案例背景
很多同学的课程作业都是需要自己爬虫数据然后进行分析,这里提供一个财经新闻的爬虫案例供学习。本案例的全部数据和代码获取可以参考:财经新闻数据
数据来源
新浪财经的新闻网,说实话,他这个网站做成这样就是用来爬虫的...
代码实现
首先导入包
import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
from wordcloud import WordCloud
import jieba ,re
import chardet
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号
爬虫获取数据:
#定义爬取函数
def crawl_sina_finance_reports(pages=100):
base_url = "https://stock.finance.sina.com.cn/stock/go.php/vReport_List/kind/lastest/index.phtml"
reports = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
for page in range(1, pages + 1):
url = f"{base_url}?p={page}"
response = requests.get(url,headers=headers)#
# 使用chardet检测编码
detected_encoding = chardet.detect(response.content)['encoding']
if detected_encoding:
#print(detected_encoding)
response.encoding = detected_encoding
else:
response.encoding = 'GB2312' # 如果chardet无法检测到编码,则默认使用GB2312
soup = BeautifulSoup(response.content)#, 'html.parser'
# 找到所有报道的列表项
report_items = soup.find_all('tr')[1:] # 跳过表头
for item in report_items:
columns = item.find_all('td')
if len(columns) >= 4:
title = columns[1].text.strip()
kind = columns[2].text.strip()
date = columns[3].text.strip()
organization = columns[4].text.strip()
reports.append([title, kind, date, organization])
return reports
# 爬取数据
reports_data = crawl_sina_finance_reports()
# 创建DataFrame
df_reports = pd.DataFrame(reports_data, columns=["标题",'报告类型', "发布日期", "机构"])
df_reports
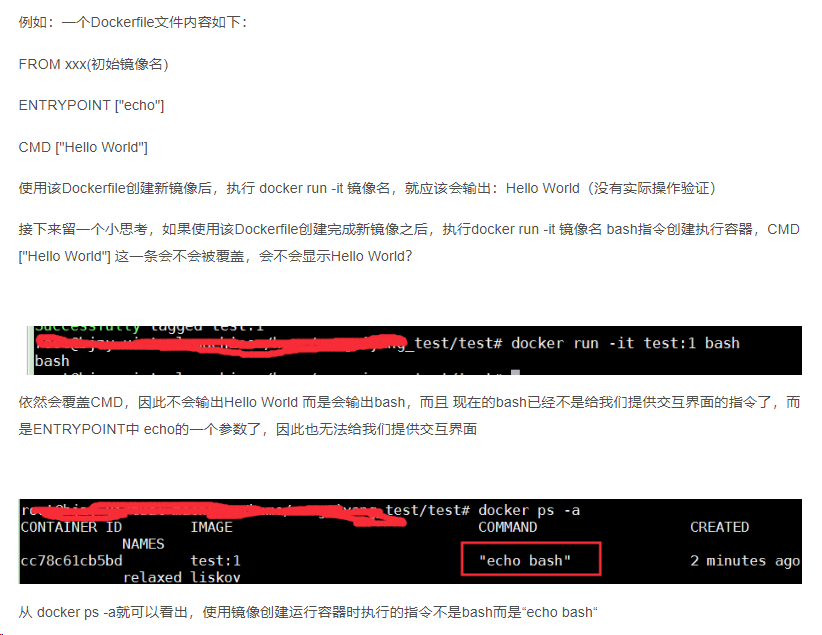
爬了100面,大概2000多条,从1-4日到1-14号,各种类型和各种机构的报告。然后储存:
df_reports.to_csv('财经新闻.csv',index=False) #储存备份一下,然后开始分析:
df=df_reports.copy()财经新闻不同种类数量对比
# Analysis 1: Value counts of report types and horizontal bar chart
report_type_counts = df['报告类型'].value_counts()
plt.figure(figsize=(8, 4),dpi=128)
sns.barplot(x=report_type_counts.index, y=report_type_counts.values, orient='v')
plt.title('Report Type Counts')
plt.xlabel('Report Type')
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.show()
做行业研究的财经新闻最多,其次是公司和策略类。
每天发布新闻数量对比
# Analysis 2: Count news per day and plot a line chart
df['发布日期'] = pd.to_datetime(df['发布日期'])
news_counts_per_day = df['发布日期'].value_counts().sort_index()
plt.figure(figsize=(8, 4),dpi=128)
sns.lineplot(x=news_counts_per_day.index, y=news_counts_per_day.values, marker='o')
plt.title('News Counts Per Day')
plt.xlabel('Date')
plt.ylabel('Number of News')
plt.xticks(rotation=45)
# Adding data labels
for date, count in zip(news_counts_per_day.index, news_counts_per_day.values):
plt.text(date, count, str(count), color='black', ha='center', va='bottom')
plt.show()
大体上曲曲折折,有高有低。
不同机构发文数量
def clean_institution_name(name):
return re.sub(r'(研究所有限公司|股份有限公司)', '', name)
df['机构'] = df['机构'].apply(clean_institution_name)
institution_counts = df['机构'].value_counts().head(10)
plt.figure(figsize=(10, 6))
sns.barplot(x=institution_counts.values, y=institution_counts.index, orient='h')
plt.title('Top 10 Institutions')
plt.xlabel('Count')
plt.ylabel('Institution')
plt.show() 
可以看到国泰君安发的报告最多。
新闻标题词云图
计算新闻标题的高平词汇:
# Analysis 4: Word cloud of titles
all_titles = ' '.join(df['标题'])
# Word segmentation
seg_list = jieba.cut(all_titles, cut_all=False)
seg_text = ' '.join(seg_list)
#对分词文本做高频词统计
word_counts = Counter(seg_text.split())
word_counts_updated=word_counts.most_common()
#过滤标点符号
non_chinese_pattern = re.compile(r'[^\u4e00-\u9fa5]')
# 过滤掉非中文字符的词汇
filtered_word_counts_regex = [item for item in word_counts_updated if not non_chinese_pattern.match(item[0])]
filtered_word_counts_regex[:5]
这五个词汇最常见
画出词云图:
# Generate word cloud
wordcloud = WordCloud(font_path='simhei.ttf', background_color='white',
max_words=80, # Limits the number of words to 100
max_font_size=50) #.generate(seg_text) #文本可以直接生成,但是不好看
wordcloud = wordcloud.generate_from_frequencies(dict(filtered_word_counts_regex))
# Display the word cloud
plt.figure(figsize=(8, 5),dpi=256)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show() 
长方形不好看,去找了一个❤图作为掩码:
from PIL import Image
# 加载本地图片
mask_image = Image.open("c2.png") # 替换为您图片的路径
mask_array = np.array(mask_image)
# 创建 WordCloud 对象,传入 mask 参数
wordcloud = WordCloud(font_path='simhei.ttf', background_color='white',
mask=mask_array, max_words=300, max_font_size=100)
# 使用 generate_from_frequencies 方法生成词云
wordcloud.generate_from_frequencies(dict(filtered_word_counts_regex))
# 显示词云图
plt.figure(figsize=(8, 8), dpi=256)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show() 
效果还不错。从图中可以看到,财经新闻基本都是什么行业,报告,策略,公司,投资等词汇。
然后进一步还可以爬取每个新闻里面的具体内容,然后使用snownlp做情感值计算打分,对不同时间,不同事件发生后新闻数量资料内容,关键词统计的对比之类的,做出更深度的分析,大家可以自己去进一步完善。
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制代码可私信)