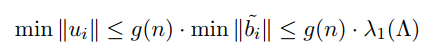文章目录
- Day1
- 1. 了解浏览器开发者工具
- 2. Get请求http://baidu.com
- 3. Post请求https://fanyi.baidu.com/sug
- 4. 肯德基小作业
- Day2
- 1. 正则表达式
- 2. 使用re模块
- 3. 爬取豆瓣电影Top250的第一页
- 4. 爬取豆瓣电影Top250所有的250部电影信息
- Day3
- 1. xpath的使用
- 2. 认识下载照片+线程池的语法
- 题外话
我所参考的学习资料,该教程位于B站并可以通过 传送门访问。
没有完全照着视频敲,所以代码和视频的有些不一样,但是大体上的思路是一样的。下面的笔记供自己复习,简单的爬虫格式还是很固定的,爬点简单的东西拷贝过来直接用就行(虽然其实是我记不住接口😭😭😭)
Day1
1. 了解浏览器开发者工具
基本介绍浏览器开发工具的各个部分
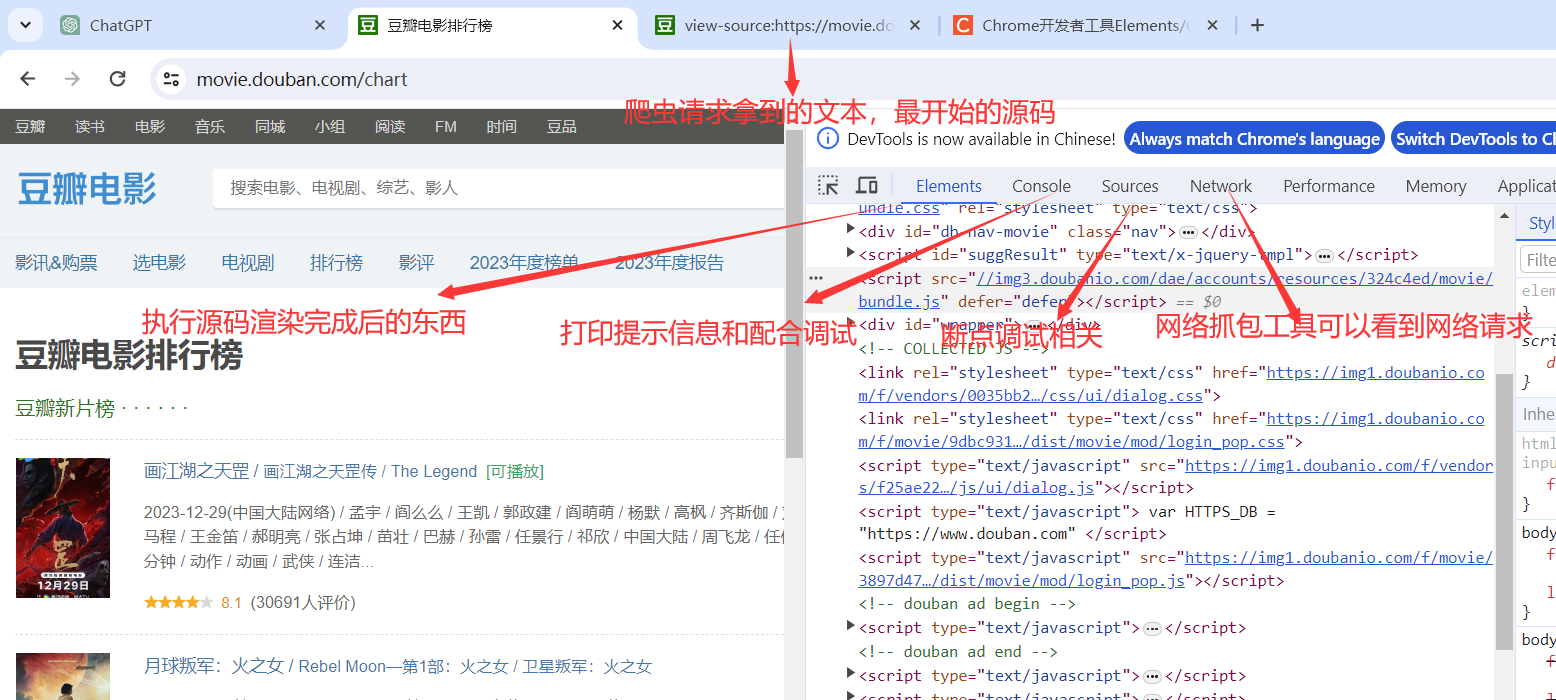
源码介绍
其余的相关字段
相对应的字段
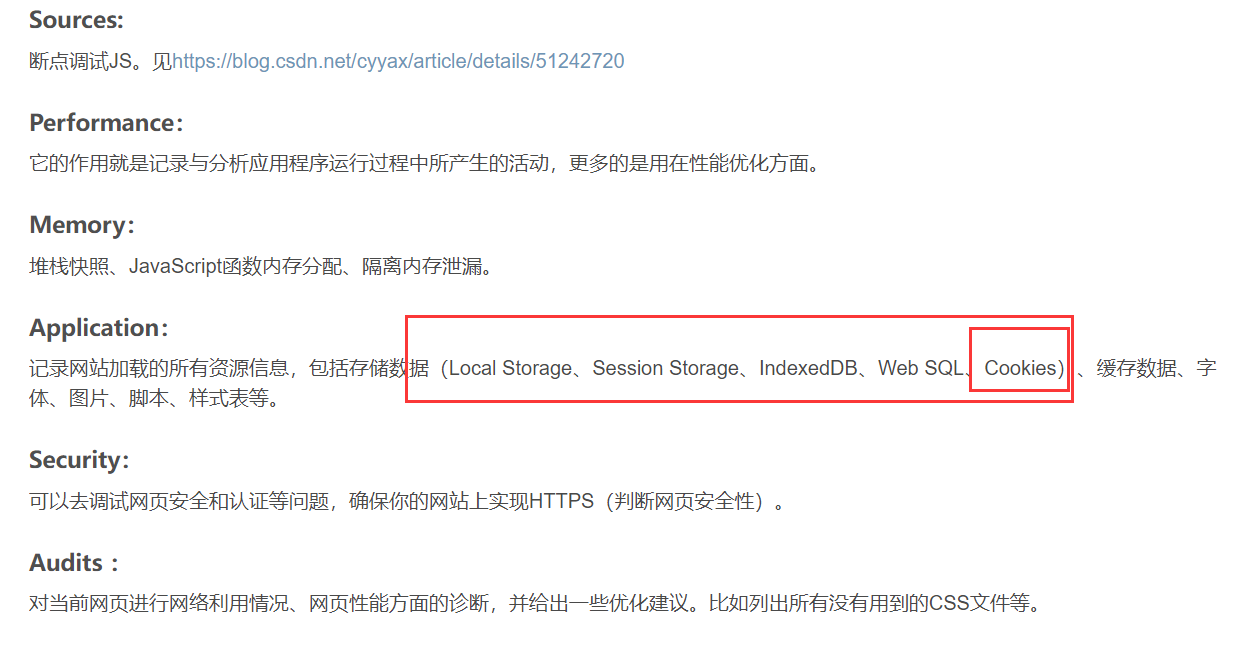
来源:https://blog.csdn.net/maidu_xbd/article/details/94062690
爬虫拿到的不是Elements,拿到的是源码
2. Get请求http://baidu.com
装requests包,请求http://baidu.com再获取响应并且写入文件
import requests
url='http://baidu.com'
resp=requests.get(url) #请求百度,记住接受返回值,类型是Response类
print(type(resp)) #检查resp的类型
# print(resp.text) #还可以打印状态码,报头等等
with open("mybaidu.html",mode="w") as f:
f.write(resp.text) #写入文件
文件内容
<html> <meta http-equiv="refresh" content="0;url=http://www.baidu.com/"> </html>
pycharm有个小图标可以直接点开,也可以自己创建一个html文件复制进去。
