1.mybatis的#{}和${}区别
- #{}是预编译处理,${}是字符串替换
- #{}可以防止SQL注入,提高安全性
2.mybatis隔离级别
读未提交 READ UNCOMMITED:读到了其他事务中未提交的数据,造成"脏读","不可重复读","幻读";
读已提交 READ COMMITED:大多数数据库的默认隔离级别,MySQL不是;造成"不可重复读","幻读";
可重复读 REPEATABLE READ:保证同一事务的多个实例在并发下读取数据相同;造成"幻读";
可串行化 SERIALIZABLE:在每个读的数据加锁;
3.mysql复制原理
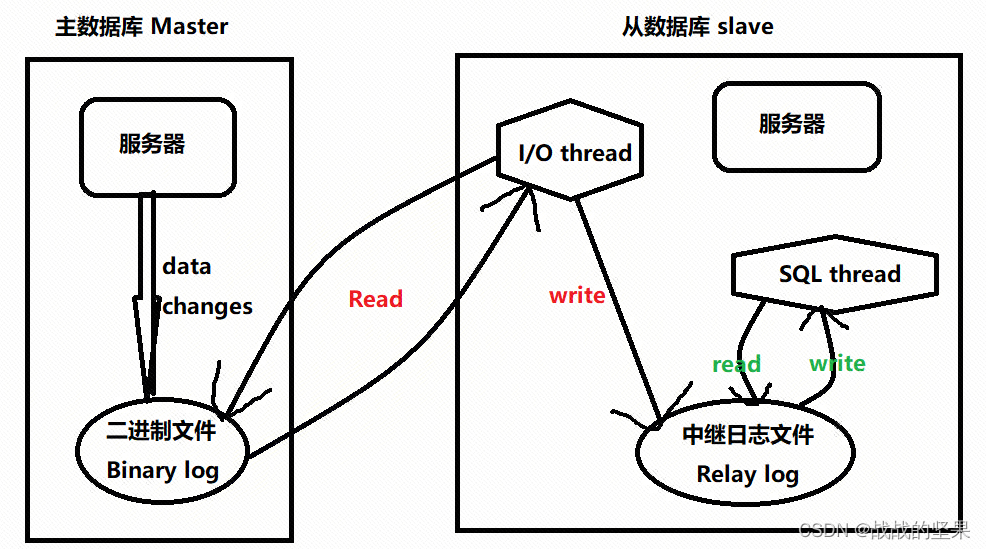
- master将数据的改变记录到二进制binlog日志;
- slave会定时对master的二进制日志进行查看是否发生变化,若发生变化,则开一个I/O线程读取二进制日志文件并保存到当前服务器中的中继文件relay log;
- 同时slave也会开一个SQL线程读取中继日志文件relay log,并解析SQL语句逐一执行;
4.MySQL聚簇与非聚簇索引区别
mysql的索引类型与存储引擎有关;索引是存储在磁盘中;
innodb存储引擎数据文件和索引文件是存储在ibd文件中,而myisam的数据文件在myd文件,索引在myi文件,表结构在frm文件;
可以看到在mysql目录下存在多个frm-myd-myi文件,此时为myisam引擎

在ccb目录下存在多个frm-ibd文件,此时为innodb引擎
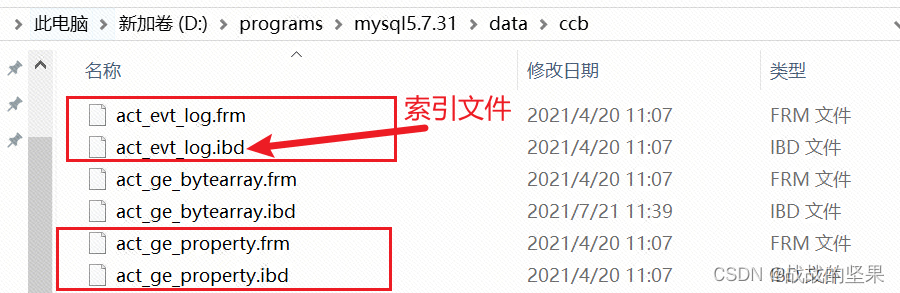
