目录
一、 前言介绍:
二 、功能设计:
三、功能实现:
系统登录实现
管理员实现
用户模块实现
四、库表设计:
五、关键代码:
六、论文参考:
七、其他案例:
八、源码获取:
一、 前言介绍:
快速发展的社会中,人们的生活水平都在提高,生活节奏也在逐渐加快。为了节省时间和提高工作效率,越来越多的人选择利用互联网进行线上打理各种事务,通过线上管理影片数据爬取与数据分析也就相继涌现。与此同时,人们开始接受方便的生活方式,他们不仅希望页面简单大方,还希望操作方便,可以快速锁定他们需要的影片数据爬取与数据分析方式。基于这种情况,我们需要这样一个界面简单大方、功能齐全的系统来解决用户问题,满足用户需求。

课题主要分为两大模块:即管理员模块和用户模块,主要功能包括系统首页、个人中心、用户管理、电影管理、系统管理等;
二 、功能设计:
影片数据爬取与数据分析分为两个部分,即管理员和用户。该系统是根据用户的实际需求开发的,贴近生活。从管理员处获得的指定账号和密码可用于进入系统和使用相关的系统应用程序。管理员拥有最大的权限,其次是用户。管理员一般负责整个系统的运行维护和总体协调。
系统结构如图所示。