content=“0;url=http://www.baidu.com/”:规定了刷新的时间间隔和目标 URL。这里的 0 表示立即刷新,url=http://www.baidu.com/ 是重定向的目标 URL。所以会展示出百度的页面
3. Post请求https://fanyi.baidu.com/sug
打开百度翻译,随便输入一个单词,打开Network->XHR->找到你输入的这个单词的请求->找到请求的类型和请求的url->发现携带了数据,在写代码时记得构建数据
注意会有多个请求,你输入一个单词就会造成一个请求,比如你输入apple,会出现 a ap app appl apple这么几个请求
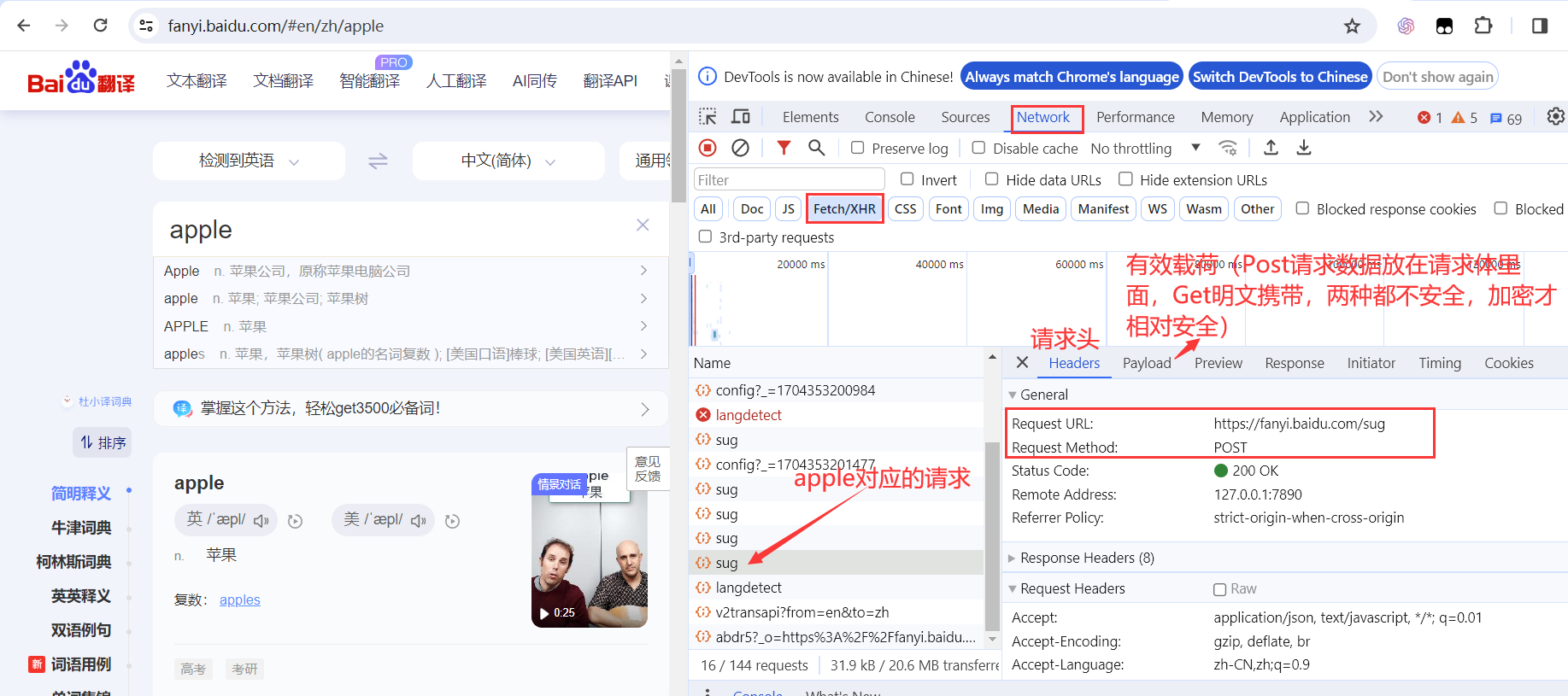
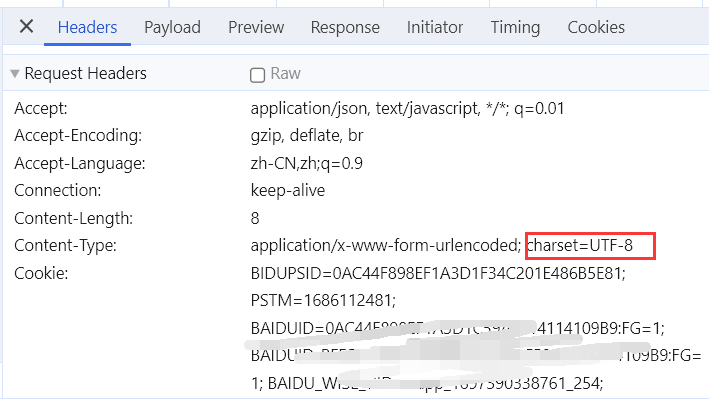
如果收到的response是乱码的,可以检查request的编码,然后修改代码在发送的请求加上对应的编码
import requests
url="https://fanyi.baidu.com/sug"
mydata={
"kw":"apple"
}
resp=requests.post(url,data=mydata)
resp.encoding="utf-8"
print(resp.status_code)
print(resp.text) #打出的字符含有\u是json的转义字符,使用json方法解析json数据返回的是一个字典
print(resp.json())
output:
200
{"errno":0,"data":[{"k":"Apple","v":"n. \u82f9\u679c\u516c\u53f8\uff0c\u539f\u79f0\u82f9\u679c\u7535\u8111\u516c\u53f8"},{"k":"apple","v":"n. \u82f9\u679c; \u82f9\u679c\u516c\u53f8; \u82f9\u679c\u6811"},{"k":"APPLE","v":"n. \u82f9\u679c"},{"k":"apples","v":"n. \u82f9\u679c\uff0c\u82f9\u679c\u6811( apple\u7684\u540d\u8bcd\u590d\u6570 ); [\u7f8e\u56fd\u53e3\u8bed]\u68d2\u7403; [\u7f8e\u56fd\u82f1\u8bed][\u4fdd\u9f84\u7403]\u574f\u7403; "},{"k":"Apples","v":"[\u5730\u540d] [\u745e\u58eb] \u963f\u666e\u52d2"}],"logid":2500940021}
