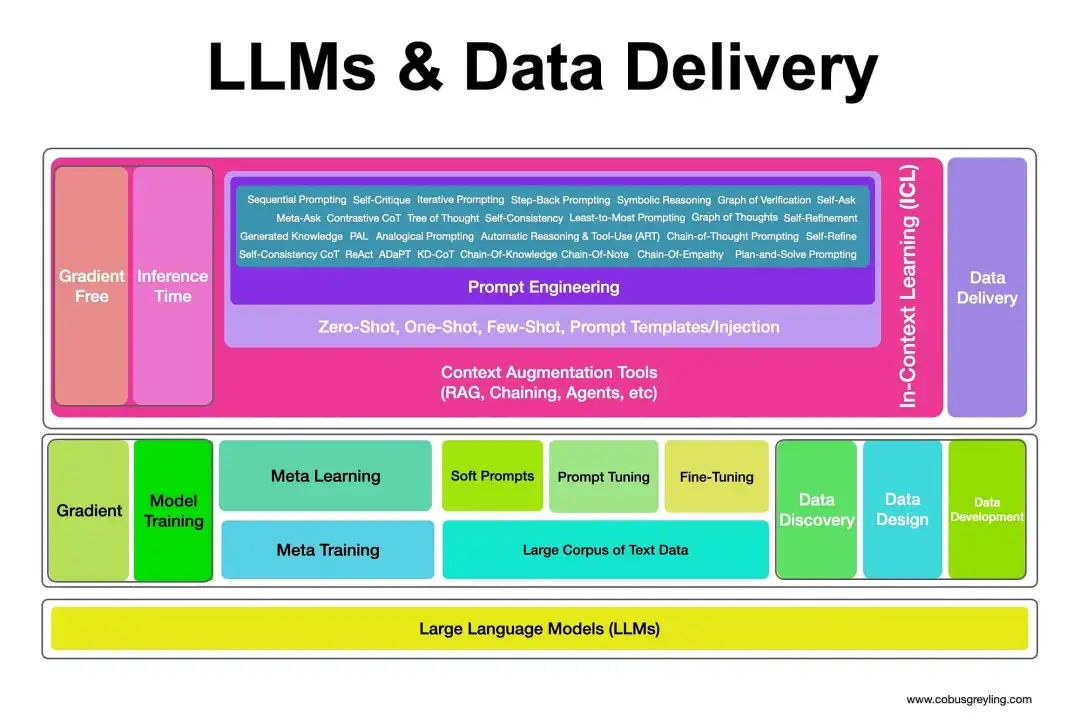
DeepFusion
Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
用于多模态 3D 物体检测的激光雷达相机深度融合
论文网址:DeepFusion
论文代码:DeepFusion
摘要
激光雷达和摄像头是关键传感器,可为自动驾驶中的 3D 检测提供补充信息。现在流行的多模态方法只是简单地用相机特征装饰原始激光雷达点云,并将它们直接输入到现有的 3D 检测模型,但本文的研究表明,将相机特征与深度激光雷达特征而不是原始点融合,可以带来更好的效果。然而,由于这些特征经常被增强和聚合,融合的一个关键挑战是如何有效地对齐两种模态的转换后的特征。本文提出了两种新颖的技术:InverseAug,它反转几何相关的增强(例如旋转),以实现激光雷达点和图像像素之间的精确几何对齐;LearnableAlign,它利用交叉注意力来动态捕获图像和激光雷达之间的相关性融合过程中的特征。基于 InverseAug 和 LearnableAlign,本文开发了一系列通用的多模态 3D 检测模型,名为 DeepFusion,它比以前的方法更准确。例如,DeepFusion 将行人检测的 PointPillars、CenterPoint 和 3D-MAN 基线分别改进为 6.7、8.9 和 6.2 LEVEL 2 APH。
引言
激光雷达和摄像头是自动驾驶的两种互补传感器。对于 3D 物体检测,激光雷达提供低分辨率形状和深度信息,而相机提供高分辨率形状和纹理信息。虽然人们期望这两种传感器的组合能够提供最佳的 3D 物体检测器,但事实证明,大多数最先进的 3D 物体检测器仅使用激光雷达作为输入 。这表明如何有效地融合这两个传感器的信号仍然具有挑战性。
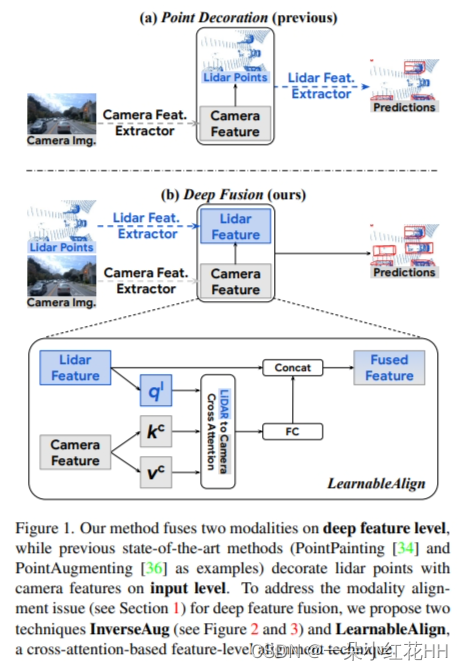
文献中融合激光雷达和相机的现有方法大致遵循两种方法(图 1):它们要么在早期阶段融合特征,例如用相应的相机特征装饰激光雷达点云中的点 ,或者他们使用中级融合,其中特征在特征提取后组合 。这两种方法中最大的挑战之一是找出激光雷达和相机功能之间的对应关系。为了解决这个问题,我们提出了两种方法:InverseAug 和 LearnableAlign,以实现有效的中级融合。 InverseAug 反转几何相关的数据增强(例如,RandomRotation ),然后使用原始相机和激光雷达参数来关联两种模态。 LearnableAlign 利用交叉注意力来动态学习激光雷达特征与其相应的相机特征之间的相关性。这两种提出的技术简单、通用且高效。给定一种流行的 3D 点云检测框架,例如 PointPillars 和 CenterPoint ,InverseAug 和 LearnableAlign 可以帮助相机图像以边际计算成本(即只有一个交叉注意层)有效地与激光雷达点云对齐。当融合对齐的多模态特征时,相机信号具有更高的分辨率,显着提高了模型的识别和定位能力。这些优点对于远距离物体检测特别有利。
