多,意味着需要传输的数据量越大;
- 可能会影响到索引的使用。
SELECT * FROM exam_result;
+----+-----------+-------+--------+--------+
| id | name | chinese | math | english |
+----+-----------+-------+--------+--------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘玄德 | 55 | 85 | 45 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
+----+-----------+-------+--------+--------+
7 rows in set (0.00 sec)指定列查询:
指定列的顺序不需要按定义表的顺序来
SELECT id, name, english FROM exam_result;
+----+-----------+--------+
| id | name | english |
+----+-----------+--------+
| 1 | 唐三藏 | 56 |
| 2 | 孙悟空 | 77 |
| 3 | 猪悟能 | 90 |
| 4 | 曹孟德 | 67 |
| 5 | 刘玄德 | 45 |
| 6 | 孙权 | 78 |
| 7 | 宋公明 | 30 |
+----+-----------+--------+
7 rows in set (0.00 sec)查询字段为表达式:
SELECT id, name, 10 FROM exam_result;
+----+-----------+----+
| id | name | 10 |
+----+-----------+----+
| 1 | 唐三藏 | 10 |
| 2 | 孙悟空 | 10 |
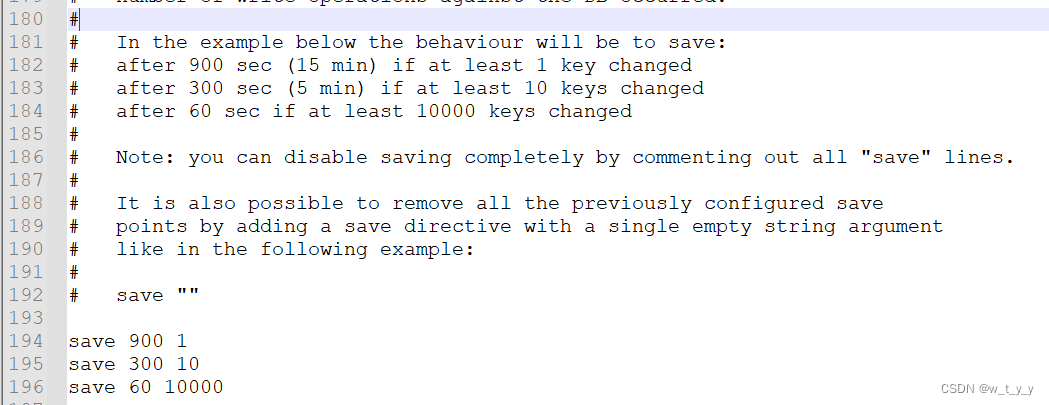
| 3 | 猪悟能 | 10 |
| 4 | 曹孟德 | 10 |
| 5 | 刘玄德 | 10 |
| 6 | 孙权 | 10 |
| 7 | 宋公明 | 10 |
+----+-----------+----+
7 rows in set (0.00 sec)表达式包含一个字段:
SELECT id, name, english + 10 FROM exam_result;
+----+-----------+-------------+
| id | name | english + 10 |
+----+-----------+-------------+
| 1 | 唐三藏 | 66 |
| 2 | 孙悟空 | 87 |
| 3 | 猪悟能 | 100 |
| 4 | 曹孟德 | 77 |
| 5 | 刘玄德 | 55 |
| 6 | 孙权 | 88 |
| 7 | 宋公明 | 40 |
+----+-----------+-------------+
7 rows in set (0.00 sec)表达式包含多个字段:
SELECT id, name, chinese + math + english FROM exam_result;
+----+-----------+-------------------------+
| id | name | chinese + math + english |
+----+-----------+-------------------------+
| 1 | 唐三藏 | 221 |
| 2 | 孙悟空 | 242 |
| 3 | 猪悟能 | 276 |
| 4 | 曹孟德 | 233 |
| 5 | 刘玄德 | 185 |
| 6 | 孙权 | 221 |
| 7 | 宋公明 | 170 |
+----+-----------+-------------------------+
7 rows in set (0.00 sec)为查询结果指定别名 :
语法:
SELECT column [AS] alias_name [...] FROM table_name;例子:
SELECT id, name, chinese + math + english 总分 FROM exam_result;
+----+-----------+--------+
| id | name | 总分 |
+----+-----------+--------+
| 1 | 唐三藏 | 221 |
| 2 | 孙悟空 | 242 |
| 3 | 猪悟能 | 276 |
| 4 | 曹孟德 | 233 |
| 5 | 刘玄德 | 185 |
| 6 | 孙权 | 221 |
| 7 | 宋公明 | 170 |
+----+-----------+--------+
7 rows in set (0.00 sec)结果去重:
SELECT math FROM exam_result;
+--------+
| math |
+--------+
| 98 |
| 78 |
| 98 |
| 84 |
| 85 |
| 73 |
| 65 |
+--------+
7 rows in set (0.00 sec)98分是重复的
去重结果:
SELECT DISTINCT math FROM exam_result;
+--------+
| math |
+--------+
| 98 |
| 78 |
| 84 |
| 85 |
| 73 |
| 65 |
+--------+
6 rows in set (0.00 sec)WHRER条件:
比较运算符:
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是TRUE(1) |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
| !=, <> | 不等于 |
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
案例:
基本比较 :
SELECT name, english FROM exam_result WHERE english < 60;
+-----------+--------+
| name | english |
+-----------+--------+
| 唐三藏 | 56 |
| 刘玄德 | 45 |
| 宋公明 | 30 |
+-----------+--------+
3 rows in set (0.01 sec)语文成绩在[80,90]分的同学及语文成绩:
可以使用AND 或 BETWEEN AND
-- 使用 AND 进行条件连接
SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese <= 90;
+-----------+-------+
| name | chinese |
+-----------+-------+
| 孙悟空 | 87 |
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+-------+
3 rows in set (0.00 sec)
SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90;
+-----------+-------+
| name | chinese |
+-----------+-------+
| 孙悟空 | 87 |
