综合实验报告格式
综合实验题目
一、人员和分工
LenckCuak
二、问题描述和基本要求
1、 用哈夫曼编码设计一个压缩软件;
2、 能对输入的任何类型的文件进行哈夫曼编码,产生编码后的文件——压缩文件;
3、 能对输入的压缩文件进行译码,生成压缩前的文件——解压文件;
4、 要求编码、译码效率尽可能地高;(额外加分)
5、 撰写实验报告。
三、工具/准备工作
2.1 综合实验中涉及的数据结构知识。
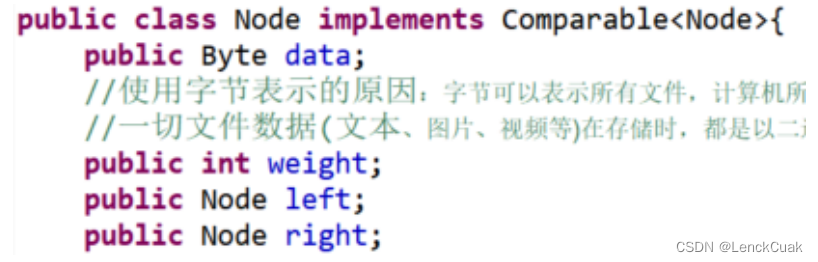
2.1.1 自定义节点
通过对基本要求的分析,确立哈夫曼树节点所需要的基本元素,即字节数据、权重、左右孩子节点。
2.1.2 哈夫曼编码采用“树型结构”
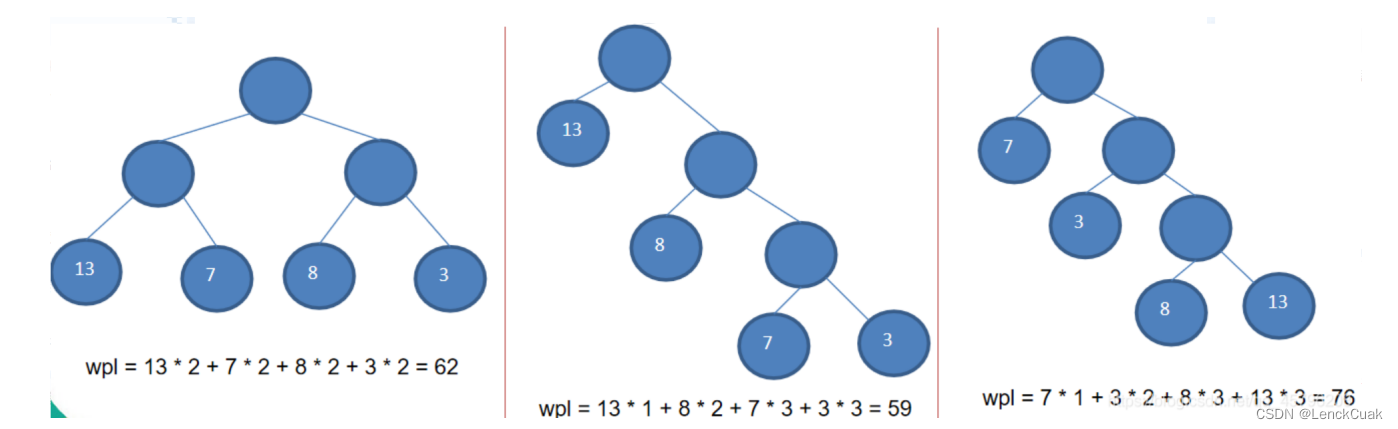
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若 根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。树的路径长度是从树根 到每 一结点的路径长度之和,记为WPL=(W1*L1+W2*L2+W3*L3+...+Wn*Ln),N个 权值Wi(i =1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,...n)。可以证明哈夫曼树的WPL是最小的。
