前言
前段时间打算做一个目标行为检测的项目,翻阅了大量资料,也借鉴了不少项目,最终感觉Yolov5+Deepsort+Slowfast实现实时动作检测这个项目不错,因此进行了实现。
一、核心功能设计
总的来说,我们需要能够实现实时检测视频中的人物,并且能够识别目标的动作,所以我们拆解需求后,整理核心功能如下所示:
- yolov5实现目标检测,确定目标坐标
- deepsort实现目标跟踪,持续标注目标坐标
- slowfast实现动作识别,并给出置信率
- 用框持续框住目标,并将动作类别以及置信度显示在框上
我做的一个效果如下:
基于Yolov5+Deepsort+SlowFast算法实现视频目标识别、追踪与行为实时检测
二、核心实现步骤
1.yolov5实现目标检测
“YOLO”是一种运行速度很快的目标检测AI模型,YOLO将对象检测重新定义为一个回归问题。它将单个卷积神经网络(CNN)应用于整个图像,将图像分成网格,并预测每个网格的类概率和边界框。YOLO非常快,它比“R-CNN”快1000倍,比“Fast R-CNN”快100倍。YOLOv5是YOLO比较新的一个版本。
所以我们把视频分解成多幅图像,并利用yolov5算法进行目标检测并逐帧执行时,可以看到目标跟踪框随目标移动。
效果如下所示:

2.deepsort实现目标跟踪
但是,如果视频帧中有多个目标,如何知道一帧中的目标和上一帧是同一个对象?这就是目标跟踪的工作,应用多个检测来识别特定目标随时间的变化,实现目标跟踪。
Deepsort是实现目标跟踪的算法,从sort(simple online and realtime tracking)演变而来,其使用卡尔曼滤波器预测所检测对象的运动轨迹,匈牙利算法将它们与新的检测目标相匹配。Deepsort易于使用且运行速度快,成为AI目标检测跟踪之热门算法。
首先来看一下DeepSORT的核心流程:
预测(track)——>观测(detection+数据关联)——>更新
- 预测:预测下一帧的目标的bbox,即后文中的tracks
- 观测:对当前帧进行目标检测,仅仅检测出目标并不能与上一帧的目标对应起来,所以还要进行数据关联
- 更新:预测Bbox和检测Bbox都会有误差,所以进行更新,更新后的跟踪结果通常比单纯预测或者单纯检测的误差小很多。

3.slowfast动作识别
我们将视频序列和检测框信息输入行为分类模型,输出每个检测框的行为类别,达到行为检测的目的。
而行为分类模型我们采用的是slowfast算法,其包括一个Slow路径,以低帧速率操作,以捕捉空间语义,以及一个Fast路径,以高帧速率操作,以精细的时间分辨率捕捉运动。快速路径可以通过减少信道容量而变得非常轻量级,同时还可以学习有用的时间信息用于视频识别。

三、核心代码解析
1.参数
if __name__=="__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--input', type=str, default="D:/temporary2/person.mp4", help='test imgs folder or video or camera')
parser.add_argument('--output', type=str, default="output1.mp4", help='folder to save result imgs, can not use input folder')
# object detect config
parser.add_argument('--imsize', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf', type=float, default=0.4, help='object confidence threshold')
parser.add_argument('--iou', type=float, default=0.4, help='IOU threshold for NMS')
parser.add_argument('--device', default='cuda', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--classes', default=0, nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--show', action='store_true', help='show img')
config = parser.parse_args()
if config.input.isdigit():
print("using local camera.")