{'errno': 0, 'data': [{'k': 'Apple', 'v': 'n. 苹果公司,原称苹果电脑公司'}, {'k': 'apple', 'v': 'n. 苹果; 苹果公司; 苹果树'}, {'k': 'APPLE', 'v': 'n. 苹果'}, {'k': 'apples', 'v': 'n. 苹果,苹果树( apple的名词复数 ); [美国口语]棒球; [美国英语][保龄球]坏球; '}, {'k': 'Apples', 'v': '[地名] [瑞士] 阿普勒'}], 'logid': 2500940021}
4. 肯德基小作业
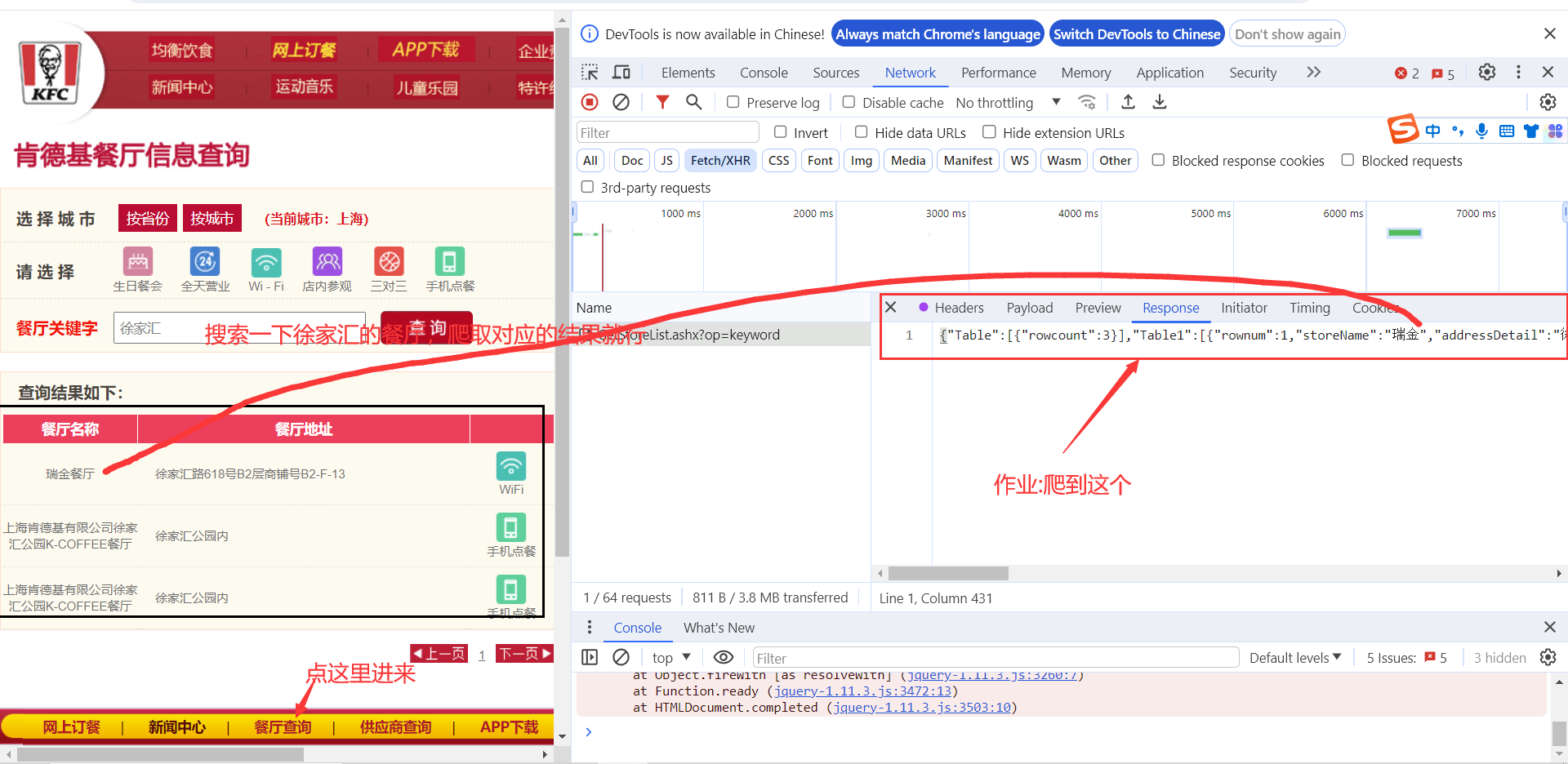
import requests
url="https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword"
mydata={
"cname":"",
"pid":"",
"keyword": "徐家汇",
"pageIndex": "1",
"pageSize": "10",
}
resp=requests.post(url,data=mydata)
print(resp.status_code)
print(resp.json())
output:
200
{'Table': [{'rowcount': 3}], 'Table1': [{'rownum': 1, 'storeName': '瑞金', 'addressDetail': '徐家汇路618号B2层商铺号B2-F-13', 'pro': 'Wi-Fi,点唱机,礼品卡,溯源', 'provinceName': '上海市', 'cityName': '上海市'}, {'rownum': 2, 'storeName': '上海肯德基有限公司徐家汇公园K-COFFEE', 'addressDetail': '徐家汇公园内', 'pro': '高铁店,手机点餐', 'provinceName': '上海市', 'cityName': '上海市'}, {'rownum': 3, 'storeName': '上海肯德基有限公司徐家汇公园K-COFFEE', 'addressDetail': '徐家汇公园内', 'pro': '高铁店,手机点餐', 'provinceName': '上海市', 'cityName': '上海市'}]}