2.2 使用的集成开发环境。
程序使用前三大 Java IDE 之一的eclipse编写,版本为JavaSE-1.8。
四、分析与实现
下图为本文算法的架构图。

4.1分析综合实验项目的实现方法(围绕基本要求)
4.1.1 输入输出文件(压缩过程)
依据文档要求,用户需要输入源文件和目标文件名,那么如何将提取源文件内容是重点,常见的提取方式是提取源文件的字符,即采用char数组存储,然而这种方式只能实现对文本文件的压缩和解压,不能对非文本文件进行压缩和解压,并且要实现任何文件的哈夫曼编码,只能对源文件中的字节进行哈夫曼编码,而采用int数组在实现转换字节的理解和编程上困难,故本文采用byte数组进行模拟,并且通过输入流提取源文件的字节数组。在实现上,采用FileInputStream和FileOutputStream作为输入输出流;在提取源文件字节数组上,采用FileInputStream::available()函数来构建一个与源文件字节数组大小的字节数组,并且使用FileInputStream::read(byte[]b)来将源文件的字节数组赋值给构建的字节数组b;在构建输出文件的实现上,采用ObjectOutputStream(FileOutputStream),构造对象输出流,采用对象输出流的原因是可以将不同对象进行写入,而在提取时可以按照对象类别进行提取,而不会混乱,便于解压,然后将哈夫曼编码后的字节数组b(4.1.5)通过ObjectOutputStream::writeObject(Byte[]b)构建压缩后的文件,通过向对象输出流写入哈夫曼编码后的字节数组和哈夫曼编码字典map便于解压。
4.1.2 将源文件字节数组转化为具有权重和字节数据的节点数组
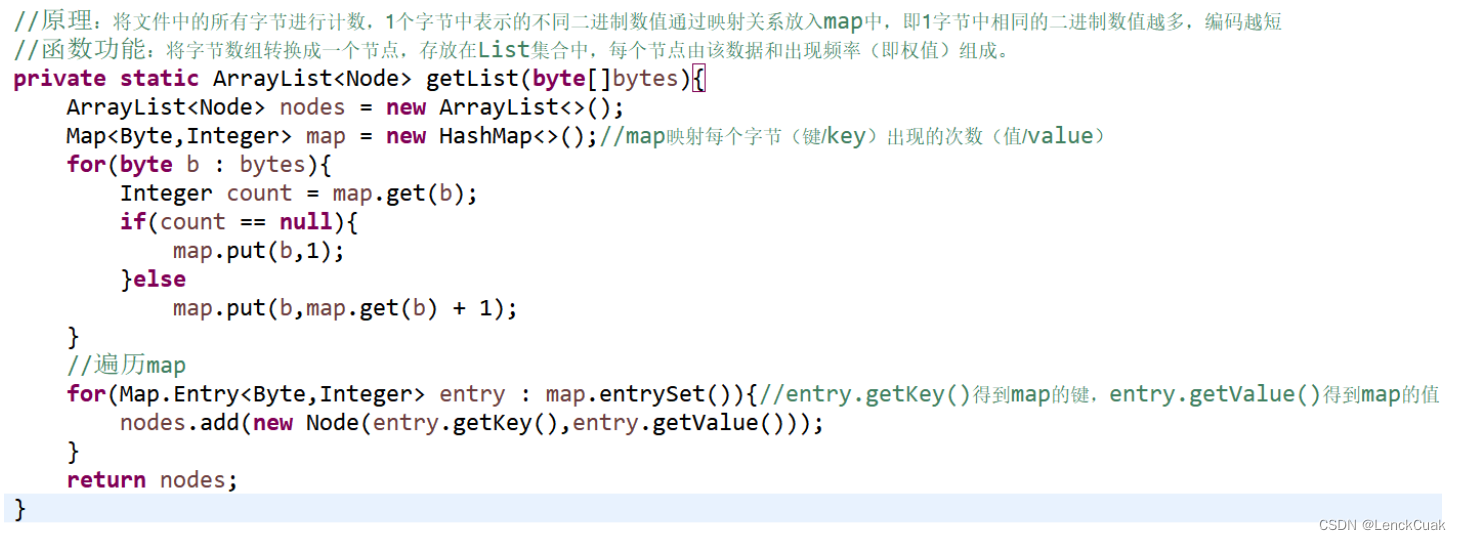
通过遍历4.1.1提取到的源文件字节数组来计算不同字节的出现频率。使用ArrayList<Node> 来存储节点,用Map<Byte,Integer>来存储不同字节对应的权重(出现频率)。其中节点由字节数据、权重组成,每个节点可以访问其左右孩子节点。
4.1.3 采用优先队列将节点数组转换为哈夫曼树,减小时间复杂度
通过将4.1.2得到的节点数组转为优先队列,由于优先队列的特殊性,在每次插入和删除节点时都会调整堆结构,从而维持整个优先队列是一个最小堆的结构。由于节点是自定义类型,所以要重载节点的比较操作。通过判断优先队列的大小是否大于1来进行,若大于1则重复下面操作:提取堆顶节点,删除堆顶节点,再提取堆顶节点,将这两个节点作为新父节点的两个孩子节点,新的父节点的数据设置为空,将父节点加入到优先队列中;若小于等于1时,则说明已构成一棵树,那么哈夫曼树构建完成。且优先队列的唯一节点即为哈夫曼树的根节点。
