Unet
UNet最早发表在2015的MICCAI上,到2020年中旬的引用量已经超过了9700多次,估计现在都过万了,从这方面看足以见得其影响力。当然,UNet这个基本的网络结构有太多的改进型,应用范围已经远远超出了医学图像的范畴。我们先从最原始的UNet网络模型开始讲解。
1、UNet网络结构
开始时,UNet主要应用在医学图像的分割,并且快速成为大多做医学图像语义分割任务的baseline,而后其他领域的学者和专家也受其启发进行了魔改。当然,也有些同学会说,这个算法中的一些思想很多人在以前也有提出,比如下采样或是多尺度的思想,但是有一个问题,在众多思路中寻找合理的方法进行组合与重构以达到更有效的结果也是一种巨大的创新和进步。
我们首先看一下UNet的网络结构,具体如下图所示:
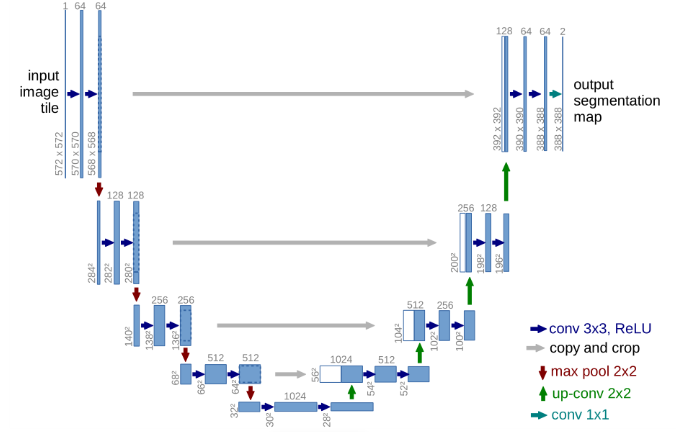
U-net网络结构(上图中以32x32像素的最低分辨率)中每个蓝框对应一个多通道特征图。 通道的数量在框的顶部表示。 x-y尺寸在框的左下边缘提供。 白框表示复制和裁剪(Concat)的特征图。 箭头表示不同的操作。因为此网络整体结构类似于大写的英文字母U,故得名U-Net。
上图已经把UNet的网络结构和思想展现的淋漓尽致了。U-Net网络非常简单,前半部分(左边下采样)作用是特征提取,后半部分(右边)是上采样过程,这是非常典型的Encoder-Decoder结构。在原论文中,下采样过程称为contracting path,它是在通过卷积等操作获取上下文的特征信息;上采样部分被称为expanding path,实际上是在进行目标对象的定位,两部分是对称存在的,同时每层对应(对称结构)使用copy and crop完成skip-connection操作。
2、UNet网络结构高性能的原因分析
2.1 多尺度获得信息
在encoder操作中,采用了5个池化层(在实际应用中也有采用4个池化层的操作),在不断的下采样过程中不断的降低分辨率以获得不同尺度的图像信息,图像的信息由底层信息中的点、线、梯度等信息逐渐向高程信息中的轮廓以及更抽象的信息过度,整个网路完成了“由细到粗”特征的提取与组合,使UNet得到的信息更加全面。
2.2 神来之笔skip connention
做过数字图像处理的同学们应该很清楚一点:图像从低分辨率转高分辨率图像会失真(decoder部分);而高分辨率转低分辨率则失真相对可忽略,也保留了更多的细节信息(encoder部分)!因此,在decoder中上采样过程中就失去了对细节信息的敏感。这个时候skip connection就成为真正的神来之笔,此操作将同层高度的encoder更精准的梯度、点、线等信息直接Concat到同层的decoder中,相当于在判断目标大体区域内添加细节信息,这种操作当然可以使UNet获得更准确的分割结果。
Res-Unet
1、Res-UNet要解决的问题
作者在文章的简介中就提到了视网膜血管分割任务的主要难点和挑战,这也是Res-UNet重点解决的问题,具体如下所示(直接翻译):
小血管缺失:位于血管末端的小血管有时甚至人眼也难以分辨;
视盘区分割结果不理想:通常视盘区域较亮,对比度相对较低,这增加了视网膜血管分割的难度;
血管拓扑结构难以维系:视网膜血管有类似树状的分叉结构,但当血管太薄而无法检测到时,这样的连续的血管结构就很难保持连接(发生断裂);