进程已结束,退出代码0
Day2
1. 正则表达式
板书,直接搬过来了(正则不用去纠结很难的,一些简单的会写就行,严格的话比如检测用户名之类的都有现成的,比自己写得好还没啥漏洞)
![Y [ ] Y []_Y []YXU A Y P C I 5 B Q Q 67 ‘ M t m b ] ( h t t p s : / / p i c − 1304888003. c o s . a p − g u a n g z h o u . m y q c l o u d . c o m / i m g / Y AYPCI5BQQ67`M_tmb](https://pic-1304888003.cos.ap-guangzhou.myqcloud.com/img/Y AYPCI5BQQ67‘Mtmb](https://pic−1304888003.cos.ap−guangzhou.myqcloud.com/img/Y%5B%5D_Y X U XU XUAYPCI5BQQ67%60M_tmb.png)
惰性匹配与贪婪匹配(惰性匹配有就匹配一次,贪婪匹配就是能匹配多少就匹配多少)
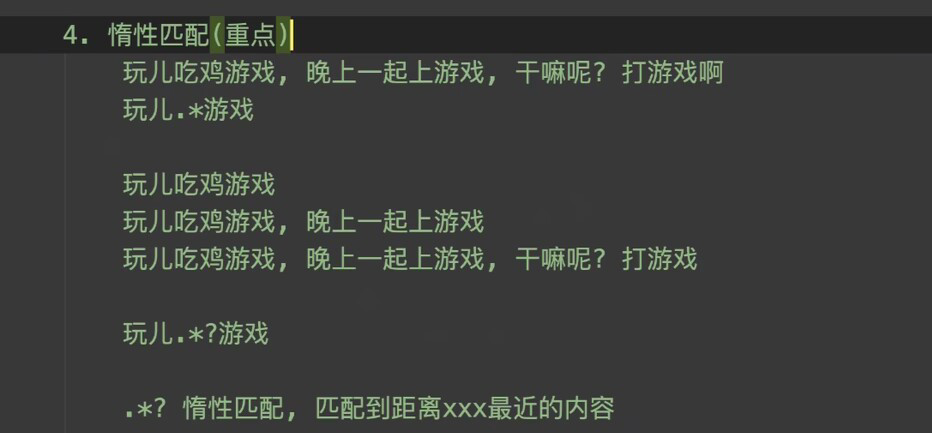
正则匹配网站:https://tool.oschina.net/regex?optionGlobl=global
手册:https://tool.oschina.net/uploads/apidocs/jquery/regexp.html
2. 使用re模块
导入re模块(内置的,不用pip)->练习findall search finditer方法
import re
print("findall")
result=re.findall(r"\d+","这是一个测试字符串,包含123和456。") #找到所有的数字,这里的r是为了避免处理转义字符,不加r字符串里的\默认转义
print(result) #返回的是一个列表
print()
print("search")
result=re.search(r"\d+","这是一个测试字符串,包含123和456。")
print(result) #Match对象