采用优先队列使得建树的时间复杂度减小为O(nlog(n)),相比于原参考资料和大多资料的建树时间复杂度(n^2log(n))更加迅速。
4.1.4 生成哈夫曼编码
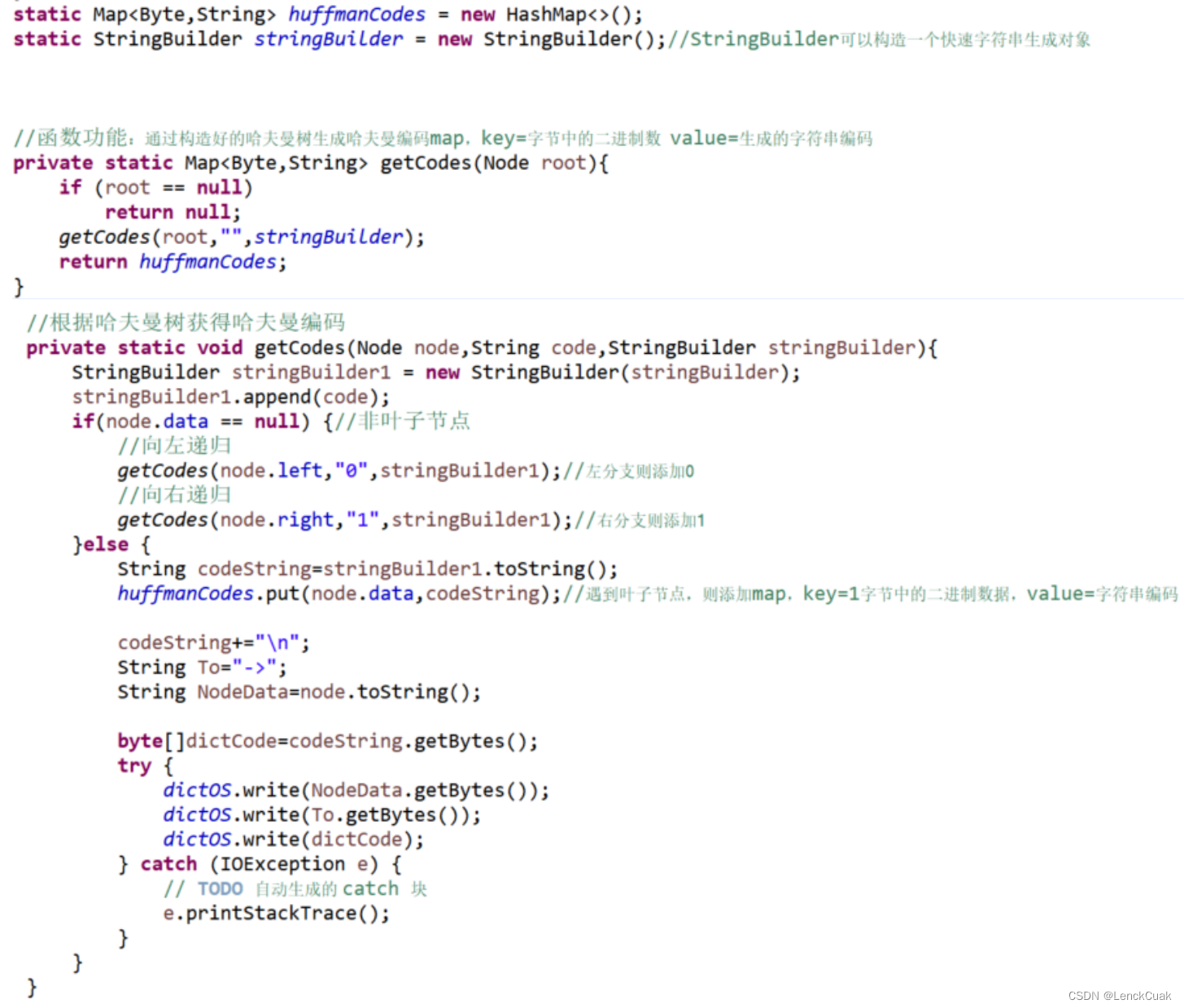
通过将4.1.3构造好的哈夫曼树生成哈夫曼编码map,其中key=节点的字节值,value=生成的字符串编码。在实现上,采用StringBuilder构造器来拼接哈夫曼编码字符串,而不采取String,拼接速度比String更加迅速。通过递归进行向哈夫曼树的左右孩子节点进行遍历,并且向左延伸时哈夫曼编码加“0”,向右时哈夫曼编码加“1” 。判断是否为叶子节点的依据是根据上述4.1.3构建父节点时将父节点的数据置为空。当递归到叶子节点时,将节点的字节值作为哈夫曼编码map的key,将对应的哈夫曼编码字符串作为map的value。同时此处也将生成字典文件。
4.1.5 将源文件的字节数组替换为经哈夫曼编码后的字节数组
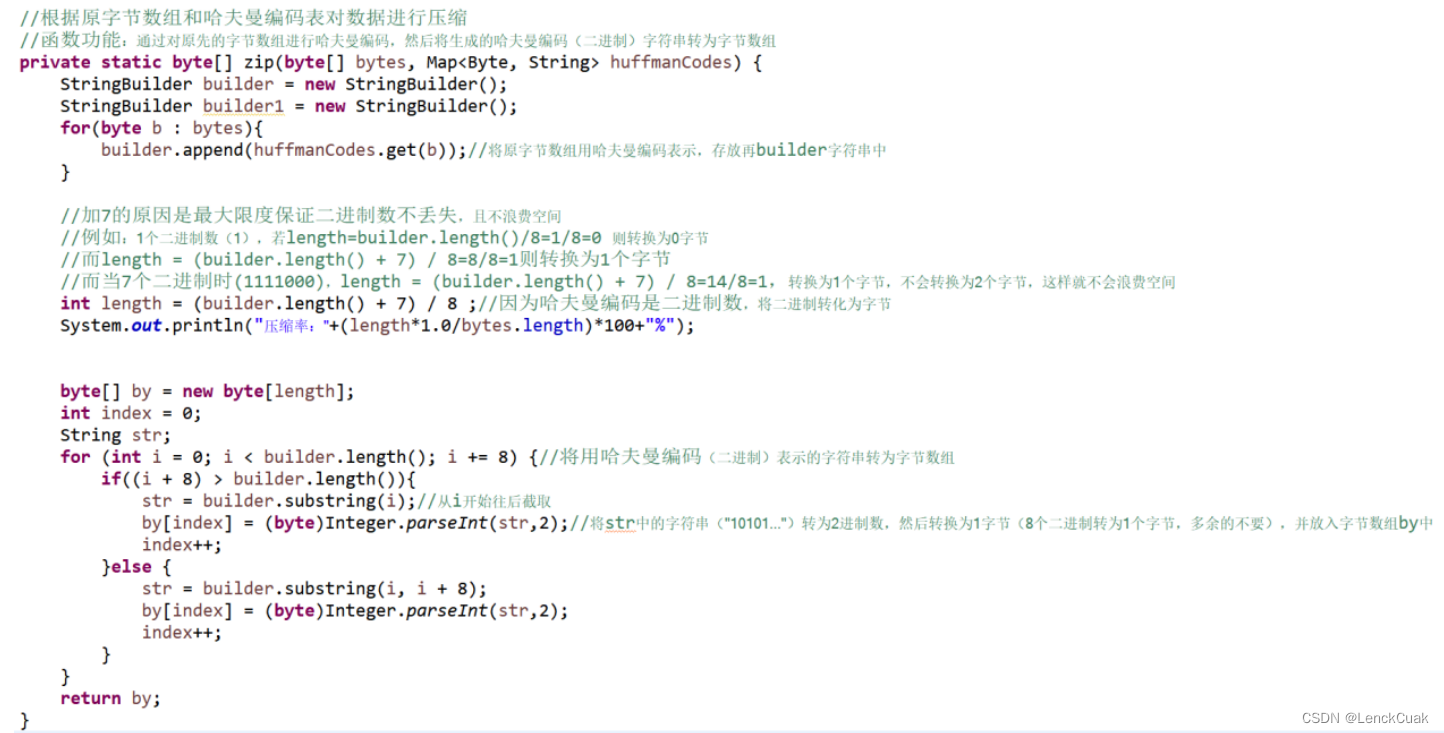
使用4.1.4得到的哈夫曼编码对4.1.1提取到的源文件字节数组进行一一替换,从而实现哈夫曼压缩。在实现上,使用StringBuilder构造器实现哈夫曼编码字符串的拼接。