本文开发了一系列名为 DeepFusions 的多模态 3D 检测模型,其优点是 (1) 可以进行端到端训练,(2) 是与许多现有的基于体素的 3D 检测方法兼容的通用构建块。 DeepFusion 作为一个插件,可以轻松应用于大多数基于体素的 3D 检测方法,例如 PointPillars 和 CenterPoint。
本文大量实验表明,(1) 有效的深度特征对齐是多模态 3D 目标检测的关键,(2) 通过本文提出的 InverseAug 和 LearnableAlign 提高对齐质量,DeepFusion 显着提高了检测精度,(3) 与单模态基线 DeepFusion 相比,对于输入损坏和分布外数据具有更强的鲁棒性。
在 Waymo 开放数据集上,DeepFusion 将 PointPillars 、CenterPoints 和 3D-MAN 等几种流行的 3D 检测模型分别改进了 6.7、8.9 和 6.2 LEVEL 2 APH。在 Waymo 开放数据集上取得了最先进的结果,在验证集上,DeepFusion 比之前最好的多模态方法 PointAugmenting 提高了 7.4 行人 LEVEL 2 APH。这一结果表明,本文的方法能够有效地结合激光雷达和相机模式,其中最大的改进来自于远程物体的识别和定位。
本文贡献:
- 本文是第一个系统研究深度特征对齐对 3D 多模态检测器的影响的论文;
- 本文提出 InverseAug 和 LearnableAlign 来实现深度特征级对齐,从而实现准确且鲁棒的 3D 目标检测器;
- 本文提出的模型 DeepFusions 在 Waymo 开放数据集上实现了最先进的性能。
相关工作
点云上的 3D 物体检测. : 激光雷达点云通常表示为无序集,并且许多 3D 目标检测方法倾向于直接处理此类原始无序点。 PointNet 和 PointNet++ 是直接在点云上应用神经网络的早期开创性工作。紧随其后,[Starnet,pointrcnn,Ipod]也通过类似PointNet的层学习特征。激光雷达点云也可以表示为密集范围图像,其中每个像素都包含额外的深度信息。 [Lasernet] 直接处理范围图像来预测 3D 边界框。
另一组 3D 检测方法将激光雷达点转换为体素或pillar,从而产生两种更常用的 3D 检测方法:基于体素的方法和基于pillar的方法。 VoxelNet 提出了一种基于体素的方法,它将点云离散化为 3D 网格,每个子空间称为体素。然后可以将密集的 3D 卷积网络应用于该网格来学习检测特征。 SECOND 基于 VoxelNet 构建,并建议使用稀疏 3D 卷积来提高效率。由于 3D 体素的处理成本通常很高,PointPillars和 PIXOR 进一步将 3D 体素简化为鸟瞰 2D 柱,其中具有相同 z 轴的所有体素都折叠为单个柱。然后可以使用现有的 2D 卷积检测网络处理这些 2D 柱,以生成鸟瞰边界框。由于 2D 柱通常易于处理且快速,因此许多最近的 3D 检测方法都是基于 PointPillars 构建的。本文也选择 PointPillar 作为处理激光雷达点云的基线方法。
