背景知识
深度学习涉及大量矩阵运算,而矩阵运算可以并行计算。

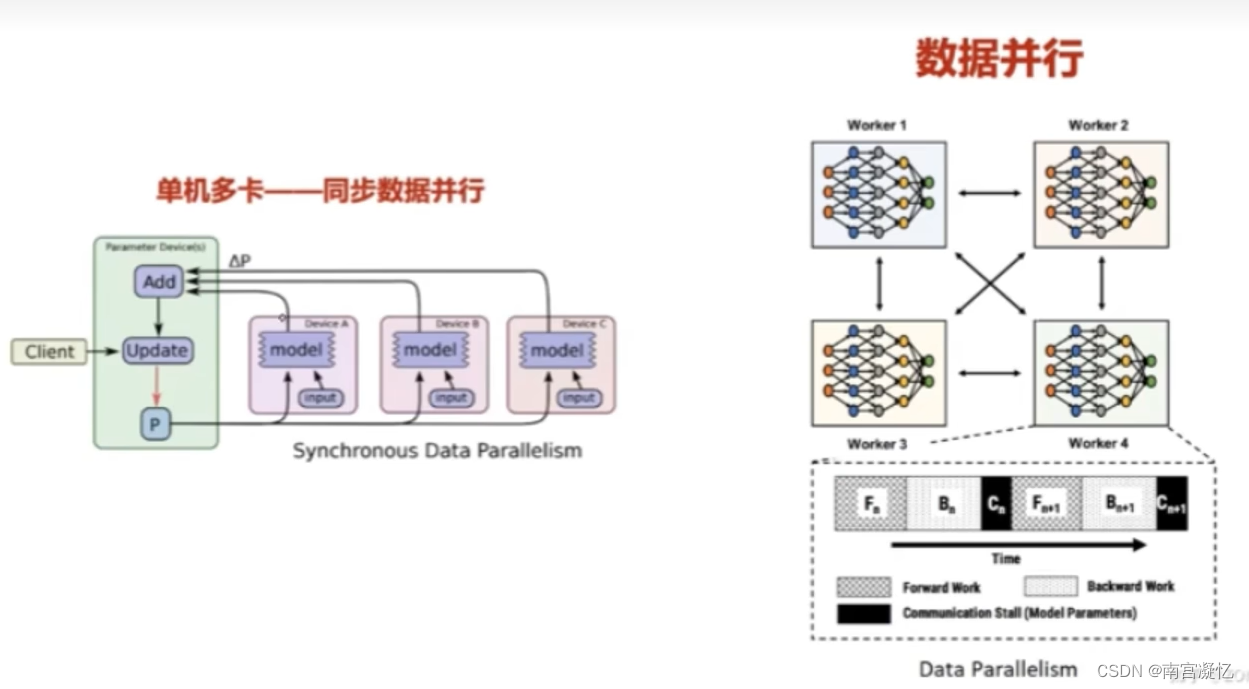
一、数据并行
每张卡加载不同的数据,将计算结果合并
存在问题:每个显卡都加载了模型,浪费了一定空间
二、模型并行:适合模型特别大的情况
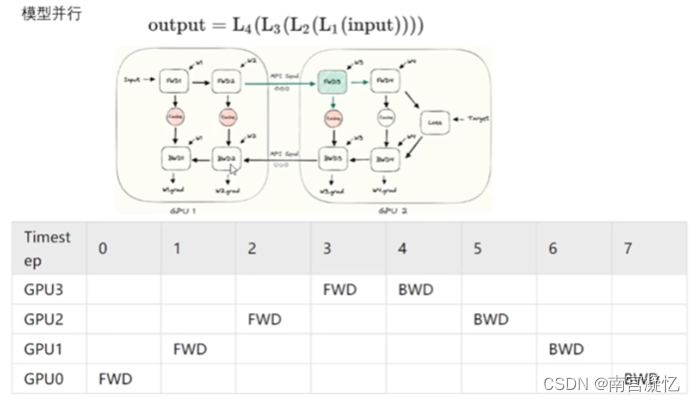
1、串行计算
先用卡1计算结果1,然后卡2计算结果2,……卡n计算结果n,然后计算损失反向传播
串行计算,不是为了提速,而是为了解决模型一张卡放不下的问题
存在问题:gpu大量空闲
