【Flink-1.17-教程】-【一】Flink概述、Flink快速入门
- 1)Flink 是什么
- 1.1.有界流和无界流
- 1.2.Flink 的发展史
- 2)Flink 特点
- 3)Flink vs SparkStreaming
- 4)Flink 的应用场景
- 5)Flink 分层 API
- 6)Flink 快速入门
- 6.1.创建项目
- 6.2.WordCount 代码编写
- 6.2.1.批处理(了解)
- 6.2.2.流处理(主流)
1)Flink 是什么

1.1.有界流和无界流

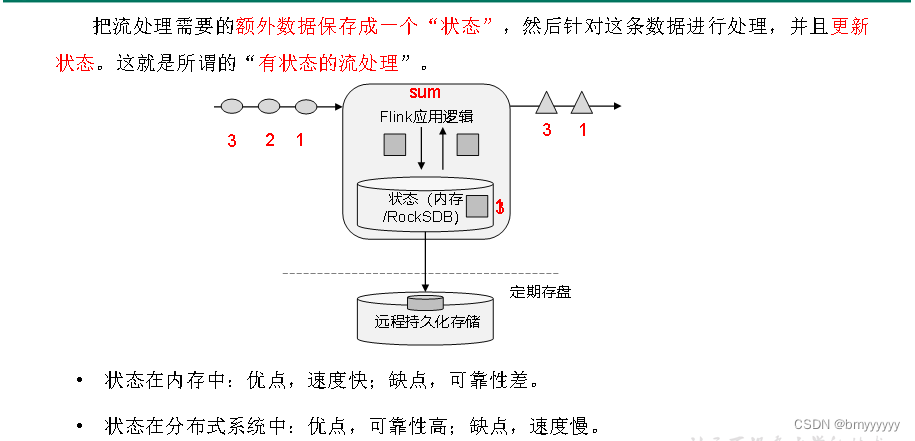
1.2.Flink 的发展史

2)Flink 特点

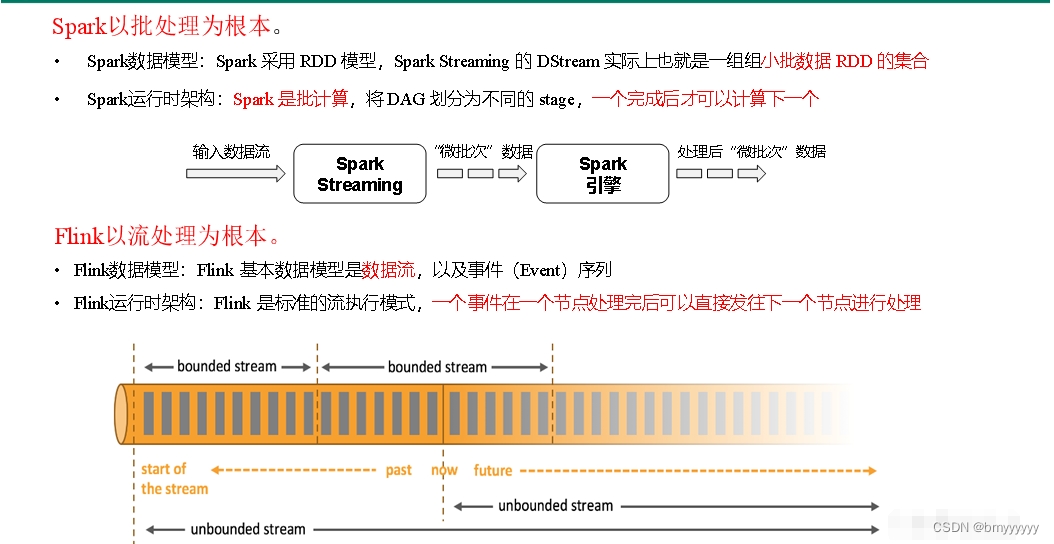
3)Flink vs SparkStreaming
4)Flink 的应用场景

5)Flink 分层 API

6)Flink 快速入门
6.1.创建项目
在准备好所有的开发环境之后,我们就可以开始开发自己的第一个 Flink 程序了。首先我们要做的,就是在 IDEA 中搭建一个 Flink 项目的骨架。我们会使用 Java 项目中常见的 Maven 来进行依赖管理。
1、创建工程
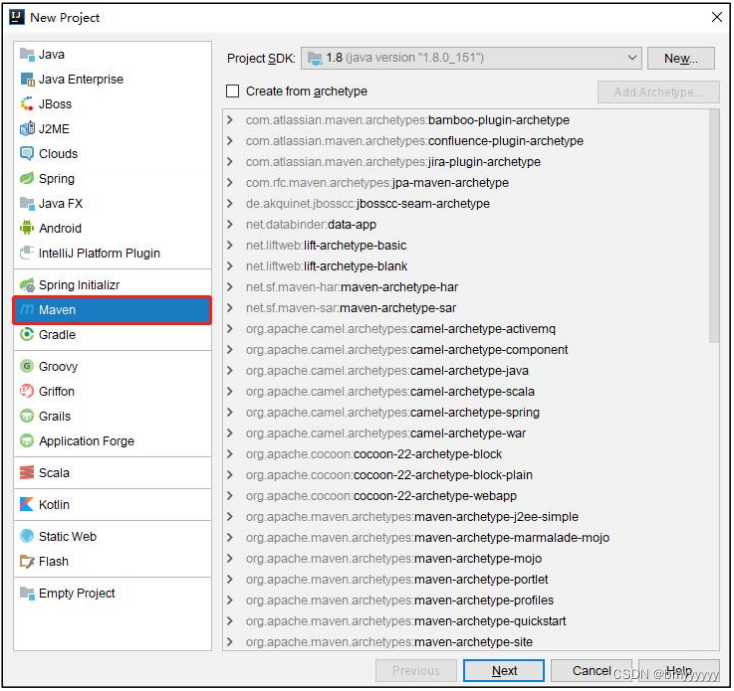
(1)打开 IntelliJ IDEA,创建一个 Maven 工程。
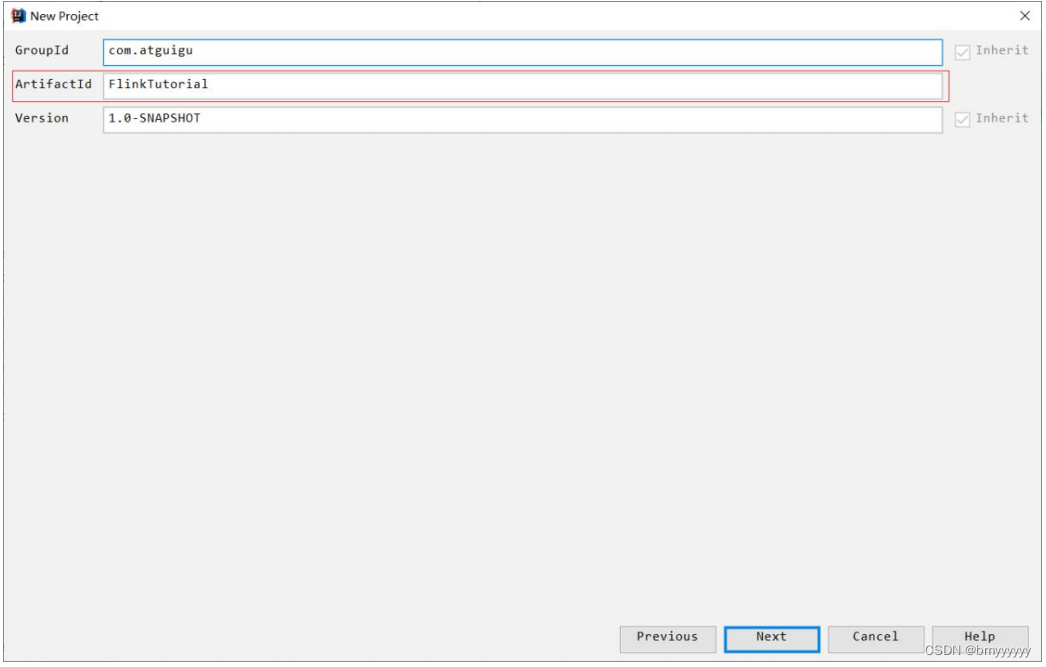
(2)将这个 Maven 工程命名为 FlinkTutorial。
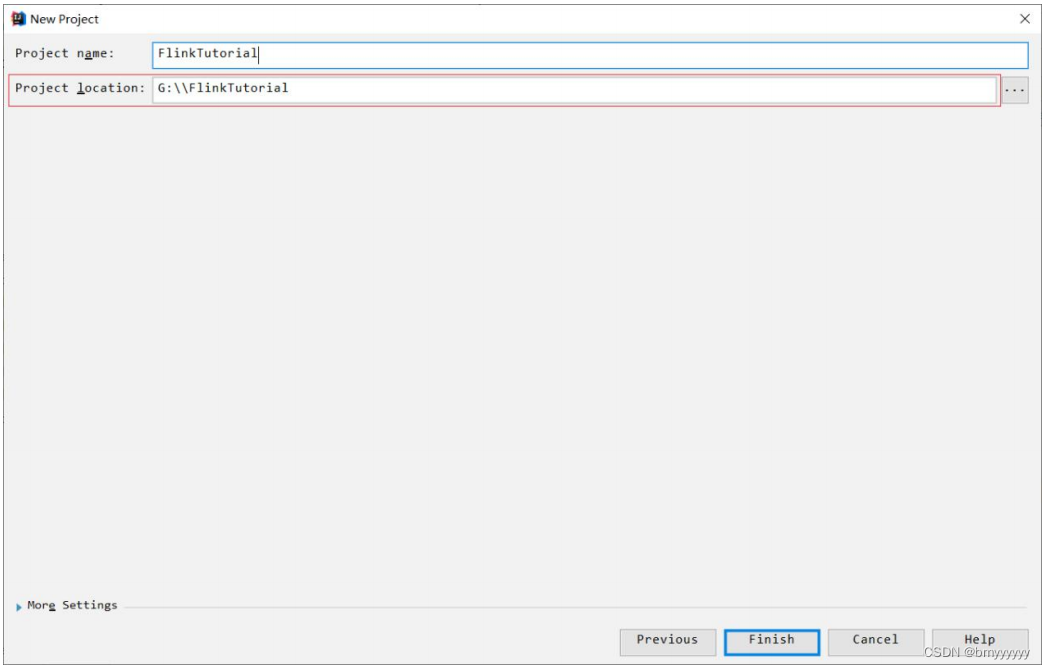
(3)选定这个 Maven 工程所在存储路径,并点击 Finish,Maven 工程即创建成功。
2、添加项目依赖
在项目的 pom 文件中,添加 Flink 的依赖,包括 flink-java、flink-streaming-java,以及 flink-clients(客户端,也可以省略)。
<properties>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
6.2.WordCount 代码编写
需求:统计一段文字中,每个单词出现的频次。
环境准备:在 src/main/java 目录下,新建一个包,命名为 com.atguigu.wc。
6.2.1.批处理(了解)
批处理基本思路:先逐行读入文件数据,然后将每一行文字拆分成单词;接着按照单词分组,统计每组数据的个数,就是对应单词的频次