print(result.group()) #使用group分组处理
print()
print("finditer")
result=re.finditer(r"\d+","这是一个测试字符串,包含123和456。")
print(result) #迭代器对象
for item in result:
# print(item) #每个item都是Match对象,group处理
print(item.group())
print()
output
findall
['123', '456']
search
<re.Match object; span=(12, 15), match='123'>
123
finditer
<callable_iterator object at 0x0000015AF5B88C70>
123
456
进程已结束,退出代码0
finditer和findall的区别,如果大量数据处理可使用finditer节省内存,即不用一次性处理所有数据,迭代器结合循环就可以获取前一百个匹配啊之类的
使用compile预处理构造正则表达式对象,符合复用原则,也提高了代码的可读性
import re
obj=re.compile(r"\d+") #构建正则对象obj
result=obj.findall("这是一个测试字符串,包含123和456。")
print(result)
result=obj.search("这是一个测试字符串,包含123和456。")
print(result.group())
output
['123', '456']
123
进程已结束,退出代码0
使用group进行分组提取出信息
import re
s="""
<div><a href="baidu.com">我是百度</a></div>
<div><a href="google.com">我是谷歌</a></div>
<div><a href="360.com">我是360</a></div>
"""
obj=re.compile(r'<div><a href="(?P<url>.*?)">(?P<name>.*?)</a></div>') #用.*?惰性匹配,?P<url>是进行分组,组名是url
result=obj.finditer(s)
for item in result:
# print(item.groupdict()) #返回字典
url=item.group("url")
name=item.group("name")