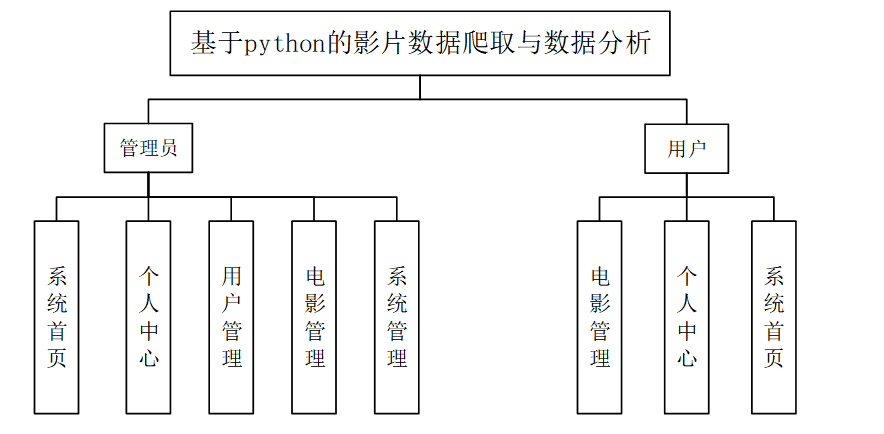
图系统结构图
三、功能实现:
系统登录实现
系统登录,在登录页面选择需要登录的角色,在正确输入用户名和密码后,进入操作系统进行操作;系统登录界面如图5-1所示:
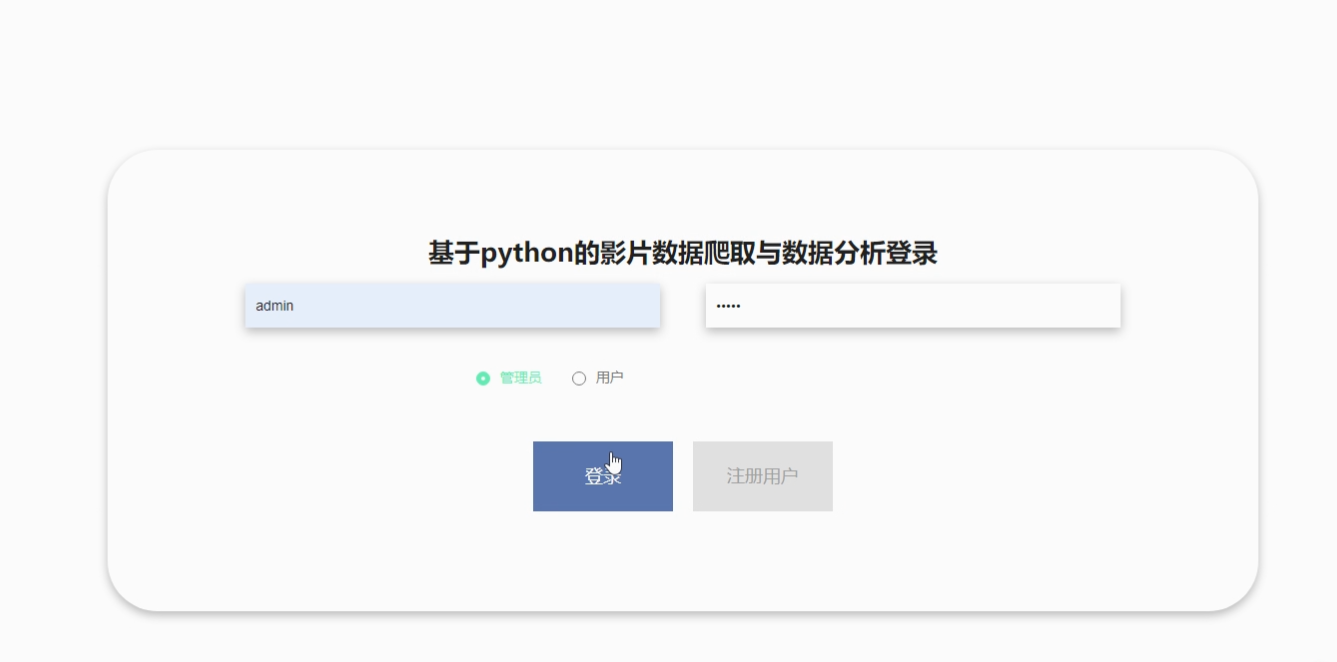
图5-1 系统登录界面
用户注册:在登录页面注册按钮,进入用户注册界面,输入用户信息点击注册进行用户注册操作,用户注册界面如图5-2所示:

图5-2 用户注册界面
管理员实现
管理员进入主页面,主要功能包括对系统首页、个人中心、用户管理、电影管理、系统管理等进行操作。管理员主界面如图5-3所示:
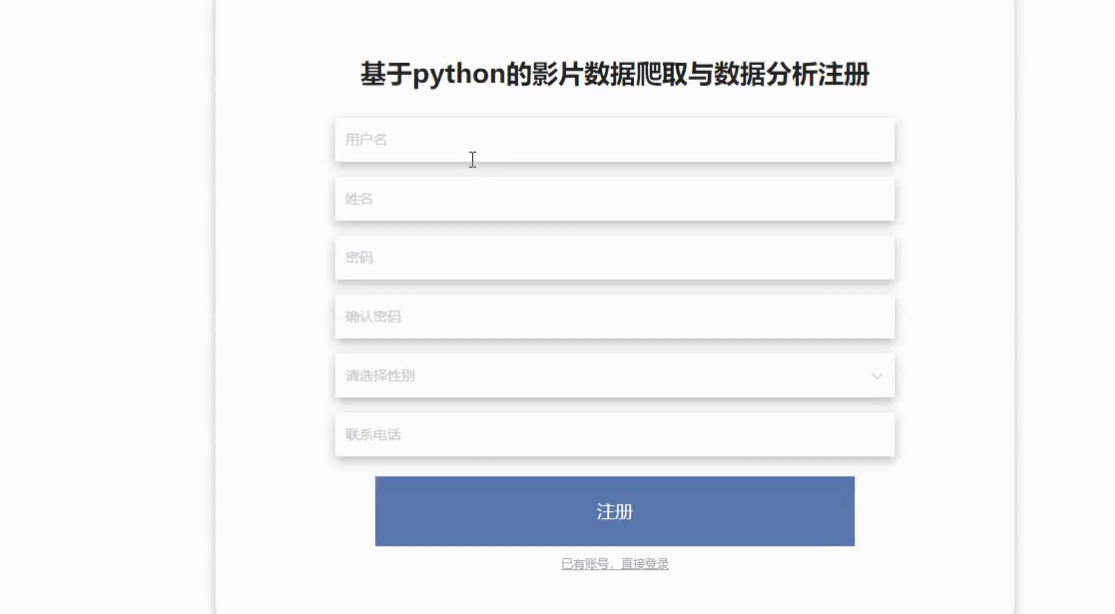
图5-3 管理员主界面
管理员点击用户管理。进入用户页面输入用户名可以查询,新增或删除用户列表,并根据需要对用户信息进行查看详情,修改或删除操作。如图5-4所示:
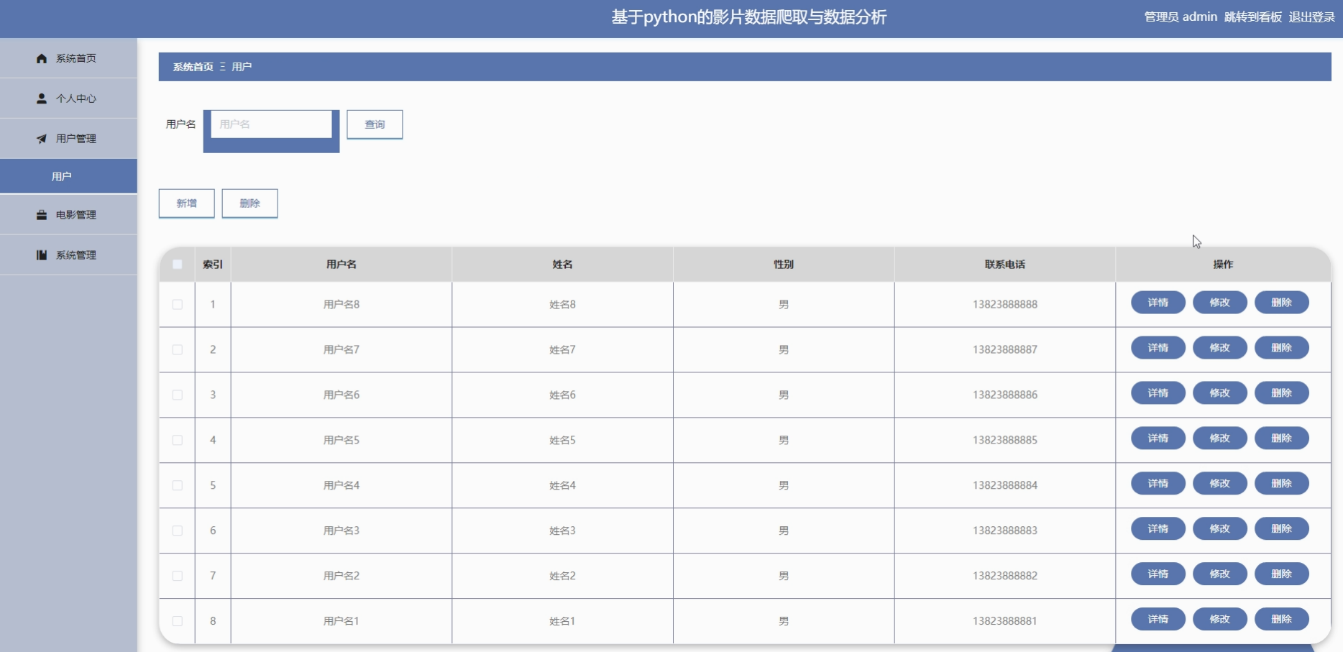
图5-4用户管理界面
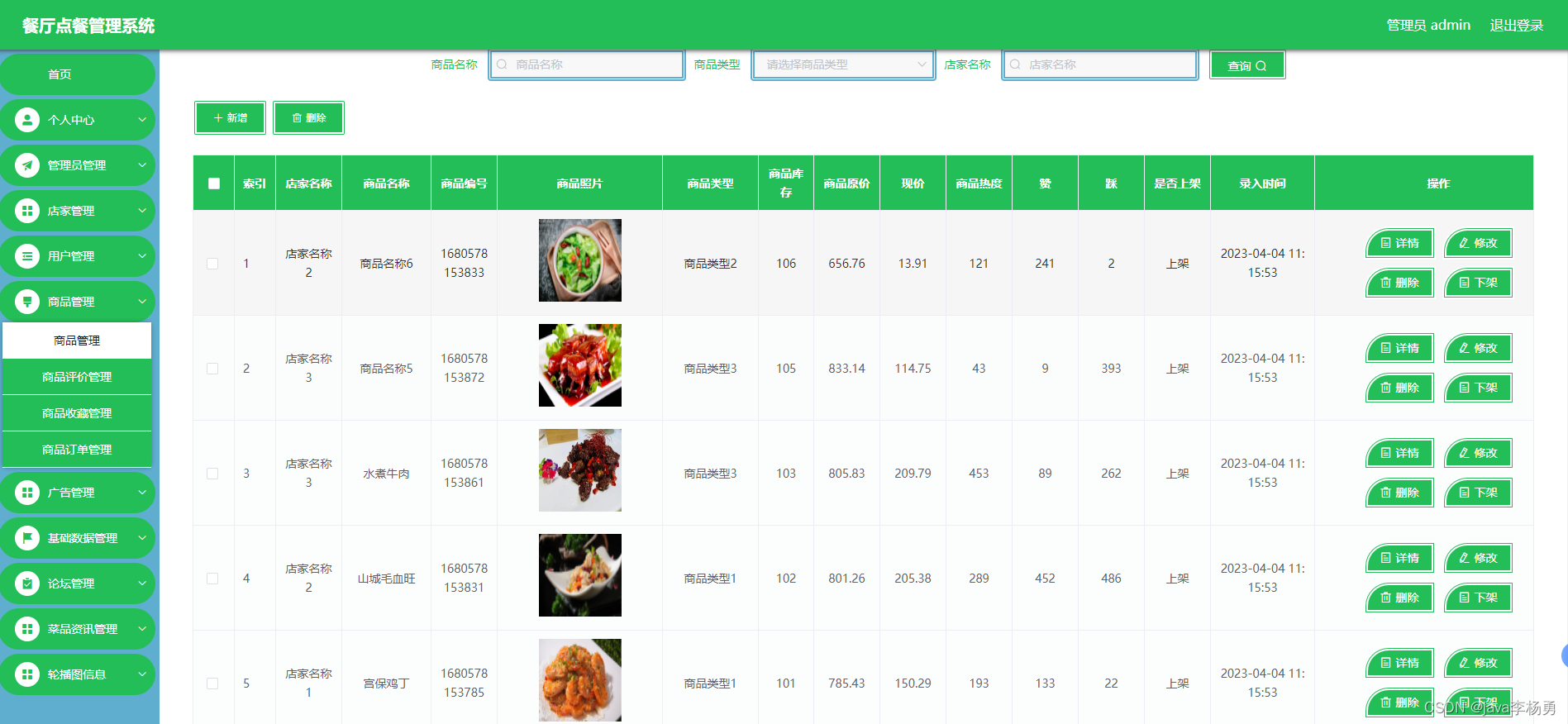
