1、简介
Power-Job 的设计目标是成为企业级的分布式任务调度平台,整个公司统一部署调度中心 power-job-server,旗下所有业务线应用只需要依赖 power-job-worker 即可接入调度中心获取任务调度与分布式计算能力。

Power-job官方网址:http://www.powerjob.tech/
1.1、同类相比
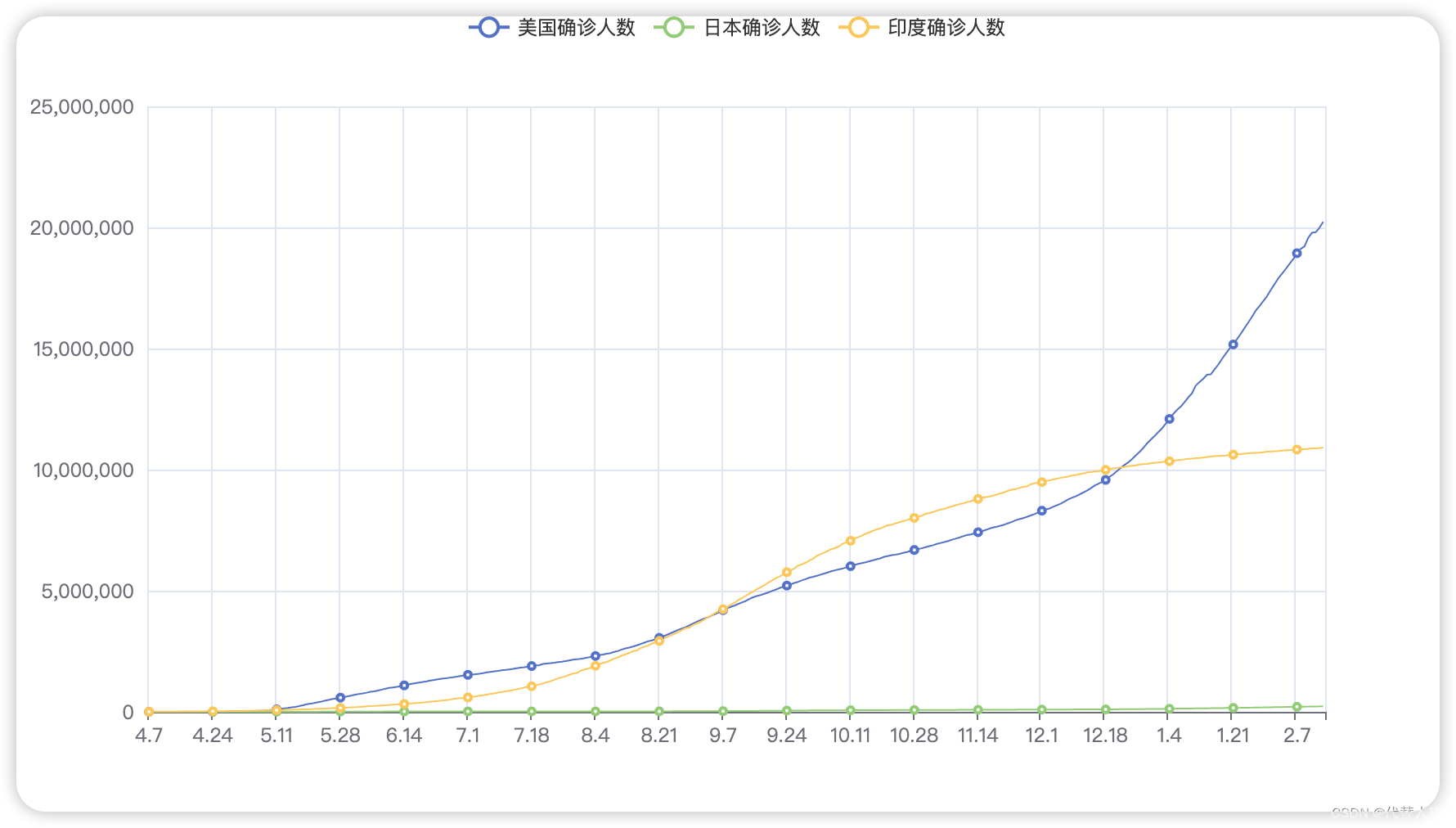
当前市面上流行的任务调度框架有:xxl-job、QuartZ以及Power-job。
主要功能相比较如下:
| xxl-job | QuartZ | Power-job | |
|---|---|---|---|
| 定时类型 | CRON | CRON | CRON、固定频率、固定延迟、OpenAPI |
| 任务类型 | 内置Java 内置Java、GLUE Java、Shell、Python等脚本 | 内置Java | 内置Java、外置Java(容器)、Shell、Python等脚本 |
| 分布式任务 | 静态分片 | 无 | MapReduce 动态分片 |
| 在线任务治理 | 支持 | 不支持 | 支持 |
| 调度方式及性能 | 基于数据库锁,有性能瓶颈 | 基于数据库锁,有性能瓶颈 | 无锁化设计(CAS),性能强劲无上限 |
| 报警监控 | 邮件 | 无 | 邮件,提供接口允许开发者扩展 |
综上观察,Power-job在一定的程度上是优于xxl-job的,但是具体的应用还得看具体的需求,如果只是一些简单的需求,使用xxl-job或者QuartZ都是可以的。
在学习路线上可以从QuartZ -> xxl-job -> Power-job,由简入难。
1.2、Power-job架构

