文章目录
- 题目
- 标题和出处
- 难度
- 题目描述
- 要求
- 示例
- 数据范围
- 前言
- 解法一
- 思路和算法
- 代码
- 复杂度分析
- 解法二
- 思路和算法
- 代码
- 复杂度分析
题目
标题和出处
标题:从前序与后序遍历序列构造二叉树
出处:889. 从前序与后序遍历序列构造二叉树
难度
7 级
题目描述
要求
给定两个整数数组 preorder \texttt{preorder} preorder 和 postorder \texttt{postorder} postorder,其中 preorder \texttt{preorder} preorder 是一个具有无重复值的二叉树的前序遍历, postorder \texttt{postorder} postorder 是同一个树的后序遍历,请构造并返回二叉树。
如果存在多个答案,返回其中任何一个。
示例
示例 1:
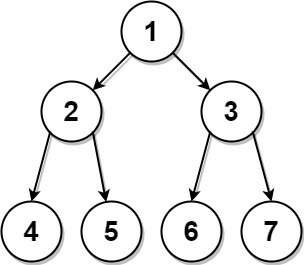
输入:
preorder
=
[1,2,4,5,3,6,7],
postorder
=
[4,5,2,6,7,3,1]
\texttt{preorder = [1,2,4,5,3,6,7], postorder = [4,5,2,6,7,3,1]}
preorder = [1,2,4,5,3,6,7], postorder = [4,5,2,6,7,3,1]
输出:
[1,2,3,4,5,6,7]
\texttt{[1,2,3,4,5,6,7]}
[1,2,3,4,5,6,7]
示例 2:
输入:
preorder
=
[1],
postorder
=
[1]
\texttt{preorder = [1], postorder = [1]}
preorder = [1], postorder = [1]
输出:
[1]
\texttt{[1]}
[1]
数据范围
- 1 ≤ preorder.length ≤ 30 \texttt{1} \le \texttt{preorder.length} \le \texttt{30} 1≤preorder.length≤30
- 1 ≤ preorder[i] ≤ preorder.length \texttt{1} \le \texttt{preorder[i]} \le \texttt{preorder.length} 1≤preorder[i]≤preorder.length
- preorder \texttt{preorder} preorder 中所有值都不同
- postorder.length = preorder.length \texttt{postorder.length} = \texttt{preorder.length} postorder.length=preorder.length
- 1 ≤ postorder[i] ≤ postorder.length \texttt{1} \le \texttt{postorder[i]} \le \texttt{postorder.length} 1≤postorder[i]≤postorder.length
- postorder \texttt{postorder} postorder 中所有值都不同
- 保证 preorder \texttt{preorder} preorder 和 postorder \texttt{postorder} postorder 是同一个二叉树的前序遍历和后序遍历
前言
当二叉树中的每个结点值各不相同时,给定二叉树的前序遍历与中序遍历,或者给定二叉树的中序遍历与后序遍历,都可以唯一地构造出二叉树。但是给定二叉树的前序遍历与后序遍历,则可能有多种符合要求的二叉树。
由于答案可能不唯一,因此在构造二叉树时需要做特殊处理,使得答案为可能的答案之一。在确保得到正确答案的前提下,将答案限定在一种可能。
解法一
思路和算法
由于二叉树中的每个结点值各不相同,因此可以根据结点值唯一地确定结点。
二叉树的前序遍历的方法为:依次遍历根结点、左子树和右子树,对于左子树和右子树使用同样的方法遍历。
二叉树的后序遍历的方法为:依次遍历左子树、右子树和根结点,对于左子树和右子树使用同样的方法遍历。
前序遍历序列的第一个元素值与后序遍历序列的最后一个元素值都是根结点值。如果左子树和右子树都不为空,则前序遍历序列的第二个元素值为左子结点值,后序遍历序列的倒数第二个元素值为右子结点值,由于后序遍历序列中每个子树的根结点总是最后被访问的,因此只要在后序遍历序列中定位到左子结点值的下标,即可得到左子树中的结点数和右子树中的结点数。对于左子树和右子树,也可以在给定的前序遍历序列和后序遍历序列中分别得到对应的子序列,根据子序列构造相应的子树。
如果前序遍历序列的第二个元素值与后序遍历序列的倒数第二个元素值相同,则只有一个子树不为空,左子树非空和右子树非空都是可能的情况。为了将答案限定在一种可能,当只有一个子树不为空时,规定左子树不为空,则左子树中的结点数为二叉树中的结点数减 1 1 1,右子树中的结点数为 0 0 0。对于左子树,使用同样的方法构造。
上述构造二叉树的过程是一个递归分治的过程。将二叉树分成根结点、左子树和右子树三部分,首先构造左子树和右子树,然后构造原始二叉树,构造左子树和右子树是原始问题的子问题。
分治的终止条件是子序列为空,此时构造的子树为空。当子序列不为空时,首先得到根结点值以及左子树和右子树对应的子序列,然后递归地构造左子树和右子树。