管理员点击电影管理。进入电影页面可以查询,新增,删除或爬取数据电影列表,并根据需要对电影信息进行查看详情,修改或删除操作。如图5-5所示:
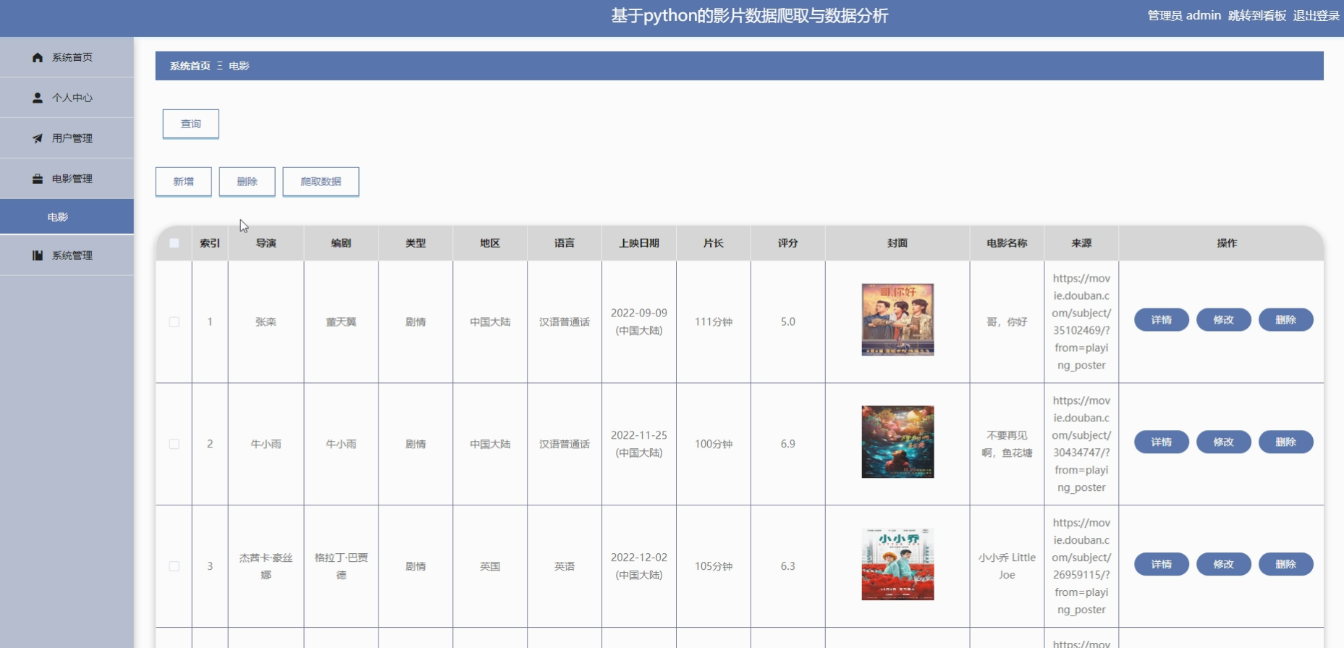
图5-5电影管理界面
管理员点击系统管理。进入系统简介页面输入标题可以查询系统简介列表,并根据需要对系统简介信息进行查看详情或修改操作。如图5-6所示:

图5-6系统管理界面
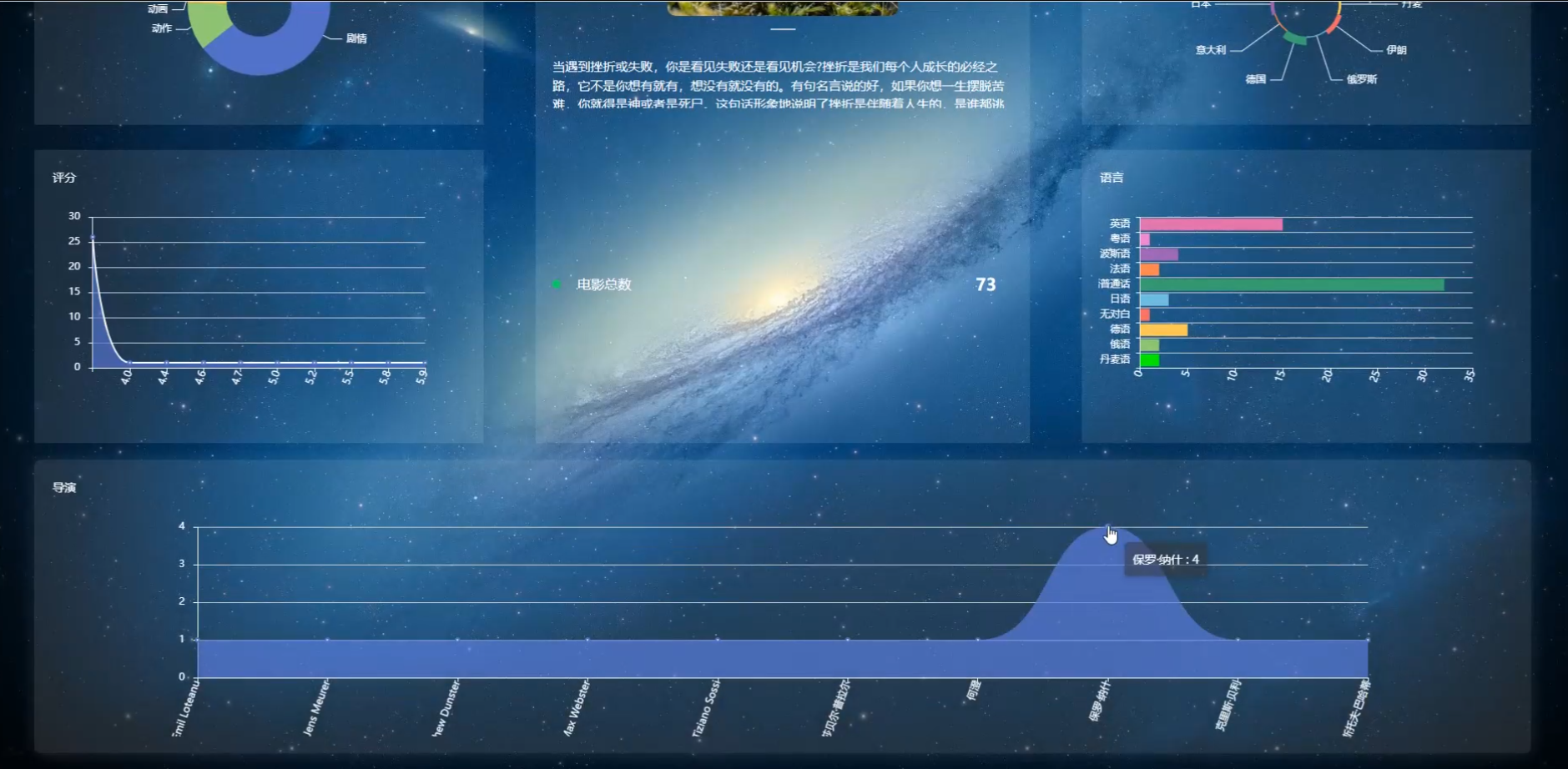
管理员点击跳转到看板。进入看板页面可以查看类型、评分、地区、语言、电影总数和导演等详细数据分析。如图5-7所示:
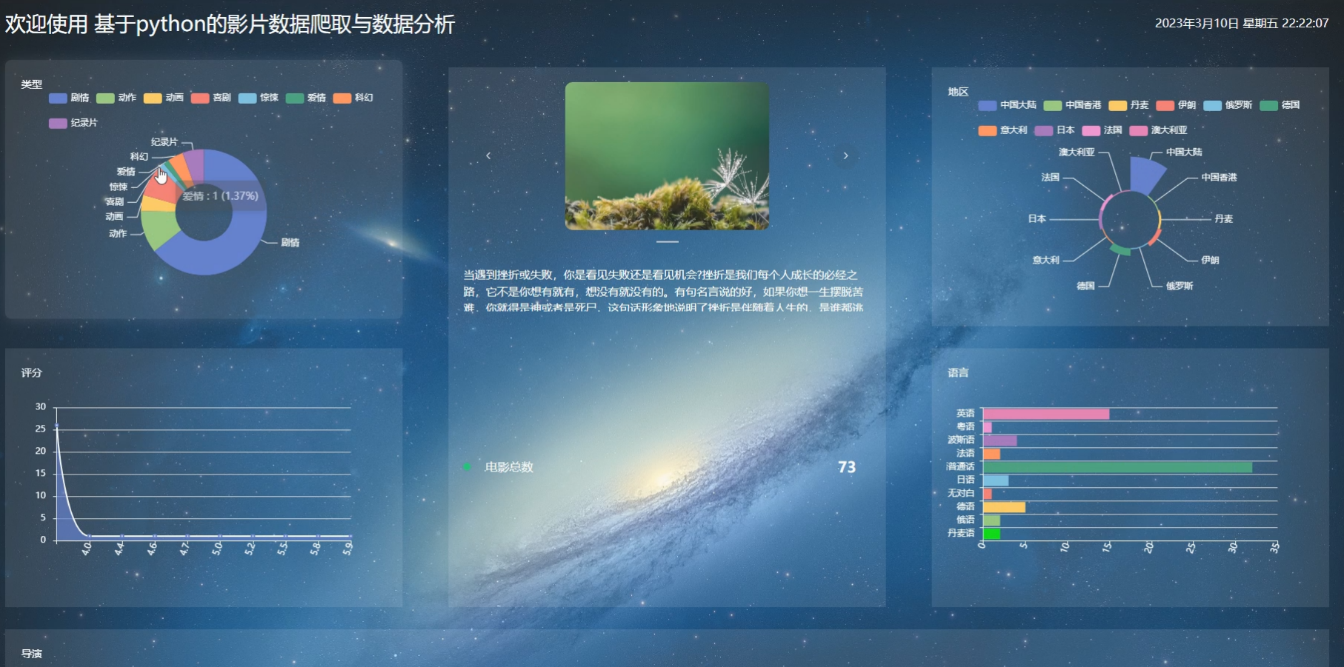
图5-7数据分析界面
用户模块实现
用户进入主页面,主要功能包括对系统首页、个人中心、电影管理等进行操作。用户主界面如图5-8所示:
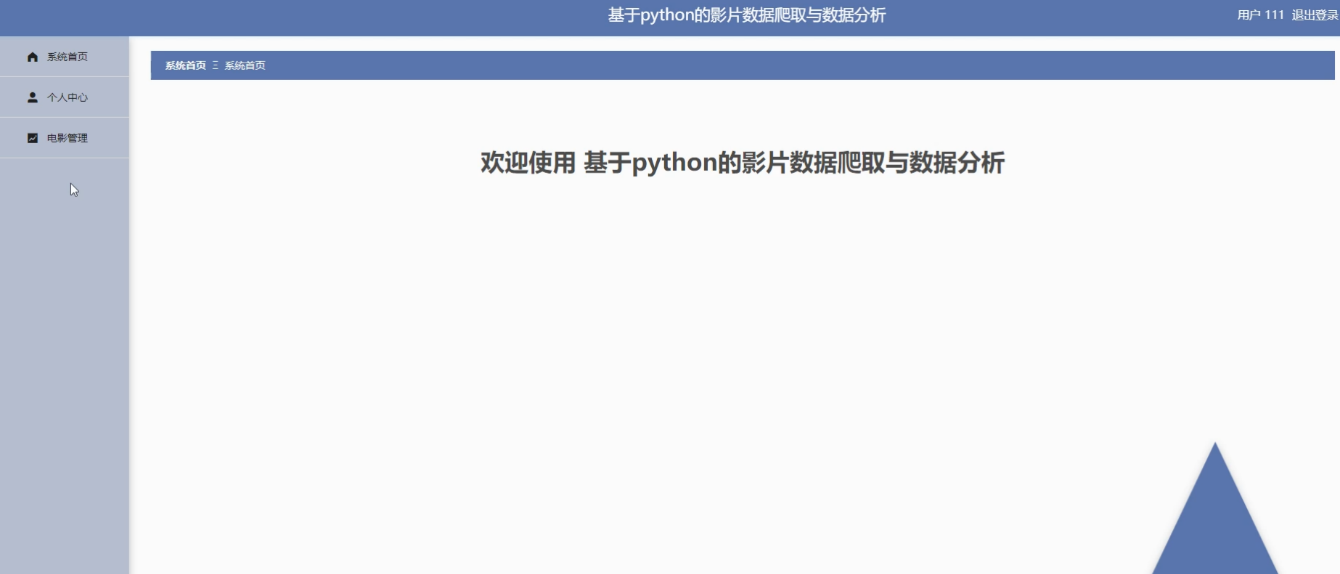
图5-8 用户主界面
用户点击电影管理。进入电影页面可以查询或爬取数据电影列表,并根据需要对电影信息进行查看详情操作。如图5-9所示:

图5-9电影管理界面