从架构图中大致可以了解到系统分为三个模块:
- 调度中心 power-job-server:PowerJob的设计目标为企业级的分布式任务调度平台,即成为调度中间件,让任意业务线的应用仅需要依赖 powerjob-worker 即可获取任务调度与分布式计算的能力。因此,PowerJob 的理想部署模式为一个公司统一部署 powerjob-server 集群,各业务线应用直接接入使用。
- 执行器 power-job-worker:根据以前对定时任务的理解,用过Quartz的话,这里相当于Job这个接口;用过ElasticJob的话,最起码相当于Job接口中的一种,比如SimpleJob接口;用过xxl-job的话,这里也是同理,相当于使用了注解@XxlJob的方法。
- Akka ActorSystem:基于Actor模型设计的,专用于构建高度并发、分布式和弹性的工具包,号称单台机器上高达 200 亿条消息/秒。从架构图来看,PowerJob用来做数据交换传输,需要单独占据一个端口。
1.3、启动Powerjob-server
(1)因为Power-Job是开源的项目并且在Docker中暂时还无法找到,所以需要我们先下载源码,下载地址可以是Github或者Gitee:
Power-job下载连接:https://gitee.com/KFCFans/PowerJob?_from=gitee_search
(2)导入开发工具并配置数据库
配置数据库需要修改powerjob-server模块下powerjob-server-starter子模块的application-daily.properties配置文件中的数据库信息:
####### Database properties(Configure according to the the environment) #######
spring.datasource.core.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.core.jdbc-url=jdbc:mysql://localhost:3306/powerjob-daily?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
spring.datasource.core.username=root
spring.datasource.core.password=123456
spring.datasource.core.maximum-pool-size=20
spring.datasource.core.minimum-idle=5
####### Storage properties(Delete if not needed) #######
#oms.storage.dfs.mongodb.uri=mongodb+srv://zqq:No1Bug2Please3!@cluster0.wie54.gcp.mongodb.net/powerjob_daily?retryWrites=true&w=majority
oms.storage.dfs.mysql_series.driver=com.mysql.cj.jdbc.Driver
oms.storage.dfs.mysql_series.url=jdbc:mysql://localhost:3306/powerjob-daily?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
oms.storage.dfs.mysql_series.username=root
oms.storage.dfs.mysql_series.password=123456
oms.storage.dfs.mysql_series.auto_create_table=true
其次再在数据库中将powerjob-daily数据库创建好,启动powerjob-server-starter模块,Power-Job底层是基于JPA,系统会自动创建所需要的表。
启动项目:

在使用PowerJob时,无论是调度中心还是执行器,控制台都会不断的有日志输入,如果不想有日志,可以在配置文件中使用logging.level.root=off来关闭日志输出。
系统自动创建表:

访问前端:
在浏览器中输入http://localhost:7700就可以进入Power-job的前端页面。
2、Power-job Worker执行器
在使用XXL-JOB的时候,我们会使用@XxlJob注解来从侧面进行任务的执行,一个类中可以存在多个@XxlJob注解,也就是会存在多个需要执行的任务。
但是在Power-Job中,如果不使用@PowerJobHandler注解的话,就需要执行任务的类去实现BasicProcessor处理策略接口,接口内部有一个任务执行的方法process。
public interface BasicProcessor {
/**
* 核心处理逻辑
* 可通过 {@link TaskContext#getWorkflowContext()} 方法获取工作流上下文
*
* @param context 任务上下文,可通过 jobParams 和 instanceParams 分别获取控制台参数和OpenAPI传递的任务实例参数
* @return 处理结果,msg有长度限制,超长会被裁剪,不允许返回 null
* @throws Exception 异常,允许抛出异常,但不推荐,最好由业务开发者自己处理
*/
ProcessResult process(TaskContext context) throws Exception;
}
通过BasicProcessor接口衍生出了另外几中类型的任务处理策略:
- BroadcastProcessor 广播处理器:广播执行的策略下,所有机器都会被调度执行该任务。为了便于资源的准备和释放,广播处理器在BasicProcessor 的基础上额外增加了 preProcess 和 postProcess 方法,分别在整个集群开始之前/结束之后选一台机器执行相关方法。
- MapReduceProcessor 并行处理器:MapReduce 是最复杂也是最强大的一种执行器,它允许开发者完成任务的拆分,将子任务派发到集群中其他Worker 执行,是执行大批量处理任务的首选。
- MapProcessor Map处理器:对应了Map任务,即某个任务在运行过程中,允许产生子任务并分发到其他机器进行运算。
BasicProcessor默认是单机策略处理器,单机执行的策略下,server 会在所有可用 worker 中选取健康度最佳的机器进行执行。
TaskContext类的基本属性:
| 属性名称 | 描述 |
|---|---|
| jobId | 任务 ID,开发者一般无需关心此参数 |
| instanceId | 任务实例 ID,全局唯一,开发者一般无需关心此参数 |
| subInstanceId | 子任务实例 ID,秒级任务使用,开发者一般无需关心此参数 |
| taskId | 采用链式命名法的 ID,在某个任务实例内唯一,开发者一般无需关心此参数 |
| taskName | task 名称,Map/MapReduce 任务的子任务的值为开发者指定,否则为系统默认值,开发者一般无需关心此参数 |
| jobParams | 任务参数对于非工作流中的任务其值等同于控制台录入的任务参数; 如果该任务为工作流中的任务且有配置节点参数信息,那么接收到的是节点配置的参数信息 |
| instanceParams | 任务实例参数对于非工作流中的任务 其值 等同于 OpenAPI 传递的实例参数,非 OpenAPI 触发的任务则一定为空。 如果该任务为工作流中的任务那么这里实际接收到的是工作流上下文信息,建议使用 getWorkflowContext 方法获取上下文信息 |
| maxRetryTimes | Task 的最大重试次数 |
| currentRetryTimes | Task 的当前重试次数,和 maxRetryTimes 联合起来可以判断当前是否为该 Task 的最后一次运行机会 |
| subTask | 子 Task,Map/MapReduce 处理器专属,开发者调用map方法时传递的子任务列表中的某一个 |
| omsLogger | 在线日志,用法同 Slf4J,记录的日志可以直接通过控制台查看,非常便捷和强大!不过使用过程中需要注意频率,滥用在线日志会对 Server 造成巨大的压力 |
| userContext | 用户在 PowerJobWorkerConfig 中设置的自定义上下文 |
| workflowContext | 工作流WorkflowContext对象 |
2.1、Cron表达式
cron表达式是一种用于指定任务在某个时间点或周期性执行的字符串表达式。它包含6个或7个域,每个域代表不同的含义,从左到右依次为"秒 分 时 日 月 星期 年",其中年不是必须的; cron表达式的配置简洁方便,因此在定时调度任务中被广泛使用;
秒(0-59)
分钟(0-59)
小时(0-23)
日(1-31)
月(1-12 或 JAN-DEC)
星期(0-6 或 SUN-SAT)
年(可选,1970-2099)
2.1.1、特殊符号
| 符号 | 含义 |
|---|---|
| * | 通配符,匹配任意值,例如* * * * * ?表示每秒执行一次任务。 |
| , | 列表,用于指定多个取值,例如0 0 6,12,18 * * ?表示每天6点、12点和18点执行任务。 |
| - | 范围,用于指定一个范围内的取值,例如0 0 9-17 * * MON-FRI表示周一至周五的9点到17点之间每小时执行一次任务。 |
| / | 步长,用于指定一个取值的步长,例如0 */30 * * * ?表示每30分钟执行一次任务。 |
| ? | 无意义占位符,用于指定一个字段没有具体的取值,只能与其他字段一起使用,例如0 0 12 ? * MON-FRI表示周一至周五中午12点执行任务。 |
| # | 日历偏移量,用于指定某个月份的第几个周几,例如0 0 0 ? * 3#1表示每个月的第一个星期三执行任务。 |
| L | Last,表示某个指定时间内的最后一天,比如0 0 L * * ?表示每月的最后一天执行任务。 |
| W | Weekday,表示距离指定日期最近的工作日,比如0 0 0 15W * ?表示当月第15个工作日执行任务。如果15号是工作日,则执行任务;如果15号是周末,则任务会提前到最近的工作日即14号执行。 |
| C | Calendar,表示距离指定日期最近的那个日子,比如0 0 0 1W * ?表示当月的第一个工作日执行任务。如果1号是工作日,则执行任务;如果1号是周末,则任务会延后到最近的工作日即2号执行。 |
L只能用在实际单位的前一个单位,比如每月的最后一天,L只能用在日单位上。
W和C的区别在于W只能用在日字段上,表示距离指定日期最近的工作日; 而C可以用在月、日、星期字段上,表示距离指定日期最近的那个日子。
2.1.2、举例
| 案例代码 | 含义 |
|---|---|
| 0 0 8 * * * | 表示每天上午8点执行任务。 |
| 0 0/30 9-17 * * * | 表示在每天9点到17点之间,每隔30分钟执行一次任务。 |
| 0 0 3-5 * * * | 表示每天凌晨3点到5点之间,每小时执行一次任务。 |
| 0 0 12 ? * WED | 表示每周三中午12点执行任务。 |
| 0 0 10 L * ? | 表示每个月的最后一天上午10点执行任务。 |
| 0 15 10 L * ? | 表示每个月的最后一天上午10:15分执行任务。 |
在使用分布式调度框架时,Cron表达式是必须要会的,这是使用前提,Power-job不会像xxl-job一样会提供选择,所以对Cron的使用就会比xxl-job难度要高。
2.2、官方案例
在下载的Power-job源码中,官方给出了一个对框架简单使用的案例。
2.2.1、项目结构

