终于考完试了,寒假期间将会每天持续更新!
447. 回旋镖的数量(Day 37)
给定平面上 n 对 互不相同 的点 points ,其中 points[i] = [xi, yi] 。回旋镖 是由点 (i, j, k) 表示的元组 ,其中 i 和 j 之间的欧式距离和 i 和 k 之间的欧式距离相等(需要考虑元组的顺序)。
返回平面上所有回旋镖的数量。
示例 1:
输入:points = [[0,0],[1,0],[2,0]]
输出:2
解释:两个回旋镖为 [[1,0],[0,0],[2,0]] 和 [[1,0],[2,0],[0,0]]
示例 2:
输入:points = [[1,1],[2,2],[3,3]]
输出:2
示例 3:
输入:points = [[1,1]]
输出:0
提示:
n == points.length
1 <= n <= 500
points[i].length == 2
-104 <= xi, yi <= 104
所有点都 互不相同
枚举实现,外层枚举i ,内层枚举j
class Solution {
public:
int numberOfBoomerangs(vector<vector<int>> &points) {
int ans = 0;
unordered_map<int, int> cnt;
for (auto &p1 : points) {
cnt.clear();
for (auto &p2 : points) {
int d2 = (p1[0] - p2[0]) * (p1[0] - p2[0]) + (p1[1] - p2[1]) * (p1[1] - p2[1]);
ans += cnt[d2]++ * 2;
}
}
return ans;
}
};
2707. 字符串中的额外字符(Day 38)
给你一个下标从 0 开始的字符串 s 和一个单词字典 dictionary 。你需要将 s 分割成若干个 互不重叠 的子字符串,每个子字符串都在 dictionary 中出现过。s 中可能会有一些 额外的字符 不在任何子字符串中。
请你采取最优策略分割 s ,使剩下的字符 最少 。
示例 1:
输入:s = “leetscode”, dictionary = [“leet”,“code”,“leetcode”]
输出:1
解释:将 s 分成两个子字符串:下标从 0 到 3 的 “leet” 和下标从 5 到 8 的 “code” 。只有 1 个字符没有使用(下标为 4),所以我们返回 1 。
示例 2:
输入:s = “sayhelloworld”, dictionary = [“hello”,“world”]
输出:3
解释:将 s 分成两个子字符串:下标从 3 到 7 的 “hello” 和下标从 8 到 12 的 “world” 。下标为 0 ,1 和 2 的字符没有使用,所以我们返回 3 。
提示:
1 <= s.length <= 50
1 <= dictionary.length <= 50
1 <= dictionary[i].length <= 50
dictionary[i] 和 s 只包含小写英文字母。
dictionary 中的单词互不相同。
字典序,哈希表+DP
class Solution {
public:
int minExtraChar(string s, vector<string>& dictionary) {
unordered_set<string> set(dictionary.begin(), dictionary.end());
int n = s.size();
vector<int> f(n + 1);
for (int i = 0; i < n; i++) {
f[i + 1] = f[i] + 1;
for (int j = 0; j <= i; j++) {
if (set.count(s.substr(j, i - j + 1))) {
f[i + 1] = min(f[i + 1], f[j]);
}
}
}
return f[n];
}
};
2696. 删除子串后的字符串最小长度(Day 39)
给你一个仅由 大写 英文字符组成的字符串 s 。
你可以对此字符串执行一些操作,在每一步操作中,你可以从 s 中删除 任一个 “AB” 或 “CD” 子字符串。
通过执行操作,删除所有 “AB” 和 “CD” 子串,返回可获得的最终字符串的 最小 可能长度。
注意,删除子串后,重新连接出的字符串可能会产生新的 “AB” 或 “CD” 子串。
示例 1:
输入:s = “ABFCACDB”
输出:2
解释:你可以执行下述操作:
- 从 “ABFCACDB” 中删除子串 “AB”,得到 s = “FCACDB” 。