激光雷达相机融合. : 单目检测方法不依赖激光雷达点云,而是直接从 2D 图像预测 3D 框。这些方法的一个关键挑战是 2D 图像没有深度信息,因此大多数单目检测器需要隐式或显式预测每个 2D 图像像素的深度,这通常是另一个非常困难的任务。最近,有一种趋势是结合激光雷达和摄像头数据来改进 3D 检测。一些方法首先检测 2D 图像中的对象,然后使用该信息进一步处理点云。之前的工作也使用两阶段框架来执行以对象为中心的模态融合。与这些方法相比,本文的方法更容易插入到大多数现有的基于体素的 3D 检测方法中。
点装饰融合. : PointPainting 提出用相机图像的语义分数来增强每个激光雷达点,这些图像是通过预先训练的语义分割网络提取的。 PointAugmenting 指出了语义分数的局限性,并提出使用从相机图像之上的 2D 对象检测网络提取的深层特征来增强激光雷达点。如图 1 (a) 所示,这些方法依赖于预训练模块(例如 2D 检测或分割模型)从相机图像中提取特征,这些特征用于装饰原始点云,然后输入激光雷达特征体素化器构建鸟瞰伪图像。
中级融合. : Deep Continuous Fusion 、EPNet 和 4D-Net 尝试通过共享 2D 和 3D 主干网之间的信息来融合两种模式。然而,这些工作中一个重要的缺失部分是相机和激光雷达特征之间的有效对齐机制,本文的实验证实这是构建有效的端到端多模态 3D 物体检测器的关键。即使知道特征对齐的重要性,由于以下原因,这样做仍然具有挑战性。首先,为了在现有基准(例如 Waymo 开放数据集)上实现最佳性能,在融合阶段之前将各种数据增强策略应用于激光雷达点和相机图像。例如,沿z轴旋转3D世界的RandomRotation[Voxelnet]通常应用于激光雷达点,但不适用于相机图像,这使得后续的特征对齐变得困难。其次,由于场景中多个激光雷达点聚合成同一个3D立方体,即体素,一个体素对应多个相机特征,而这些相机特征对于3D检测来说并不同等重要。
DeepFusion
在本节中,首先介绍本文的深度特征融合pipeline。然后,进行了一组初步实验来定量说明特征对齐对于深度特征融合的重要性。最后,提出了两种技术,InverseAug 和 LearnableAlign,来提高对齐质量。
Deep Feature Fusion Pipeline
深度特征融合管道
如图 1(a)所示,以前的方法,例如 PointPainting 和 PointAugmenting ,通常使用经过额外训练的检测或分割模型作为相机特征提取器。例如,PointPainting 使用 Deeplabv3+ 生成每像素分割标签作为相机特征。然后,用提取的相机特征装饰原始激光雷达点。最后,将经过相机特征修饰的激光雷达点输入到 3D 点云目标检测框架中。
由于以下原因,上述pipeline是可以改进的。首先,相机功能被输入到几个专门用于处理点云数据的模块中。例如,如果采用PointPillars作为3D检测框架,则需要将相机特征与原始点云一起体素化以构建鸟瞰伪图像。然而,体素化模块并不是为处理相机信息而设计的。其次,相机特征提取器是从其他独立任务(即 2D 检测或分割)中学习的,这可能会导致(1)域间隙,(2)注释工作,(3)额外的计算成本,更重要的是,(4 )次优提取的特征,因为特征是启发式选择的,而不是以端到端的方式学习的。