├── LICENSE
├── powerjob-client // powerjob-client,普通Jar包,提供 OpenAPI
├── powerjob-common // 各组件的公共依赖,开发者无需感知
├── powerjob-remote // 内部通讯层框架,开发者无需感知
├── powerjob-server // powerjob-server,基于SpringBoot实现的调度服务器
├── powerjob-worker // powerjob-worker, 普通Jar包,接入powerjob-server的应用需要依赖该Jar包
├── powerjob-worker-agent // powerjob-agent,可执行Jar文件,可直接接入powerjob-server的代理应用
├── powerjob-worker-samples // 教程项目,包含了各种Java处理器的编写样例
├── powerjob-worker-spring-boot-starter // powerjob-worker 的 spring-boot-starter ,spring boot 应用可以通用引入该依赖一键接入 powerjob-server
├── powerjob-official-processors // 官方处理器,包含一系列常用的 Processor,依赖该 jar 包即可使用
├── others
└── pom.xml
2.2.2、启动准备
在直接启动官方案例前,需要做一下前提的准备:
(1)修改application.properties配置文件中的powerjob.worker.app-name和powerjob.worker.server-address两个字段,前者表示在调度中心注册的应用名称,后者表示power-job-server的地址,可以用逗号隔开多个调度中心地址。

(2)在Power-job-server调度中心中注册一个执行器。
在启动了powerjob-server应用后,访问http://localhost:7700。

注册好之后进行登录进入:

启动执行器:
执行器的powerjob.worker.app-name就是注册时的名称。

描述:

启动成功后,就会在页面中看到执行器的基本信息。
2.2.3、编写任务
点击右上角的新建任务,创建需要执行的任务信息。

填写好基本的任务信息

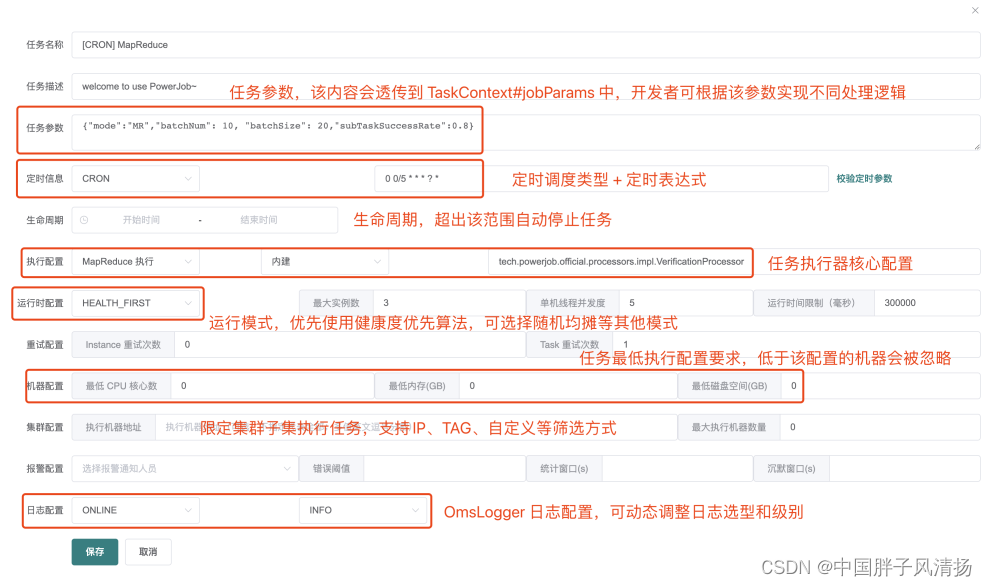
(1)定时信息:该任务的触发方式。
- API :不需要填写任何参数,表明该任务由 OpenAPI 触发,不会被调度器主动调度执行
- CRON:填写 CRON 表达式
- 固定频率: 任务以固定的频率执行,填写整数,单位毫秒
- 固定延迟: 任务以固定的延迟执行,填写整数,单位毫秒
- 每日固定间隔:哪几天的哪些时间段需要执行,比如每周二和三的10点到11点间每10分钟触发一次
- 工作流:不需要填写任何参数,表明该任务由工作流(workflow)触发
(2)执行配置:由执行类型(单机、广播和 MapReduce )、处理器类型和处理器参数组成,后两项相互关联。
- 内置Java处理器
■ 方式一:填写该处理器的全限定类名(tech.powerjob.samples.processors.SimpleProcessor)
■ 方式二:填写 IOC 容器的 bean 名称,比如 Spring 用户可填写 Spring Bean 名称(eg, 处理器使用注解 @Component(value = “powerJobProcessor”),则控制台可填写 powerJobProcessor)
■ 方式三:方法级注解,非 MapReduce 任务可直接使用注解 @PowerJobHandler 将某个方法转化为 PowerJob 任务,并设置唯一入参 TaskContext注入上下文。 - 外置Java容器
填写容器ID#处理器全限定类名
再日常的开发中一般使用的都是内置的Java处理器。
(3)运行配置
- 派发策略:默认健康度优先,优先选择性能最优机器进行执行,可选随机均摊等其他派发模式
- 最大实例数:该任务同时执行的数量,0 代表不限制实例数量
- 单机线程并发数:该实例执行过程中每个 Worker 使用的线程数量(MapReduce 任务生效,其余无论填什么,都只会使用必要的线程数)
- 运行时间限制:限定任务的最大运行时间,超时则视为失败,单位毫秒,0代表不限制超时时间(不建议不限制超时时间)。
(4)重试配置
- Instance 重试次数:实例级别,失败了整个任务实例重试,会更换TaskTracker(本次任务实例的Master节点),代价较大,大型Map/MapReduce慎用。
- Task 重试次数:Task级别,每个子 Task 失败后单独重试,会更换 ProcessorTracker(本次任务实际执行的 Worker节点),代价较小,推荐使用。
同时配置任务重试次数和子任务重试次数之后的重试放大,比如对于单机任务来说,假如任务重试次数和子任务重试次数都配置了 1 且都执行失败,实际执行次数会变成 4 次!推荐任务实例重试配置为 0,子任务重试次数根据实际情况配置。
(5)机器配置:用来标明允许执行任务的机器状态,避开那些摇摇欲坠的机器,0 代表无任何限制。
- 最低 CPU 核心数:填写浮点数,CPU 可用核心数小于该值的 Worker 将不会执行该任务。
- 最低内存(GB):填写浮点数,可用内存小于该值的 Worker 将不会执行该任务。
- 最低磁盘(GB):填写浮点数,可用磁盘空间小于该值的 Worker 将不会执行该任务。
(6)集群配置
-
执行机器地址,指定集群中的某几台机器执行任务
■ IP模式:多值英文逗号分割,如192.168.1.1:27777,192.168.1.2:27777。常用于 debug 等场景,需要指定特定机器运行。
■ TAG 模式:通过 PowerJobWorkerConfig#tag将执行器打标分组后,可在控制台通过 tag 指定某一批机器执行。常用于分环境分单元执行的场景。如某些任务需要屏蔽安全生产环境(tag 设置为环境标),某些任务只需要在特定单元执行(tag 设置单元标) -
最大执行机器数量:限定调动执行的机器数量
(7)日志配置:可使用控制台配置调整 Job 使用的 Logger 及 LogLevel
- 支持 SERVER(服务端日志,默认)、LOCAL(本地日志)、STDOUT(系统输出)、NULL(空实现)4种 LogType
- 支持 DEBUG、INFO、WARN、ERROR、OFF 5种级别控制
初期调试可使用 SERVER 日志,后续功能稳定后改为 LOCAL,并调高日志级别,降低通讯压力,消除性能瓶颈问题。
2.2.4、执行器运行结果