config.input = int(config.input)
print(config)
main(config)
从__main__开始分析,设置了输入输出参数以及目标检测的一些参数,包括输入路径、输出路径、尺寸大小、置信度、iou值、以及目标检测的类别,其中0是人。
2.主函数
对输入的config参数解析并使用,模型使用yolov5l6,权重下载到本地
model = torch.hub.load('ultralytics/yolov5', 'yolov5l6') #加载yolov5模型
model.conf = config.conf
model.iou = config.iou
model.max_det = 200
model.classes = config.classes
device = config.device
imsize = config.imsize
video_model = slowfast_r50_detection(True).eval().to(device) #加载slowfast_r50_detection模型
# video_model = slowfast_r50_detection(False).eval().to(device)
# video_model.load_state_dict(torch.load("SLOWFAST_8x8_R50_DETECTION.pyth")['model_state'])
加载Slowfast、Deepsort模型,使用的Slowfast是在AVA2.2上训练的,通过AvaLabeledVideoFramePaths函数获得id到动作的mapping
deepsort_tracker = DeepSort("deep_sort/deep_sort/deep/checkpoint/ckpt.t7") #加载DeepSort模型
ava_labelnames,_ = AvaLabeledVideoFramePaths.read_label_map("selfutils/temp.pbtxt") #加载类别标签
ava_labelnames_abnormal,_ = AvaLabeledVideoFramePaths.read_label_map("selfutils/ava_action_abnormal.pbtxt") #加载类别标签
coco_color_map = [[random.randint(0, 255) for _ in range(3)] for _ in range(80)]
首先对视频进行抽帧处理,通过get_clip()对一秒内的视频进行抽帧,只保留视频图片,将tensor转numpy数组,BGR格式
a=time.time()
for i in range(0,math.ceil(video.duration),1): #截视频
video_clips=video.get_clip(i, i+1-0.04)
video_clips=video_clips['video']
if video_clips is None:
continue
img_num=video_clips.shape[1]
imgs=[]
for j in range(img_num):
imgs.append(tensor_to_numpy(video_clips[:,j,:,:]))
# "video": A tensor of the clip's RGB frames with shape: (channel, time, height, width).
# 将tensor转为numpy数组,BGR格式
通过yolov5网络进行目标检测
yolo_preds=model(imgs, size=imsize)
# 每25帧后插入1帧作为预测图像
yolo_preds.files=[f"img_{i*25+k}.jpg" for k in range(img_num)]
print(i,video_clips.shape,img_num)