与数据绑定在一起的都是聚簇索引,所以myisam是非聚簇索引,innodb既是聚簇索引又是非聚簇索引(表含有多个索引)。innodb引擎在数据插入时,数据与索引是绑定到一起的,有主键优先主键,其次是唯一键,最后是6字节的rowid。当某表含有多个索引时,数据必然只存储一份,与数据绑定到一起的是聚簇索引,其他索引存储的是聚簇索引的key值。
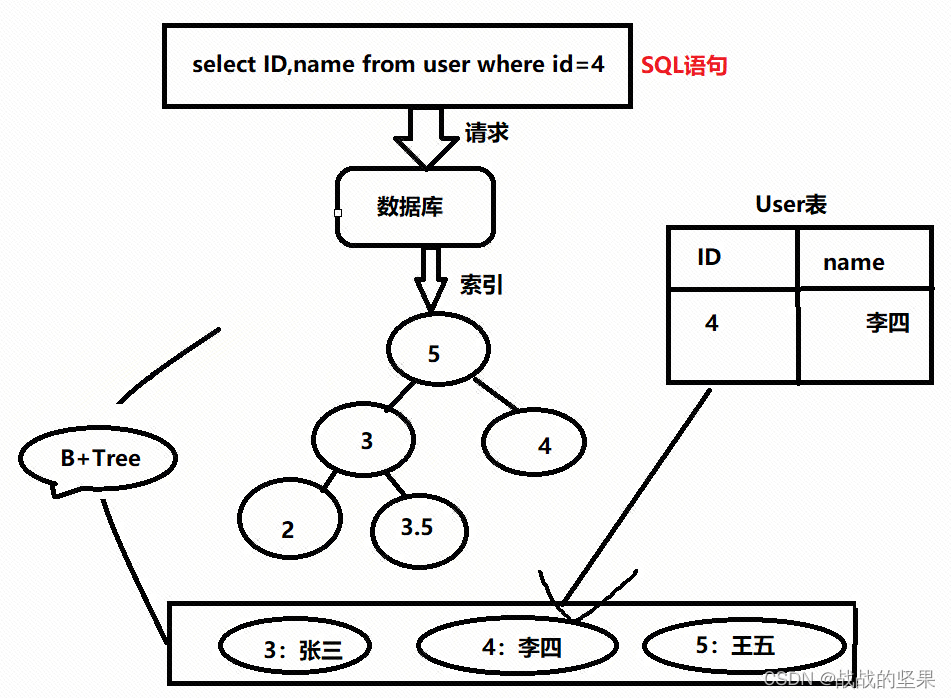
5.mysql索引的基本原理
索引作用:为了加快数据库查询速度
mysql索引的数据结构:B+Tree(innodb引擎)、Hash(memory引擎)
B+Tree:平衡多叉树
Hash:动态数组+链表 详见hash算法
若等值查询,hash索引有优势,因为等值匹配可得到下标,进而去动态数组找到对应数据;
若范围查询,B+Tree有优势,因为首先没有下标,其次B+Tree搜索时,速度可以快一半;
6.mysql锁的类型
- 锁的属性:共享锁(读锁)、排它锁(写锁)
- 锁的粒度:行级锁(行)、表级锁(整张表)、页级索(页[4kb/8kb]的整数倍)、记录锁(一行数据)、间隙锁、临键锁
7.mysql执行计划
关键字:EXPLAIN
执行计划包含信息:ID(主键)、table(表名)、type(执行类型)、key(实际用到索引)、rows(预估数据量)、extre(额外信息)
- ID相同,执行顺序从上到下;ID不同,值越大优先执行;
- type效率从好到坏顺序:system>const>ref>index_subquery>range>index>all