print(url,name)
output:
baidu.com 我是百度
google.com 我是谷歌
360.com 我是360
进程已结束,退出代码0
3. 爬取豆瓣电影Top250的第一页
我们要获取电影的名字 年份 和平均得分
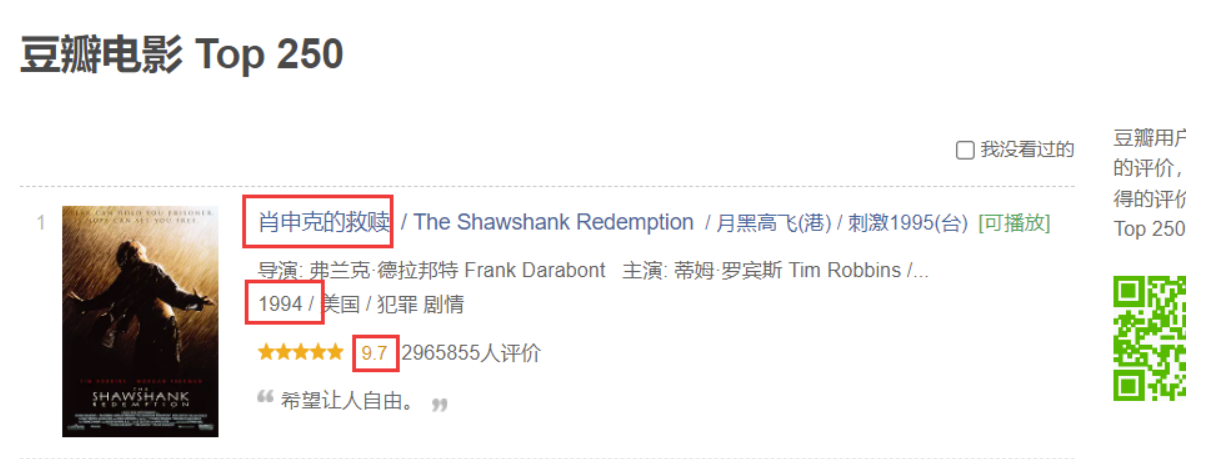
通过豆瓣电影Top250页面源码可知我们可以直接获得这些信息,所以爬取的基本流程就是获取源码->正则提取出需要的信息->分组打印即可
关键在于正则的编写
其中有一个关于反爬的机制,需要给我们的请求头部加一些特定的信息,比如
“User-Agent”:“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36”,
表示我们的请求不是由自动化程序发出的,如果不加伪装,默认情况下写的py爬虫的请求头部User-Agent的值会是
‘User-Agent’: ‘python-requests/2.28.1’
豆瓣那边发现是自动化程序发出的请求就不会给响应了(状态码也变成了418)
所以我们改一下头部信息再发过去(伪装成一个正常设备发过去的请求)
import re
import requests
url="https://movie.douban.com/top250"
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
}
resp=requests.get(url,headers=header)
resp.encoding="utf-8"
print(resp.status_code) #观察状态码是不是200
# print(resp.text)
obj=re.compile(r'<div class="item">.*?'
r'<span class="title">(?P<name>.*?)</span>.*?'
r'<br>(?P<year>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
,re.S) #.*里的.默认匹配非换行符之外的所有字符,re.S选项表示换行符也参与匹配。因为请求到的源码里有很多换行符,所以必须加这个选项
result=obj.finditer(resp.text)
for item in result:
name=item.group('name')