同时新建一个字节数组用以输出压缩后的文件,新建字节数组的大小依据源文件字节数组的哈夫曼编码字符串的长度构造,由于哈夫曼编码是0101的二进制数据,而1个字节含有8个二进制数,所以构造的新字节数组的长度为(哈夫曼编码字符串长度+7)/8,这样的做法不会丢弃任何二进制数,并且最大限度避免了空间浪费。例如:1个二进制数(1),若length=builder.length()/8=1/8=0 则转换为0字节而length = (builder.length() + 7) / 8=8/8=1则转换为1个字节而当7个二进制时(1111000),length = (builder.length() + 7) / 8=14/8=1,转换为1个字节,不会转换为2个字节,这样就不会浪费空间。在将哈夫曼编码字符串转换为字节数组的操作上,由于本文是采用模拟的方式,所以全程都依据模拟的方式进行,而不能直接用字符串转为字节数组的内置函数转换。通过遍历哈夫曼编码字符串,依次截取8个二进制数通过(byte)Integer.parseInt(string,2)函数将其转为一个字节,并存储在新建的字节数组中;若哈夫曼编码最后的二进制字符串不足8个时,也是如此。这样就构建好了哈夫曼编码后的字节数组。
4.1.6 输入输出文件(解压过程)
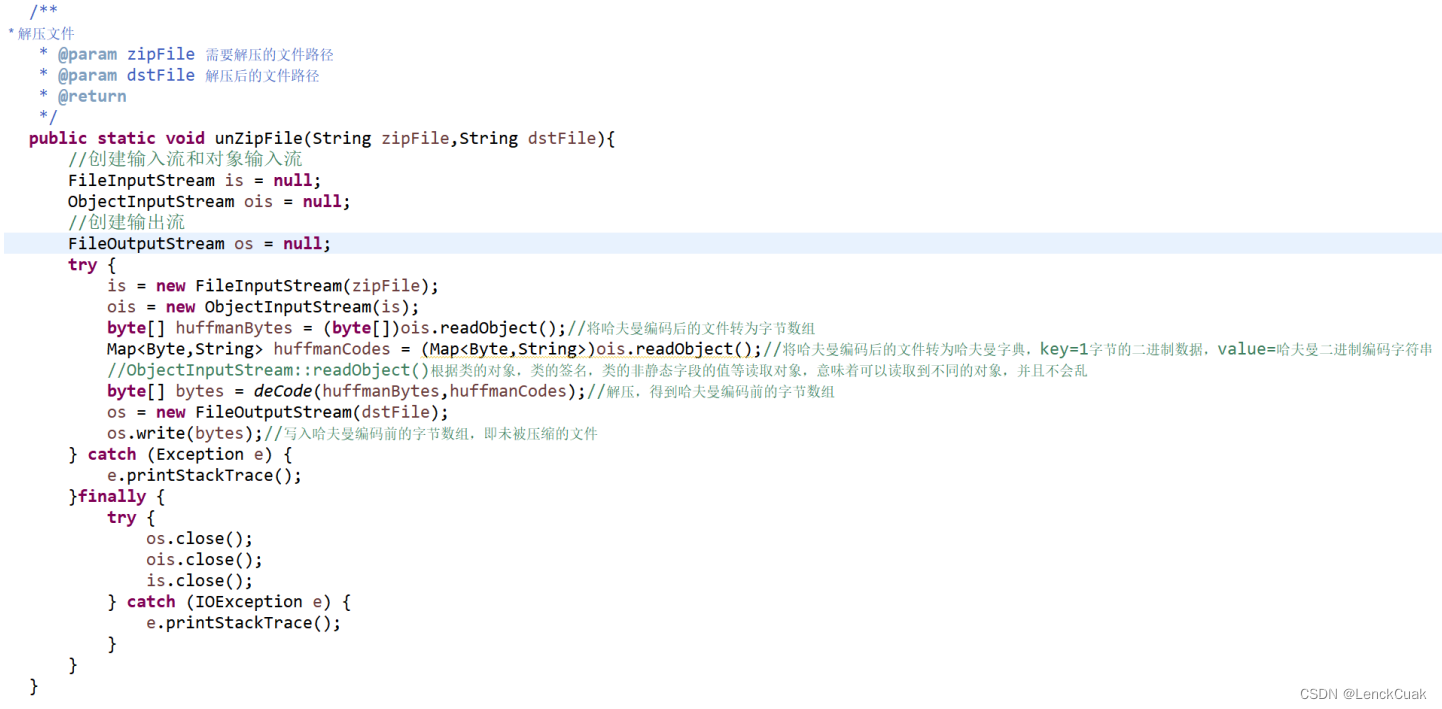