使用预训练的Deepsort权重,以yolo预测结果作为输入,用Deepsort的结果代替yolo预测的结果,这里Deepsort是用来给相同id的目标分配动作label的。
deepsort_outputs=[]
for j in range(len(yolo_preds.pred)):
temp=deepsort_update(deepsort_tracker,yolo_preds.pred[j].cpu(),yolo_preds.xywh[j][:,0:4].cpu(),yolo_preds.imgs[j])
if len(temp)==0:
temp=np.ones((0,8))
deepsort_outputs.append(temp.astype(np.float32))
yolo_preds.pred=deepsort_outputs
通过ava_inference_transform()函数对预测输入进行预处理,然后通过调用Slowfast模型进行预测,最后为每个id分配动作类别
id_to_ava_labels={}
if yolo_preds.pred[img_num//2].shape[0]:
inputs,inp_boxes,_=ava_inference_transform(video_clips,yolo_preds.pred[img_num//2][:,0:4],crop_size=imsize)
inp_boxes = torch.cat([torch.zeros(inp_boxes.shape[0],1), inp_boxes], dim=1)
if isinstance(inputs, list): #判断类型
inputs = [inp.unsqueeze(0).to(device) for inp in inputs]
else:
inputs = inputs.unsqueeze(0).to(device)
with torch.no_grad():
slowfaster_preds = video_model(inputs, inp_boxes.to(device)) #预测动作
slowfaster_preds = slowfaster_preds.cpu()
for tid,avalabel,avapred in zip(yolo_preds.pred[img_num//2][:,5].tolist(),np.argmax(slowfaster_preds,axis=1).tolist(),torch.max(slowfaster_preds,axis=1).values.tolist()):
# if(avalabel in ava_labelnames_abnormal):
# id_to_ava_labels[tid]=ava_labelnames[avalabel+1]+'_abnormal'
id_to_ava_labels[tid]=[ava_labelnames[avalabel+1],avapred] # print(avalabel)
# print(avalabel)
# print(ava_labelnames[avalabel+1])
if((avalabel+1) in ava_labelnames_abnormal):
isnormal=False
else:
isnormal=True
save_yolopreds_tovideo(yolo_preds,id_to_ava_labels,coco_color_map,outputvideo,isnormal)
print("total cost: {:.3f}s, video clips length: {}s".format(time.time()-a,video.duration))
outputvideo.release()
print('saved video to:', vide_save_path)
3.将结果保存成视频