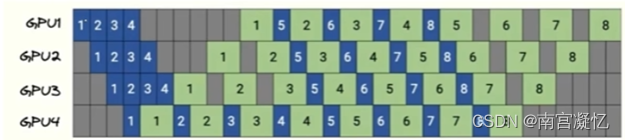
2、并行计算
batchsize=80,分成4个20
类似操作系统学的并行处理
存在问题:80个全部计算完,才反向传播
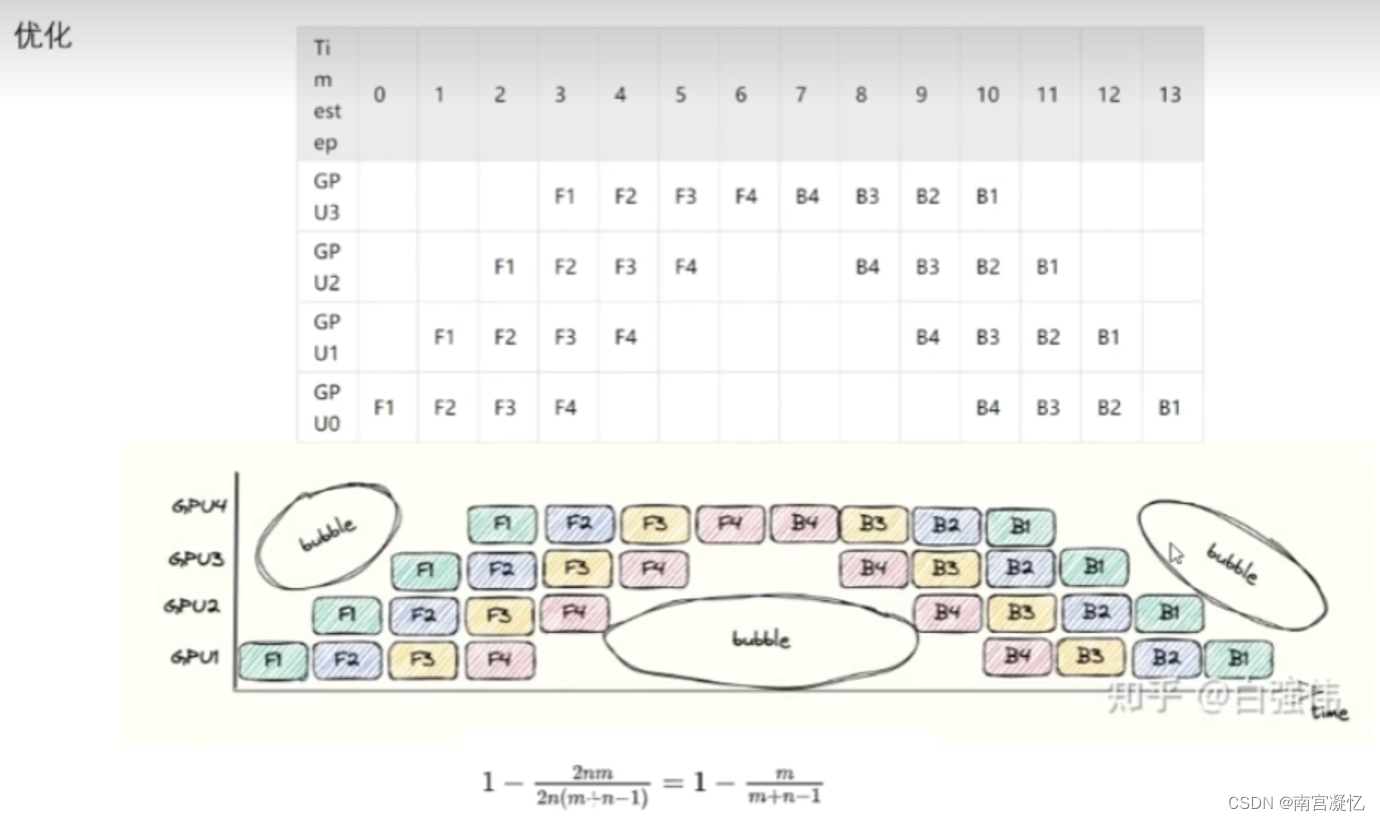 3、进一步优化
3、进一步优化
算完前向计算,直接反向传播,不等别人,gpu利用率进一步提高
绿色块为更新后的参数
存在问题:每一块gpu用的参数都不一样,参数不是同时更新的,模型层与层之间的参数不配套。
GPU优化:时间换空间或空间换时间
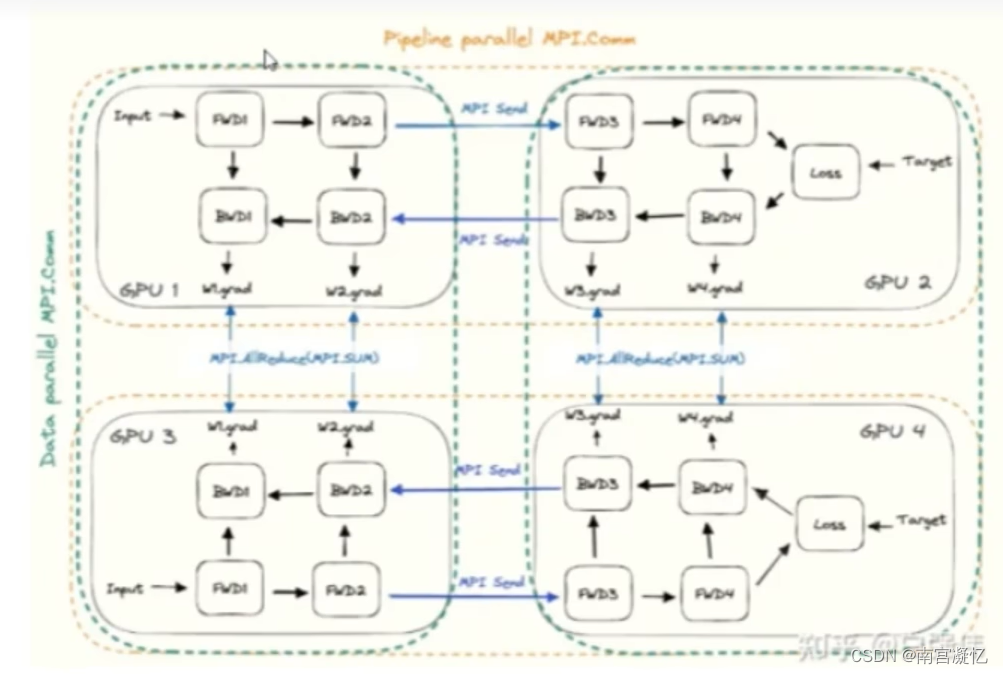