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+-------+
3 rows in set (0.00 sec)数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩:
使用OR进行连接:
-- 使用 OR 进行条件连接
SELECT name, math FROM exam_result
WHERE math = 58
OR math = 59
OR math = 98
OR math = 99;
+-----------+--------+
| name | math |
+-----------+--------+
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+--------+
2 rows in set (0.01 sec)使用IN条件:
-- 使用 IN 条件
SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99);
+-----------+--------+
| name | math |
+-----------+--------+
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+--------+
2 rows in set (0.00 sec)性孙 的同学及孙某同学:
%匹配任意多个字符(包括0)
SELECT name FROM exam_result WHERE name LIKE '孙%';
+-----------+
| name |
+-----------+
| 孙悟空 |
| 孙权 |
+-----------+
2 rows in set (0.00 sec)_严格匹配一个字符
SELECT name FROM exam_result WHERE name LIKE '孙_';
+--------+
| name |
+--------+
| 孙权 |
+--------+
1 row in set (0.00 sec)语文成绩好于英语成绩的同学:
-- WHERE 条件中比较运算符两侧都是字段
SELECT name, chinese, english FROM exam_result WHERE chinese > english;
+-----------+-------+--------+
| name | chinese | english |
+-----------+-------+--------+
| 唐三藏 | 67 | 56 |
| 孙悟空 | 87 | 77 |
| 曹孟德 | 82 | 67 |
| 刘玄德 | 55 | 45 |
| 宋公明 | 75 | 30 |
+-----------+-------+--------+
5 rows in set (0.00 sec)NULL的查询:
-- 查询 students 表
+-----+-------+-----------+-------+
| id | sn | name | qq |
+-----+-------+-----------+-------+
| 100 | 10010 | 唐大师 | NULL |
| 101 | 10001 | 孙悟空 | 11111 |
| 103 | 20002 | 孙仲谋 | NULL |
| 104 | 20001 | 曹阿瞒 | NULL |
+-----+-------+-----------+-------+
4 rows in set (0.00 sec)
-- 查询 qq 号已知的同学姓名
SELECT name, qq FROM students WHERE qq IS NOT NULL;
+-----------+-------+
| name | qq |
+-----------+-------+
| 孙悟空 | 11111 |
+-----------+-------+
1 row in set (0.00 sec)NULL和NULL的比较,区别于 = 和<=> :
SELECT NULL = NULL, NULL = 1, NULL = 0;
+-------------+----------+----------+
| NULL = NULL | NULL = 1 | NULL = 0 |
+-------------+----------+----------+
| NULL | NULL | NULL |
+-------------+----------+----------+
1 row in set (0.00 sec)
SELECT NULL <=> NULL, NULL <=> 1, NULL <=> 0;
+---------------+------------+------------+
| NULL <=> NULL | NULL <=> 1 | NULL <=> 0 |
+---------------+------------+------------+
| 1 | 0 | 0 |
+---------------+------------+------------+
1 row in set (0.00 sec)结果排序:
语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
同学及数学成绩,按数学成绩升序显示:
SELECT name, math FROM exam_result ORDER BY math;
+-----------+--------+
| name | math |
+-----------+--------+
| 宋公明 | 65 |
| 孙权 | 73 |
| 孙悟空 | 78 |
| 曹孟德 | 84 |
| 刘玄德 | 85 |
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+--------+
7 rows in set (0.00 sec)同学及 qq 号,按 qq 号排序显示:
-- NULL 视为比任何值都小,升序出现在最上面
SELECT name, qq FROM students ORDER BY qq;
+-----------+-------+
| name | qq |
+-----------+-------+
| 唐大师 | NULL |
| 孙仲谋 | NULL |
| 曹阿瞒 | NULL |
| 孙悟空 | 11111 |
+-----------+-------+
4 rows in set (0.00 sec)-- NULL 视为比任何值都小,升序出现在最下面
SELECT name, qq FROM students ORDER BY qq DESC;
+-----------+-------+
| name | qq |
+-----------+-------+
| 孙悟空 | 11111 |
| 唐大师 | NULL |
| 孙仲谋 | NULL |
| 曹阿瞒 | NULL |
+-----------+-------+
4 rows in set (0.00 sec)查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示:
SELECT name, math, english, chinese FROM exam_result
ORDER BY math DESC, english, chinese;
+-----------+--------+--------+-------+