def save_yolopreds_tovideo(yolo_preds,id_to_ava_labels,color_map,output_video,isnormal):
for i, (im, pred) in enumerate(zip(yolo_preds.imgs, yolo_preds.pred)):
im=cv2.cvtColor(im,cv2.COLOR_BGR2RGB)
if pred.shape[0]:
for j, (*box, cls, trackid, vx, vy) in enumerate(pred):
if int(cls) != 0:
ava_label = ''
ava_pred=0.0
elif trackid in id_to_ava_labels.keys():
ava_label = id_to_ava_labels[trackid][0].split(' ')[0]
ava_pred=id_to_ava_labels[trackid][1]
else:
ava_label = 'Unknow'
ava_pred=0.0
if(isnormal):
text = '{:.4f} {} {}'.format(ava_pred,yolo_preds.names[int(cls)],ava_label)
color = [40,113,62]
else:
text = '{:.4f} {} {} {}'.format(ava_pred,yolo_preds.names[int(cls)],ava_label,'abnormal')
color = [43,44,124]
# print(cls)
im = plot_one_box(box,im,color,text)
output_video.write(im.astype(np.uint8))
四、复现与配置过程
1.首先配置好自己的Anaconda虚拟环境在这里不再详细说了,不会的可以参考我另一篇博客中有介绍,YOLOv8目标跟踪环境配置笔记(完整记录一次成功)
2.下载好源码,将项目文件配置好,并用Pycharm打开
3.在虚拟环境中下载所需要的库
pip install opencv-python==4.5.3.56
pip install natsort
pip install ultralytics
pip install pytorchvideo当然这里还需要下载torch 库,最好配置GPU版本,配置方法我上面分享的我的另一篇博客里也有教程,跟着来就好。
我用的虚拟环境python版本是3.7,我的环境中所用到的库目录如下,如果没有配置出来可以对照我的库,看看是不是版本不对或缺少什么库
Package Version
----------------------------- --------------------
absl-py 1.3.0
altgraph 0.17.4
astor 0.8.1
astroid 2.15.8
atomicwrites 1.4.1
attrs 23.2.0
av 10.0.0
backcall 0.2.0
bidict 0.21.2
Bottleneck 1.3.5
cached-property 1.5.2
certifi 2022.12.7
cffi 1.15.1
charset-normalizer 3.3.2
clang 5.0
click 8.0.4
colorama 0.4.6
cryptography 38.0.2
cycler 0.11.0
Cython 0.29.33
decorator 4.4.2
dill 0.3.6
easydict 1.11
exceptiongroup 1.2.0
ffmpeg-python 0.2.0
Flask 2.2.2
Flask-SocketIO 5.1.0
Flask-SQLAlchemy 3.0.2
flatbuffers 1.12
flit_core 3.6.0
fonttools 4.38.0
future 0.18.3
fvcore 0.1.5.post20221221
