Playwright 网页截图
在做web自动化测试时,脚本执行时会出现执行失败的情况,这个时候就需要分析失败的原因,由于脚本执行时是不需要人工盯着执行的,这个时候就需要在脚本执行失败时保留某些信息方便脚本执行完成后来分析失败的原因,将脚本执行失败时的网页截个图保留下来,就可以非常方便的查看脚本失败时页面上的状态或者页面上的信息。这是辅助分析脚本失败原因的一种好的方式,接下来看一下如何实现网页截图。
网页截图代码:
page.screenshot(path='xxx", full_page=True) #full_page=True截取整个页面
实践案例:
# '''
# author: 测试-老姜 交流微信/QQ:349940839
# 欢迎添加微信或QQ,加入学习群共同学习交流。
# QQ交流群号:877498247
# 西安的朋友欢迎当面交流。
# '''
from playwright.sync_api import Playwright, sync_playwright, expect
playwright = sync_playwright().start()
browser = playwright.chromium.launch(headless=False, args=['--start-maximized']) #默认无头模式,设置浏览器最大化
context = browser.new_context(no_viewport=True) # 创建上下文,相当浏览器于实例化,即打开浏览器
page = context.new_page() # 打开一个新标签页
page.goto("http://127.0.0.1/zentao/user-login-L3plbnRhby8=.html")
page.wait_for_timeout(2000)
ele = page.locator('css=#account')
ele.type('admin') # 页面刷新后依然可以输入
page.wait_for_timeout(1000)
page.locator('xpath=//*[@name="password"]').fill('Deshifuzhi01')
page.wait_for_timeout(1000)
page.locator('text=登录').last.click()
page.wait_for_timeout(2000)
img_path = 'D:\jnc\自动化测试\playwright\playwright_project\jietu.png'
page.screenshot(path= img,full_page=True) #将截图保存到指定目录中,并命名为jietu.png
context.close()
browser.close()
截取的图片正常保存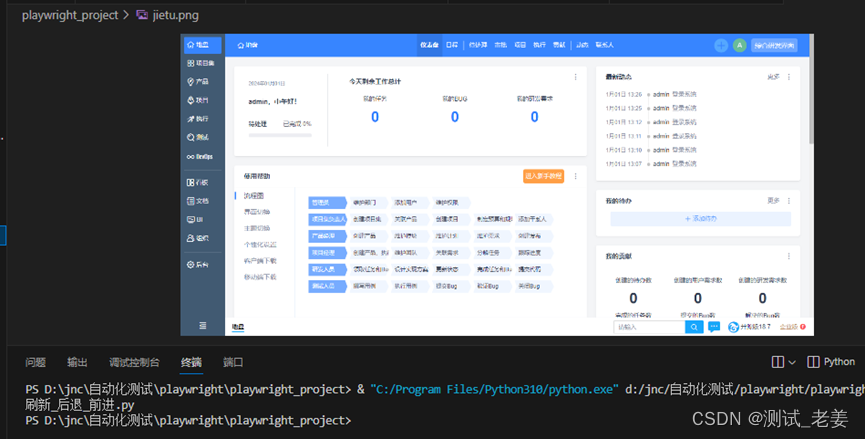








![C语言通过MSXML6.0读写XML文件(同时支持char[]和wchar_t[]字符数组)](https://img-blog.csdnimg.cn/direct/893ce3d2bdd74cccaa1bb3911ea7b416.png)