| name | math | english | chinese |
+-----------+--------+--------+-------+
| 唐三藏 | 98 | 56 | 67 |
| 猪悟能 | 98 | 90 | 88 |
| 刘玄德 | 85 | 45 | 55 |
| 曹孟德 | 84 | 67 | 82 |
| 孙悟空 | 78 | 77 | 87 |
| 孙权 | 73 | 78 | 70 |
| 宋公明 | 65 | 30 | 75 |
+-----------+--------+--------+-------+
7 rows in set (0.00 sec)查询同学及总分,由高到低:
ORDER BY中可以使用表达式:
SELECT name, chinese + english + math FROM exam_result
ORDER BY chinese + english + math DESC;
+-----------+-------------------------+
| name | chinese + english + math |
+-----------+-------------------------+
| 猪悟能 | 276 |
| 孙悟空 | 242 |
| 曹孟德 | 233 |
| 唐三藏 | 221 |
| 孙权 | 221 |
| 刘玄德 | 185 |
| 宋公明 | 170 |
+-----------+-------------------------+
7 rows in set (0.00 sec)ORDER BY中可以使用别名:
SELECT name, chinese + english + math 总分 FROM exam_result
ORDER BY 总分 DESC;
+-----------+--------+
| name | 总分 |
+-----------+--------+
| 猪悟能 | 276 |
| 孙悟空 | 242 |
| 曹孟德 | 233 |
| 唐三藏 | 221 |
| 孙权 | 221 |
| 刘玄德 | 185 |
| 宋公明 | 170 |
+-----------+--------+
7 rows in set (0.00 sec)筛选分页结果:
语法:
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;建议: 对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死
按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页:
-- 第 1 页
SELECT id, name, math, english, chinese FROM exam_result
ORDER BY id LIMIT 3 OFFSET 0;
+----+-----------+--------+--------+-------+
| id | name | math | english | chinese |
+----+-----------+--------+--------+-------+
| 1 | 唐三藏 | 98 | 56 | 67 |
| 2 | 孙悟空 | 78 | 77 | 87 |
| 3 | 猪悟能 | 98 | 90 | 88 |
+----+-----------+--------+--------+-------+
3 rows in set (0.02 sec)
-- 第 2 页
SELECT id, name, math, english, chinese FROM exam_result
ORDER BY id LIMIT 3 OFFSET 3;
+----+-----------+--------+--------+-------+
| id | name | math | english | chinese |
+----+-----------+--------+--------+-------+
| 4 | 曹孟德 | 84 | 67 | 82 |
| 5 | 刘玄德 | 85 | 45 | 55 |
| 6 | 孙权 | 73 | 78 | 70 |
+----+-----------+--------+--------+-------+
3 rows in set (0.00 sec)
-- 第 3 页,如果结果不足 3 个,不会有影响
SELECT id, name, math, english, chinese FROM exam_result
ORDER BY id LIMIT 3 OFFSET 6;
+----+-----------+--------+--------+-------+
| id | name | math | english | chinese |
+----+-----------+--------+--------+-------+
| 7 | 宋公明 | 65 | 30 | 75 |
+----+-----------+--------+--------+-------+
1 row in set (0.00 sec)Update(更新)
语法:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]将孙悟空同学的数学成绩变更为 80 分:
-- 数据更新
UPDATE exam_result SET math = 80 WHERE name = '孙悟空';
Query OK, 1 row affected (0.04 sec)
Rows matched: 1 Changed: 1 Warnings: 0
-- 查看更新后数据
SELECT name, math FROM exam_result WHERE name = '孙悟空';
+-----------+--------+
| name | math |
+-----------+--------+
| 孙悟空 | 80 |
+-----------+--------+
1 row in set (0.00 sec)将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分:
UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';
Query OK, 1 row affected (0.14 sec)
Rows matched: 1 Changed: 1 Warnings: 0
-- 查看更新后数据
SELECT name, math, chinese FROM exam_result WHERE name = '曹孟德';
+-----------+--------+-------+
| name | math | chinese |
+-----------+--------+-------+
| 曹孟德 | 60 | 70 |
+-----------+--------+-------+
1 row in set (0.00 sec)将总成绩倒数前三的 3 位同学的数学成绩加上 30 分:
-- 数据更新,不支持 math += 30 这种语法
UPDATE exam_result SET math = math + 30
ORDER BY chinese + math + english LIMIT 3;
-- 查看更新后数据
-- 思考:这里还可以按总分升序排序取前 3 个么?
