Transformers 开启了NLP一个新时代,注意力模块目前各类大模型的重要结构。作为刚入门LLM的新手,怎么能不感受一下这个“变形金刚的魅力”呢?
目录
Transformers ——Attention is all You Need
背景介绍
模型结构
位置编码
代码实现:
Attention
Scaled Dot-product Attention
Multi-head Attention
Position-Wise Feed-Forward Networks
Encoder and Decoder
Add & Norm
mask 机制
参考链接
论文链接:Attention Is All You Need
Transformers ——Attention is all You Need
背景介绍
在Transformer提出之前,NLP主要基于RNN、LSTM等算法解救相关问题。这些模型在处理长序列时面临梯度消失和梯度爆炸等问题,且这些模型是串行计算的,运行时间较长。
Transformer 模型的提出是为了摆脱序列模型的顺序依赖性,引入了注意力机制,使得模型能够在不同位置上同时关注输入序列的各个部分,且支持并行计算。该模型的提出对深度学习和自然语言处理领域产生了深远的影响,成为了现代NLP模型的基础架构,并推动了attention 机制在各种任务中的应用。
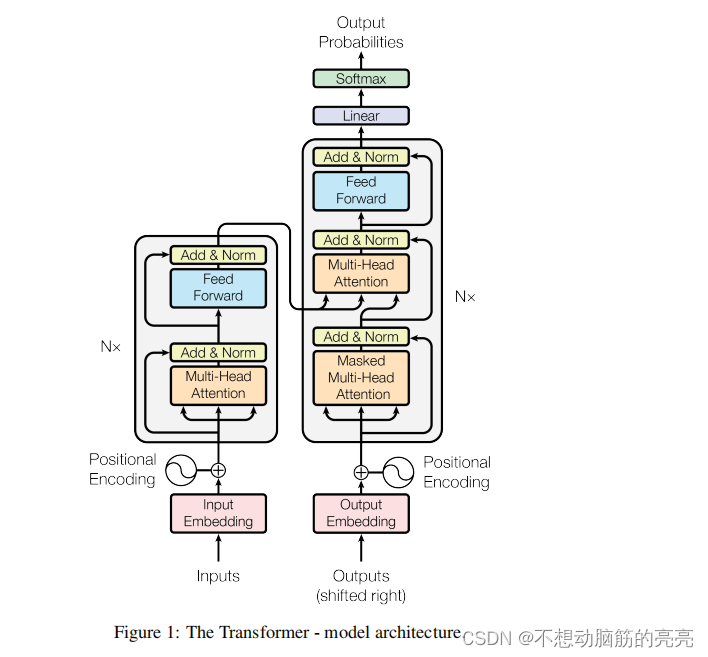
模型结构
位置编码
任何一门语言,单词在句子中的位置以及排列顺序是非常重要的。一个单词在句子的位置或者排列顺序不同,整个句子的意义就发生了偏差。举个例子:
小明欠小王500块
小王欠小明500块
顺序不同,债主关系就发生变化了😑
当采用了Attention之后,句子中的词序信息就会丢失,模型就没法知道每个词在句子中的相对和绝对的位置信息。目前位置编码有多种方法:
(1)整型值标记位置,即第一个token标记为1, 第二个token标记为2。。。以此类推
可能存在的问题:
- 随着序列长度的增加,位置值会越来越大;
- 推理的序列长度比训练时所用的序列长度更长,不利于模型的泛化
(2)用[0,1] 范围标记位置
将位置值的范围限制在[0,1]之内,即在第一种的方法进行归一化操作(除以序列长度)。比如有4个token,那么位置信息就是[0, 0.33, 0.69, 1]。 但这样产生的问题是,当序列长度不同时,token间的相对距离是不一样的。
因此,一个好的位置编码方法应该满足以下特性:
(1)可以表示一个token 在序列中的绝对位置;
(2)在序列长度不同的情况下,不同序列中token 的相对位置/ 距离要保持一直;
(3)可以扩展到更长的句子长度;
Transformers 中选择的是sincos编码法,其公式如下所示:
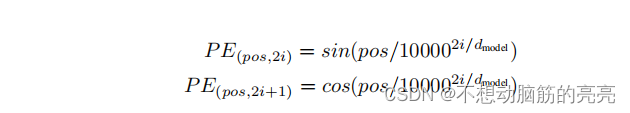
其中,pos 是token在sentence中的位置,i是维度。
代码实现:
假设句子长度是 s, embedding的维度是d, 最终生成的PE的shape是(s, d)。公式的核心是计算, 这里可以借助对数和指数的性质进行如下操作:
所以可以转换成(可对照代码进行推导理解)
class Position_Encoding(nn.Module):
def __init__(self, max_length, d_model):
self.max_length = max_length
self.dim = d_model
pe = torch.zeros(self.max_length, self.dim)
position = torch.arange(0, self.max_length).unsqueeze(1)
div_term = torch.exp( torch.arange(0, self.dim ,2) * (-1) *math.log(10000) / self.dim)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
def forward(self, x):
# input_embedding + position_encoding
#....Attention
Attention 是将query 和key、value映射为输出值,其中query 和 key 计算一个相似度,然后以这个相似度为权重,计算value的加权和,最终得到输出。
Scaled Dot-product Attention
论文中用的是放缩点乘注意力(scaled dot-product attention),其公式是:
其中, 计算时需要用到的矩阵Q(查询),K(键值),V(值)是输入单词的embedding 变换或者 上一个Encoder block的输出 。注意Q、K、V的shape 会存在一定的联系(因为需要做矩阵乘法运算)。
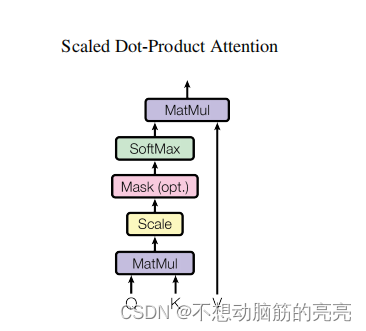
公式中会除以dk的平方根,从而避免内积过大。还有解释是说 softmax 在 绝对值较大的区域梯度较小,梯度下降的速度比较慢。因此希望softmax的点乘数值尽可能小。
论文中解释了为什么点积会变大。假设q 和 k中的元素满足独立分布,且均值是0,方差为1。点积 的均值是0, 方差是dk 。
Multi-head Attention
作者发现,相比直接在dmodel 维度上的 q、k、v进行attention计算 ,使用不同的、可学习的linear function 分别地对q、k、v 进行多次映射(映射的维度是dk, dk, dv) , 然后对每一组映射的q、k、v进行attention 并行计算,并concat得到最终输出。后一种方法更有效。就像卷积层可以用多个卷积核生成多个通道的特征,在Transformers中可以用多组self attention 生成多组注意力的结果,从而增加特征表示。其计算公式和流程图如下:
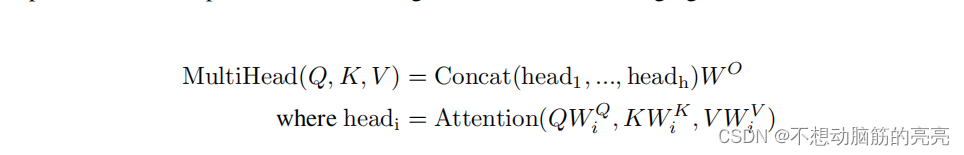

注意: head的数量 * 每一组head中q的维度 = dmodel (输入Q的维度)
Position-Wise Feed-Forward Networks