2.3、自定义案例
自定义案例依照官方给出来的案例即可。
2.3.1、导入依赖
<dependency>
<groupId>tech.powerjob</groupId>
<artifactId>powerjob-worker-spring-boot-starter</artifactId>
<version>4.3.3</version>
</dependency>
2.3.2、编写application.yaml
server:
port: 8080
spring:
jpa:
open-in-view: false
powerjob:
worker:
app-name: powerjob-worker-samples # 调度中心注册的名称
port: 27777# 端口
server-address: localhost:7700 # # 调度服务器地址,IP:Port 或 域名,多值逗号分隔
store-strategy: disk # 持久化方式,可选,默认 disk
max-result-length: 4096 # 任务返回结果信息的最大长度,超过这个长度的信息会被截断,默认 8192
# 单个任务追加的工作流上下文最大长度,超过这个长度的会被直接丢弃,默认 8192
max-appended-wf-context-length: 4096
- spring.jpa.open-in-view: 是 Spring Boot 的一个配置属性,它用于控制 JPA(Java Persistence API)是否在视图渲染期间保持数据库连接。
默认情况下,Spring Boot 会在每个 HTTP 请求结束后关闭 JPA 数据库连接。这是为了防止数据库连接泄漏。然而,在某些情况下,例如使用 Thymeleaf 或其他模板引擎进行视图渲染时,需要在渲染过程中保持数据库连接。
当你设置 spring.jpa.open-in-view=true 时,Spring Boot 会在整个视图渲染期间保持 JPA 数据库连接打开。这可以避免在渲染过程中出现数据库连接关闭的情况,从而提高性能。但是,请注意,这可能会导致数据库连接泄漏,尤其是在长时间运行的请求或出现异常的情况下。
需要注意的是,在使用 spring.jpa.open-in-view=true 时,你需要确保你的应用程序能够正确地管理数据库连接,以避免潜在的资源泄漏问题。
总的来说,spring.jpa.open-in-view 是一个高级配置选项,通常只在必要时使用。在大多数情况下,让 Spring Boot 自动管理数据库连接是更好的选择。 - powerjob.worker.port: 是一个配置项,用于指定PowerJob Worker的端口号。这个端口用于接收调度服务器发送的任务,并执行相应的处理逻辑。具体的端口号需要在配置文件中进行设置,默认情况下端口号为8081。
- powerjob.worker.store-strategy: 选值可以是
disk和memory,当值为disk时,意味着PowerJob的存储策略被设置为DISK类型。在这种情况下,任务数据会被存储在硬盘上。具体而言,PowerJob会使用H2数据库来存储任务数据,数据库文件的默认路径是用户主目录下的“powerjob/worker”目录,主目录一般是在C盘。此属性是用来配置执行任务时产生的数据的存储位置。
2.3.3、单机任务
(1)编写单机执行器类
// 实现BasicProcessor接口并注入到Spring容器中托管
@Component
public class StandaloneProcess implements BasicProcessor {
// 当调度中心调度时就会执行此方法
@Override
public ProcessResult process(TaskContext taskContext) throws Exception {
System.out.println("单机模式调用成功");
return new ProcessResult(true, taskContext + ": success");
}
}
(2)编写单机执行器配置

(3)执行结果

2.3.4、广播任务
(1)BroadcastProcessor接口
BroadcastProcessor接口是BasicProcessor接口的子接口。内部提供了执行前(preProcess)和执行后(postProcess)的处理方法。
public interface BroadcastProcessor extends BasicProcessor {
default ProcessResult preProcess(TaskContext context) throws Exception {
return new ProcessResult(true);
}
default ProcessResult postProcess(TaskContext context, List<TaskResult> taskResults) throws Exception {
return defaultResult(taskResults);
}
static ProcessResult defaultResult(List<TaskResult> taskResults) {
long succeed = 0L;
long failed = 0L;
Iterator var5 = taskResults.iterator();
while(var5.hasNext()) {
TaskResult ts = (TaskResult)var5.next();
if (ts.isSuccess()) {
++succeed;
} else {
++failed;
}
}
return new ProcessResult(failed == 0L, String.format("succeed:%d, failed:%d", succeed, failed));
}
}
(2)启动多个服务
在项目启动栏中选择Edit configurations。

允许同时运行多个实例

启动多个实例
启动前一定要注意修改配置文件,不然端口是被占用的状态。

(3)调度中心
当两个服务都成功启动后,在调度中心的Web页面可以看到两个服务的基本信息。

(4)编写广播执行器类
@Component
public class BroadcastProcess implements BroadcastProcessor {
@Override
public ProcessResult process(TaskContext taskContext) throws Exception {
System.out.println("广播执行");
return new ProcessResult();
}
}
执行前和执行后的方法都可以省略。
(5)编写广播执行器配置

