文章目录
- 1、初始实现思路:@Async注解新开一个线程去审核
- 2、改进思路一:加LinkedBlockingQueue阻塞队列
- 3、改进思路二:RabbitMQ
- 4、总结
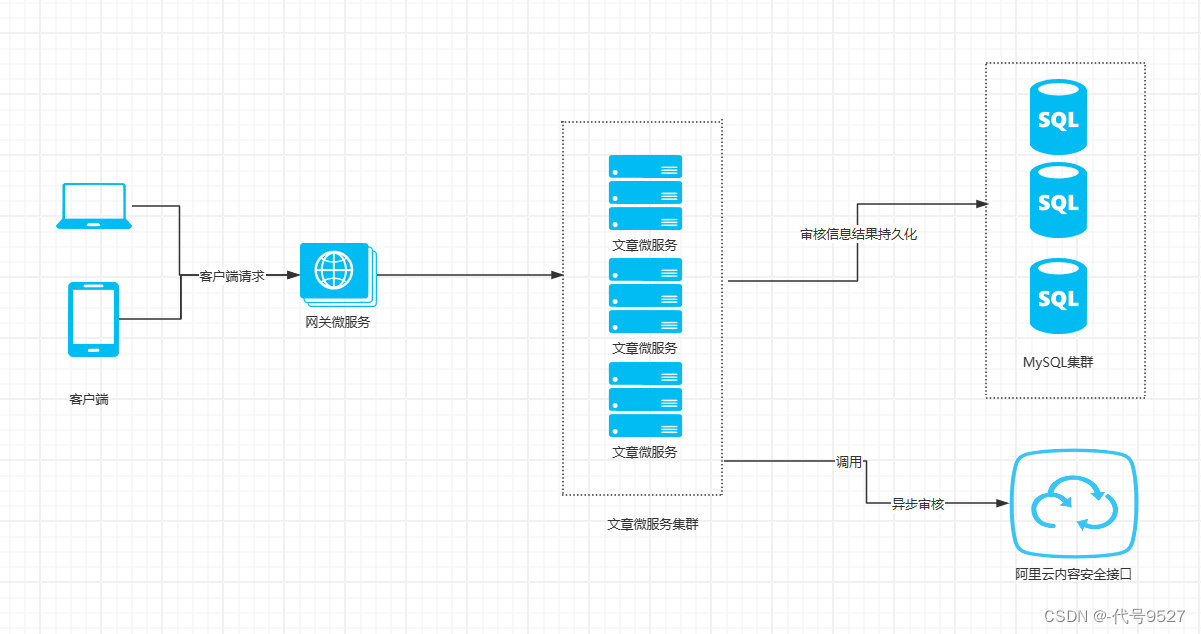
背景:文章微服务中有一个文章审核接口,接口内又调用阿里云的内容安全接口进行文字图片的审核。
1、初始实现思路:@Async注解新开一个线程去审核
客户端请求经网关到文章微服务后,因为调用阿里云安全审核接口得等一会儿才能出结果,所以这里做个落库后即返回信息给用户(比如提交成功,审核中),然后异步去调审核接口。实现思路:用@Async注解单起一个线程去审核,接口当前线程直接返回结果。
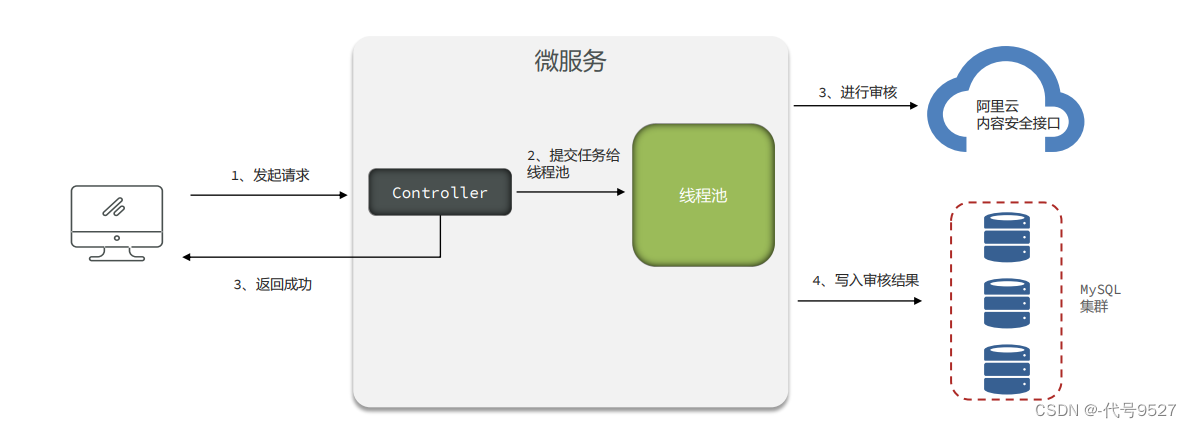
Demo代码:
@PostMapping("/demo1/{id}")
public void article1(@PathVariable("id") long id, @RequestBody ArticleDto article){
article.setId(id);
articleService.asyncSaveArticle(article);
}
@Service
public class ArticleServiceImpl implements ArticleService {
@Autowired
private AliyunUtil aliyunUtil;
@Override
@Async("asyncTaskExecutor")
public void asyncSaveArticle(ArticleDto article) {
//调用阿里云审核接口,其余落库操作的代码略
aliyunUtil.verify(article.getTitle() + "。" + article.getContent()); //拼接标题和内容成一个新字符串来审核
}
}
这里用sleep模拟远程调用阿里云审核接口的延迟:
@Component
public class AliyunUtil {
//阿里云审核接口调用
public void verify(String content){
try {
/**
* 调用第三方接口审核数据,但是此时网络出现问题,
* 第三方接口长时间没有响应,此处使用休眠来模拟30秒
*/
Thread.sleep(30 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
线程池定义,设置核心线程数、最大线程数、缓存队列长度。注意其中的最大线程数为Integer.MAX_VALUE:
@Configuration
@EnableAsync //开启异步调用@Async
public class AsyncThreadPoolTaskConfig {
private static final int corePoolSize = 50; // 核心线程数(默认线程数)
private static final int keepAliveTime = 10; // 允许线程空闲时间(单位:默认为秒)
private static final int queueCapacity = 200; // 缓冲队列数
private static final String threadNamePrefix = "Async-Task-"; // 线程池名前缀
@Bean("asyncTaskExecutor")
public ThreadPoolTaskExecutor getAsyncExecutor(){
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(Integer.MAX_VALUE);
executor.setQueueCapacity(queueCapacity);
executor.setKeepAliveSeconds(keepAliveTime);
executor.setThreadNamePrefix(threadNamePrefix);
// 线程池对拒绝任务的处理策略
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
// 初始化
executor.initialize();
return executor;
}
}
尝试压测这个接口,压测前VisualVM下堆内存平稳且占用较少:

压测,Jmeter开50个线程不停并发调审核接口:

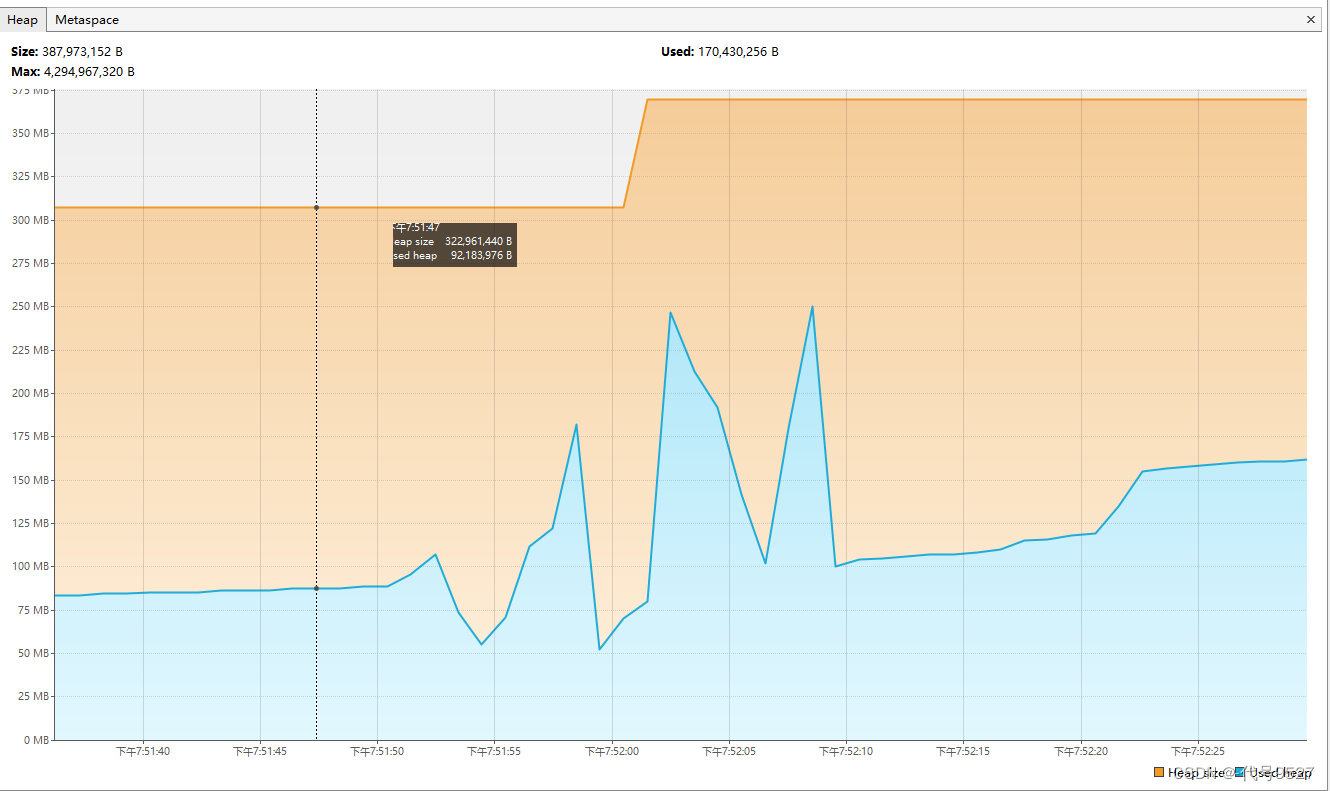
可以看到堆占用呈上涨趋势,不到两分钟就接近一个G:

查看线程信息:六万多线程对象

很明显,线程池不合理,修改最大线程数为100:

重启,堆内存右上右下,整体在一个区间内:
线程对象数量也只有100个左右:

但这样很多请求就被丢弃了(线程池这个办事大厅,就这么多窗口和排队座位,根据我设置的拒绝策略,没地儿了就拒绝并抛出异常)

很明显,问题的根源在于异步调用阿里云审核接口慢,而请求一直在过来,生产的快,消费的慢。而现在的实现,有两个弊病:
- 给@Async用的线程池,线程数开大了或者等待队列长度调大了,会导致大量线程对象创建,占用堆内存
- 任务没有持久化,一旦宕机或者走了线程池拒绝策略,就会丢任务
2、改进思路一:加LinkedBlockingQueue阻塞队列
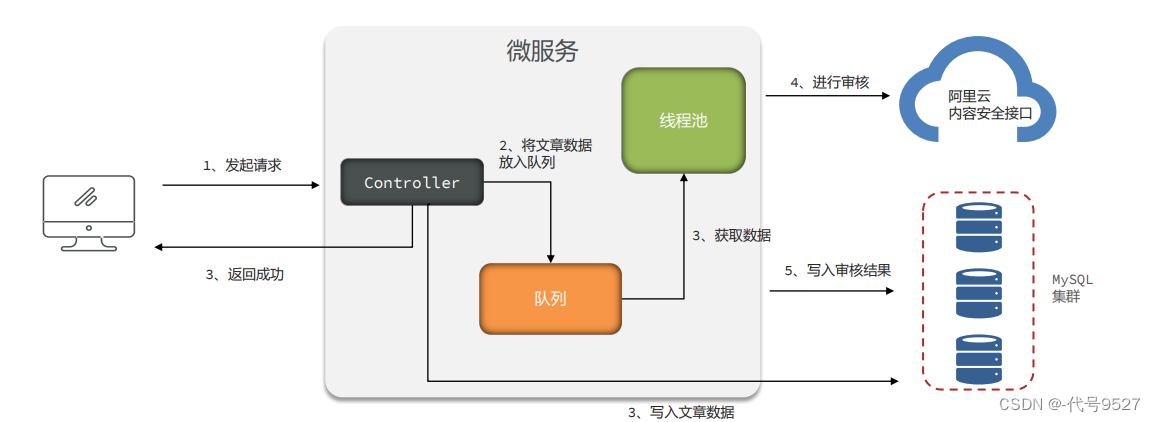
- 关于丢任务的解决:Service层加个写库操作,把文章数据写库里
- 关于大量线程对象被创建的解决:中间垫一个LinkedBlockingQueue阻塞队列(默认大小Intege.MAX_VALUE)
调审核接口,文章数据写库 + 文章数据放入队列,不停从阻塞队列中取数据,提交异步审核任务到一个固定线程数的线程池。Demo代码:
@PostMapping("/demo2/{id}")
public void article2(@PathVariable("id") long id, @RequestBody ArticleDto article){
article.setId(id);
articleService.saveArticle(article);
}
@Service
public class ArticleServiceImpl implements ArticleService {
@Override
@Async("asyncTaskExecutor")
public void asyncSaveArticle(ArticleDto article) {
System.out.println(Thread.currentThread().getName());
aliyunUtil.verify(article.getTitle() + "。" + article.getContent());
}
}
这次的线程池就固定核心线程数50个:
@Configuration
@EnableAsync
public class ThreadPoolTaskConfig {
public static final BlockingQueue<ArticleDto> BUFFER_QUEUE = new LinkedBlockingQueue<>();
private static final int corePoolSize = 50; // 核心线程数(默认线程数)
private static final int maxPoolSize = 100; // 最大线程数
private static final int keepAliveTime = 10; // 允许线程空闲时间(单位:默认为秒)
private static final int queueCapacity = 200; // 缓冲队列数
private static final String threadNamePrefix = "Async-Service-"; // 线程池名前缀
@Bean("taskExecutor")
public ThreadPoolTaskExecutor getAsyncExecutor(){
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(Integer.MAX_VALUE);
//executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setKeepAliveSeconds(keepAliveTime);
executor.setThreadNamePrefix(threadNamePrefix);
// 线程池对拒绝任务的处理策略
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
// 初始化
executor.initialize();
return executor;
}
}
拿一个@PostConstruct注解,目的是执行下从队列取数据提交审核任务到线程池的操作:
@Component
public class ArticleSaveTask {
@Autowired
@Qualifier("taskExecutor")
private ThreadPoolTaskExecutor threadPoolTaskExecutor;
@PostConstruct
public void pullArticleTask(){
/**
* 向线程池提交50个任务
* 每个任务是一个死循环,不停的从我放入文章对象的队列中拿数据,掉审核接口(这里的审核接口直接用休眠模拟)
*/
for (int i = 0; i < 50; i++) {
threadPoolTaskExecutor.submit((Runnable) () -> {
while (true){
try {
ArticleDto data = BUFFER_QUEUE.take();
/**
* 获取到队列中的数据之后,调用第三方接口审核数据,但是此时网络出现问题,