前馈网络比较简单,是一个两层的全连接层,第一层的激活函数是ReLU,第二层不使用激活函数,对应的公式如下所示:
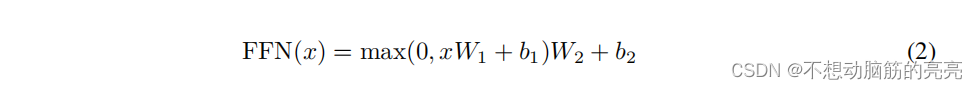
Encoder and Decoder
Transformer 从结构上可以分为Encoder 和Decoder 两个部分,这两者结构上比较类似,但也存在一些差异。
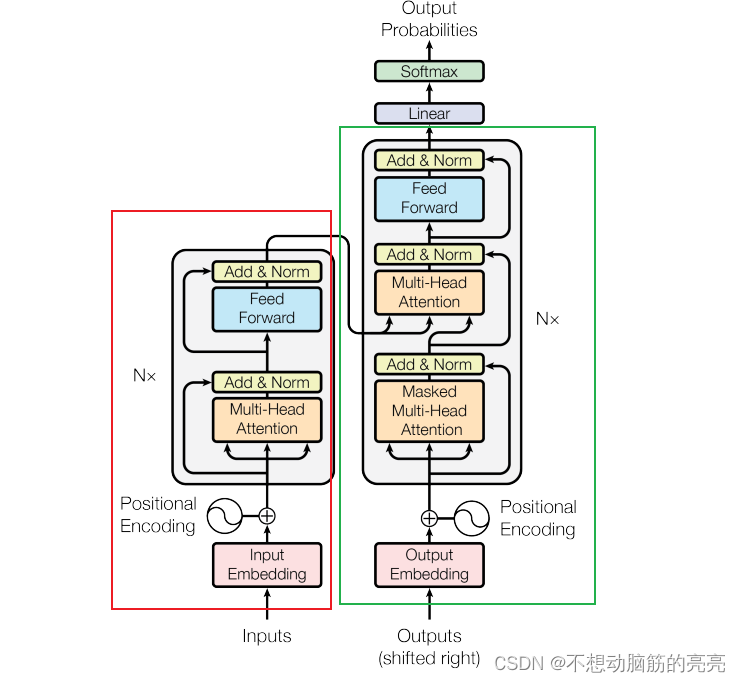
上图红色区域对应的是Encoder部分,可以看出是由 Input Embedding 、Position Encoding 和6层的EncoderLayer组成。 EncoderLayer 主要包括Multi-head Attention, Add&Norm, Feed Forward ,Add&Norm。
上图绿色区域对应的是Decoder部分,相比Encoder,需要注意Decoder中的Multi-head Attention 有所不同。首先是Masked Multi-head Attention, 是为了实现串行推理;第二个Multi-head Attention输入的Q、K、V来自不同的地方,其中Q是Masked Multi-head Attention 的输出, K和V是Encoder 的输出。
Add & Norm
这部分主要由Add 和 Norm 组成,其计算公式如下所示:

Add 是一种残差结构,和ResNet中的是一样的,可以帮助网络收敛。Norm 是指Layer Norm。
mask 机制
Transformers中比较重要的一个知识点就是mask设置。mask主要来源有两个:第一个是填充操作的空白字符(为了保证batch内句子的长度一样会进行padding操作);第二个是因为模拟串行推理需要用到mask(Decoder部分)。
一般情况下, query 和 key都是一样的,但是在Decoder的第二个多头注意力层中,query 来自目标语言,key来自源语言。为了生成mask, 首先要知道query 和 key中<pad> 字符的分布情况,它们的形状为[n, seq_len]。如果某处是True, 表明这个地方的字符是<pad>。
src_pad_mask = x == pad_idx
dst_pad_mask = y == pad_idx为了实现串行推理,即某字符只能知道该字符以及该字符之前的内容,即一个下三角全1矩阵。mask矩阵需要取反,实现方式如下所示:
mask = 1 - torch.tril(torch.ones(mask_shape))最后根据<pad>字符分布情况分别将mask对应的行或者列置1。
参考链接
- GitHub - P3n9W31/transformer-pytorch: Transformer model for Chinese-English translation.
- PyTorch Transformer 英中翻译超详细教程 - 知乎
- Transformer模型详解(图解最完整版) - 知乎