四、库表设计:
概念设计是将整体分为在地面上表达出来的单个个体。E-R图形象的连接了实体模型和概念模型。因此,E-R图需要根据数据库表和表字段进行合理设计,表达的概念知识点用图形描述,可以直观地让相应人员清楚,并分解整个E-R图[13]。我们通常表达不清晰没有概念的东西。但是通过E-R之间的联系,E-R模型法是对这种模糊概念的事务最简单、最常用的设计方法。
(1) 用户实体属性图如下图4-2所示。

图4-2用户实体属性图
(2) 电影实体属性图如下图所示。
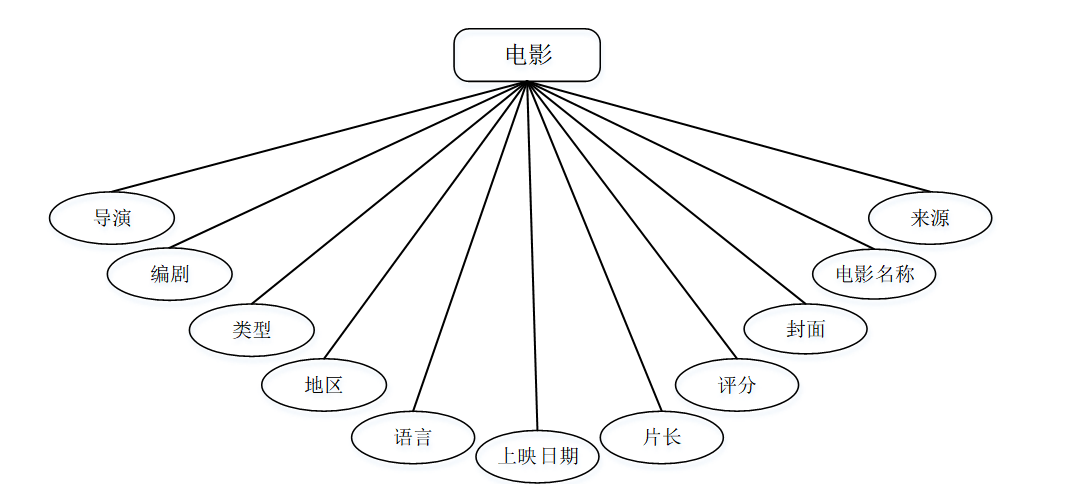
图4-3电影实体属性图
(3) 系统简介实体属性图如下图4-4所示。
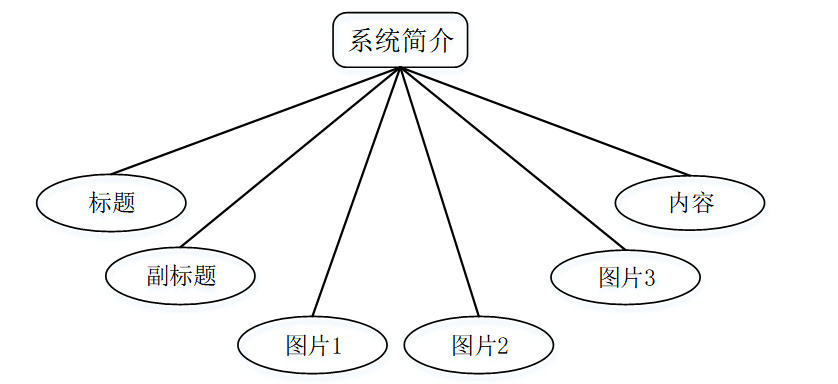
图系统简介实体属性图
五、关键代码:
# coding:utf-8
from configparser import ConfigParser
import logging, sys, os
import pymysql
from util.configread import config_read
class Create(object):
def __init__(self, dbtype, host, port, user, passwd, dbName, charset):
self.dbtype, self.host, self.port, self.user, self.passwd, self.dbName, self.charset = dbtype, host, port, user, passwd, dbName, charset
self.conn = pymysql.connect(host=self.host, user=self.user, passwd=self.passwd, port=self.port,
charset=self.charset)
self.cur = self.conn.cursor()
def create_db(self, sql):
self.cur.execute(sql)
self.conn.commit()
def create_tables(self, sqls):
use_sql = '''use `{}`;'''.format(self.dbName)
self.cur.execute(use_sql)
for sql in sqls:
self.cur.execute(sql)
self.conn.commit()
def conn_close(self):
self.cur.close()
self.conn.close()
# 管道文件
import pymysql
import pymssql
from itemadapter import ItemAdapter
class SpiderPipeline(object):
# 打开数据库
def open_spider(self, spider):
type = spider.settings.get('TYPE', 'mysql')
host = spider.settings.get('HOST', 'localhost')
port = int(spider.settings.get('PORT', 3306))
user = spider.settings.get('USER', 'root')
password = spider.settings.get('PASSWORD', '123456')
try:
database = spider.databaseName
except:
database = spider.settings.get('DATABASE', '')
if type == 'mysql':
self.connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
else:
self.connect = pymssql.connect(host=host, user=user, password=password, database=database)
self.cursor = self.connect.cursor()
# 关闭数据库
def close_spider(self, spider):
self.connect.close()
# 对数据进行处理
def process_item(self, item, spider):
self.insert_db(item, spider.name)
return item
# 插入数据
def insert_db(self, item, spiderName):
values = tuple(item.values())
# print(values)
qmarks = ', '.join(['%s'] * len(item))
cols = ', '.join(item.keys())
sql = "INSERT INTO %s (%s) VALUES (%s)" % (spiderName.replace('Spider', ''), cols, qmarks)
self.cursor.execute(sql, values)
self.connect.commit()
六、论文参考:


七、其他案例:

学习资源推荐
零基础Python学习资源介绍
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(学习教程文末领取哈)

👉Python必备开发工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉100道Python练习题👈
检查学习结果。

👉面试刷题👈

资料领取
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码输入“领取资料” 即可领取。