1、数据准备
(1)在工程根目录下新建一个input文件夹,并在下面创建文本文件words.txt
(2)在words.txt中输入一些文字,例如:
hello flink
hello world
hello java
2、代码编写
(1)在 com.atguigu.wc 包下新建 Java 类 BatchWordCount,在静态 main 方法中编写代码。具体代码实现如下:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件读取数据 按行读取(存储的元素就是每行的文本)
DataSource<String> lineDS = env.readTextFile("input/words.txt");
// 3. 转换数据格式
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Long>> out) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word,1L));
}
}
});
// 4. 按照 word 进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG = wordAndOne.groupBy(0);
// 5. 分组内聚合统计
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);
// 6. 打印结果
sum.print();
}
}
(2)输出
(flink,1)
(world,1)
(hello,3)
(java,1)
需要注意的是,这种代码的实现方式,是基于 DataSet API 的,也就是我们对数据的处理转换,是看作数据集来进行操作的。事实上 Flink 本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的 API 来实现。所以从 Flink 1.12 开始,官方推荐的做法是直接使用 DataStream API,在提交任务时通过将执行模式设为 BATCH 来进行批处理:
$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
这样,DataSet API 就没什么用了,在实际应用中我们只要维护一套 DataStream API 就可以。这里只是为了方便大家理解,我们依然用 DataSet API 做了批处理的实现。
6.2.2.流处理(主流)
对于Flink而言,流才是整个处理逻辑的底层核心,所以流批统一之后的 DataStream API 更加强大,可以直接处理批处理和流处理的所有场景。
