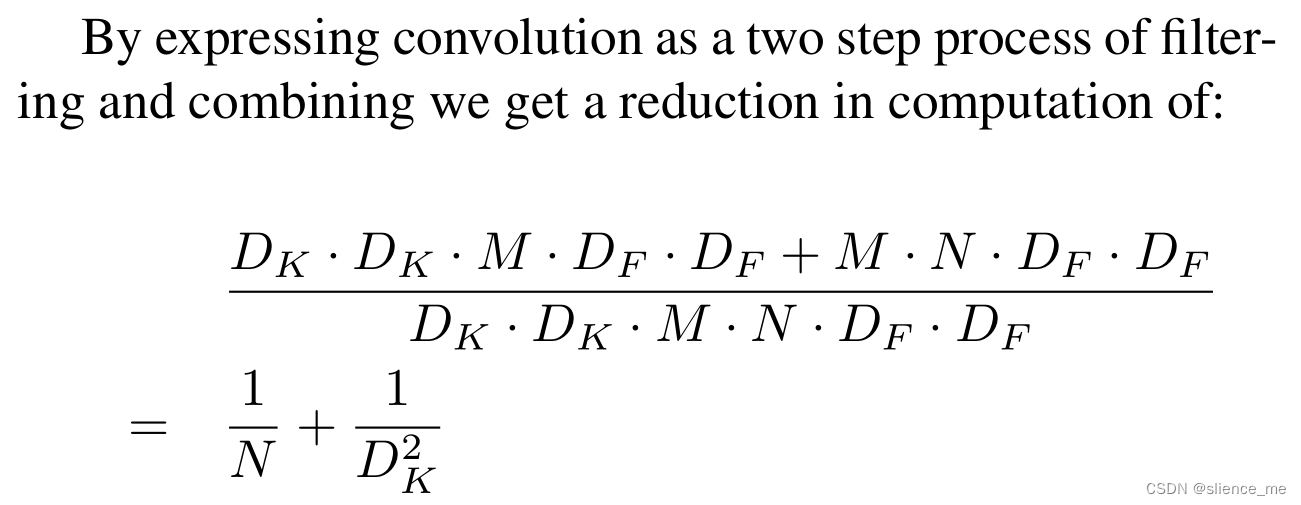一、为什么漏洞叫bug
为什么漏洞的英文是bug,众所周知bug有虫子的意思,这其实有一个很有名的故事。
1947年,计算机科学的先驱格蕾丝·霍普(Grace Hopper)和她的团队在使用哈佛大学的马克二电脑时,发现了一个故障。他们检查机器时,在其中一个继电器里找到了一只飞蛾,这只飞蛾卡在了机器的部件中,导致电脑出错。他们将这只飞蛾移除,并在日志中记录了这个事件,写下了"bug"这个词。


因此,这个词就被用来形象地描述导致技术设备或软件出现问题的缺陷。
然而,值得注意的是,"bug"这个词作为故障的隐喻使用,其实早在电脑和电子设备之前就已经存在了。例如,19世纪的发明家托马斯·爱迪生就在他的通信中使用了"bug"这个词来描述一些技术上的难题或者故障。因此,虽然霍普的故事让这个词变得更加知名,但它作为技术故障的同义词在电脑产生之前就已经被使用了。
对应的debug就变成了调试。
有趣的是在许多编程编辑器和编译器中,调试(debugging)功能的图标常常采用一只虫子的形象。由于“debugging”字面意思就是“除虫”,因此使用虫子作为图标既幽默又形象地反映了这一过程——即检测并修复编程代码中的bug。
二、调试是什么
调试(debug/debugging)是软件开发中的一个关键过程,它涉及识别、检查、定位和修正软件程序中的错误或称为“bug”的缺陷。调试的目的是确保程序按照期望正确运行,并且解决任何可能导致程序崩溃、产生不正确结果或者表现出不预期行为的问题。
调试是一个可能既复杂又耗时的过程,它需要程序员有良好的逻辑思维能力、对代码的深入理解以及对可能出现问题的系统部分有敏锐的洞察力。通过调试,开发者能够确保软件的质量,提升用户体验,减少未来可能出现的问题。
程序员在进行代码调试的时候可以被比喻为侦探。每一段代码都像是一个潜在的线索,每一个异常都可能是犯罪现场的蛛丝马迹。当程序不按预期运行时,程序员就要开始他们的侦探工作,仔细检查代码库,寻找导致问题的源头。
他们会审查变量、跟踪函数调用、监视内存使用情况,并且利用断点来逐步执行代码,就像侦探在犯罪现场搜集证据一样。他们需要逻辑推理和细致观察,推敲每一个逻辑分支,解读每一行代码背后的意图,以期揭开导致软件故障的秘密。
调试的过程充满了挑战,它要求程序员不仅要有深厚的技术知识,还要有像侦探一样的耐心和洞察力,以便能够解决那些最棘手的编程之谜。
是否曾有过长时间埋首于代码,却苦于无法定位那个狡猾的错误?是否曾经用尽目力审视每一行代码,试图捕捉那个潜藏的bug?是否因为无法追踪到问题的根源而感到挫败?让我们一起尝试这种更好用的调试方法吧!
三、调试
这里用的编译器是Visual Studio 2022
1、调试基本步骤
(1)发现程序错误
(2)以隔离、消除等方式对错误进行定位
(3)确定错误产生的原因
(4)提出纠正错误的解决方法
(5)对程序错误予以改正、重新测试
2、debug和release的区别
debug称为调试版本,它包含调试信息,并且不做任何优化,以便程序员调试程序。
release称为发布版本,它通常是进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户很好地使用。

在选择debug版本后运行程序,对应的路径下就会产生debug文件夹:
![]()
debug文件夹中有相关可执行程序:

在选择release版本后运行程序,对应的路径下就会产生release文件夹:
![]()
release文件夹中有相关可执行程序:
![]()
可以看到release版本的可执行程序内存大小更小,因为它没有包含各种包含调试信息。所以在release版本下是没法正常调试的。
#include <stdio.h>
int main()
{
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", i);
}
return 0;
}如果选择release版本,再进行调试,监视局部变量时会发现:

如果选择debug版本,再进行调试,监视局部变量时是正常的:

而且在release版本下是无法进行逐步调试的,程序会直接运行跳过很大一个代码块。不只有这些区别,在反汇编等方面也有一些区别。
所以我们在进行调试时要选择debug版本。
3、调试相关的快捷键
F5
启动调试,经常是用来直接跳到下一个断点处。
F9
创建断点和取消断点。
在程序中设置断点是调试过程的一个基本而强大的功能。断点的作用主要包括:
-
暂停执行:断点允许程序员指定一个特定的代码位置,当程序执行到这个位置时,它会暂停运行。这意味着可以在代码执行到某一行时立即停下来,而不是等到程序完全运行结束或者出现错误后才停止。
-
检查程序状态:一旦程序暂停,程序员可以检查和评估程序的当前状态,包括变量的值、内存状态、调用栈和其他重要的调试信息。这有助于了解程序的行为和查找可能出错的原因。
-
控制执行流程:通过设置断点,程序员可以控制程序执行的流程,逐步执行(stepping)代码来观察程序的每一步行为,这有助于识别出问题发生的确切位置。
-
条件调试:许多调试工具允许设置条件断点,即只有当满足特定条件时,程序才会在断点处暂停。这使得调试工作更加高效,尤其是在处理需要在特定情况下才出现的错误时。
-
减少调试时间:通过合理地放置断点,程序员可以快速跳过他们确定没有问题的代码部分,直接关注可能出现问题的区域,这样可以节省寻找bug的时间。
设置断点是一种无需在代码中添加临时调试代码(例如打印语句)的调试方法。它提供了一种干净、可控且不非常侵入性的方式来观察程序的内部工作,使调试过程更加直观和高效。
条件断点
#include <stdio.h>
int main()
{
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", i);
}
return 0;
}假设要测试第六次循环,跳过前五次循环,可以在循环体内加一个条件断点,设置i == 5,即当第六次循环时停止。


这时按下F5(如若不行,则按Fn + F5)之后,就直接到达第六次循环:


F10
逐过程,通常用来处理一个过程,一个过程可以是一次函数调用,或者是一条语句。不会进入函数内部。

F11
逐语句,就是每次都执行一条语句,但是这个快捷键可以使我们的执行逻辑进入函数内部(这是最常用的)。

Ctrl + F5
开始执行(不调试),如果你想让程序运行起来而不进行调试就可以用这个快捷键。
4、查看程序当前信息
(1)查看变量的值
#include <stdio.h>
int main()
{
int a = 10;
printf("%d\n", a);
return 0;
}调试开始之后,才能看到窗口设置。

在蓝色框的三个窗口都可以看到变量的值。

自动窗口可以自动检测变量,直接显示上下文相关变量,不用手动输入变量。

局部变量窗口也是自动显示上下文相关变量的。

监视窗口中的变量虽然是手动输入的,但是在脱离变量作用范围时也能观察,这个更加实用。
在查看传递到函数中的数组的值时:
#include <stdio.h>
void test(int a[])
{
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", a[i]);
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
test(arr);
return 0;
}F11进行到函数内部时,在监视窗口输入a,只能看到数组首元素一个值:

在a后面加逗号和个数可以解决:

(2)查看内存
查看内存的窗口同样在调试窗口中


可以看地址对应的数据。
#include <stdio.h>
int main()
{
int i = 0x11223344;
return 0;
}
可以点击这个两个三角形,调整现实的列数,一般是用4列,4列正好4字节,一个整型的大小。

这里的数据都是以十六进制显示的。

(3)查看调用堆栈
调用堆栈可以清晰地看到函数调用关系。
#include <stdio.h>
void test2()
{
printf("6\n");
}
void test1()
{
test2();
}
int main()
{
test1();
return 0;
}

可以选择显示外部代码,可以看到主调函数调用main函数,以及一系列函数的调用。

在调用堆栈窗口右击鼠标可以看到更多选项:
(4)查看汇编信息
汇编信息可以更清楚地了解程序,从程序底层了解程序。
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int res = a + b;
printf("%d\n", res);
return 0;
}程序调试起来后可以在调试窗口找到反汇编,这里可以转到反汇编。

或者程序调试起来后在代码段右击鼠标,可以转到反汇编。

汇编代码
#include <stdio.h>
int main()
{
00007FF639742AE0 push rbp
00007FF639742AE2 push rdi
00007FF639742AE3 sub rsp,148h
00007FF639742AEA lea rbp,[rsp+20h]
00007FF639742AEF lea rcx,[__39EA4C76_test@cpp (07FF639751008h)]
00007FF639742AF6 call __CheckForDebuggerJustMyCode (07FF639741352h)
int a = 1;
00007FF639742AFB mov dword ptr [a],1
int b = 2;
00007FF639742B02 mov dword ptr [b],2
int res = a + b;
00007FF639742B09 mov eax,dword ptr [b]
00007FF639742B0C mov ecx,dword ptr [a]
00007FF639742B0F add ecx,eax
00007FF639742B11 mov eax,ecx
00007FF639742B13 mov dword ptr [res],eax
printf("%d\n", res);
00007FF639742B16 mov edx,dword ptr [res]
00007FF639742B19 lea rcx,[string "%d\n" (07FF639749BD8h)]
00007FF639742B20 call printf (07FF6397413B6h)
return 0;
00007FF639742B25 xor eax,eax
}
00007FF639742B27 lea rsp,[rbp+128h]
00007FF639742B2E pop rdi
00007FF639742B2F pop rbp
00007FF639742B30 ret这里还有一些编译器加的一些调试或者其他的汇编代码,不太方便观察的话可以进行下面的设置操作:
找到解决方案管理器:

鼠标右击自己的解决方案,点击属性:

出现属性页:

这时再转到反汇编:
#include <stdio.h>
int main()
{
00007FF7FDF61840 push rbp
00007FF7FDF61842 push rdi
00007FF7FDF61843 sub rsp,148h
00007FF7FDF6184A lea rbp,[rsp+20h]
int a = 1;
00007FF7FDF6184F mov dword ptr [a],1
int b = 2;
00007FF7FDF61856 mov dword ptr [b],2
int res = a + b;
00007FF7FDF6185D mov eax,dword ptr [b]
00007FF7FDF61860 mov ecx,dword ptr [a]
00007FF7FDF61863 add ecx,eax
00007FF7FDF61865 mov eax,ecx
00007FF7FDF61867 mov dword ptr [res],eax
printf("%d\n", res);
00007FF7FDF6186A mov edx,dword ptr [res]
00007FF7FDF6186D lea rcx,[string "%d\n" (07FF7FDF69C24h)]
00007FF7FDF61874 call printf (07FF7FDF61195h)
return 0;
00007FF7FDF61879 xor eax,eax
}
00007FF7FDF6187B lea rsp,[rbp+128h]
00007FF7FDF61882 pop rdi
00007FF7FDF61883 pop rbp
00007FF7FDF61884 ret(5)查看寄存器信息
可以查看当前运行环境的寄存器使用情况。
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int res = a + b;
printf("%d\n", res);
return 0;
}可以在调试窗口中找到寄存器窗口:

配合汇编更好观察(这里是32位平台,从寄存器名字和数据长度可以看出):

配合汇编更(这里是64位平台,从寄存器名字和数据长度可以看出):

在知道寄存器的名字的情况下,也可以在监视窗口中观察寄存器的信息:

这里显示的值是十进制,可以在监视窗口中右击鼠标,选择以十六进制显示:

四、实例
1、实例一
求1! + 2! + ... + n!的值
#include <stdio.h>
int main()
{
int n = 0;
scanf("%d", &n);
int i = 1;
int j = 1;
int res = 1;
int sum = 0;
for (i = 1; i <= n; i++)
{
for (j = 1; j <= i; j++)
{
res *= j;
}
sum += res;
}
printf("%d\n", sum);
return 0;
}这里有一个很明显的错误,在运行时,我们使用3作为测试数据输入,运行结果为:

明显是错误的,因为1! + 2! + 3! = 1 + 2 + 6 = 9。
错误就是res在每次循环没有重置为一,导致答案加了之前的数据,以至于答案偏大。
这里假设我们没发现这个错误,在发现运行结果错误后,我们及时进行逐语句(按F10,如若不行,请按Fn + F10)调试:

在进行到外层循环的第三轮时,我们发现,res的值不应该是2,而应该是1,原来是res的值没有重置为一,所以我们发现了错误。

改正后的代码:
#include <stdio.h>
int main()
{
int n = 0;
scanf("%d", &n);
int i = 1;
int j = 1;
int res = 1;
int sum = 0;
for (i = 1; i <= n; i++)
{
res = 1;
for (j = 1; j <= i; j++)
{
res *= j;
}
sum += res;
}
printf("%d\n", sum);
return 0;
}2、实例二
#include <stdio.h>
int main()
{
int i = 0;
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
for (i = 0; i <= 12; i++)
{
arr[i] = 0;
printf("6\n");
}
return 0;
}只是简单的看了这段代码,发现是越界访问数组,可是当我们将程序运行(32位平台)起来后会发现这个程序是死循环。

在调试时我们发现在i等于12时即第13轮循环时,arr[i] = 0;这个操作使i变成了0,后面还会循环出现这种状况导致无限循环。
实际上在i变化的同时,arr[12]也在变化,实际上i的地址和arr[12]的地址是同一个所以i和arr[12]的空间实际上是同一个。
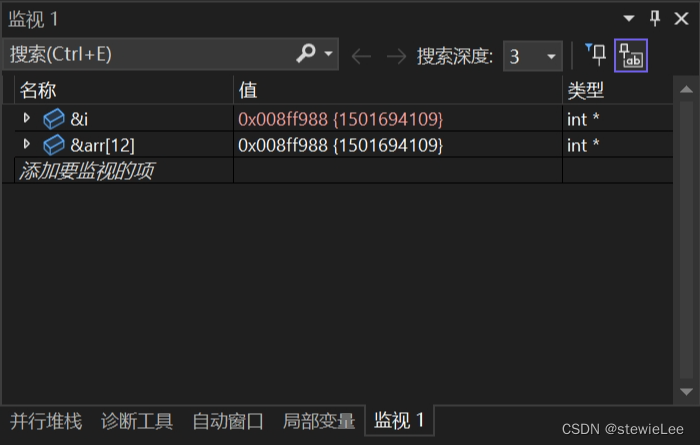
所以会导致这样的死循环,这种错误如果不调试的话是很难发现的。

这里的一个小格是一个整型的大小。
五、如何写出易于调试的代码
1、添加必要的注释
2、避免一些陷阱
3、良好的风格
4、使用assert函数
5、使用const修饰变量
1、assert函数
在C语言中,assert函数是一种用来辅助调试程序的宏,定义在assert.h头文件中。它用于检查程序中的假设是否为真,如果假设为假(即表达式的值为0),assert会打印一条错误信息到标准错误流,并终止程序的执行。如果假设为真,程序会继续进行。
assert函数的用法非常简单。只需包含assert.h头文件,并在代码中加入assert宏,后跟需要检查的表达式。例如:
#include <assert.h>
int main() {
int a = 10;
assert(a == 10); // 如果a等于10,则程序继续执行;如果a不等于10,程序终止,打印错误信息
assert(a > 10); // 如果a不大于10,则打印错误信息并终止程序,如果a大于10,程序继续进行
// ... 其他代码 ...
return 0;
}如果assert宏的参数表达式结果为非零(表达式为真),则assert不会执行任何操作。如果表达式结果为零(表达式为假),assert会打印包含以下信息的错误消息:
- 失败的表达式本身
- 发生错误的源文件名
- 发生错误的源代码行号
- 发生错误的函数名(C99标准之后)
#include <assert.h>
int main()
{
int a = 1;
assert(a == 0);
return 0;
}打印错误:

使用assert的好处在于,它可以在开发阶段帮助程序员检测逻辑错误,但是它也有一个缺点:在发布的产品代码中,assert会增加不必要的性能开销。因此,在编译发布版本的代码时,通常会通过定义NDEBUG宏来禁用assert。这可以在编译命令中通过定义宏来实现,或者在包含assert.h之前的代码中定义。
#define NDEBUG
#include <assert.h>定义了NDEBUG宏后,assert宏实际上不会执行任何操作,因此不会产生任何性能开销。
#define NDEBUG
#include <assert.h>
int main()
{
int a = 1;
assert(a == 0);
return 0;
}运行之后不会输出错误信息。
使用assert是一种很好的调试习惯,可以帮助迅速定位程序中的错误。不过,它不应该被用作常规的错误处理机制,而只应该用于检测程序中的逻辑错误和不应该发生的情况。
2、例子
仿照库函数strcpy写一个类似的函数实现这种功能。
#include <stdio.h>
#include <assert.h>
void my_strcpy(char* dest, char* src)
{
assert(dest != NULL);//防止传参指针是空指针
assert(src != NULL);
while (*src != '\0')//复制内容
{
*dest = *src;
dest++;
src++;
}
*dest = *src;//将\0复制
}
int main()
{
char ch1[10] = "nihao";
char ch2[10];
my_strcpy(ch2, ch1);
printf("%s\n", ch2);
return 0;
}3、const修饰
(1)引子
对于上面的例子,我们发现在库函数中strcpy的参数是:

这里的源字符串指针是使用const修饰的。
为社么呢?
实际上是防止两个变量赋值搞反。
如果上个例子中将变量赋值写反,就像下面这样,如果不用const修饰的话,编译器可能不报错。如果使用const修饰,则会无法编译,编译器会直接报错。
*src = *dest;修改后的代码:
#include <stdio.h>
#include <assert.h>
void my_strcpy(char* dest, const char* src)
{
assert(dest != NULL);//防止传参指针是空指针
assert(src != NULL);
while (*src != '\0')//复制内容
{
*dest = *src;
dest++;
src++;
}
*dest = *src;//将\0复制
}
int main()
{
char ch1[10] = "nihao";
char ch2[10];
my_strcpy(ch2, ch1);
printf("%s\n", ch2);
return 0;
}(2)介绍
在C语言中,const关键字用于修饰变量,表示变量的值不应被改变。使用const修饰符有多个好处:
-
类型安全: 当你将
const用于函数参数时,如const char* src,这告诉编译器和阅读代码的人,这个参数指向的数据不应该被该函数修改。这提供了额外的类型安全,因为如果函数内部的代码尝试修改src指向的内容,编译器将报错。 -
自文档化:
const关键字作为函数接口的一部分有助于自我文档化。人们立即可以看出src是不应该改变的,而dest因为没有const修饰,是可以被修改的。 -
优化: 编译器可以利用
const关键字进行优化。因为编译器知道某些数据是不变的,它可以做出一些优化决策,比如将const数据放在只读段中。 -
保护数据: 当你使用指针作为函数参数传递大型结构或数组时,
const可以确保传入的数据在函数内部不会被意外修改,从而防止潜在的bug和副作用。
简单来说,使用const修饰符是一种良好的编程实践,它有助于提高代码的可读性和健壮性。
(3)细节
在C语言中,const关键字用来修饰变量、数组或者指针,以指示它们的值不应该被修改。当用于指针时,const可以用于指针自身、指针所指向的数据,或者同时用于两者。具体来说:
1、指针指向的内容为常量 (const修饰的是指针指向的类型):
const char i = '\0';
const char* ptr = &i;同时也可以这样表示,只不过第一种表示方式更常见:
const char i = '\0';
char const* ptr = &i;这里ptr是一个指向const char的指针。这意味着,你不能通过ptr来修改它所指向的内容,实际上这里的const char*类型的指针也不仅可以指向const char类型的数据,也可以指向char类型的变量,当指向char类型的变量时,虽然不能通过ptr改变变量的值,但是可以直接用char类型的变量名改变变量的值,即对变量名直接赋值。然而,指针ptr本身不是常量,所以你可以改变指针ptr来指向另一个地址。
2、指针自身为常量(const修饰的是指针自身):
char i = '\0';
char* const ptr = &i;这里ptr是一个指向char的常量指针。这意味着,ptr一旦被初始化后,就不能再指向另一个地址,但是你可以修改ptr所指向的内容。
3、指针和所指的内容都为常量(const同时修饰指针指向的类型和指针自身):
const char i = '\0';
const char* const ptr = &i;这里ptr是一个指向const char的常量指针。这意味着你既不能修改ptr指向的地址,也不能通过ptr修改它所指向的内容。
(4)小调整
对于上面的例子,我们采用的返回值是void,实际上strcpy的返回值是char *类型:
然而,返回char *类型又有什么好处呢,返回char *类型实际上是返回目标内存空间的起始地址,这样可以实现链式访问,即一个函数的返回值作为另一个函数的参数。
#include <stdio.h>
#include <assert.h>
char* my_strcpy(char* dest, const char* src)
{
assert(dest != NULL);//防止传参指针是空指针
assert(src != NULL);
char* p = dest;//将目标空间初始地址保存,下面dest的值会发生改变
while (*src != '\0')//复制内容
{
*dest = *src;
dest++;
src++;
}
*dest = *src;//将\0复制
return p;
}
int main()
{
char ch1[10] = "nihao";
char ch2[10];
printf("%s\n", my_strcpy(ch2, ch1));//实现链式访问
return 0;
}六、容易出现的错误
1、编译型错误
一般是语法或词法错误,编译器会提示,很容易找到了。

2、链接错误
一般是标识符拼写错误,编译器只会报错,不会提示到哪一行。
#include <stdio.h>
int main()
{
int a = 0;
int b = 1;
int res = Add(a, b);
printf("%d\n", res);
return 0;
}这里调用了Add函数,但是未定义Add函数。
这时会报错:

这时可以用 Ctrl + f 来搜索Add函数的调用位置以及定义:

3、运行时的错误
能正常运行,但是运行结果不正确。
这个就要通过上面的一些调试方法来进行调试排错。
七、结语
这些只是一些较为简单的调试方法,后面会接着更新一些进阶的调试方法。
对于初学者可能大部分时间在写代码,少部分时间在调试;而对于程序员则是大部分时间在调试,少部分时间在写代码。
调试要多上手练习。