光照因素:光照不足或过度曝光,包括相机光源引起的光反射,会降低图像对比度,从而导致视网膜血管边界不清晰。
综上所述,由于视网膜血管本身成像的限制与成像过程中光源等干扰,都会使视网膜血管的对比度降低,进而造成血管信息丢失或是直接影响血管的拓扑结构。
2、Res-UNet主要网络结构
从本质上说Res-UNet并不是一个特别难懂的甚至不是特别难以想到的网络结构。在18年之前已经提出了其中经典的Resnet和Attention思想,作者是将这三者做了有机结合。此方法的流程主要所示:
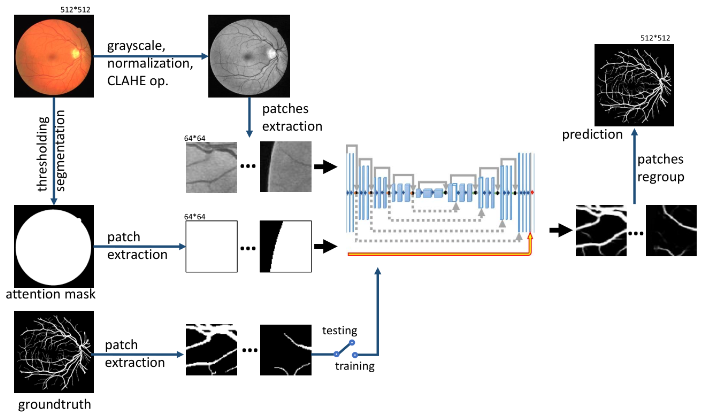
详细的网络结构如下图所示:

2.1 Attention部分
Attention部分其实操作也相对简单,主要是通过提取具有圆形感兴趣区域(ROI)和深色背景。然后使用圆形模板ROI mask M作为加权注意,如图2所示黄色箭头。利用这种加权注意机制,使模型只关注目标ROI区域,而忽略了不相关的噪声背景。这个操作实质上就是注意机制是通过将模型的最后一层的特征图与注意掩模相乘来实现的。ROI mask实际上是将图像进行二值化的过程。
2.2 skip连接部分
根据Resnet的思想将skip连接添加到网络中(见图2的灰色实线部分),此操作增加了网络的深度,根据Resnet中的解释,还可以防止过拟合,提高模型的准确度。
3、引发的思考
3.1 网络结构的思考
Attention部分祛除了ROI区域以外的噪声影响,但是使用CLAHE增强后并没有去除ROI内部的噪声干扰。但是从文章结果来分析,似乎并没有造成较大的影响。
skip连接部分充分说明了Resnet的强大,当然网上有太多的解释和分析, 本人不在此处细讲。
3.2 CLAHE增强与patch操作
CLAHE增强操作必然会增加图像的噪声,当然作者应该进行了滤波操作以保障二值化(ROI)的准确性,也保证网络输入部分图像信号的质量。但是有一个问题值得我们思考,增加噪声就一定会使网络性能变差吗?就算是进行滤波或是其他降噪操作,CLAHE增强带来的噪声是不会完全消失的。噪声是不是还会使网络性能产生较好的性能?我在这一刻想到了反向传播,想到了梯度和激活函数,这是个有趣的点。
原文中的patch操作是无重叠的,最后再拼在一起。实际上无重叠会造成信息的丢失,尤其是上下文信息的丢失,这在一定程度上会影响血管拓扑结构,这也是一个需要关注的地方。
Attention Unet
1、Attention Unet主要目标
作者在摘要与简介中很清楚的表明了要解决的问题以及要达到的目标。具体如下所示:
抑制输入图像中的不相关区域,同时突出特定局部区域的显著特征;
用soft-attention 代替hard-attention的思路(注意:sorf-attention可微,可以微分的attention就可以通过神经网络算出梯度并且前向传播和后向反馈来学习得到attention的权重);
集成到标准UNet网络结构中时要简单方便、计算开销小,最重要的是提高模型的灵敏度和预测的精度;

Unet++
先是提到FCN和UNet已经被广泛应用在医学图像分割中了,并总结了两个限制:
- 最佳的深度是在先验上未知的,需要广泛的架构搜索或不同深度模型的低效率集成来测试
- 跳接施加了不必要的限制性融合方案,仅在编码器和解码器子网的相同比例的特征图上强制融合。
为了缓解这两个问题,作者提出了unet++,可以用于语义分割和实例分割,主要基于三个方面:
- 通过不同深度的U-Net的有效集成来缓解未知的网络深度,这些U-Net可以部分共享一个编码器,并且可以通过深度监督(deep supervision)同时进行共同学习;
- 重新设计跳接以在解码器子网络上聚合语义尺度不同的特征,从而产生高度灵活的特征融合方案;
- 设计一种剪枝方案以加快UNet++的推理速度。
作者使用六个不同的医学图像分割数据集对UNet ++进行了评估,涵盖了多种成像方式,例如计算机断层扫描(CT)、磁共振成像(MRI)和电子显微镜(EM),并证明了:
- UNet++始终优于基线模型,用于跨不同数据集和骨干架构进行语义分割的任务;
- UNet++增强了各种尺寸对象的分割质量,这是对固定深度UNet的改进;
- Mask RCNN++(具有UNet++设计的Mask R-CNN)在执行实例分割任务方面优于原始Mask R-CNN;
- 剪枝过的UNet++模型可实现显着的加速,同时仅显示出适度的性能下降。
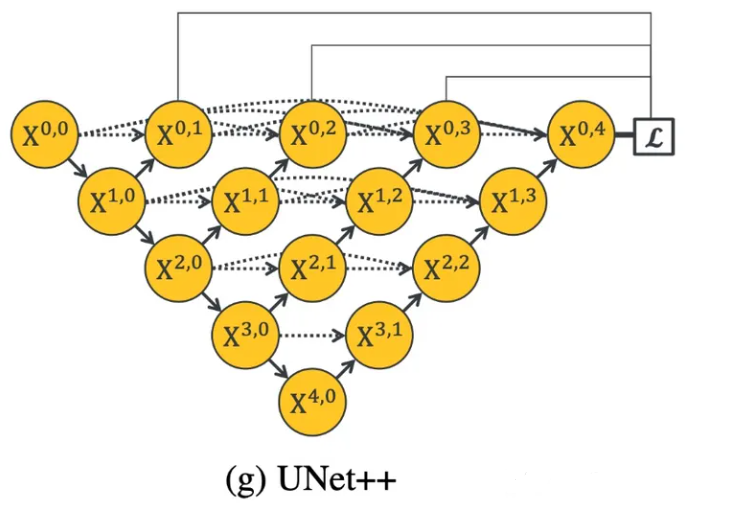
UNet++由不同深度的U-Net组成,其解码器通过重新设计的跳接以相同的分辨率密集连接。 UNet++中引入的体系结构更改具有以下优点。首先,UNet++不易明确地选择网络深度,因为它在其体系结构中嵌入了不同深度的U-Net。所有这些U-Net都部分共享一个编码器,而它们的解码器则交织在一起。通过在深度监督下训练UNet++,可以同时训练所有组成的U-Net,同时受益于共享的图像表示。这种设计不仅可以提高整体分割性能,而且可以在推理期间修剪模型。其次,UNet++不会受到不必要的限制性跳接的限制,在这种情况下,只能融合来自编码器和解码器的相同比例的特征图。UNet++中引入的经过重新设计的跳接在解码器节点处提供了不同比例的特征图,从而使聚合层可以决定如何将跳接中携带的各种特征图与解码器特征图融合在一起。通过以相同的分辨率密集连接组成部分U-Net的解码器,可以在UNet++中实现重新设计的跳接。作者在六个分割数据集和不同深度的多个主干中对UNet++进行了广泛地评估。
五个贡献:
- 在UNet++中引入了一个内置的深度可变的U-Net集合,可为不同大小的对象提供改进的分割性能,这是对固定深度U-Net的改进。
- 重新设计了UNet++中的跳接,从而在解码器中实现了灵活的特征融合,这是对U-Net中仅需要融合相同比例特征图的限制性跳接的一种改进。
- 设计了一种方案来剪枝经过训练的UNet++,在保持其性能的同时加快其推理速度。
- 同时训练嵌入在UNet++体系结构中的多深度U-Net可以激发组成U-Net之间的协作学习,与单独训练具有相同体系结构的隔离U-Net相比,可以带来更好的性能。
- 展示了UNet++对多个主干编码器的可扩展性,并进一步将其应用于包括CT、MRI和电子显微镜在内的各种医学成像模式。






![内网穿透[让你在家里也能榨干学校的服务器]Yep!](https://img-blog.csdnimg.cn/direct/2f4ea18b50184bbcb6efc8c6acb6f839.png)