与4.1.1一样,采用输入输出流分别对压缩文件和目标文件进行输入输出。在提取哈夫曼编码后的字节数组上,采用对象流内置函数和强转(byte[])ObjectInputStream::readObject()提取字节数组。由于4.1.1对象流的特殊性,可以将哈夫曼字典数据加入到压缩文件中,从而可以使用对象流提取出字典数据,可以避免再一次扫描源文件或额外的字典文件。具体方法是(Map<Byte,String>)ObjectInputStream::readObject()。最后通过对象流将4.1.7得到的源文件字节数组写入到文件中,得到解压后的文件。
4.1.7 将哈夫曼编码后的字节数组转为哈夫曼编码前的字节数组(源文件字节数组)
通过对4.1.6得到的哈夫曼字典map和哈夫曼编码后的字节数组可以得到源文件字节数组。在实现上,先将哈夫曼编码后的字节数组转为二进制字符串,其中通过遍历哈夫曼编码后的字节数组并使用StringBuilder构造器对每个字节生成的二进制字符串进行拼接;在将字节转为二进制字符串的实现上,首先判断该字节是否为正数,若为正数则将该字节补高位,即该字节与256进行或运算,然后使用Integer.toBinaryString(byte)进行转换为二进制字符串,最后截取将该字符串截取最后8个字符作为转换结果。这样就可以得到未压缩的文件经哈夫曼编码后的二进制字符串,最后通过新的map对哈夫曼字典进行键值反转,得到映射关系为二进制字符串到字节的逆哈夫曼编码字典。