三、数据并行&模型并行
GPU1&GPU2、GPU3&GPU4:模型并行(难点:合理地切割模型)
GPU1&GPU3、GPU2&GPU4:数据并行
四、张量并行
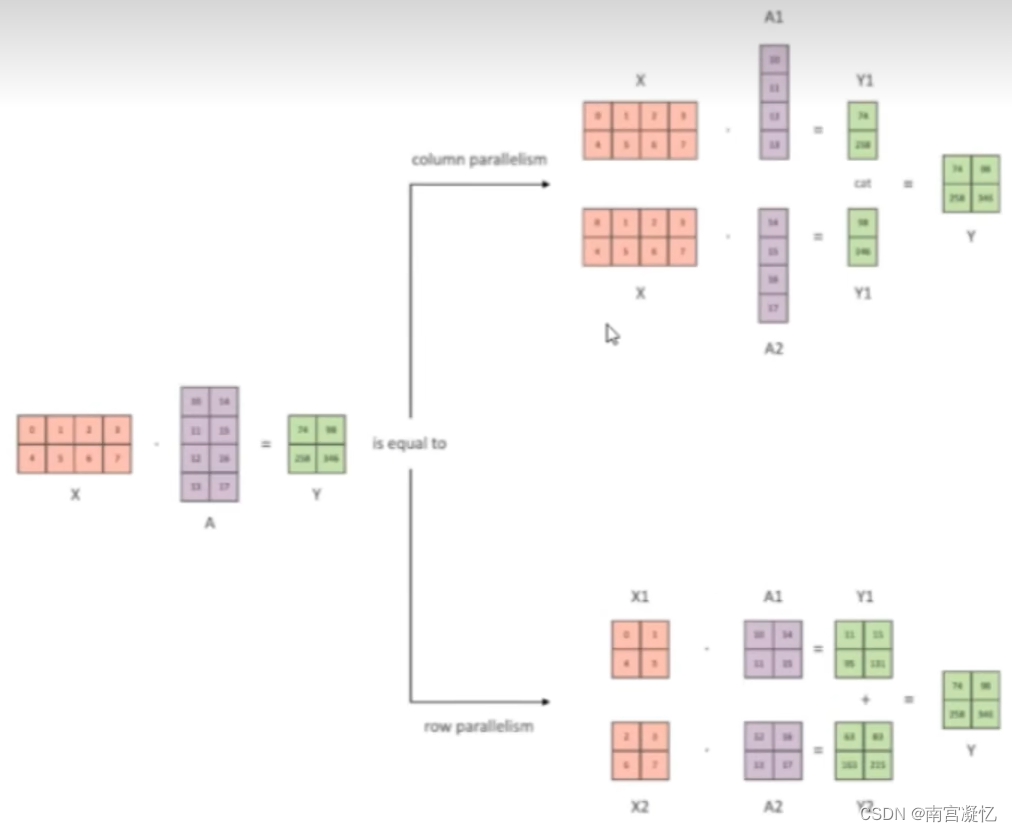
1、一个完整,另一个按行或列并行
两张卡都保存x,卡1保存A列1,卡2保存A列2,分别计算然后拼接结果
支持激活函数的并行(因此常用)

2、对两个矩阵合理拆解
x和A都拆成两个模块,分别在卡1和卡2中计算,然后将结果相加
不支持激活函数的并行(因此不常用)
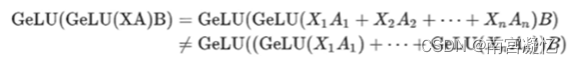
3、其它拆法
优点:Gpu1和Gpu2没有重复数据,节约内存

五、多头注意力机制
大模型的核心:Transformer
Transformer的核心:多头注意力机制
多头注意力机制天然就适合并行计算
X1和X2的计算互不干扰
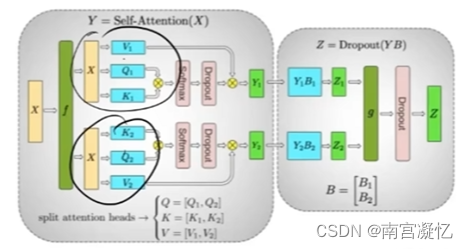
LSTM、RNN下一时刻的输出需要依赖上一时刻,无法做到并行,导致GPU闲置率太大。其效果不如注意力,同时与硬件也不匹配,因此失去研究前景。
GPT、T5、Bart、Bert都是基于注意力做的。
六、两台机器如何配合并行训练