year=item.group('year')
year=year.split()[0] #split返回的是列表,处理一下
score=item.group('score')
print(name,year,score)
output
200
肖申克的救赎 1994 9.7
霸王别姬 1993 9.6
阿甘正传 1994 9.5
泰坦尼克号 1997 9.5
这个杀手不太冷 1994 9.4
千与千寻 2001 9.4
美丽人生 1997 9.5
星际穿越 2014 9.4
盗梦空间 2010 9.4
辛德勒的名单 1993 9.5
楚门的世界 1998 9.4
忠犬八公的故事 2009 9.4
海上钢琴师 1998 9.3
三傻大闹宝莱坞 2009 9.2
放牛班的春天 2004 9.3
机器人总动员 2008 9.3
疯狂动物城 2016 9.2
无间道 2002 9.3
控方证人 1957 9.6
大话西游之大圣娶亲 1995 9.2
熔炉 2011 9.4
教父 1972 9.3
触不可及 2011 9.3
当幸福来敲门 2006 9.2
寻梦环游记 2017 9.1
进程已结束,退出代码0
数据拿到之后怎么处理就不是爬虫关心的事情了。
4. 爬取豆瓣电影Top250所有的250部电影信息
找到分页的规律构造每一页的url,构造好url后就转换成了爬取每一页的电影信息
找url的规律(点击分页按钮,发现start后面的数字呈规律性递增)
https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=
…
import re
import requests
def GetOnePage(url:str):#传入url爬取这一页的所有电影信息
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
}
resp = requests.get(url, headers=header)
# resp=requests.get(url)
resp.encoding = "utf-8"
# print(resp.request.headers)
# print(resp.status_code)
# print(resp.text)
obj = re.compile(r'<div class="item">.*?'
r'<span class="title">(?P<name>.*?)</span>.*?'