然后采用前缀编码方式对哈夫曼编码后的二进制字符串进行替换,得到字节存储在列表之中,最后将列表的字节存放在字节数组中。其中在将哈夫曼编码后的二进制字符串转为字节的前缀编码实现上,通过对二进制字符串进行遍历,使用两个变量记录二进制字符串的位置,当最前的几个二进制能够通过逆哈夫曼字典查询到数据时,即将该位置记录下来,从而实现前缀编码。
4.2采用适当的数据结构与算法(Why、What、How)
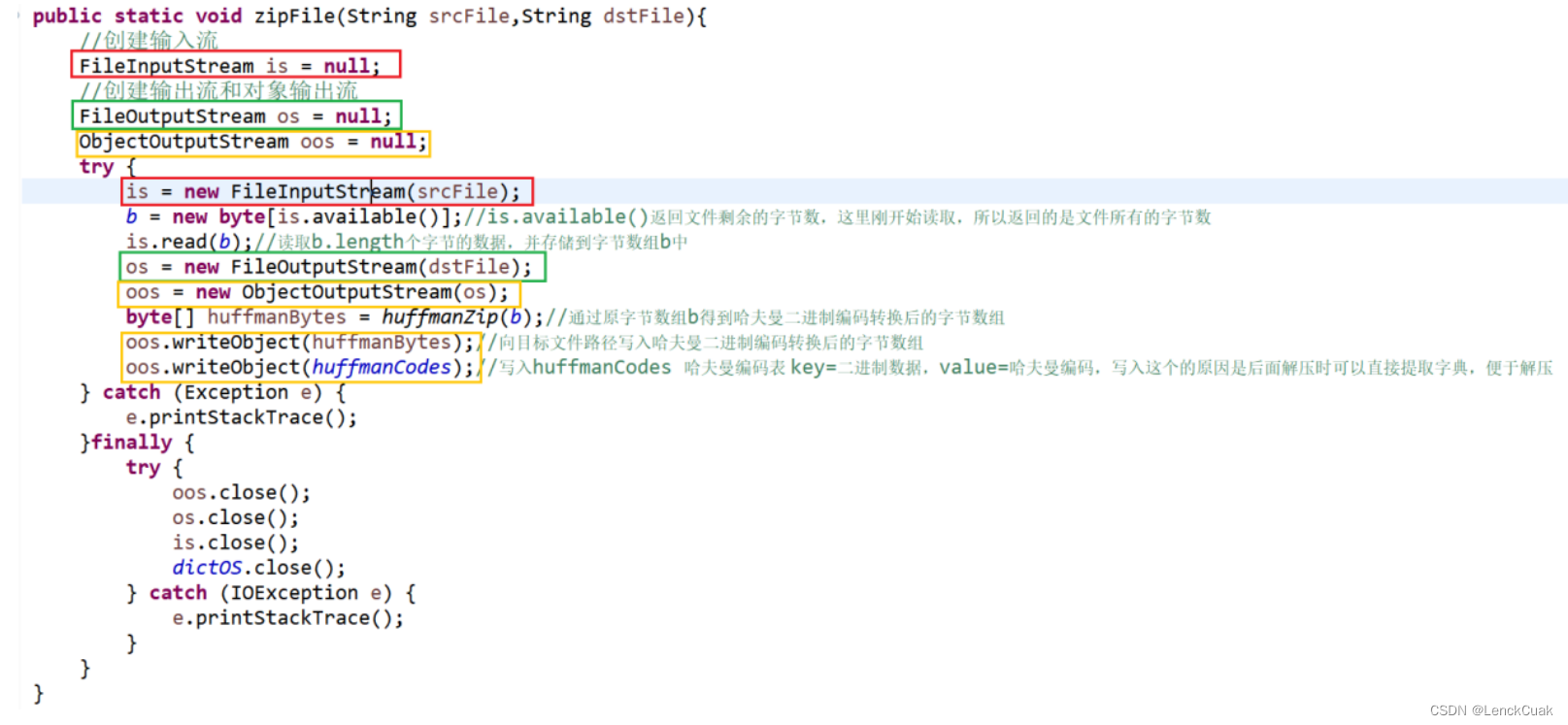
4.2.1 输入输出文件
用户输入源文件和目标文件名,分别赋值于zipFile函数的srcFile和dstFile字符串中。通过创建输入流(下图红色矩形框)和输出流(下图绿色矩形框)来接收源文件和写入文件,其中写入文件使用对象流(下图黄色矩形框)写入,采用对象流写入的原因是对象流可以将不同对象进行写入,并且在解压时可以按照对象类别进行提取,提取的内容只会包含同一种类别,本文通过向目标文件路径写入哈夫曼二进制编码转换后的字节数组和huffmanCodes(哈夫曼编码表)其中key=二进制数据,value=哈夫曼编码,写入这个的原因是后面解压时可以直接提取字典,便于解压。
通过FileInputStream::read(byte[]b)可以将源文件的字节数据赋值给字节数组b中。