实现方面有两点需要注意。
-
在后序遍历序列中定位左子结点值的下标时,简单的做法是遍历整个序列寻找左子结点值,该做法的时间复杂度较高。可以使用哈希表存储每个结点值在后序遍历序列中的下标,即可在 O ( 1 ) O(1) O(1) 的时间内定位到任意结点值在后序遍历序列中的下标。
-
对于左子树和右子树的构造需要使用子序列,此处的子序列实质为下标连续的子数组。为了降低时间复杂度和空间复杂度,使用开始下标和子数组长度确定子数组,则不用新建数组和复制数组元素,而且可以复用哈希表存储的每个结点值在后序遍历序列中的下标信息。
代码
class Solution {
Map<Integer, Integer> postorderIndices = new HashMap<Integer, Integer>();
int[] preorder;
int[] postorder;
public TreeNode constructFromPrePost(int[] preorder, int[] postorder) {
this.preorder = preorder;
this.postorder = postorder;
int length = preorder.length;
for (int i = 0; i < length; i++) {
postorderIndices.put(postorder[i], i);
}
return constructFromPrePost(0, 0, length);
}
public TreeNode constructFromPrePost(int preorderStart, int postorderStart, int nodesCount) {
if (nodesCount == 0) {
return null;
}
int rootVal = preorder[preorderStart];
TreeNode root = new TreeNode(rootVal);
if (nodesCount == 1) {
return root;
}
int leftChildVal = preorder[preorderStart + 1];
int postorderLeftChildIndex = postorderIndices.get(leftChildVal);
int leftNodesCount = postorderLeftChildIndex - postorderStart + 1;
int rightNodesCount = nodesCount - 1 - leftNodesCount;
root.left = constructFromPrePost(preorderStart + 1, postorderStart, leftNodesCount);
root.right = constructFromPrePost(preorderStart + 1 + leftNodesCount, postorderLeftChildIndex + 1, rightNodesCount);
return root;
}
}
复杂度分析
-
时间复杂度: O ( n ) O(n) O(n),其中 n n n 是数组 preorder \textit{preorder} preorder 和 postorder \textit{postorder} postorder 的长度,即二叉树的结点数。将后序遍历序列中的每个结点值与下标的对应关系存入哈希表需要 O ( n ) O(n) O(n) 的时间,构造二叉树也需要 O ( n ) O(n) O(n) 的时间。
-
空间复杂度: O ( n ) O(n) O(n),其中 n n n 是数组 preorder \textit{preorder} preorder 和 postorder \textit{postorder} postorder 的长度,即二叉树的结点数。空间复杂度主要是递归调用的栈空间以及哈希表空间,因此空间复杂度是 O ( n ) O(n) O(n)。
解法二
思路和算法
使用迭代的方法构造二叉树,需要充分利用二叉树遍历的性质,考虑遍历序列中相邻结点的关系。
对于前序遍历序列中的两个相邻的值 x x x 和 y y y,其对应结点的关系一定是以下两种情况之一:
-
结点 y y y 是结点 x x x 的左子结点,或者结点 x x x 没有左子结点且结点 y y y 是结点 x x x 的右子结点;
-
结点 x x x 是叶结点,结点 y y y 是结点 x x x 的某个祖先结点的右子结点。
对于第 1 种情况,在后序遍历序列中, y y y 在 x x x 前面。对于第 2 种情况,在后序遍历序列中, x x x 在 y y y 前面。
判断前序遍历序列中的两个相邻的值属于哪一种情况,需要借助后序遍历序列。由于后序遍历访问根结点在访问左右子树之后,因此可以比较前序遍历序列的上一个结点值和后序遍历序列的当前结点值,判断属于哪一种情况:
-
如果前序遍历序列的上一个结点值和后序遍历序列的当前结点值不同,则前序遍历序列的上一个结点不是叶结点,属于第 1 种情况;
-
如果前序遍历序列的上一个结点值和后序遍历序列的当前结点值相同,则前序遍历序列的上一个结点是叶结点,属于第 2 种情况。
注意在第 1 种情况下,后序遍历序列的结点值顺序恰好和前序遍历序列的结点值顺序相反,可以使用栈实现反转序列。
