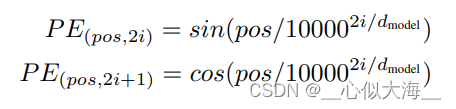redis可以存储键与5种不同数据结构类型之间的映射:
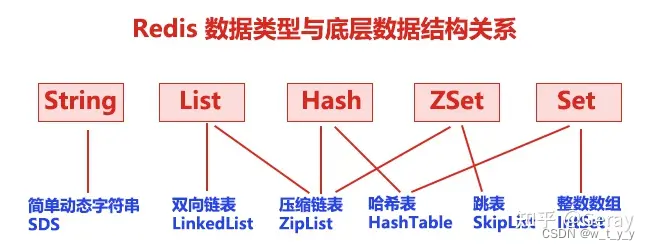
String类型的底层实现只有一种数据结构,也就是动态字符串。而List、Hash、Set、ZSet都由两种底层数据结构实现。通常我们把这四种类型称为集合类型,它们的特点是一个键对应了一个集合的数据。下面分别介绍下
一、STRING字符串:
1、介绍:redis没有直接使用C语言传统的字符串表示,而是自己实现的叫做简单动态字符串SDS的抽象类型。C语言的字符串不记录自身的长度信息,而SDS则保存了长度信息,内部结构实现上类似于 Java 的ArrayList,这样将获取字符串长度的时间由O(N)降低到了O(1),同时可以避免缓冲区溢出和减少修改字符串长度时所需的内存重分配次数;
- 对C语言中的字符串的封装和优化,c语言字符串不是二进制安全的,字符串中间不能有空格,空格标志结束
- 频繁修改一个字符串时,会涉及到内存的重分配,比较消耗性能。(Redis中的简单动态字符串会有内存预分配和惰性空间释放)。
- 如果字符串实际使用长度len<1M,实际分配空间=len长度来存储字符串+1字节存末尾空字符+len长度的预分配空闲内。
- 如果字符串实际使用长度len>1M,实际分配空间=len长度来存储字符串+1字节存末尾空字符+1M长度的预分配空闲内存
2、底层数据结构:简单动态字符串(free、len、buf[])(可以保存文本+二进制+不会缓冲溢出+获取字符串长度时间[O1]);
3、大小:当字符串长度小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。需要注意的是字符串最大长度为 512M;
4、基本命令:set,get,strlen,exists,decr,incr,setex 等等;
set num 1;incr num【计数器】,expire key 60;ttl key 【设置过期时间+查看指定key的过期时间】;
5、应用场景:计数;
二、LIST列表:
1、底层数据结构:链表,链接上的每个节点都包含了一个字符串。
Redis中list是由两种数据结构构成的,数据少时用ziplist,数据多时用linkedlist(ziplist连锁更新耗时),当列表弹出了最后一个元素之后,该数据结构自动被删除,内存被回收。
扩展:也可将list模拟队列和栈的使用。

列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成 quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间,而且会加重内存的碎片化。
比如这个列表里存的只是 int 类型的数据,结构上还需要两个额外的指针 prev 和 next 。所以 Redis 将链表和 ziplist 结合起来组成了 quicklist。也就是将多个ziplist 使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
linkedlist维护前后指针,占内存空间,还造成内存碎片化
ziplist没有前后指针,entry保存了上一个结点长度,所以也可以双向遍历,但是当一个结点长度变化了,后面结点都要变,连锁更新耗时
ziplist结构:
- zlbytes:整个ziplist占字节数
- zltail:尾结点相对于首地址偏移量
- zllen:结点数
- entry:保存了前一个结点长度+编码+内容
- zlend:代表结束
2、基本命令:rpush、lpop、lpush、rpop,、lrange、llen 等。
3、应用场景:
(1)发布与订阅或者说消息队列: Redis 的列表结构常用来做异步队列使用。将需要延后处理的任务结构体序列化成字符串塞进 Redis 的列表,另一个线程从这个列表中轮询数据进行处理;
(2)慢查询。
三、SET集合:
四、HASH字典:
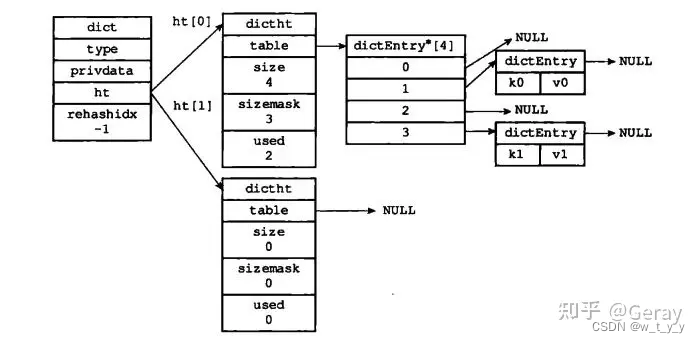
1、底层数据结构:Redis 的字典相当于 Java 语言里面的 HashMap,它是无序字典。内部实现结构上同Java 的 HashMap 也是一致的,同样的数组 + 链表二维结构。第一维 hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。
不同的是,Redis 的字典的值只能是字符串,另外它们 rehash 的方式不一样,因为Java 的 HashMap 在字典很大时,rehash 是个耗时的操作,需要一次性全部 rehash。Redis 为了高性能,不能堵塞服务,所以采用了渐进式 rehash 策略。
(1)触发rehash的时机:
字典类型容量变化过程叫做rehash,需要满足一定的条件才能触发扩容机制。服务器当前没有进行BGWRITEAOF或者BGSAVE命令,且当前键值对个数超过一维数组的大小,才会触发扩容。
如果当前键值对个数超过一维数组大小的五倍,无论是否在进行BGWRITEAOF或者BGSAVE命令,都会强制扩容。 Hash类型扩容后数组的长度为原来的二倍
缩容机制:如果当前键值对个数少于一维数组大小的十分之一,则触发缩容过程。缩容不会考虑当前服务器是否在进行BGWRITEAOF或者BGSAVE命令。
(2)Rehash过程
利用了两个哈希表进行的 , 有点类似数据库的迁移 , 读的时候先读旧库 , 读不到读新库 , 写的时候只写新库 ; 其他旧数据一点点的往新库上搬。
当触发扩容的时候,Redis会首先为ht[1] 分配一块内存空间。如果当前字典是一个比较大的字典,那么整个扩容过程的时间复杂度为O(n),直接完整进行扩容机制可能会导致Redis一段时间内停止服务。为了避免停止服务的情况,Redis的设计团队采用了渐进式rehash的策略,每次只对原哈希表中的一小部分进行搬迁,这样渐进式的进行,直到全部键值对都迁移到新的哈希表中。
首先,对于key的查询,我们需要到原来的哈希表中进行查找,如果找到对应的value,直接返回就可以了。如果没有找到,那么只有两种可能,一个是这个键值对已经搬迁到新的哈希表了,另外一种可能是根本就不存在这个键值对,无论是哪种可能,我们都需要再去新哈希表中对他进行查找,如果找到了就返回,如果找不到说明这个键值对不存在。
五、ZSET有序集合: