一、哈希表(Hash Table)简介:
哈希表是一种数据结构,用于实现字典或映射等抽象数据类型。它通过把关键字映射到表中的一个位置来实现快速的数据检索。哈希表的基本思想是利用哈希函数将关键字映射到数组的索引位置上,从而实现常数时间的查找、插入和删除操作。
二、哈希表的基本组成部分:
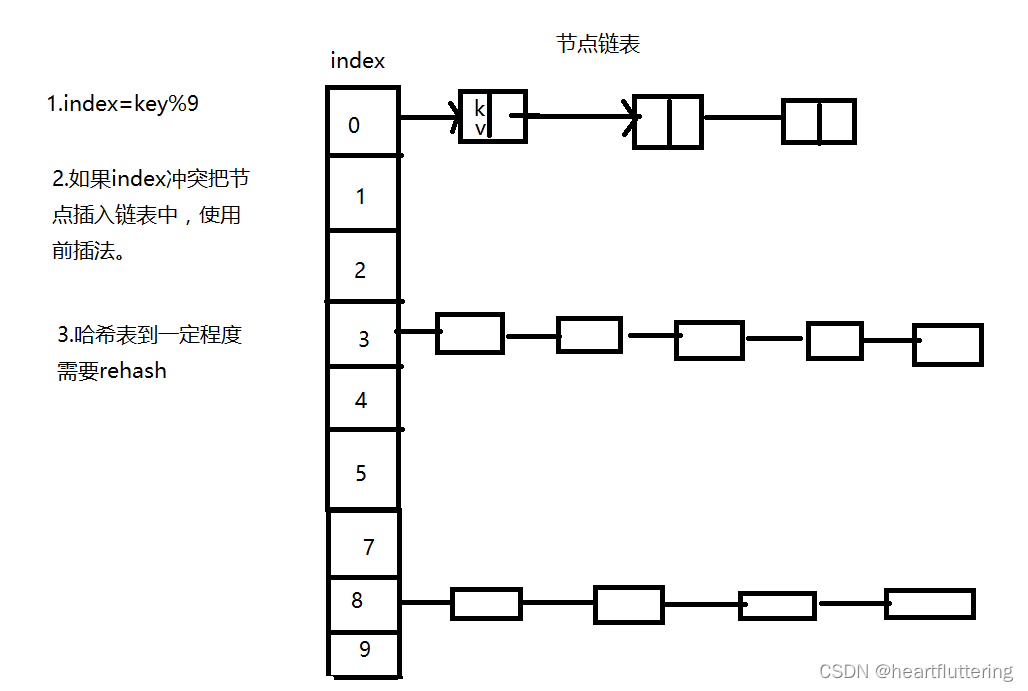
- 哈希函数(Hash Function): 哈希函数负责将关键字映射到哈希表的索引位置。一个好的哈希函数应该能够将关键字均匀地分布到哈希表的各个位置上,减少冲突的概率。
- 数组(Array): 哈希表的主要存储结构是一个数组,通过哈希函数计算的索引将关键字映射到数组的位置上。
- 冲突处理(Collision Resolution): 冲突是指两个不同的关键字被哈希函数映射到了相同的位置上。常见的冲突处理方法包括链地址法和开放地址法。
- 链地址法(Separate Chaining): 每个哈希表的位置上维护一个链表,冲突的关键字被放入相应位置的链表中。如上图所示,是一个链地址法实现的哈希表。
- 开放地址法(Open Addressing):如果发生冲突,就尝试寻找下一个可用的位置。有多种开放地址法的实现方式,如线性探测、二次探测等。
三、Java 中的 HashMap:
在 Java 中,HashMap 是基于哈希表实现的键值对存储的数据结构。以下是 HashMap 的一些重要特性和实现细节:
- 数据结构: HashMap 使用数组存储键值对,每个数组元素称为桶(bucket)。每个桶可以存储多个键值对。
- 哈希函数: HashMap 使用键的哈希码来确定桶的位置。Java 中的
hashCode()方法用于获取对象的哈希码。 - 冲突处理: 当多个键的哈希码映射到相同的桶上时,HashMap 使用链地址法或者红黑树来解决冲突,即在桶中维护一个链表。
- 负载因子和扩容: HashMap 有一个负载因子(load factor)的概念,当桶中的键值对数量达到负载因子与桶的容量的乘积时,触发扩容操作。默认负载因子为 0.75。负载因子的值增大,冲突率也随着增大,我们不能直接控制冲突率,可以通过影响负载因子来降低冲率,而控制负载因子,负载因子是哈希表的元素数量除哈希桶数量,我们认为哈希表要传入的数量是未知的,也可以看作无穷的,所以,通过不能降低减少哈希表元素的数量来降低负载因子的值,但我们可以通过增加哈希桶的值来降低负载因子的值,进而降低冲突率。
- 迭代顺序: HashMap 的迭代顺序不是固定的,不同版本的 JDK 可能有不同的实现。在 Java 8 之前,HashMap 的迭代顺序是不确定的。在 Java 8 及以后,为了提高性能,引入了红黑树(RB-tree)来优化链表,影响了迭代顺序。
- 线程安全: HashMap 不是线程安全的,如果多个线程同时操作 HashMap,可能会导致并发问题。可以考虑使用
Collections.synchronizedMap()或者ConcurrentHashMap来实现线程安全。参考【数据类型】ConcurrentHashMap分段锁实现高并发 和【数据类型】Collections.synchronizedMap 多线程Map
// 示例代码
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
// 创建 HashMap 实例
Map<String, Integer> hashMap = new HashMap<>();
// 添加键值对
hashMap.put("Alice", 25);
hashMap.put("Bob", 30);
hashMap.put("Charlie", 22);
// 获取值
int age = hashMap.get("Bob");
System.out.println("Bob's age: " + age);
// 遍历 HashMap
for (Map.Entry<String, Integer> entry : hashMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
}
上述代码展示了使用 HashMap 存储和访问键值对的基本操作。
四、java中的HashTable
HashTable也是利用哈希表算法原理,Hashtable底层也采用数组+链表的数据结构进行实现,当哈希冲突发生时,使用链表来解决冲突。与HashMap不同的是,Hashtable在JDK 8及以前没有使用红黑树解决哈希冲突,这导致了其效率相对较低。还有以下几处不同:
1、同步性:
- HashTable: 是线程安全的,所有的方法都是同步的,即在单个方法调用时,HashTable 会对其进行锁定,以确保线程安全。这使得在并发环境下,HashTable 是安全的,但在性能上可能会受到影响。
- HashMap: 不是线程安全的。在多线程环境下,如果没有外部同步措施,对 HashMap 进行并发修改可能导致不确定的结果。
2、空值处理:
- HashTable: 不允许键或值为 null,如果试图存储 null 键或值,会抛出 NullPointerException。
- HashMap: 允许键和值为 null。
3、继承关系:
- Hashtable 继承自Dictionary类,Dictionary类是一个已经被废弃的类(见其源码中的注释)。父类都被废弃,自然而然也没人用它的子类Hashtable了。
- HashMap 继承自AbstractMap类,是 Java Collections Framework 中的一部分。但二者都实现了Map接口。
4、性能:
- 由于 HashTable 在所有方法上使用同步,它在性能上可能会受到影响,尤其在多线程环境下。
- HashMap 不使用同步,因此在单线程环境或者不需要线程安全保证的场景下,性能可能更好。
在新的 Java 5+ 版本中,推荐使用 HashMap 或者 ConcurrentHashMap 而不是
HashTable,因为它们提供了更好的性能和更灵活的使用方式。
5、包含的contains方法不同
- hashtable则保留了
contains方法,效果同 containsValue ,还包括 containsValue 和 containsKey 方法。 - HashMap是没有
contains方法的,而包括 containsValue 和 containsKey 方法.
6、应用场景
根据上述的区别和特点,我们可以得出以下建议:
- 如果线程安全的Map集合,并且不需要存储
null键或null值,可以选择Hashtable; - 如果需要高效、非线程安全的Map集合,并且需要存储
null键或null值,可以选择HashMap; - 如果需要高效、线程安全的Map集合,可以选择使用
ConcurrentHashMap,也允许键、值为null。
知识是一个环,来我的博客绕圈吧~ 持续更新中,后续更精彩!