集群配置可以不用给,默认就是全部服务。
(6)执行结果
服务一:

服务二:

在PowerJob中,广播处理器对应了广播任务,即某个任务的某次运行会调动集群内所有机器参与运算。为了便于资源的准备和释放,广播处理器在BasicProcessor的基础上额外增加了preProcess和postProcess方法,分别在整个集群开始之前/结束之后选一台机器执行相关方法。
2.3.5、@PowerJobHandle
通过使用@PowerJobHandle注解,可以简化任务的定义过程。你只需要在方法上添加该注解,并指定任务的名称,就可以快速地定义一个任务处理器。
使用调度中心或API,你可以方便地调度使用@PowerJobHandle注解的任务。你只需要指定任务的名称和其他相关参数,就可以轻松地触发任务的执行。
(1)编写执行类
@Component
public class PowerJobHandleService {
@PowerJobHandler(name = "handler")
public void abc(TaskContext taskContext){
System.out.println("@PowerJobHandler执行 :" + taskContext.getJobId() );
}
}
(2)编写执行配置

- 全限定名就是类的完整路径:
com.tt.powerjobdemo.process.PowerJobHandleService。 - 托管类名就是注入Spring容器中的类的名称:
@Component("ClassName")。 - 任务名称就是
@PowerJobHandler(name = "handler")中name对应的值。
(3)运行结果

必须要有入参 TaskContext,返回值可以是 null,也可以是其他任意类型。正常返回代表成功,抛出异常代表执行失败。
因为TaskContent的参数都不需要我们开发人员来参与,所以TaskContent的参数值都是Power Job系统给出的。
3、打包发布
所谓的打包发布就是将自定义的案例打成jar包然后发布到Docker等平台上运行。
因为我们使用的是SpringBoot,所以打包很容易,而我们的Docker使用的是本地的Docker环境,所以这里主要体现部署方面。
3.1、打包Power-job
在将导入的源码打包成jar文件时,很有可能会出现问题。
3.1.1、常见问题
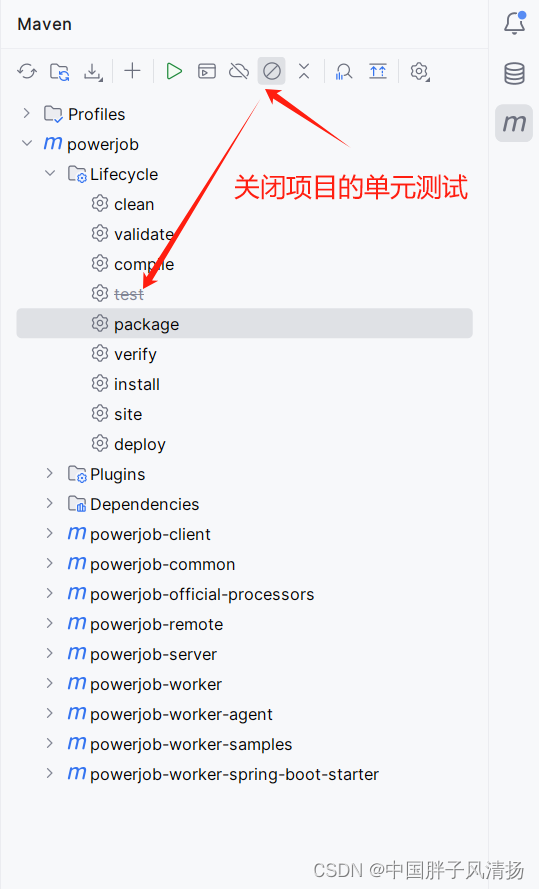
(1)Please refer to XXX for the individual test results.
解决办法:项目打包时跳关单元测试。
(2)class lombok.javac.apt.LombokProcessor (in unnamed module @0x70485aa)
解决办法:降低或者提升Lombok或者JDK的版本。
我使用的是JDK 17,PowerJob使用的Lombok是1.8.12,然后我改成了1.8.28。就成功启动了。
3.1.2、获取Jar包
在将PowerJob打包完成后,会有多个可执行的jar包文件。但是我们只需要找到powerjob-server-starter-4.3.6.jar文件就可以了,这个是主要的启动文件。
找到后执行java -jar powerjob-server-starter-4.3.6.jar。如果没有报错并且能在浏览器中访问到页面就是打包成功了。
3.2、部署Docker
- Docker通过使用容器技术实现了资源的隔离,使得每个容器都可以拥有独立的计算、内存和存储资源。这有助于确保应用程序的性能和稳定性。
- 由于Docker实现了资源的共享和复用,因此可以有效地降低硬件成本。同时,由于部署和管理的简化,也降低了运营成本。
- 可以轻松地管理和升级应用程序。只需构建新的容器并替换旧的容器即可完成升级,无需对整个系统进行重新部署。
3.2.1、编写Dockerfile
FROM java
ADD powerjob-server-starter-4.3.6.jar ./powerjob-server-starter-4.3.6.jar
ENTRYPOINT ["java","-jar","powerjob-server-starter-4.3.6.jar"]
- FROM:构建当前镜像所基于的基础镜像,先使用
docker search命令查看是否有此镜像。 - ADD:指将宿主机的文件或目录复制到镜像文件系统中指定的路径。
- ENTRYPOINT :类似于CMD指令,但其不会被docker run指令运行参数所覆盖,并且这些命令行参数会被当作参数送给ENTRYPOINT指令指定的程序。但是如果运行docker run时使用了–entrypoint选项,将覆盖CMD指令指定的程序。
最后,因为我的环境是Windows,编写Dockerfile是使用的是文本文件,所以会有一个.txt的后缀,这个是需要去掉的。
编写Dockerfile注意点:
- Dockerfile一定是
Dockerfile这样的。 - 不能有其余的后缀。
3.2.2、构建镜像
docker build -f E:\virtual\build\power-job\Dockerfile -t power-job .
- -f:指定本地的Dockerfile文件。
- -t:构建的镜像名称。
- .:表示当前目录
敲了回车后等待构建完成,可能需要几分钟:

查看镜像

3.2.3、启动容器
(1)构建并启动容器
docker run -d --name power-job -p 7700:7700 6620d48dd2cc
(2)查看容器
docker ps
(3)查看启动日志
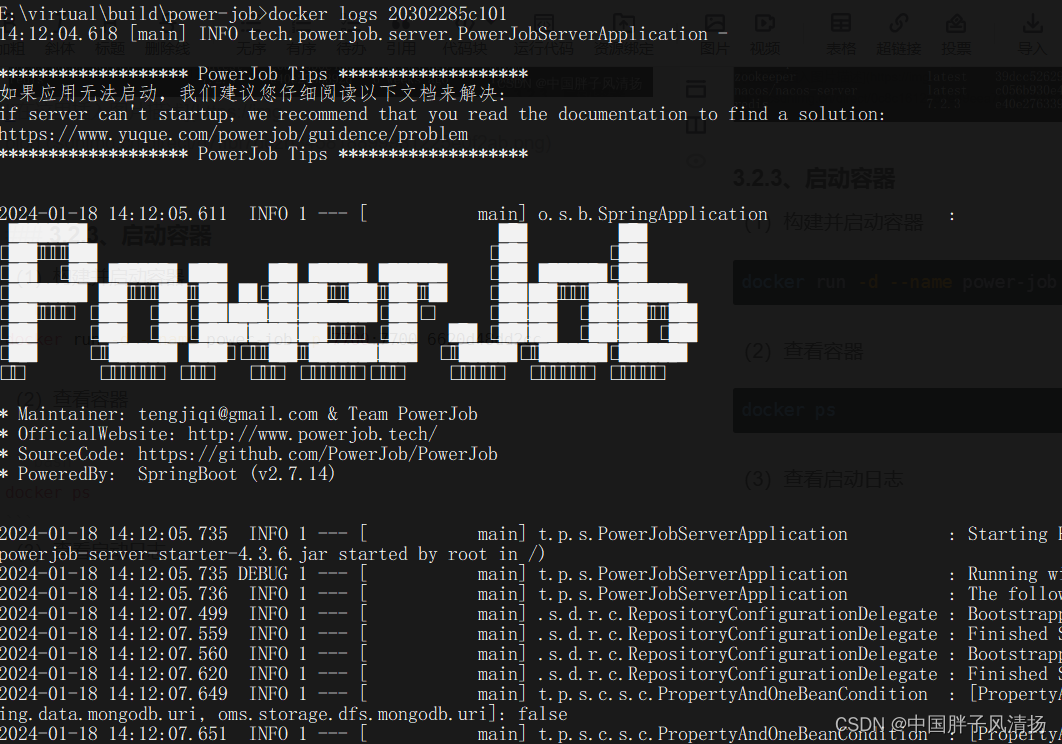
看到图中的日志且后续没有报错的情况下,我们的镜像就是构建成功的。
(4)访问

访问成功,镜像和容器都正确。