gast 0.5.3
greenlet 2.0.1
grpcio 1.34.1
h11 0.14.0
h5py 3.7.0
idna 3.6
imageio 2.31.2
imageio-ffmpeg 0.4.9
importlib-metadata 4.11.3
imutils 0.5.4
iniconfig 2.0.0
install 1.3.5
iopath 0.1.10
ipython 7.34.0
isort 5.11.5
itsdangerous 2.0.1
jedi 0.18.2
Jinja2 3.1.2
Keras-Applications 1.0.8
keras-nightly 2.5.0.dev2021032900
Keras-Preprocessing 1.1.2
kiwisolver 1.4.4
lap 0.4.0
lazy-object-proxy 1.9.0
libclang 16.0.0
Markdown 3.4.1
MarkupSafe 2.1.1
matplotlib 3.5.3
matplotlib-inline 0.1.6
mccabe 0.7.0
mediapipe 0.9.0.1
mkl-fft 1.3.1
mkl-random 1.2.2
mkl-service 2.4.0
more-itertools 9.1.0
moviepy 1.0.3
multiprocess 0.70.14
munkres 1.1.4
natsort 8.4.0
networkx 2.6.3
numexpr 2.8.4
numpy 1.21.6
opencv-contrib-python 3.4.2.16
opencv-python 4.5.3.56
opencv-python-headless 4.1.2.30
packaging 23.0
pandas 1.3.5
pandas-stubs 1.2.0.62
parameterized 0.9.0
parso 0.8.3
pefile 2023.2.7
pickleshare 0.7.5
Pillow 9.4.0
pip 22.3.1
platformdirs 4.0.0
pluggy 1.2.0
portalocker 2.7.0
proglog 0.1.10
prompt-toolkit 3.0.38
protobuf 3.20.3
psutil 5.9.4
py 1.11.0
py-cpuinfo 9.0.0
pycparser 2.21
pygame 2.5.2
Pygments 2.14.0
pyinstaller 5.13.2
pyinstaller-hooks-contrib 2023.12
pylint 2.17.7
PyMySQL 1.0.2
pyparsing 3.0.9
PyQt5 5.15.10
PyQt5-Qt5 5.15.2
PyQt5-sip 12.13.0
pytest 4.0.0
python-dateutil 2.8.2
python-engineio 4.1.0
python-ffmpeg-video-streaming 0.1.14
python-socketio 5.3.0
pytorchvideo 0.1.5
pytz 2022.7.1
pywin32 306
pywin32-ctypes 0.2.2
PyYAML 6.0
requests 2.31.0
scipy 1.7.3
seaborn 0.12.2
setuptools 65.6.3
simple-websocket 0.10.0
six 1.16.0
SQLAlchemy 1.4.39
tabulate 0.9.0
tensorboard 1.14.0
tensorflow 1.14.0
tensorflow-estimator 2.5.0
tensorflow-io-gcs-filesystem 0.31.0
termcolor 2.1.0
thop 0.1.1.post2209072238
tomli 2.0.1