下面我们就针对不同类型的输入数据源,用具体的代码来实现流处理。
1、读取文件
我们同样试图读取文档 words.txt 中的数据,并统计每个单词出现的频次。整体思路与之前的批处理非常类似,代码模式也基本一致。
在 com.atguigu.wc 包下新建 Java 类 StreamWordCount,在静态 main 方法中编写代码。具体代码实现如下:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文件
DataStreamSource<String> lineStream = env.readTextFile("input/words.txt");
// 3. 转换、分组、求和,得到统计结果
SingleOutputStreamOperator<Tuple2<String, Long>> sum = lineStream.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Long>> out) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}
}).keyBy(data -> data.f0)
.sum(1);
// 4. 打印
sum.print();
// 5. 执行
env.execute();
}
}
输出:
3> (java,1)
5> (hello,1)
5> (hello,2)
5> (hello,3)
13> (flink,1)
9> (world,1)
主要观察与批处理程序BatchWordCount的不同:
- 创建执行环境的不同,流处理程序使用的是StreamExecutionEnvironment。
- 转换处理之后,得到的数据对象类型不同。
- 分组操作调用的是keyBy方法,可以传入一个匿名函数作为键选择器(KeySelector),指定当前分组的key是什么。
- 代码末尾需要调用env的execute方法,开始执行任务。
2、读取socket文本流
在实际的生产环境中,真正的数据流其实是无界的,有开始却没有结束,这就要求我们需要持续地处理捕获的数据。为了模拟这种场景,可以监听 socket 端口,然后向该端口不断的发送数据。
(1)将 StreamWordCount 代码中读取文件数据的 readTextFile 方法,替换成读取 socket 文本流的方法 socketTextStream。具体代码实现如下:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