- 从 “FCACDB” 中删除子串 “CD”,得到 s = “FCAB” 。
- 从 “FCAB” 中删除子串 “AB”,得到 s = “FC” 。
最终字符串的长度为 2 。
可以证明 2 是可获得的最小长度。
示例 2:
输入:s = “ACBBD”
输出:5
解释:无法执行操作,字符串长度不变。
提示:
1 <= s.length <= 100
s 仅由大写英文字母组成
栈的简单应用:
class Solution {
public:
int minLength(string s) {
int len = s.size();
char* stack = (char*)malloc(sizeof(char) * len);
int top = -1;
for (int i = 0; i < len; i++) {
if (s[i] == 'B') {
if (top >= 0 && stack[top] == 'A') {
top--;
} else {
stack[++top] = s[i];
}
}
else if (s[i] == 'D') {
if (top >= 0 && stack[top] == 'C') {
top--;
} else {
stack[++top] = s[i];
}
}
else
stack[++top] = s[i];
}
return top + 1;
}
};
2645. 构造有效字符串的最少插入数
给你一个字符串 word ,你可以向其中任何位置插入 “a”、“b” 或 “c” 任意次,返回使 word 有效 需要插入的最少字母数。
如果字符串可以由 “abc” 串联多次得到,则认为该字符串 有效 。
示例 1:
输入:word = “b”
输出:2
解释:在 “b” 之前插入 “a” ,在 “b” 之后插入 “c” 可以得到有效字符串 “abc” 。
示例 2:
输入:word = “aaa”
输出:6
解释:在每个 “a” 之后依次插入 “b” 和 “c” 可以得到有效字符串 “abcabcabc” 。
示例 3:
输入:word = “abc”
输出:0
解释:word 已经是有效字符串,不需要进行修改。
提示:
1 <= word.length <= 50
word 仅由字母 “a”、“b” 和 “c” 组成。
这里学习了灵神的解法,实在是优雅巧妙:
class Solution {
public:
int addMinimum(string word) {
int ans = word[0] + 2 - word.back();
for(int i = 1; i < word.length();i++){
ans += (word[i] + 2 - word[i - 1]) % 3;
}
return ans;
}
};
2085. 统计出现过一次的公共字符串
给你两个字符串数组 words1 和 words2 ,请你返回在两个字符串数组中 都恰好出现一次 的字符串的数目。
示例 1:
输入:words1 = [“leetcode”,“is”,“amazing”,“as”,“is”], words2 = [“amazing”,“leetcode”,“is”]
输出:2
解释:
- “leetcode” 在两个数组中都恰好出现一次,计入答案。
- “amazing” 在两个数组中都恰好出现一次,计入答案。
- “is” 在两个数组中都出现过,但在 words1 中出现了 2 次,不计入答案。
- “as” 在 words1 中出现了一次,但是在 words2 中没有出现过,不计入答案。
所以,有 2 个字符串在两个数组中都恰好出现了一次。
示例 2:
输入:words1 = [“b”,“bb”,“bbb”], words2 = [“a”,“aa”,“aaa”]
输出:0
解释:没有字符串在两个数组中都恰好出现一次。
示例 3:
输入:words1 = [“a”,“ab”], words2 = [“a”,“a”,“a”,“ab”]
输出:1
解释:唯一在两个数组中都出现一次的字符串是 “ab” 。
提示:
1 <= words1.length, words2.length <= 1000
1 <= words1[i].length, words2[j].length <= 30
words1[i] 和 words2[j] 都只包含小写英文字母。
哈希表的应用,哈希表计数:
class Solution {
public:
int countWords(vector<string>& words1, vector<string>& words2) {
unordered_map<string, int> cnt1;
unordered_map<string, int> cnt2;
for (auto& w : words1) {