tomlkit 0.12.3
torch 1.13.1+cu116
torchaudio 0.13.1+cu116
torchvision 0.14.1+cu116
tqdm 4.64.1
traitlets 5.9.0
typed-ast 1.5.5
typing_extensions 4.7.1
ultralytics 8.0.145
urllib3 1.23
wcwidth 0.2.6
Werkzeug 2.2.2
wheel 0.38.4
wincertstore 0.2
wrapt 1.14.1
wsproto 1.2.0
yacs 0.1.8
zipp 3.11.0其实主要就是numpy、opencv、torch这几个库和版本要注意
4.修改要进行检测的视频路径,这里以本地视频为例
parser.add_argument('--input', type=str, default="D:/temporary2/person.mp4", help='test imgs folder or video or camera')5.按照官网还要自己再下载一个东西,放在指定文件夹下:
download weights file(ckpt.t7) from [deepsort] to this folder:
./deep_sort/deep_sort/deep/checkpoint/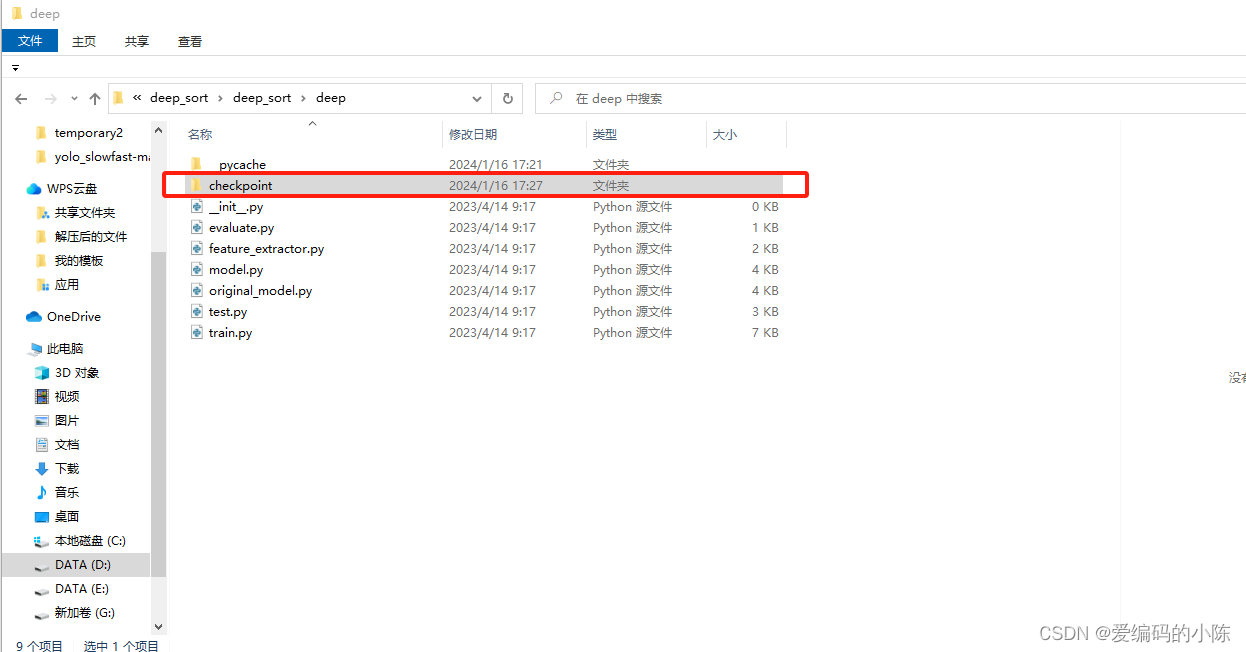
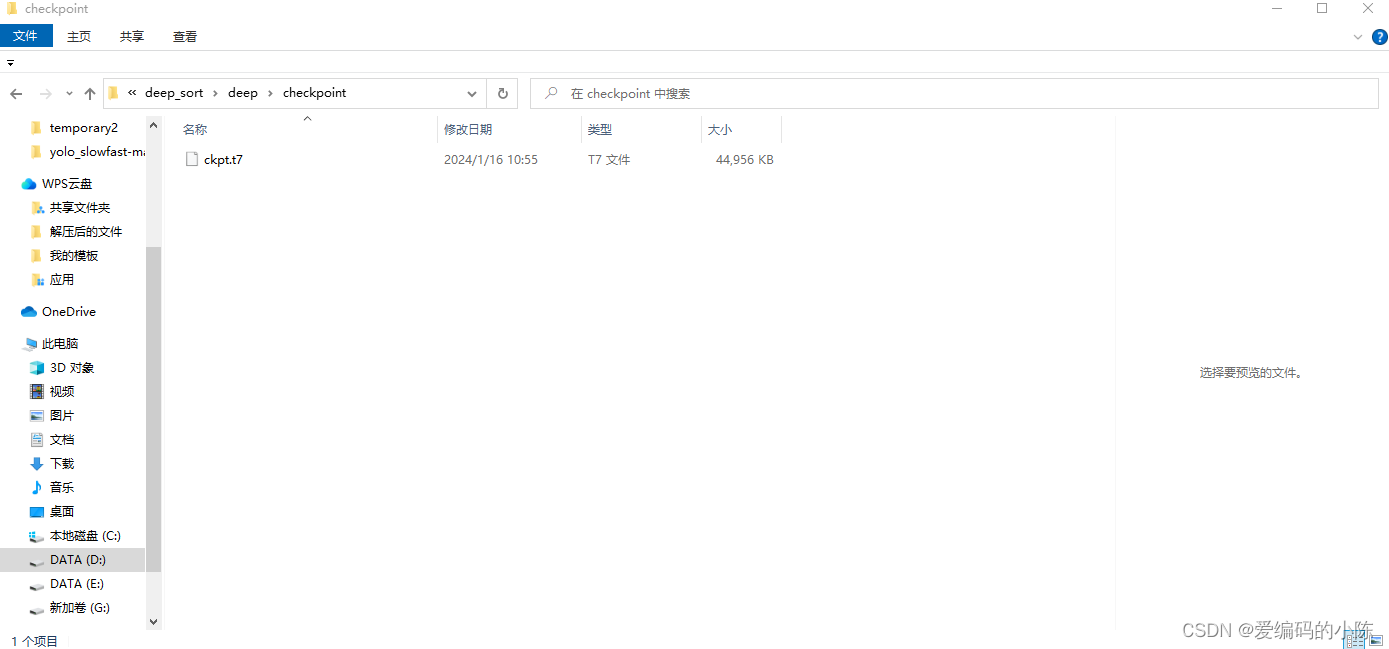
这个checkpoint文件夹要自己建,然后把下载的ckpt.t7放进去,否则运行会因缺少文件而报错。
6.其他地方不需要改动,点击运行yolo_slowfast.py,报错
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized
解决办法:
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"7.再运行会显示
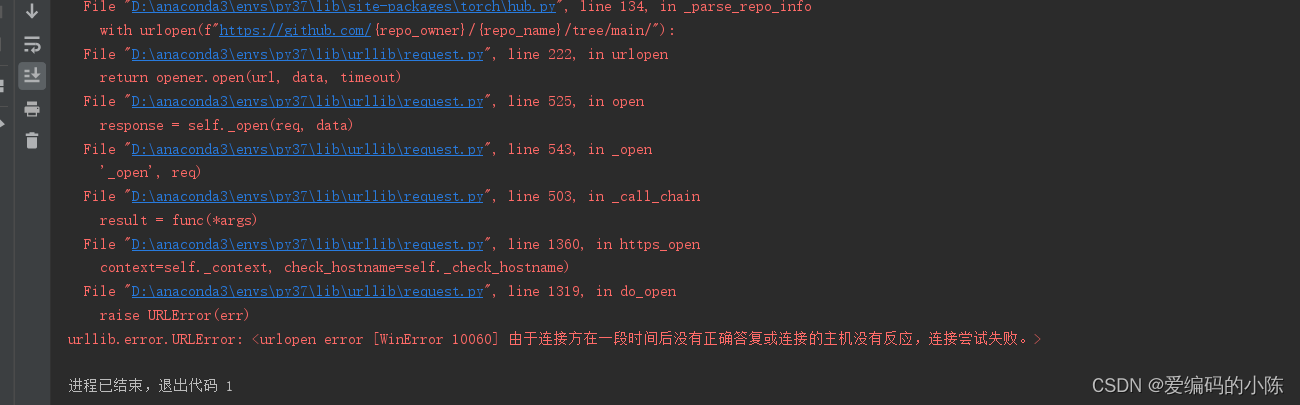
这是因为没有用魔法,一些相关依赖需要下载,不用魔法访问不了
8.用魔法后再运行,会显示这个样子

发现它会自动将slowfast模型文件和yolov5这个模型包括权重文件下载到你本地这个地方

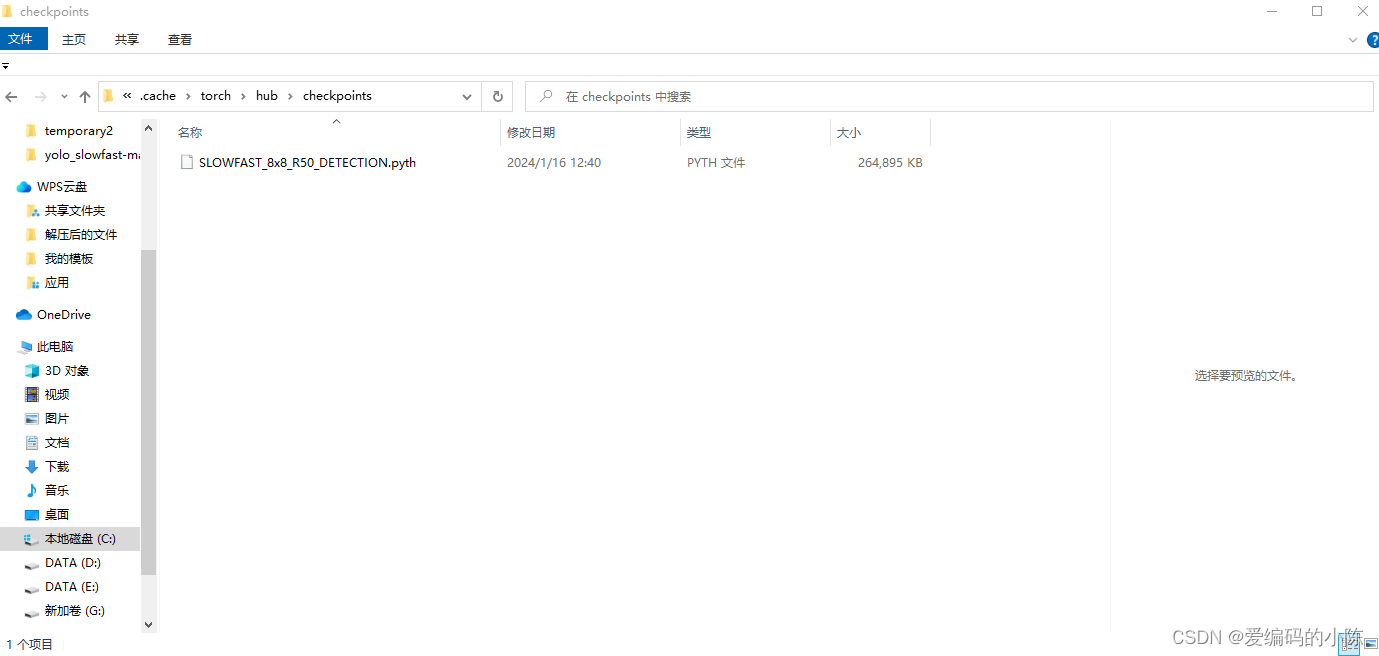
为什么它自己会自动下载yolov5和slowfast所需依赖文件,而且默认在C盘默认位置
Using cache found in C:\Users\MY/.cache\torch\hub\ultralytics_yolov5_master
因为下面这行命令中的 torch.hub.load,具体含义可以自己百度
model = torch.hub.load('ultralytics/yolov5', 'yolov5l6').to(device)9.下载完之后它会自动检测,可能还会自动更新你的两个库,以满足要求

requirements: Ultralytics requirements ['gitpython>=3.1.30', 'Pillow>=10.0.1'] not found, attempting AutoUpdate...
记住在更新下载这两个库的时候,如果你之前虚拟环境下载库,都是通过国内镜像下载的,那么此时一定要及时把魔法先关了,它才能继续找到清华源库,并继续升级和更新相关库,否则会因为冲突下载安装不了,导致升级失败

WARNING: There was an error checking the latest version of pip.
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Could not fetch URL https://pypi.tuna.tsinghua.edu.cn/simple/pip/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.tuna.tsinghua.edu.cn', port=443):