* 第三方接口长时间没有响应,此处使用休眠来模式30秒
*/
Thread.sleep(30 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}
启动,同样的jmeter脚本压测:
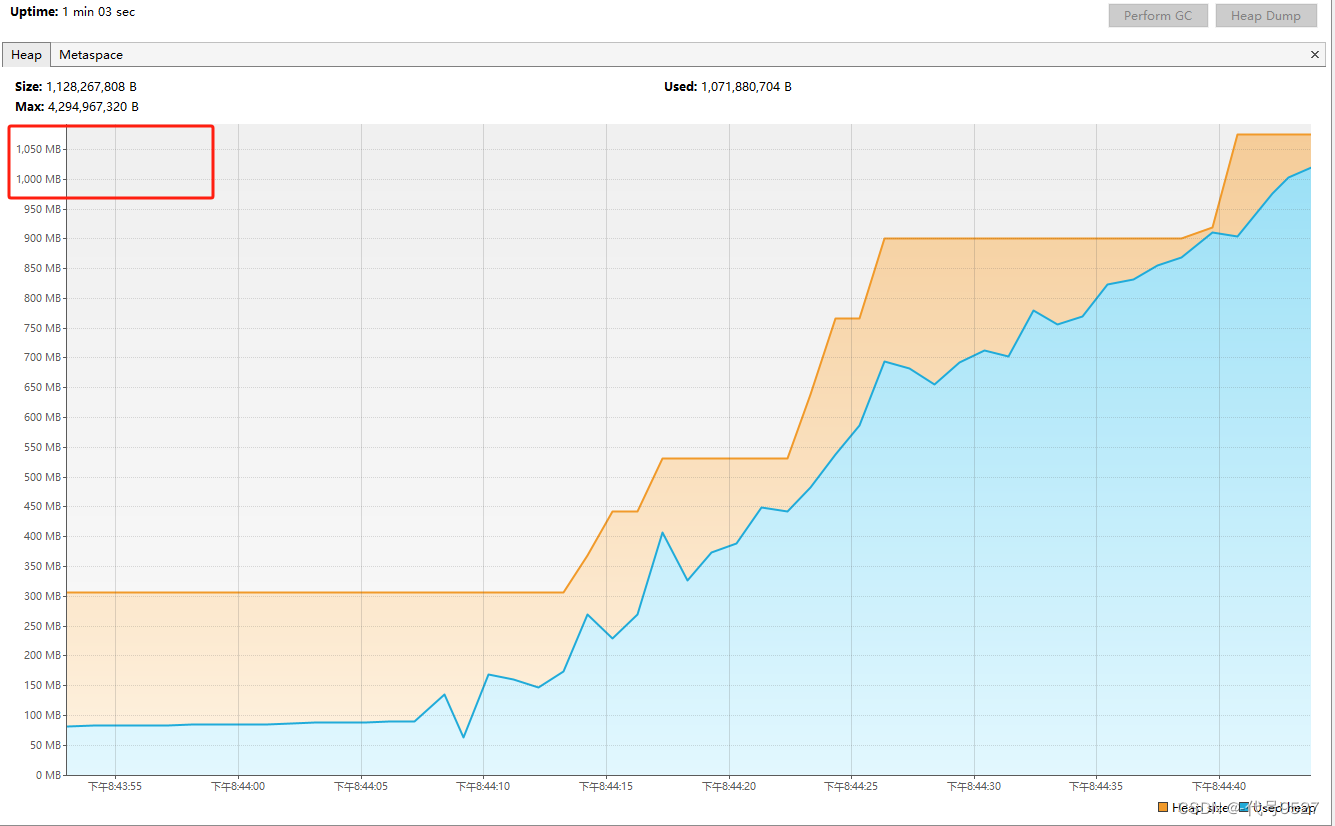
看到堆内存一路升高,且控制台发现已经往队列放了34万个对象了:
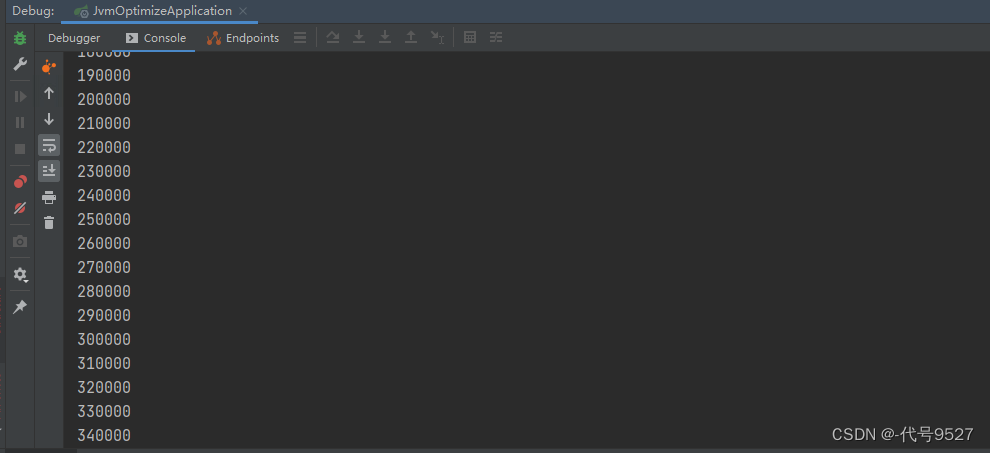
还是不合理,审核时间久,对阻塞队列,生产的快,消费的慢,大量对象积压,最终会oom。考虑把阻塞队列的容量从默认的Intege.MAX_VALUE调小,比如2000,此时内存不会oom,但容量到2000后再add会抛异常,还得自己实现持久化:
public static final BlockingQueue<ArticleDto> BUFFER_QUEUE = new LinkedBlockingQueue<>(2000);
比如当容量满的时候,先存到数据库,等队列不满了再从库里拿出来放到队列(那这里肯定不能用add了,add是满时再放抛异常Queue full,可用put方法)以保证数据不丢失,如此,内存和数据丢失问题久都解决了。但这样实现太繁琐了,一条数据被转移来转移去。
3、改进思路二:RabbitMQ
中间垫一个RabbitMQ,生产者和消费者都是文章审核服务自己。
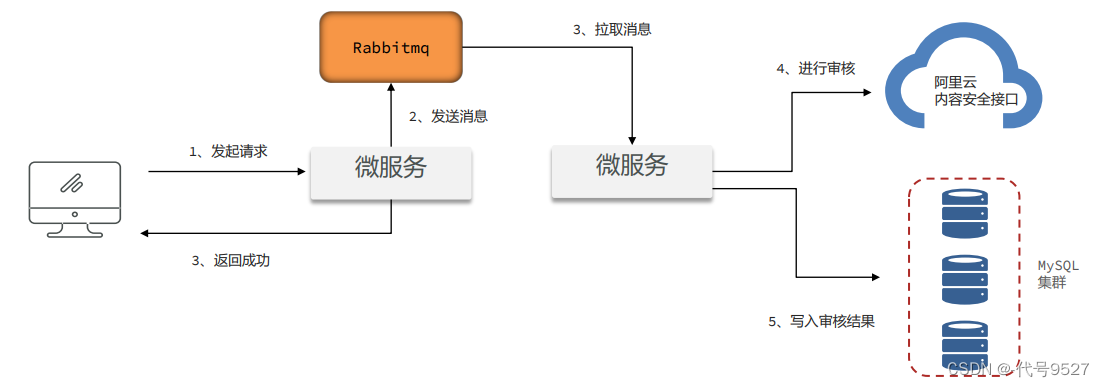
好处:
- 一来,存到RabbitMQ的数据,算服务器内存
- 二来,RabbitMQ有自己的持久化机制,可靠
页面创建个交换机:

页面创建队列并绑定到交换机:(正常写生产消费者服务的代码里,这里做测试,直接页面创建)
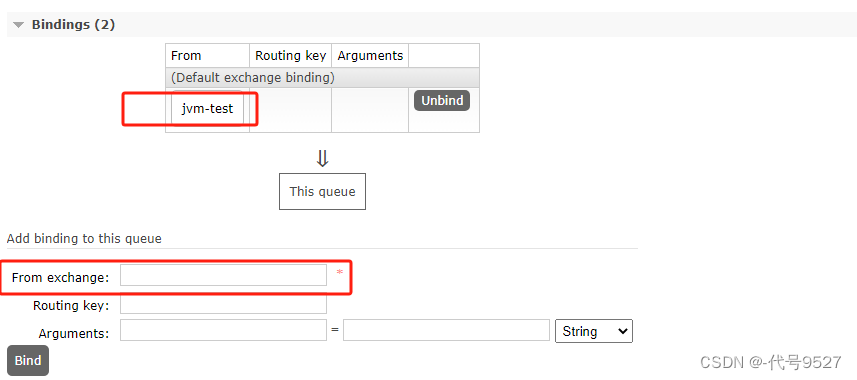
调审核接口,往队列中存,这里存对象,拿Jackson框架的ObjectMapper转json,写到队列就返回给用户提交成功的信息:
@Autowired
private RabbitTemplate rabbitTemplate;
@Autowired
private ObjectMapper objectMapper;
@PostMapping("/demo3/{id}")
public void article3(@PathVariable("id") long id, @RequestBody ArticleDto article) throws JsonProcessingException {
article.setId(id);
rabbitTemplate.convertAndSend("jvm-test",null, objectMapper.writeValueAsString(article));
}
监听队列,调阿里安全审核接口消费:
@Component
public class SpringRabbitListener {
@RabbitListener(queues = "queue1",concurrency = "10") //监听queue1队列,concurrency = "10"即启动十个线程并行处理
public void listenSimpleQueue(String msg) throws InterruptedException {
//消费
System.out.println(msg);
//用延迟模拟远程调用阿里云审核接口
Thread.sleep(30 * 1000);
}
}
启动同样配置的Jmeter脚本压测:
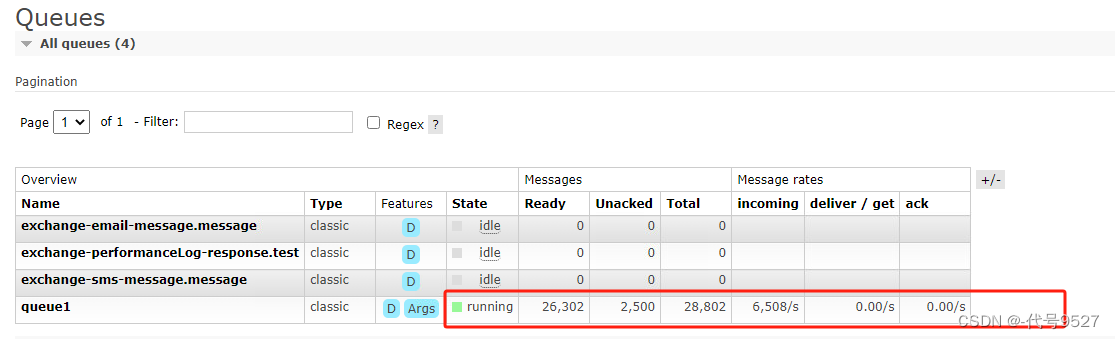
内存平稳,占用很低。(当然很低,占空间的都存MQ里了)

到此,优化完成。
4、总结
项目中要异步处理业务,或者实现生产者 – 消费者的模型,如果在Java代码中实现,那生产消费的速度、网络、远程调用的响应时间等影响,很有可能导致这些中间数据挤压,保存它们的同时占用了大量JVM堆内存,导致OOM,可使用MQ来实现。