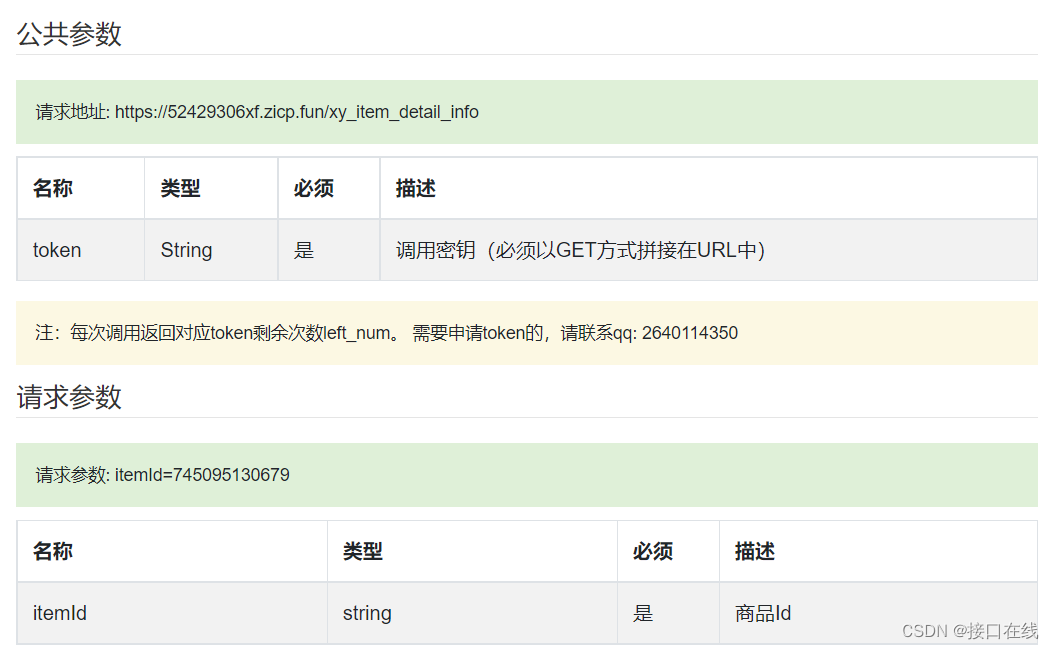
一、【说在前面】
Ansible Filter一般被称为滤波器或者叫过滤器。
这个东西初次听到以为是什么科学计算的东西,但是想来ansible不太可能有什么滤波操作,所以这个东西本质是一个数值筛选器,内置函数,本质是一个为了做区别化的工具,比如根据不同的机器名做不同操作,根据预先设定的值做区别化对待。
这篇文章介绍一下ansibe常用的过滤器是怎么用的,有什么作用,官网文档更详细,但看起来例子比较单薄,本文本质是笔者回顾Ansible的学习笔记,希望这篇文章能发挥一些补充作用。
官网:Using filters to manipulate data — Ansible Documentation
二、【过滤器介绍】
1-15可见笔者的另一篇文章
Ansible Filter滤波器的使用(一)-CSDN博客
16. 数学过滤器 (calculating numbers math filters):
用于进行数学运算,如加减乘除、对数、幂等。
# 例1 在1.9版本中新增了一些科学计算
# 如你所见log是对数,默认以e为底
# pow是幂计算
# root是开方,默认开二次方根
{{ 8 | log }}
# => 2.0794415416798357
Get the base 10 logarithm:
{{ 8 | log(10) }}
# => 0.9030899869919435
Give me the power of 2! (or 5):
{{ 8 | pow(5) }}
# => 32768.0
Square root, or the 5th:
{{ 8 | root }}
# => 2.8284271247461903
{{ 8 | root(5) }}
# => 1.515716566510398217. IP地址过滤器(IP address filters):
该过滤器可以判断是否是合法IP地址,提取CIDR中的IP地址
# 在1.9版本中才有这个
# 例1 判断一个字符串是否是合法IP地址
{{ myvar | ansible.netcommon.ipaddr }}
# 例2 可以指定IP地址版本来检测字符串是否是合法IP
{{ myvar | ansible.netcommon.ipv4 }}
{{ myvar | ansible.netcommon.ipv6 }}
# 例3 可以抽取CIDR中的IP,如下
{{ '192.0.2.1/24' | ansible.netcommon.ipaddr('address') }}
# => 192.0.2.118. 网络命令行过滤器(Network CLI filters)
这个过滤器,简单来讲他会把网络信息根据写好的模板,输出为JSON格式。此功能在2.4版本加入,下面以官网文档为例,说明一下
# 例1 这个命令需要先有一个yaml模板用来捕获数值
# 官网的例子以show vlan命令为例
---
vars: # 这一部分在构造值的结构,这里会影响到最后拿到的JSON结构
vlan:
key: "{{ item.vlan_id }}"
values:
vlan_id: "{{ item.vlan_id }}"
name: "{{ item.name }}"
enabled: "{{ item.state != 'act/lshut' }}"
state: "{{ item.state }}"
keys: # 这里本质是在做一个正则的捕获式,捕获了VLAN_ID,NAME,STATE这些数值用于构建上方的VARS
vlans:
value: "{{ vlan }}"
items: "^(?P<vlan_id>\\d+)\\s+(?P<name>\\w+)\\s+(?P<state>active|act/lshut|suspended)"
state_static:
value: present
# 这里是命令,本质就一行,路径是模板路径
{{ output | ansible.netcommon.parse_cli('path/to/spec') }}
19. 网络XML格式过滤器(Network XML filters)
这个东西本质是把XML格式的输出转化为JSON格式的输出,笔者对XML不甚了解,这里只做简单搬运,不过值得一提的是捕获变量用的是XPATH,这个语法在做爬虫的时候非常有用。
# 规范文件
vars:
vlan:
vlan_id: "{{ item.vlan_id }}"
name: "{{ item.name }}"
desc: "{{ item.desc }}"
enabled: "{{ item.state.get('inactive') != 'inactive' }}"
state: "{% if item.state.get('inactive') == 'inactive' %} inactive {% else %} active {% endif %}"
keys:
vlans:
value: "{{ vlan }}"
top: configuration/vlans/vlan
items:
vlan_id: vlan-id
name: name
desc: description
state: ".[@inactive='inactive']"
# 执行命令片段,路径是上方文件的路径
{{ output | ansible.netcommon.parse_xml('path/to/spec') }}
# 官网给出的一个XML格式的,可作为该函数输入的一个XML数据
<rpc-reply>
<configuration>
<vlans>
<vlan inactive="inactive">
<name>vlan-1</name>
<vlan-id>200</vlan-id>
<description>This is vlan-1</description>
</vlan>
</vlans>
</configuration>
</rpc-reply>20. VLAN过滤器(Network VLAN filter)
这个本质是一个多个数字变成数字段的工具,举个例子一说明就看得很清楚了
# 如你所见,我这边有一堆VLAN ID
# 然后用一个这个vlan过滤器,可以把邻近的多个变成一个段
{{ [3003, 3004, 3005, 100, 1688, 3002, 3999] | ansible.netcommon.vlan_parser }}
# 输出['100,1688,3002-3005,3999']21. 哈希和加密过滤器(Hashing and encrypting strings and passwords)
本质就是一个生成摘要用的,并且可以支持自己加盐
# 例1 生成一个SHA1,这种散列是160位
{{ 'test1' | hash('sha1') }}
# => "b444ac06613fc8d63795be9ad0beaf55011936ac"
# 例2 根据字符串生成一个MD5
{{ 'test1' | hash('md5') }}
# => "5a105e8b9d40e1329780d62ea2265d8a"
# 例3 生成一个字符串校验和
{{ 'test2' | checksum }}
# => "109f4b3c50d7b0df729d299bc6f8e9ef9066971f"
# 例4 支持一些小众的哈希类型
{{ 'test2' | hash('blowfish') }}
# 例5 sha512散列
# 你可以注意到password做了sha256但是例子1中只做了SHA1
# 这一般是考虑到密码的安全性,防止被彩虹表撞出来。
{{ 'passwordsaresecret' | password_hash('sha512') }}
# => "$6$UIv3676O/ilZzWEE$ktEfFF19NQPF2zyxqxGkAceTnbEgpEKuGBtk6MlU4v2ZorWaVQUMyurgmHCh2Fr4wpmQ/Y.AlXMJkRnIS4RfH/"
# 例6 加盐的摘要生成
# 一般来讲,做这种摘要,最好都加一下盐,更安全
# 加盐的本质是增加哈希密码的随机性和复杂性
# wifi的WPA2密码就是根据SSID来做的加盐
{{ 'secretpassword' | password_hash('sha256', 'mysecretsalt') }}
# => "$5$mysecretsalt$ReKNyDYjkKNqRVwouShhsEqZ3VOE8eoVO4exihOfvG4"
# 例7 随机盐值
{{ 'secretpassword' | password_hash('sha512', 65534 | random(seed=inventory_hostname) | string) }}
# => "$6$43927$lQxPKz2M2X.NWO.gK.t7phLwOKQMcSq72XxDZQ0XzYV6DlL1OD72h417aj16OnHTGxNzhftXJQBcjbunLEepM0"
# 例8 在2.7版本中,支持加入哈希轮次,这里迭代了1w轮
{{ 'secretpassword' | password_hash('sha256', 'mysecretsalt', rounds=10000) }}
# => "$5$rounds=10000$mysecretsalt$Tkm80llAxD4YHll6AgNIztKn0vzAACsuuEfYeGP7tm7"
# 例9 同样还可以指定摘要算法的版本
# 比如这里选用了blowfish的2b版本,使用12345……作为盐值
{{ 'secretpassword' | password_hash('blowfish', '1234567890123456789012', ident='2b') }}
# => "$2b$12$123456789012345678901uuJ4qFdej6xnWjOQT.FStqfdoY8dYUPC"22. Vault过滤器(Vault filter)
vault本质是保证敏感信息不泄露的管理工具,我们可以在剧本中取用我们需要的密钥。
# 加密剧本,用了一个随机盐值
# vaultsecret这个值一般是运行前提供的
- name: save templated vaulted data
template: src=dump_template_data.j2 dest=/some/key/vault.txt
vars:
mysalt: '{{ 2**256|random(seed=inventory_hostname) }}'
template_data: '{{ secretdata|vault(vaultsecret, salt=mysalt) }}'
# 解密剧本
- name: save templated unvaulted data
template: src=dump_template_data.j2 dest=/some/key/clear.txt
vars:
template_data: '{{ secretdata|unvault(vaultsecret) }}'
23. 注释过滤器ansible.builtin.comment(Adding comments to files)
用来写注释的,支持多种格式,比如
{{ "C style" | comment('c') }}
{{ "C block style" | comment('cblock') }}
{{ "Erlang style" | comment('erlang') }}
{{ "XML style" | comment('xml') }}同时也支持添加前后缀,比如
# 例1
{{ "My Special Case" | comment(decoration="! ") }}
# 会输出以下
# !
# ! My Special Case
# !
# 例2
{{ "Custom style" | comment('plain', prefix='#######\n#', postfix='#\n#######\n ###\n #') }}
# 输出:
#######
#
# Custom style
#
#######
###
#
还支持直接对变量变更为注释
# 例3 也可以直接对一个变量进行comment,会得到这个变量的注释
{{ ansible_managed | comment }}
# 比如这个语句对一个值做了comment,那么会得到下面的注释后的文本
# [defaults]
#
# ansible_managed = This file is managed by Ansible.%n
# template: {file}
# date: %Y-%m-%d %H:%M:%S
# user: {uid}
# host: {host}24. URL 过滤器(URL filter)
这个是对文本做URL格式化,或者从URL取一些值出来
# 例1 格式化utf8文本
{{ 'Trollhättan' | urlencode }}
# => 'Trollh%C3%A4ttan'
# 例2 切分URL方法
# 按照官网的说法,在2.4版本中,引入了这个ansible.builtin.urlsplit
# 这个可以很方便的提取URL中的 fragment, hostname, netloc,
# password, path, port, query, scheme, username这些值
# 具体可以看下面的例子,本人认为这个非常好用
{{ "http://user:password@www.acme.com:9000/dir/index.html?query=term#fragment" | urlsplit('hostname') }}
# => 'www.acme.com'
{{ "http://user:password@www.acme.com:9000/dir/index.html?query=term#fragment" | urlsplit('netloc') }}
# => 'user:password@www.acme.com:9000'
{{ "http://user:password@www.acme.com:9000/dir/index.html?query=term#fragment" | urlsplit('username') }}
# => 'user'
{{ "http://user:password@www.acme.com:9000/dir/index.html?query=term#fragment" | urlsplit('password') }}
# => 'password'
{{ "http://user:password@www.acme.com:9000/dir/index.html?query=term#fragment" | urlsplit('path') }}
# => '/dir/index.html'
{{ "http://user:password@www.acme.com:9000/dir/index.html?query=term#fragment" | urlsplit('port') }}
# => '9000'
{{ "http://user:password@www.acme.com:9000/dir/index.html?query=term#fragment" | urlsplit('scheme') }}
# => 'http'
{{ "http://user:password@www.acme.com:9000/dir/index.html?query=term#fragment" | urlsplit('query') }}
# => 'query=term'
{{ "http://user:password@www.acme.com:9000/dir/index.html?query=term#fragment" | urlsplit('fragment') }}
# => 'fragment'
{{ "http://user:password@www.acme.com:9000/dir/index.html?query=term#fragment" | urlsplit }}
# =>
# {
# "fragment": "fragment",
# "hostname": "www.acme.com",
# "netloc": "user:password@www.acme.com:9000",
# "password": "password",
# "path": "/dir/index.html",
# "port": 9000,
# "query": "query=term",
# "scheme": "http",
# "username": "user"
# }
25. 正则过滤器(ansible.buitin.regex_search)
使用正则表达式处理一些字符串,正则语法比较通用,笔者直接抄官网代码了
# 提取database+数字
{{ 'server1/database42' | regex_search('database[0-9]+') }}
# => 'database42'
# 多行,不区分大小写
{{ 'foo\nBAR' | regex_search('^bar', multiline=True, ignorecase=True) }}
# => 'BAR'
# 内联正则表达式
# i 表示不区分大小写(ignorecase)。
# m 表示多行模式(multiline)
{{ 'foo\nBAR' | regex_search('(?im)^bar') }}
# => 'BAR'
# 使用捕获组的示例
{{ 'server1/database42' | regex_search('server([0-9]+)/database([0-9]+)', '\\1', '\\2') }}
# => ['1', '42']
# 使用命名捕获组<dividend>和<divisor>,并且在之后使用\\g引用他们
{{ '21/42' | regex_search('(?P<dividend>[0-9]+)/(?P<divisor>[0-9]+)', '\\g<dividend>', '\\g<divisor>') }}
# => ['21', '42']可以结合map使用,对列表的每个元素做正则替换
# 在每个列表项前添加 "https://" 前缀的示例:
# 每行都是一个意思
{{ hosts | map('regex_replace', '^(.*)$', 'https://\\1') | list }}
{{ hosts | map('regex_replace', '(.+)', 'https://\\1') | list }}
{{ hosts | map('regex_replace', '^', 'https://') | list }}
# 在每个列表项末尾添加 ":80" 的示例:
# 每行都是一个意思
{{ hosts | map('regex_replace', '^(.*)$', '\\1:80') | list }}
{{ hosts | map('regex_replace', '(.+)', '\\1:80') | list }}
{{ hosts | map('regex_replace', '$', ':80') | list }}还有做转译,避免触发正则的过滤器
# 转译 '^f.*o(.*)$' 为 '\^f\.\*o\(\.\*\)\$'
{{ '^f.*o(.*)$' | regex_escape() }}
这里使用了默认的 re_type='python' 选项,将标准 Python 正则表达式中的特殊字符进行转义。这个功能在 Ansible 2.0 版本引入。
# 同样也是转译,只不过用的是POSIX标准(2.8版本引入):
# 转译 '^f.*o(.*)$' 为 '\^f\.\*o(\.\*)\$'
{{ '^f.*o(.*)$' | regex_escape('posix_basic') }}26. 文件或路径名过滤器()
内置功能,无需额外添加前缀,主要是一些对文件名、路径名等操作
用途:获取文件路径的最后一个名称,即文件名。
示例:{{ path | basename }}
win_basename:
用途:获取 Windows 风格文件路径的最后一个名称(在版本 2.0 中引入)。
示例:{{ path | win_basename }}
win_splitdrive:
用途:将 Windows 文件路径拆分为驱动器和其余部分(在版本 2.0 中引入)。
示例:{{ path | win_splitdrive }}
win_splitdrive | first:
用途:获取 Windows 文件路径的驱动器部分。
示例:{{ path | win_splitdrive | first }}
win_splitdrive | last:
用途:获取 Windows 文件路径的不包含驱动器的其余部分。
示例:{{ path | win_splitdrive | last }}
dirname:
用途:获取路径的目录部分。
示例:{{ path | dirname }}
win_dirname:
用途:获取 Windows 路径的目录部分(在版本 2.0 中引入)。
示例:{{ path | win_dirname }}
expanduser:
用途:扩展包含波浪符(~)的路径(在版本 1.5 中引入)。
示例:{{ path | expanduser }}
expandvars:
用途:扩展包含环境变量的路径。
示例:{{ path | expandvars }}
realpath:
用途:获取链接的真实路径(在版本 1.8 中引入)。
示例:{{ path | realpath }}
relpath('/etc'):
用途:获取链接的相对路径,从指定的起始点开始(在版本 1.7 中引入)。
示例:{{ path | relpath('/etc') }}
splitext:
用途:获取路径或文件名的根和扩展名。
示例:{{ path | splitext }}
splitext | first:
用途:获取路径或文件名的根部分。
示例:{{ path | splitext | first }}
splitext | last:
用途:获取路径或文件名的扩展名部分。
示例:{{ path | splitext | last }}
path_join:
用途:连接一个或多个路径组件。
示例:{{ ('/etc', path, 'subdir', file) | path_join }}27. 字符串控制与操作(Manipulating strings)
主要是一些字符串操作,比如字符串执行shell,字符串转BASE64等
# 引用字符串用于 shell 命令:
- name: Run a shell command
ansible.builtin.shell: echo {{ string_value | quote }}
# 参考文档: ansible.builtin.quote
# 将列表连接成字符串:
{{ list | join(" ") }}
# 将字符串拆分成列表:
{{ csv_string | split(",") }}
# (从版本 2.11 开始支持)
# 处理 Base64 编码的字符串:
# 解码:
{{ encoded | b64decode }}
# 编码:
{{ decoded | string | b64encode }}
# 参考文档: ansible.builtin.b64encode
# 从版本 2.6 开始,你可以定义要使用的编码类型,默认为 utf-8:
{{ encoded | b64decode(encoding='utf-16-le') }}
{{ decoded | string | b64encode(encoding='utf-16-le') }}
# 参考文档: ansible.builtin.b64decode28. UUID过滤器(Managing UUIDs)
这里ansible使用的是UUIDv5,本质是将字符串通过SHA1来生成UUID
# 例1 创建一个带有命名空间的UUIDv5
{{ string | to_uuid(namespace='11111111-2222-3333-4444-555555555555') }}
# 例2 创建带有默认Ansible命名空间的UUIDv5
# 新版本1.9中引入。此使用默认 Ansible 命名空间 '361E6D51-FAEC-444A-9079-341386DA8E2E' 创建 UUIDv5
{{ string | to_uuid }}
# 例3 获取主机上挂载点的逗号分隔列表(例如,"/,/mnt/stuff")
{{ ansible_mounts | map(attribute='mount') | join(',') }}29. 日期过滤器(Handling dates and times)
支持datatime也支持时间戳操作,主要用来做日期相关处理与提取
# 例1 总秒数计算: 这部分计算两个日期之间的总秒数。
# 你可以通过指定日期格式传递自定义格式,否则默认格式为 %Y-%m-%d %H:%M:%S。
{{ (("2016-08-14 20:00:12" | to_datetime) - ("2015-12-25" | to_datetime('%Y-%m-%d'))).total_seconds() }}
# 例2 剩余秒数计算: 这部分计算两个日期之间的差异,但返回的是剩余的秒数。
# 请注意,这不会将年、天、小时等转换为秒数。如果需要转换,可以使用 total_seconds()。
{{ (("2016-08-14 20:00:12" | to_datetime) - ("2016-08-14 18:00:00" | to_datetime)).seconds }}
这个表达式的结果是 "12" 而不是 "132",因为差异是2小时12秒。
# 例3 天数计算: 这部分计算两个日期之间的天数。
# 它返回的是天数,而丢弃了剩余的小时、分钟和秒数。
{{ (("2016-08-14 20:00:12" | to_datetime) - ("2015-12-25" | to_datetime('%Y-%m-%d'))).days }}
# 例4 格式化日期
{{ '%Y-%m-%d %H:%M:%S' | strftime }}
# 输出: "2021-03-19 21:54:09"
# 例5 格式化时间戳
{{ '%Y-%m-%d' | strftime(0) }}
# 输出: "1970-01-01"
# 例6 使用UTC时区
{{ '%H:%M:%S' | strftime(utc=True) }}
# 输出: 当前时间,UTC 时区30. 与kubernetes合用(k8s_config_resource_name)
这个笔者没玩过,先写在这里。
{{ configmap_resource_definition | kubernetes.core.k8s_config_resource_name }}
# 这个过滤器的结果可以用于引用 Pod 规范中的哈希值,例如:
my_secret:
kind: Secret
metadata:
name: my_secret_name
deployment_resource:
kind: Deployment
spec:
template:
spec:
containers:
- envFrom:
- secretRef:
name: {{ my_secret | kubernetes.core.k8s_config_resource_name }}