10.更新完那两个库之后,终止程序,再开启魔法,重新运行程序,就会显示满足条件,开始运行了
Requirement already satisfied: gitpython>=3.1.30 in d:\anaconda3\lib\site-packages (3.1.41)
Requirement already satisfied: Pillow>=10.0.1 in d:\anaconda3\lib\site-packages (10.2.0)
Requirement already satisfied: gitdb<5,>=4.0.1 in d:\anaconda3\lib\site-packages (from gitpython>=3.1.30) (4.0.11)
Requirement already satisfied: smmap<6,>=3.0.1 in d:\anaconda3\lib\site-packages (from gitdb<5,>=4.0.1->gitpython>=3.1.30) (5.0.1)requirements: AutoUpdate success 24.9s, installed 2 packages: ['gitpython>=3.1.30', 'Pillow>=10.0.1']

10.成功之后的检测视频会保存为output.mp4在根目录下,也可以根据下行命令自己进行更改
parser.add_argument('--output', type=str, default="output2.mp4", help='folder to save result imgs, can not use input folder')结果如下

11.但是每次运行的时候都需要开启魔法才能成功跑起来,原因就在第8步,它每次都会重新检索并启用,可以尝试把第8步它自动下载的依赖文件复制到自己yolo-slowfast项目根目录下,然后修改
model = torch.hub.load('ultralytics/yolov5', 'yolov5l6').to(device)改为以下加载本地路径下的模型
model_path = "D:/temporary2/yolo_slowfast-master/yolov5l6.pt"
model = torch.load(model_path, map_location=device)
model = model.to(device).eval()
修改
video_model = slowfast_r50_detection(True).eval().to(device)
改为
video_model_path = "D:/temporary2/checkpoints/SLOWFAST_8x8_R50_DETECTION.pyth"
video_model = torch.load(video_model_path, map_location=device)
video_model = video_model.to(device).eval()
12.如果有报错
if config.input.isdigit():AttributeError: 'int' object has no attribute 'isdigit'
则将
if config.input.isdigit():改为
if isinstance(config.input, str):#如果要改为实时摄像头用这行最后,如果还有什么问题,欢迎大家评论区一起交流~
参考链接:
1. 视频实时行为检测——基于yolov5+deepsort+slowfast算法
2. Yolov5+Deepsort+Slowfast实现实时动作检测
3. YOLOv5算法详解
4. pytorch yolo5+Deepsort实现目标检测和跟踪