public class SocketStreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文本流:hadoop102表示发送端主机名、7777表示端口号
DataStreamSource<String> lineStream = env.socketTextStream("hadoop102", 7777);
// 3. 转换、分组、求和,得到统计结果
SingleOutputStreamOperator<Tuple2<String, Long>> sum = lineStream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG))
.keyBy(data -> data.f0)
.sum(1);
// 4. 打印
sum.print();
// 5. 执行
env.execute();
}
}
(2)在 Linux 环境的主机 hadoop102 上,执行下列命令,发送数据进行测试
[atguigu@hadoop102 ~]$ nc -lk 7777
注意:要先启动端口,后启动 StreamWordCount 程序,否则会报超时连接异常。
(3)启动 StreamWordCount 程序
我们会发现程序启动之后没有任何输出、也不会退出。这是正常的,因为 Flink 的流处理是事件驱动的,当前程序会一直处于监听状态,只有接收到数据才会执行任务、输出统计结果。
(4)从 hadoop102 发送数据
①在 hadoop102 主机中,输入“hello flink”,输出如下内容
13> (flink,1)
5> (hello,1)
②再输入“hello world”,输出如下内容
2> (world,1)
5> (hello,2)
泛型擦除的说明:
Flink 还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于 Java 中泛型擦除的存在,在某些特殊情况下(比如 Lambda 表达式中),自动提取的信息是不够精细的——只告诉 Flink 当前的元素由“船头、船身、船尾”构成,根本无法重建出“大船”的模样;这时就需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
因为对于 flatMap 里传入的Lambda表达式,系统只能推断出返回的是 Tuple2 类型,而无法得到 Tuple2<String, Long>。只有显式地告诉系统当前的返回类型,才能正确地解析出完整数据。