具体做法是,遍历前序遍历序列,对于每个值分别创建结点,将每个结点作为栈顶结点的左子结点,并将每个结点入栈,直到栈顶结点值等于后序遍历序列的当前结点值。然后遍历后序遍历序列并依次将栈内的结点出栈,直到栈顶结点值和后序遍历序列的当前结点值不同,此时前序遍历序列的当前值对应的结点为栈顶结点的右子结点,将当前结点入栈。然后对前序遍历序列和后序遍历序列的其余值继续执行上述操作,直到遍历结束时,二叉树构造完毕。
以下用示例 1 说明构造二叉树的过程。已知二叉树的前序遍历序列是 [ 1 , 2 , 4 , 5 , 3 , 6 , 7 ] [1, 2, 4, 5, 3, 6, 7] [1,2,4,5,3,6,7],后序遍历序列是 [ 4 , 5 , 2 , 6 , 7 , 3 , 1 ] [4, 5, 2, 6, 7, 3, 1] [4,5,2,6,7,3,1]。
初始时,后序遍历序列的下标是 0 0 0。以下将后序遍历序列的下标处的值称为后序遍历序列的当前结点值。
-
将前序遍历序列的下标 0 0 0 的元素 1 1 1 作为根结点值创建根结点,并将根结点入栈。
-
当遍历到前序遍历序列的 2 2 2 时,上一个结点值和后序遍历序列的当前结点值不同,因此创建结点 2 2 2,作为结点 1 1 1 的左子结点,并将结点 2 2 2 入栈。
-
当遍历到前序遍历序列的 4 4 4 时,上一个结点值和后序遍历序列的当前结点值不同,因此创建结点 4 4 4,作为结点 2 2 2 的左子结点,并将结点 4 4 4 入栈。
-
当遍历到前序遍历序列的 5 5 5 时,上一个结点值是 4 4 4,和后序遍历序列的当前结点值相同,因此遍历后序遍历序列并将栈内的结点 4 4 4 出栈,此时后序遍历的下标移动到 1 1 1。创建结点 5 5 5,将结点 5 5 5 作为结点 2 2 2 的右子结点,并将结点 5 5 5 入栈。
-
当遍历到前序遍历序列的 3 3 3 时,上一个结点值是 5 5 5,和后序遍历序列的当前结点值相同,因此遍历后序遍历序列并将栈内的结点 5 5 5、 2 2 2 出栈,此时后序遍历的下标移动到 3 3 3。创建结点 3 3 3,将结点 3 3 3 作为结点 1 1 1 的右子结点,并将结点 3 3 3 入栈。
-
当遍历到前序遍历序列的 6 6 6 时,上一个结点值和后序遍历序列的当前结点值不同,因此创建结点 6 6 6,作为结点 3 3 3 的左子结点,并将结点 6 6 6 入栈。
-
当遍历到前序遍历序列的 7 7 7 时,上一个结点值是 6 6 6,和后序遍历序列的当前结点值相同,因此遍历后序遍历序列并将栈内的结点 6 6 6 出栈,此时后序遍历的下标移动到 4 4 4。创建结点 7 7 7,将结点 7 7 7 作为结点 3 3 3 的右子结点,并将结点 7 7 7 入栈。
此时遍历结束,二叉树构造完毕。
代码
class Solution {
public TreeNode constructFromPrePost(int[] preorder, int[] postorder) {
int length = preorder.length;
TreeNode root = new TreeNode(preorder[0]);
Deque<TreeNode> stack = new ArrayDeque<TreeNode>();
stack.push(root);
int postorderIndex = 0;
for (int i = 1; i < length; i++) {
TreeNode prev = stack.peek();
TreeNode curr = new TreeNode(preorder[i]);
if (prev.val != postorder[postorderIndex]) {
prev.left = curr;
stack.push(curr);
} else {
while (stack.peek().val == postorder[postorderIndex]) {
stack.pop();
postorderIndex++;
}
prev = stack.peek();
prev.right = curr;
stack.push(curr);
}
}
return root;
}
}
复杂度分析
-
时间复杂度: O ( n ) O(n) O(n),其中 n n n 是数组 preorder \textit{preorder} preorder 和 postorder \textit{postorder} postorder 的长度,即二叉树的结点数。前序遍历序列和后序遍历序列各需要遍历一次,构造二叉树需要 O ( n ) O(n) O(n) 的时间。
-
空间复杂度: O ( n ) O(n) O(n),其中 n n n 是数组 preorder \textit{preorder} preorder 和 postorder \textit{postorder} postorder 的长度,即二叉树的结点数。空间复杂度主要是栈空间,取决于二叉树的高度,最坏情况下二叉树的高度是 O ( n ) O(n) O(n)。







![[zabbix] zabbix监控](https://img-blog.csdnimg.cn/direct/5e2ec9e265984b4cb0c8c7bfc67b8cb1.png)