为了解决上述两个问题,本文提出了一种深度特征融合pipeline。为了解决第一个问题,本文融合深度相机和激光雷达特征,而不是在输入级别装饰原始激光雷达点,以便相机信号不会通过为点云设计的模块。对于第二个问题,本文使用卷积层来提取相机特征,并以端到端的方式与网络的其他组件一起训练这些卷积层。总而言之,本文提出的深度特征融合流程如图 1 (b) 所示:将激光雷达点云输入现有的激光雷达特征提取器(例如,来自 PointPillars 的 Pillar 特征网络)以获得激光雷达特征(例如,来自 PointPillars 的伪图像 );将相机图像输入 2D 图像特征提取器(例如 ResNet )以获得相机特征;然后,将相机特征与激光雷达特征融合;最后,融合的特征由所选激光雷达检测框架的其余组件(例如来自Pointpillars 的Backbone和Detection Head)进行处理以获得检测结果。
与以前的设计相比,本文的方法有两个好处:(1)具有丰富上下文信息的高分辨率相机特征不需要被错误地体素化,然后从透视图转换为鸟瞰图; (2)领域差距和注释问题得到缓解,并且由于端到端训练可以获得更好的相机特征。然而,缺点也很明显:与输入级修饰相比,在深层特征级别上将相机特征与激光雷达信号对齐变得不那么简单。例如,两种模态的异构数据增强导致的不准确对齐可能会给融合阶段带来潜在的挑战。在第 3.2 节中,本文验证了错位确实会损害检测模型,并在第 3.3 节中提供了解决方案。
Impact of Alignment Quality
对齐质量的影响
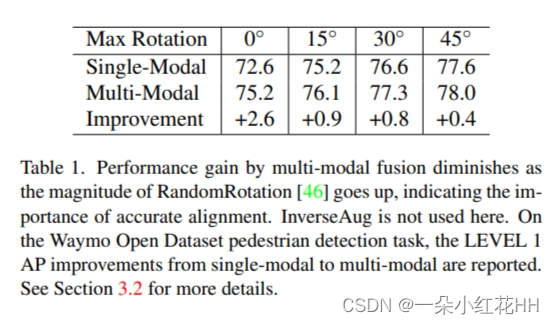
为了定量评估对齐对深度特征融合的影响,本文禁用所有其他数据增强,但仅在训练期间将 RandomRotation 的幅度扭曲到深度融合pipeline的激光雷达点云。实验设置的更多详细信息可以在补充材料中找到。由于仅增强激光雷达点云但保持相机图像不变,因此更强的几何相关数据增强会导致更差的对齐。如表 1 所示,多模态融合的好处随着旋转角度的增大而减小。例如,当不应用增强时(最大旋转=0°),改进是最显着的(+2.6 AP);当最大旋转为 45° 时,仅观察到 +0.4 AP 增益。基于这些观察,得出结论,对齐对于深度特征融合至关重要,如果对齐不准确,那么相机输入的好处就会变得微乎其微。
Boosting Alignment Quality
提高对准质量
鉴于对齐深度特征的重要性,本文提出了两种技术,InverseAug 和 LearnableAlign,来有效地对齐两种模态的深度特征。
InverseAug. 为了在现有基准上获得最佳性能,大多数方法都需要强大的数据增强,因为训练通常会陷入过度拟合的情况。从表1中可以看出数据增强的重要性,其中单模态模型的精度最多可以提高5.0。此外,[Improving 3d object detection through progressive population based augmentation] 还提出了数据增强对于训练 3D 目标检测模型的重要性。然而,数据增强的必要性对 DeepFusion pipeline提出了不小的挑战。具体来说,来自两种模式的数据通常采用不同的增强策略进行增强(例如,针对 3D 点云沿 z 轴旋转,结合针对 2D 图像的随机翻转),使得对齐具有挑战性。
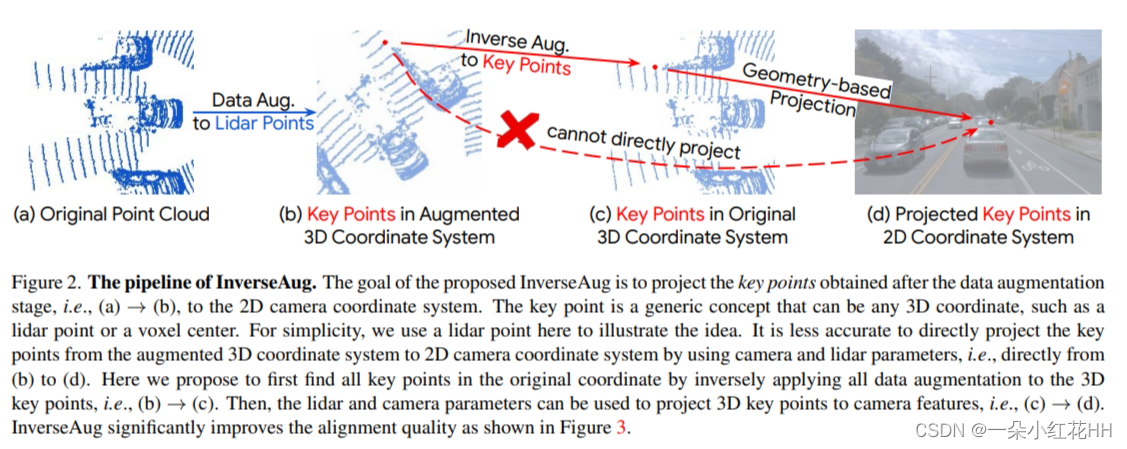
