自己在看面经中遇到的一些面试题,结合自己和理解进行了一下整理。
transformer中求和与归一化中“求和”是什么意思?
求和的意思就是残差层求和,原本的等式为y = H(x)转化为y = x + H(x),这样做的目的是防止网络层数的加深而造成的梯度消失,无法对前面网络的权重进行有效调整,导致神经网络模型退化(这种退化不是由过拟合造成的,而是较深模型后面添加的不是恒等映射反而是一些非线性层)。已经学习到较饱和的准确率(或者当发现下层的误差变大时),那么接下来的学习目标就转变为恒等映射的学习,也就是使输入x近似于输出H(x),以保持在后面的层次中不会造成精度下降。
注意力机制中计算注意力分数时为什么会除以根号dk?
这和softmax的求导有关,softmax的计算公式=exp(x1)/exp(x1)+exp(x2),另p=exp(x1)/exp(x1)+exp(x2),那么softmax求导之后=p*(1-p),当p趋近于1时,softmax的导数就趋近于0。故除以根号dk的原因是:为了避免softmax计算的结果过大,造成偏导数为0。
多头注意力比单头注意力的好处?
注意力的计算是并行进行的,多头可以提高计算效率。并且多头可以捕获不同子空间内的特征。
transformer比起RNN的优势?
RNN在传播的过程中会出现信息衰减,而transformer当前词不管距离其他词多远,其只有这个词与其他词的相关性有关。并且transformer的encode可以并行计算,RNN不可以。
transformer为什么使用层归一化?
(当前值减均值)/ 标准差。减小梯度消失和梯度爆炸的问题,并提高网络的泛化性能。*
批量归一化是不同训练数据之间对单个神经元的归一化,层归一化是单个训练数据对某一层所有神经元之间的归一化。
transformer中解码器的注意力与编码器的区别
decode中的自注意力是带掩码的,不让decode看到后文。还有一个encode-decode注意力层,这一层注意力层只有q来源于上一层decode单元的输出,剩下的k、v都来源于encode最后一层的输出。
前馈层
两层relu激活函数,一层全连接神经网络。
BERT的训练任务
1.在输入数据中选择15%用于预测,这15%的数据中有80%被替换为mask,10%的单词被替换为其他词,10%的单词保持不变。2.上下段落匹配,其中50%使用正确的上下句关系,50%随机抽取一个句子拼在后面。
BERT的优缺点
1.预训练阶段会出现特殊的[MASK]字符,而在下游任务中不会出现,造成预训练和微调之间的不匹配。
2.每个batch只有15%的token会被预测,所有收敛速度会比传统语言模型慢。
3.缺乏生成能力。
chatgpt的训练过程
1.SFT阶段(有阶段微调):使用问答对微调GPT3。这一阶段的损失是交叉熵。
2.RM奖励模型:使用1的SFT模型收集每个问题的4-9个回答,并对其进行人为排序。这一阶段使用的损失是排序损失函数,排序高的回答的奖励值-排序低的回答的奖励值,我们希望这个值越大越好。
3.PPO算法更新策略:
LLAMA作出的改进
1.归一化又LN改为了RMS Norm。
2.SwiGLU替代ReLU。
3.旋转位置编码替代位置编码。
ChatGLM作出的改进
1.重新排列了层归一化和残差连接的顺序
2.用GeLU替。换ReLU激活函数
3.在结构和训练目标上兼容这三种预训练模型,需要GLM中同时存在单向注意力和双向注意力,当attention_mask为全1时为双向的attention,当attention_mask为三角矩阵时为单向的attention。
4.使用P-tuning进行的微调。
ChatGLM的训练任务
1.文档级别的预测/生成:从文档中随机采样一个文本片段进行掩码,片段的长度为文档长度的50%-100%。
2.句子级别的预测/生成:从文档中随机掩码若干文本片段,每个文本片段必须为完整的句子,被掩码的词数量为整个文档长度的15%。
既保证了模型的自编码能力又有自回归能力。
Baichuan作出的改进
1.RoPE位置编码
2.RMSNorm归一化
3.SwiGLU激活函数
4.1.2万亿训练数据/上下文窗口4096
参数微调的方法
1.Adapter Tuning:将其嵌入Transformer的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调。
2.Prefix Tuning:构造隐式的输入token,加入到输入前缀(我的理解是将prompt变成可以调整参数的格式)
3.P-tuning:同样加了可微的virtual token,但是仅限于输入,没有在每层加。且virtual token的位置也不一定是前缀,插入的位置是可选的,这里的出发点实际是把传统人工设计模版中的真实token替换成可微的virtual token。
4.P-tuning V2:在输入前面的每层加入可微调的参数。
5.LoRA:冻结了预训练的模型权重,在需要训练的矩阵开通一个旁路矩阵,分为一个降秩矩阵和一个升秩矩阵(比如一个100×100的矩阵可以替换为一个100×2和一个2×100两个矩阵,参数量减少了10000-400),将最后的结果加到原始矩阵上。
6.QLoRA:引入了4位量化、双量化和利用nVidia统一内存进行分页。所有这些步骤都大大减少了微调所需的内存,同时性能几乎与标准微调相当。
模型量化
比如8位量化需要最大值为127,那么选取模型中参数最大的值/127为缩放比例a,将所有的数都除以这个缩放比例a。
Actor-Critic架构

Actor演员使用SFT模型初始化,使用问答对来更新其策略;Critic评论家使用RM模型初始化,用来拟合旧价值估计;Reward Model用来产生当前状态和策略下获得的奖励值;奖励值减掉SFT旧策略与新策略之间的KL散度作为reward,优势函数等于reward减掉旧状态价值估计。当优势函数大于0时,就要鼓励当前的动作;当优势函数小于0时,就要抑制当前动作。
优化器
SGD:随机梯度下降,它使用数据集中的单个样本或一批样本的梯度来更新模型参数。计算过程为原始参数=原始参数-学习率×梯度。
Adam:自适应学习率的梯度下降,Adam算法将不同的梯度给予不同的权重,使得神经网络在学习率稳定时,能快速、稳定的收敛到最佳点。



当m0很小时,使用修正因子重新计算了mt。
为什么sigmoid函数和tanh函数会出现梯度消失
这和两者的求导有关,sigmoid(x) = 1/(1+exp(-x)) = p,求导后表达式为p(1-p),当x趋于正无穷或负无穷时,p趋于1或0,求导后的结果趋于0,因此会出现梯度消失。
tanh(x) = (exp(x)-exp(-x))/(exp(x)+exp(-x)) = p,求导后表达式为1-p2,当x趋于正无穷或负无穷时,p趋于1或-1,求导后的结果趋于0,因此会出现梯度消失。
BERT为什么会做编码任务、完型填空任务、段落匹配任务
BERT本身的结构就是transformer的Encode,其会使用位置编码、词级编码以及段级编码作为输入,经过Encoder的单元之后形成嵌入向量。
当BERT在做完型填空任务时,BERT会将需要预测的位置,通过将最后的输出linear线性变换后,将Embedding_size转化为vovab_size,再进行softmax激活函数之后得到最后单词的概率,使用交叉熵函数进行损失计算。
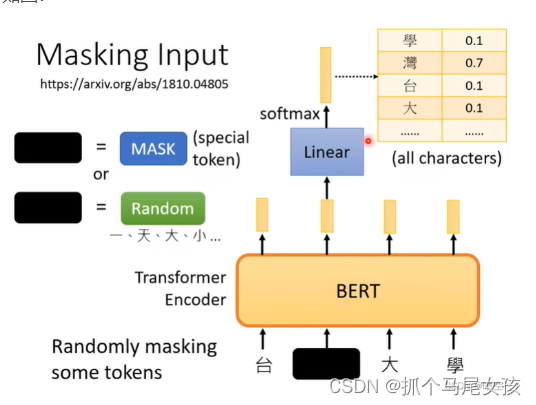
当BERT在做段落匹配任务时,会将CLS处进行linear线性变换后将Embedding_size转化为2,再通过sigmoid函数计算概率来判断这两个句子是否构成上下句的关系。

BERT模型为什么要将15%的词语进行80%mask、10%替换、10%什么也不做,而不是全部mask
在训练时,不是用这种方式,而是全部mask掉的话,模型就会把虽有的注意力集中到“mask”这个词汇上了,模型就能知道不出现“mask”的地方我不用管,啥时候出现“mask”我在管,这对模型提取语义关系是不利的。使用(80% mask,10% 随机替换,10% 保持原词)的方式之后呢,模型不只是需要在“mask”位置做工作,还要时刻预防着随机替换的情况呀,也就是检查这个句子对不对,这就大大提高了模型提取语义效果的能力。
为什么relu激活函数要优于sigmoid激活函数?
1.relu激活函数在正区间内不会出现梯度消失。
2.relu的偏导数计算量比sigmoid小。
3.relu使得一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的互相依存关系,缓解了过拟合问题的发生。
缺点:函数导致负梯度在经过该ReLU单元时被置为0,在下一层传播时也为0,即流经该神经元的梯度永远为0,不对任何数据产生响应。
为什么会出现梯度消失?
采用了不合适的激活函数。
隐藏层数太多。
解决:使用合适的激活函数,使用归一化,残差网络。
为什么会出现梯度爆炸?
参数初始化太大
隐藏层数太多。
解决:使用梯度裁剪策略,使用合适的激活函数,使用归一化,使用残差网络。
lora为什么可以映射到低秩维度?
lora论文中指出常见的预训练模型具有非常低的内在维度(如果你有一个在三维空间中分布的数据集,但所有的数据点都严格地位于同一平面上,那么这个数据集的内在维度就是2,因为你只需要两个坐标就能准确地描述每个数据点);换句话说,存在一个低维度的重新参数化,对于微调来说与完整参数空间一样有效。用少量数据微调大语言模型可能不需要那么多维度的参数,而因为尽管模型可能有数亿个参数,但这些参数中的大部分可能并不需要改变,或者它们的改变对模型的性能没有太大影响。
LSTM为什么选择sigmoid和tanh而不选择relu?
因为sigmoid和tanh都是饱和函数,当输入达到一定值时,输出几乎不发生变化;而relu难以实现门控的效果。
sigmoid用于“开关”,控制信息能流出多少;tanh符合0中心分布,此外tanh函数在输入为0附近相比 Sigmoid函数有更大的梯度,通常使模型收敛更快。
LSTM如何缓解RNN的梯度消失或梯度爆炸
因为每个LSTM都有门控机制,中间记忆细胞通过输入门和遗忘门之后进行累加,而不像RNN那样的累乘,从而缓解了RNN的梯度消失或梯度爆炸。
Deepspeed分布式计算
1.数据并行,在几张GPU卡上平均把训练的数据分开。
2.模型并行,分为层间并行和层内并行(比如多头注意力分开多个卡进行训练)。
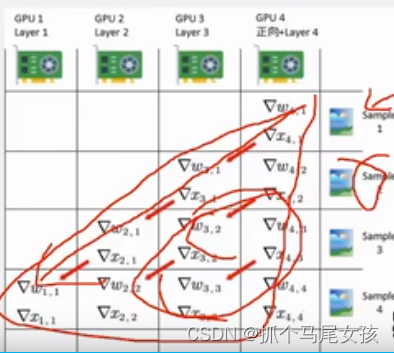
3.混合并行