SELECT name, math, chinese + math + english 总分 FROM exam_result
WHERE name IN ('宋公明', '刘玄德', '曹孟德');
+-----------+--------+--------+
| name | math | 总分 |
+-----------+--------+--------+
| 曹孟德 | 90 | 227 |
| 刘玄德 | 115 | 215 |
| 宋公明 | 95 | 200 |
+-----------+--------+--------+
3 rows in set (0.00 sec)Delete(删除)
删除数据:
语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]删除孙悟空同学的考试成绩:
-- 查看原数据
SELECT * FROM exam_result WHERE name = '孙悟空';
+----+-----------+-------+--------+--------+
| id | name | chinese | math | english |
+----+-----------+-------+--------+--------+
| 2 | 孙悟空 | 174 | 80 | 77 |
+----+-----------+-------+--------+--------+
1 row in set (0.00 sec)
-- 删除数据
DELETE FROM exam_result WHERE name = '孙悟空';
Query OK, 1 row affected (0.17 sec)
-- 查看删除结果
SELECT * FROM exam_result WHERE name = '孙悟空';
Empty set (0.00 sec)删除整张表数据:
慎用!慎用!慎用!
结构会被保留,数据会被清空
-- 准备测试表
CREATE TABLE for_delete (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
Query OK, 0 rows affected (0.16 sec)
-- 插入测试数据
INSERT INTO for_delete (name) VALUES ('A'), ('B'), ('C');
Query OK, 3 rows affected (1.05 sec)
Records: 3 Duplicates: 0 Warnings: 0
-- 查看测试数据
SELECT * FROM for_delete;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.00 sec)截断表:
语法:
TRUNCATE [TABLE] table_name注意这个操作慎用:
- 只能对整表操作,不能像 DELETE 一样针对部分数据操作
- 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
- 会重置 AUTO_INCREMENT 项
-- 准备测试表
CREATE TABLE for_truncate (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
Query OK, 0 rows affected (0.16 sec)
-- 插入测试数据
INSERT INTO for_truncate (name) VALUES ('A'), ('B'), ('C');
Query OK, 3 rows affected (1.05 sec)
Records: 3 Duplicates: 0 Warnings: 0
-- 查看测试数据
SELECT * FROM for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.00 sec)
TRUNCATE for_truncate;
Query OK, 0 rows affected (0.10 sec)
-- 截断整表数据,注意影响行数是 0,所以实际上没有对数据真正操作
-- 查看删除结果
SELECT * FROM for_truncate;
Empty set (0.00 sec)
-- 再插入一条数据,自增 id 在重新增长
INSERT INTO for_truncate (name) VALUES ('D');
Query OK, 1 row affected (0.00 sec)
-- 查看数据
SELECT * FROM for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | D |
+----+------+
1 row in set (0.00 sec)
插入查询结果
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...案例:
CREATE TABLE duplicate_table (id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
-- 插入测试数据
INSERT INTO duplicate_table VALUES
(100, 'aaa'),
(100, 'aaa'),
(200, 'bbb'),
(200, 'bbb'),
(200, 'bbb'),
(300, 'ccc');
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0思路: 创建一张空表 no_duplicate_table,结构和 duplicate_table 一样,然后对dumplicate_table中的数据去重后插入到no_duplicate_table中:
-- 创建一张空表 no_duplicate_table,结构和 duplicate_table 一样 CREATE TABLE no_duplicate_table LIKE duplicate_table; Query OK, 0 rows affected (0.00 sec) -- 将 duplicate_table 的去重数据插入到 no_duplicate_table INSERT INTO no_duplicate_table SELECT DISTINCT * FROM duplicate_table; Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 -- 通过重命名表,实现原子的去重操作 RENAME TABLE duplicate_table TO old_duplicate_table, no_duplicate_table TO duplicate_table; Query OK, 0 rows affected (0.00 sec) -- 查看最终结果 SELECT * FROM duplicate_table; +------+------+ | id | name | +------+------+ | 100 | aaa | | 200 | bbb | | 300 | ccc | +------+------+ 3 rows in set (0.00 sec)
聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |




![[陇剑杯 2021]jwt](https://img-blog.csdnimg.cn/d7a5d9849ce34d058b7c974f8ad5d277.png)