++cnt1[w];
}
for (auto& w : words2) {
++cnt2[w];
}
int ans = 0;
for (auto& [w, v] : cnt1) {
ans += v == 1 && cnt2[w] == 1;
}
return ans;
}
};
2182. 构造限制重复的字符串
给你一个字符串 s 和一个整数 repeatLimit ,用 s 中的字符构造一个新字符串 repeatLimitedString ,使任何字母 连续 出现的次数都不超过 repeatLimit 次。你不必使用 s 中的全部字符。
返回 字典序最大的 repeatLimitedString 。
如果在字符串 a 和 b 不同的第一个位置,字符串 a 中的字母在字母表中出现时间比字符串 b 对应的字母晚,则认为字符串 a 比字符串 b 字典序更大 。如果字符串中前 min(a.length, b.length) 个字符都相同,那么较长的字符串字典序更大。
示例 1:
输入:s = “cczazcc”, repeatLimit = 3
输出:“zzcccac”
解释:使用 s 中的所有字符来构造 repeatLimitedString “zzcccac”。
字母 ‘a’ 连续出现至多 1 次。
字母 ‘c’ 连续出现至多 3 次。
字母 ‘z’ 连续出现至多 2 次。
因此,没有字母连续出现超过 repeatLimit 次,字符串是一个有效的 repeatLimitedString 。
该字符串是字典序最大的 repeatLimitedString ,所以返回 “zzcccac” 。
注意,尽管 “zzcccca” 字典序更大,但字母 ‘c’ 连续出现超过 3 次,所以它不是一个有效的 repeatLimitedString 。
示例 2:
输入:s = “aababab”, repeatLimit = 2
输出:“bbabaa”
解释:
使用 s 中的一些字符来构造 repeatLimitedString “bbabaa”。
字母 ‘a’ 连续出现至多 2 次。
字母 ‘b’ 连续出现至多 2 次。
因此,没有字母连续出现超过 repeatLimit 次,字符串是一个有效的 repeatLimitedString 。
该字符串是字典序最大的 repeatLimitedString ,所以返回 “bbabaa” 。
注意,尽管 “bbabaaa” 字典序更大,但字母 ‘a’ 连续出现超过 2 次,所以它不是一个有效的 repeatLimitedString 。
贪心解法,当然看题解还有运用双指针实现的,感兴趣的读者可以去了解一下:
class Solution {
public:
string repeatLimitedString(string s, int repeatLimit) {
vector<int> cnt(26);
for(int i=0;i<s.size();i++){
cnt[s[i]-'a']++;
}
int cur=25;
int pre=cur-1;
int m=0;
string res;
while(cur>=0&&pre>=0){
if(cnt[cur]==0){
cur--;
m=0;
}
else if(m<repeatLimit){
cnt[cur]--;
res.push_back('a'+cur);
m++;
}
else if(pre>=cur||cnt[pre]==0){
pre--;
}
else{
res.push_back('a'+pre);
cnt[pre]--;
m=0;
}
}
return res;
}
};
83. 删除排序链表中的重复元素
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:

输入:head = [1,1,2]
输出:[1,2]
示例 2:
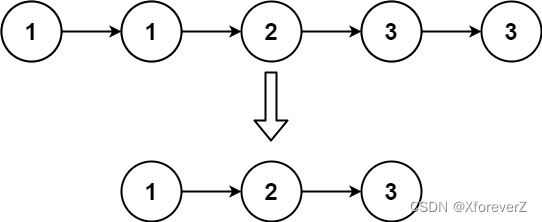
输入:head = [1,1,2,3,3]
输出:[1,2,3]
提示:
链表中节点数目在范围 [0, 300] 内
-100 <= Node.val <= 100
题目数据保证链表已经按升序 排列
遍历实现:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (!head) {
return head;
}
ListNode* cur = head;
while (cur->next) {
if (cur->val == cur->next->val) {
cur->next = cur->next->next;
}
else {
cur = cur->next;
}
}
return head;
}
};