r'<br>(?P<year>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
, re.S)
result = obj.finditer(resp.text)
for item in result:
name = item.group('name')
year = item.group('year')
year = year.split()[0]
score = item.group('score')
str=name+" "+year+" "+score+"\n" #构建表示信息的字符串
# print(str)
with open('info.txt',mode='a') as f:
f.write(str)#创建文件如何写入电影信息
# GetOnePage('https://movie.douban.com/top250') #测试函数
# https://movie.douban.com/top250?start=25&filter=
for i in range(0,10): #循环构造url
page=i*25
url=f"https://movie.douban.com/top250?start={page}&filter=" #f-string便于插入值,r-string取消转义,利用f-str构造url
GetOnePage(url)
output:
写到了文件里面
Day3
1. xpath的使用
语法文档:https://docs.python.org/zh-cn/3/library/xml.etree.elementtree.html?highlight=xpath#elementtree-parsing-xml
熟悉xpath相关的一些语法
import requests
from lxml import etree
url='http://www.baidu.com/' #这里没加请求头,baidu有反爬机制,加了请求头和不加得到的数据是不同的
#myhead={
# "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
#}
resp=requests.get(url)
resp.encoding='utf-8'
# print(resp.text) #打印响应的数据
et=etree.HTML(resp.text)
print(et) #印证确实是Element html对象
result=et.xpath("/html/head/title/text()") #逐层往下找,text()表示标签之间的文本,如<p>123</p>
print(result)
result=et.xpath("/html/head/link/@href") #匹配link标签的href属性
print(result)
print()
keys=et.xpath("//div[@id='u1']/a/text()") #//div表示匹配HTML里所有的div,div[@id='u1']选择特定属性的div
# print(keys)
values=et.xpath("//div[@id='u1']/a/@href")
# print(values)
result=dict(zip(keys,values))
for item in result.items(): #一一对应输出
print(item)
output:
<Element html at 0x294a32b1000>
['百度一下,你就知道']
['http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css']
('新闻', 'http://news.baidu.com')
('hao123', 'http://www.hao123.com')
('地图', 'http://map.baidu.com')
('视频', 'http://v.baidu.com')
('贴吧', 'http://tieba.baidu.com')
('更多产品', '//www.baidu.com/more/')
进程已结束,退出代码0
2. 认识下载照片+线程池的语法
下载图片
import requests
url='https://images.pexels.com/photos/2950499/pexels-photo-2950499.jpeg' #网上随便找了一张图片
resp=requests.get(url)
print(resp.status_code) #看一下请求是否成功
#写入图片得使用content,返回的是二进制数据,所以得使用wb打开而不是w。不能使用text,text返回的是文本数据
with open('test.jpg',mode='wb') as f:
f.write(resp.content)
output:
运行成功后当前目录下多出一张test.jpg的图片
线程池
导包->创建线程池->确定线程池里最大线程的数量,提交任务
记得提交的任务要封装成一个函数
#导包,名字还挺长
from concurrent.futures import ThreadPoolExecutor
def func():
for i in range(0,10):
print(f"子线程{i}")
def main():
with ThreadPoolExecutor(max_workers=10) as executor: #线程池同时最多执行十个线程
executor.submit(func) #提交任务,func而不是func(),如果是func()会立即执行而不会放在线程池中跑
for i in range(0, 10): #交替打印
print(f"主线程{i}")
# for i in range(0, 10): #线程池的任务完成了才会运行到这
# print(f"主线程{i}")
if __name__ == '__main__':
main()
output:
可以明显看到交替打印的现象
子线程0主线程0
主线程1
主线程2子线程1
子线程2主线程3
主线程4
子线程3
主线程5子线程4
主线程6
主线程7子线程5
子线程6
主线程8
子线程7
主线程9
子线程8
子线程9
进程已结束,退出代码0
我没有做视频里的项目,但是我自己做了别的网站的,实现的效果差不多就是构建图库。
题外话
上面有错误的话敬请大佬斧正。
request.get的使用和加请求头之类的这些知识只是入门的,真正的爬虫和逆向紧密相关,所以会使用request.get不表示会爬虫🤡,要精通爬虫与多个方向都相关,比如加密算法,js逆向等,是一个很大的板块。但是学会上面的东西爬一些简单的不设防的网站没啥问题,比如构建自己的壁纸图库等。其实去年五月份就爬了ttok,按博主分类爬了几千个视频,但是调用别人的API终究不是自己写的,前两天想再运行的时候发现代码文件命名混乱和没写注释使得完全跑不了了,蚌。包括爬一些数据加密过的网站都是有难度的。