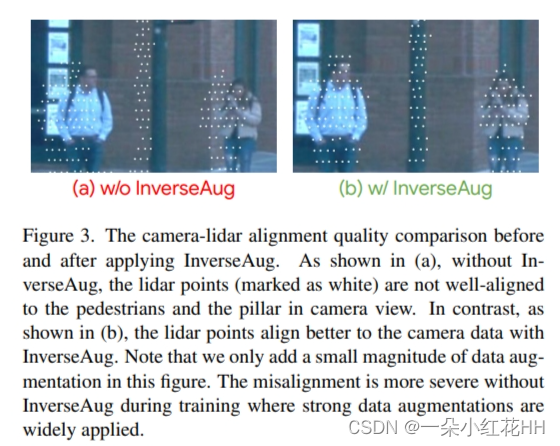
为了解决几何相关数据增强引起的对齐问题,本文提出了 InverseAug。如图2所示,将数据增强应用于点云后,给定增强空间中的3D关键点(可以是任意3D坐标,例如激光雷达点、体素中心等),对应的相机特征无法得到只需使用原始激光雷达和相机参数即可在 2D 空间中进行定位。为了使定位可行,InverseAug 在应用几何相关的数据增强时首先保存增强参数(例如 RandomRotate 的旋转度)。在融合阶段,它反转所有这些数据增强以获得3D关键点的原始坐标(图2(c)),然后在相机空间中找到其对应的2D坐标。请注意,本文的方法是通用的,因为它可以对齐不同类型的关键点(例如体素中心),尽管为了简单起见仅采用图 2 中的激光雷达点,并且它还可以处理两种模态都增强的情况。相比之下,现有的融合方法(例如PointAugmenting )只能处理增强之前的数据。最后,在图 3 (b) 中展示了 InverseAug 对齐质量改进的示例。
LearnableAlign. 对于输入级装饰方法,例如 PointPainting 和 PointAugmenting ,给定 3D 激光雷达点,由于存在一对一映射,因此可以准确定位唯一对应的相机像素。相比之下,当在 DeepFusion 管道中融合深度特征时,每个激光雷达特征代表一个包含点子集的体素,因此其相应的相机像素位于多边形中。因此,对齐变成了一个体素到多个像素的问题。一种简单的方法是对与给定体素对应的所有像素进行平均。然而,直观地看,正如可视化结果所支持的那样,这些像素并不同样重要,因为来自激光雷达深度特征的信息与每个相机像素的对齐程度不同。例如,某些像素可能包含检测的关键信息,例如要检测的目标对象,而其他像素可能信息量较少,由背景(例如道路、植物、遮挡物等)组成。
为了更好地将来自激光雷达特征的信息与最相关的相机特征对齐,本文引入了 LearnableAlign,它利用交叉注意力机制来动态捕获两种模态之间的相关性,如图 1 所示。具体来说,输入包含一个体素单元,及其所有相应的 N 相机功能。 LearnableAlign 使用三个全连接层分别将体素转换为查询 ql,将相机特征转换为键 kc 和值 vc。对于每个查询(即体素单元),在查询和键之间进行内积以获得注意力亲和度矩阵,该矩阵包含体素与其所有对应的 N 个相机特征之间的 1 × N 相关性。通过 softmax 算子进行归一化,然后使用注意力亲和度矩阵来加权和聚合包含相机信息的 vc 值。然后聚合的相机信息由全连接层处理,最后与原始激光雷达特征连接。输出最终被输入到任何标准 3D 检测框架中,例如用于模型训练的 PointPillars 或 CenterPoint。
结论
本文研究如何有效融合激光雷达和相机数据以进行多模态 3D 物体检测。研究表明,后期的深度特征融合在对齐良好时会更加有效,但是对齐来自不同模态的两个深度特征具有挑战性。为了应对这一挑战,本文提出了两种技术:InverseAug 和 LearnableAlign,以实现多模态特征之间的有效对齐。基于这些技术,开发了一系列简单、通用但有效的多模态 3D 检测器,名为 DeepFusions,它在 Waymo 开放数据集上实现了最先进的性能。