具体实现方法如下图:其中的函数功能和原理在下面截图均有详细注释
4.2.2 将源文件字节数组转化为具有权重和字节数据的节点数组
具体算法:
节点的数据结构:

4.2.3 采用优先队列将节点数组转换为哈夫曼树,减小时间复杂度
下图为建树过程:
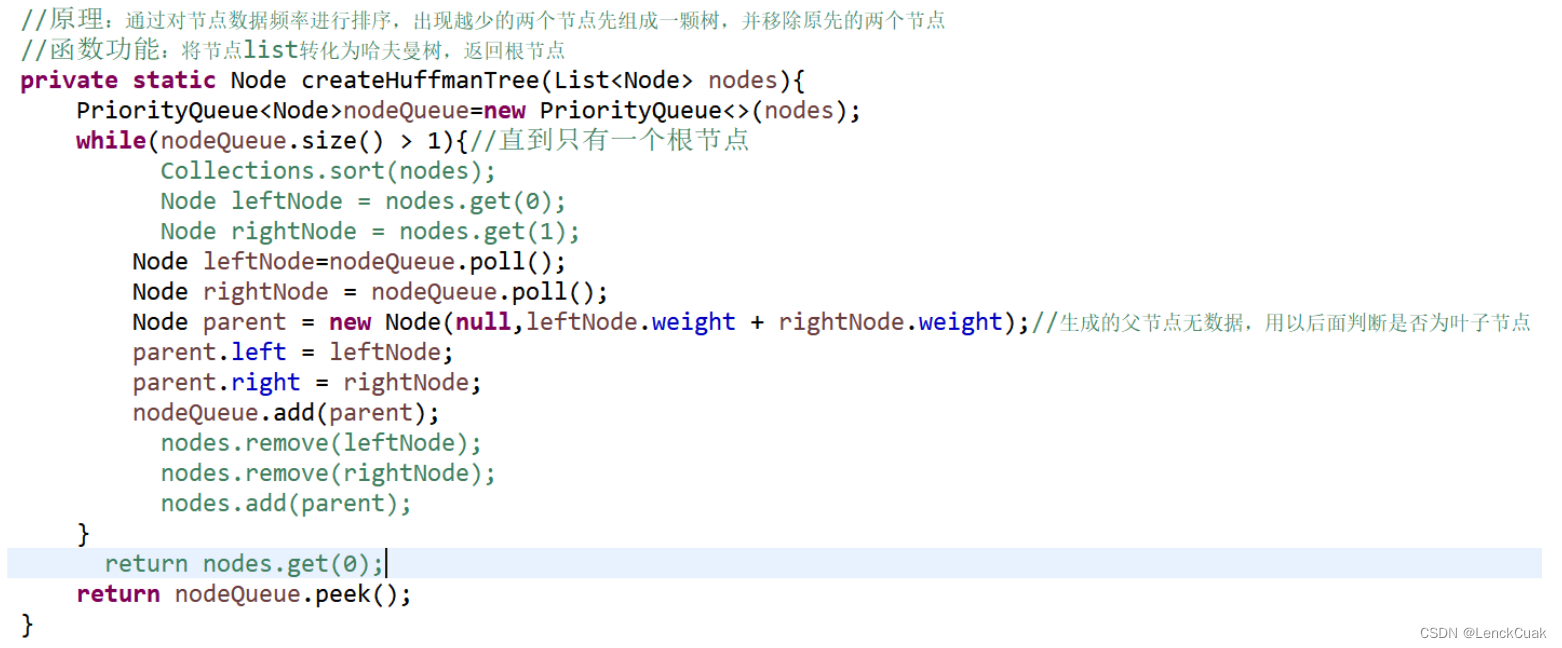
下图为使节点可比较的过程:

4.2.4 生成哈夫曼编码
4.2.5 将源文件的字节数组替换为经哈夫曼编码后的字节数组
4.2.6 输入输出文件(解压过程)
4.2.7 将哈夫曼编码后的字节数组转为哈夫曼编码前的字节数组(源文件字节数组)
五、测试与结论
1.对图像文件的压缩和解压
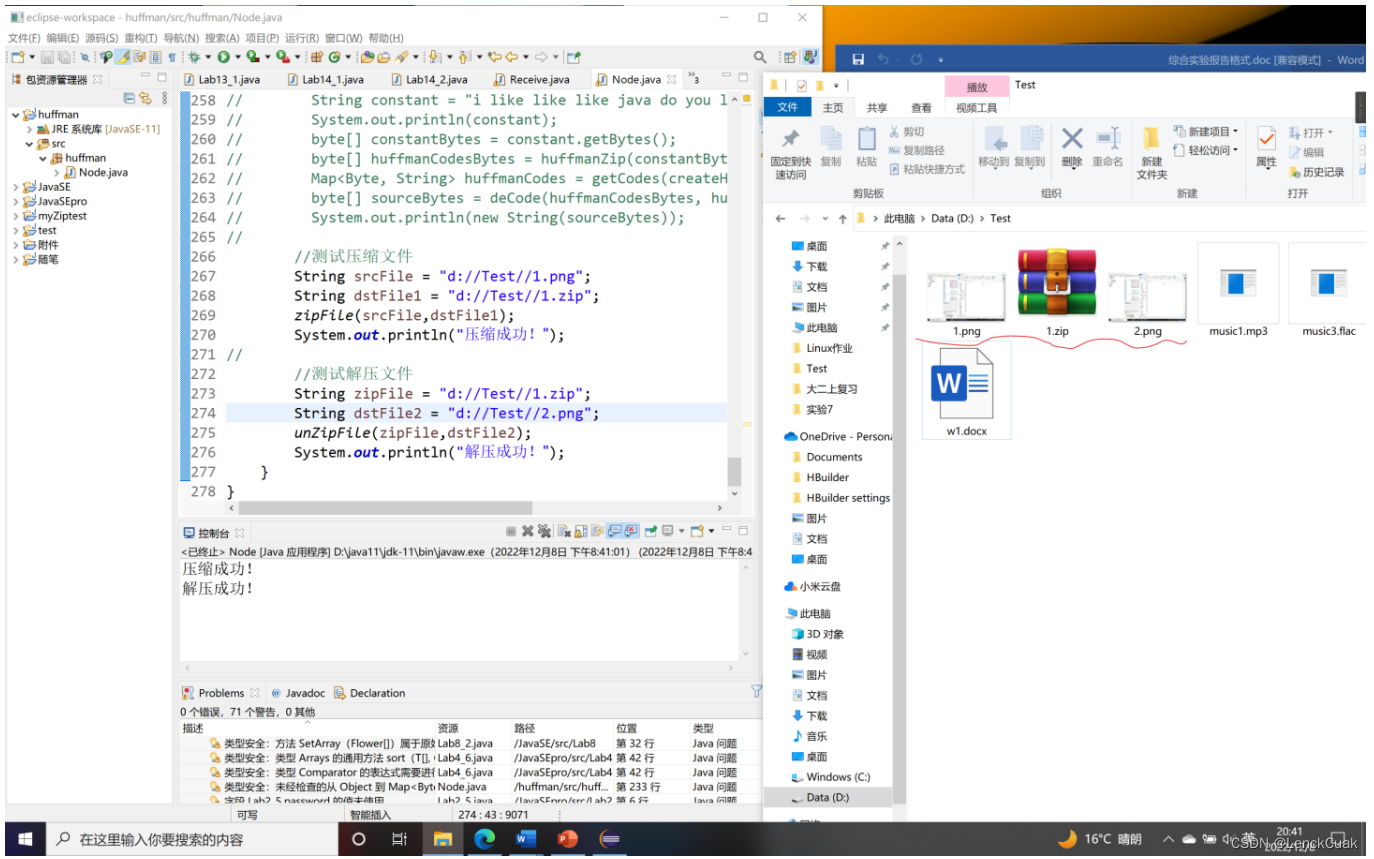
如图所示,将原文件(1.png)成功压缩为1.zip,后成功解压文件(1.zip)为2.png
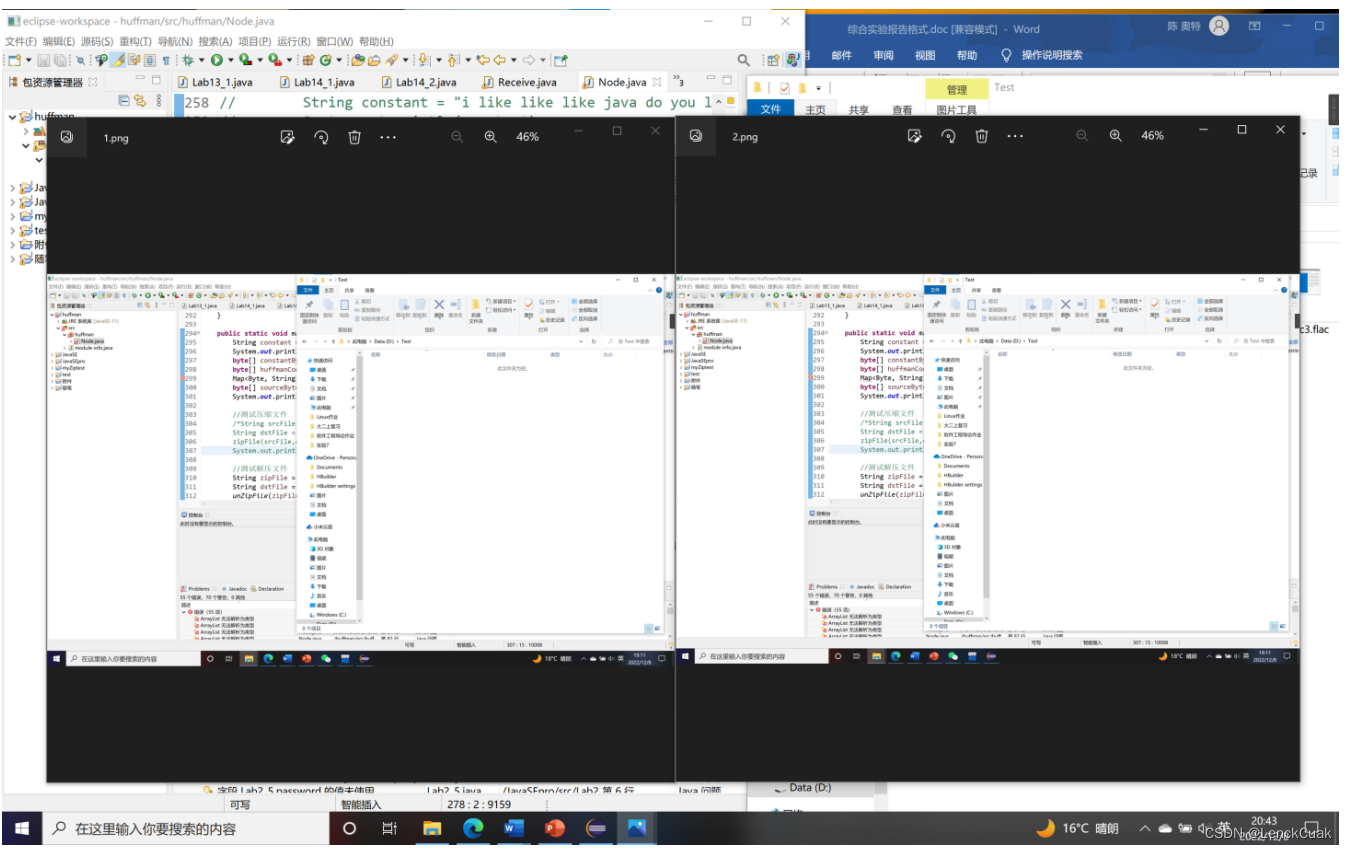
上图所示,即为原文件(1.png)和压缩再解压后的文件(2.png)对比示意图
2.对纯文本文件的压缩与解压
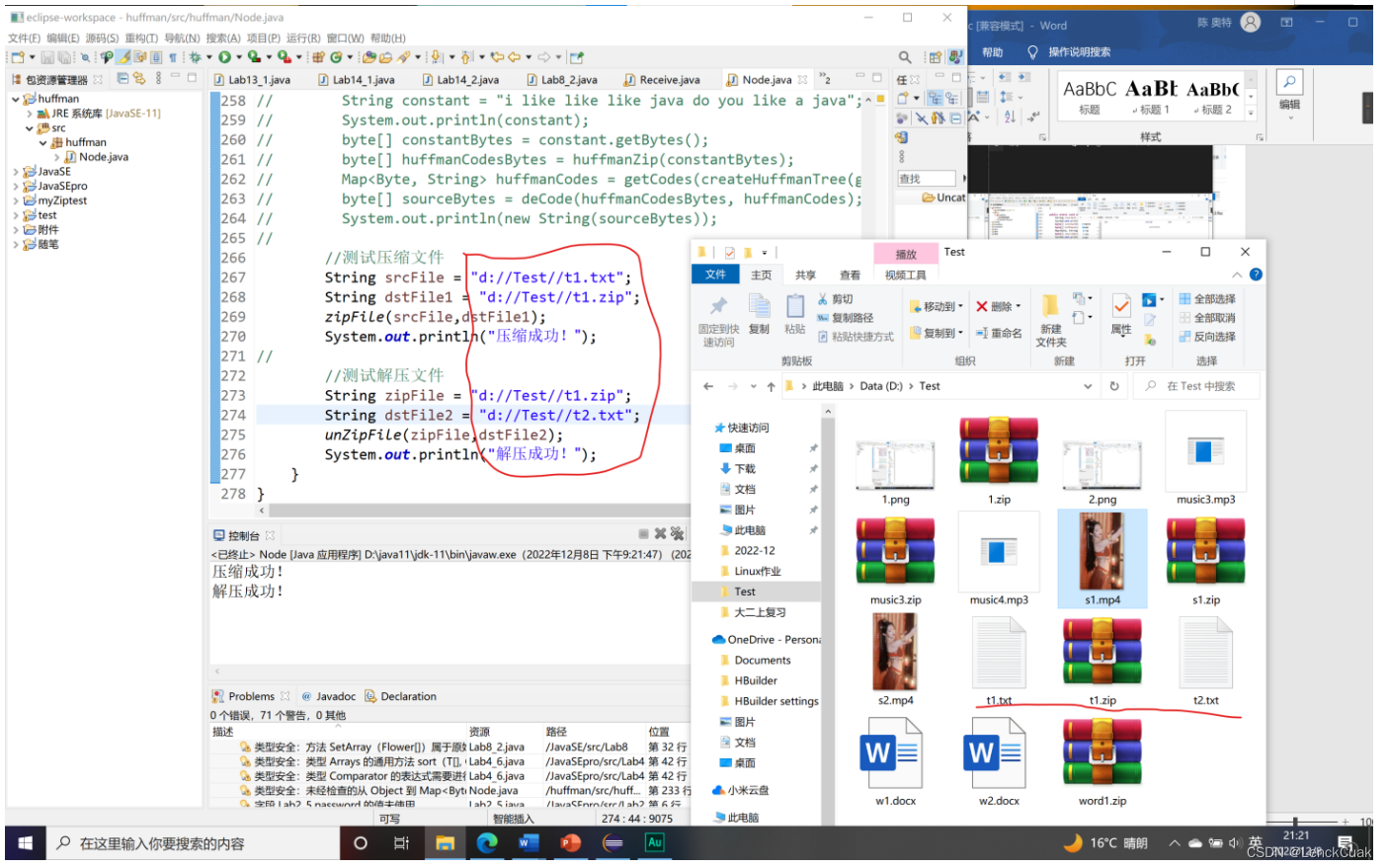
如图所示,将原文件(t1.txt)成功压缩为t1.zip,后成功解压文件(t1.zip)为t2.txt
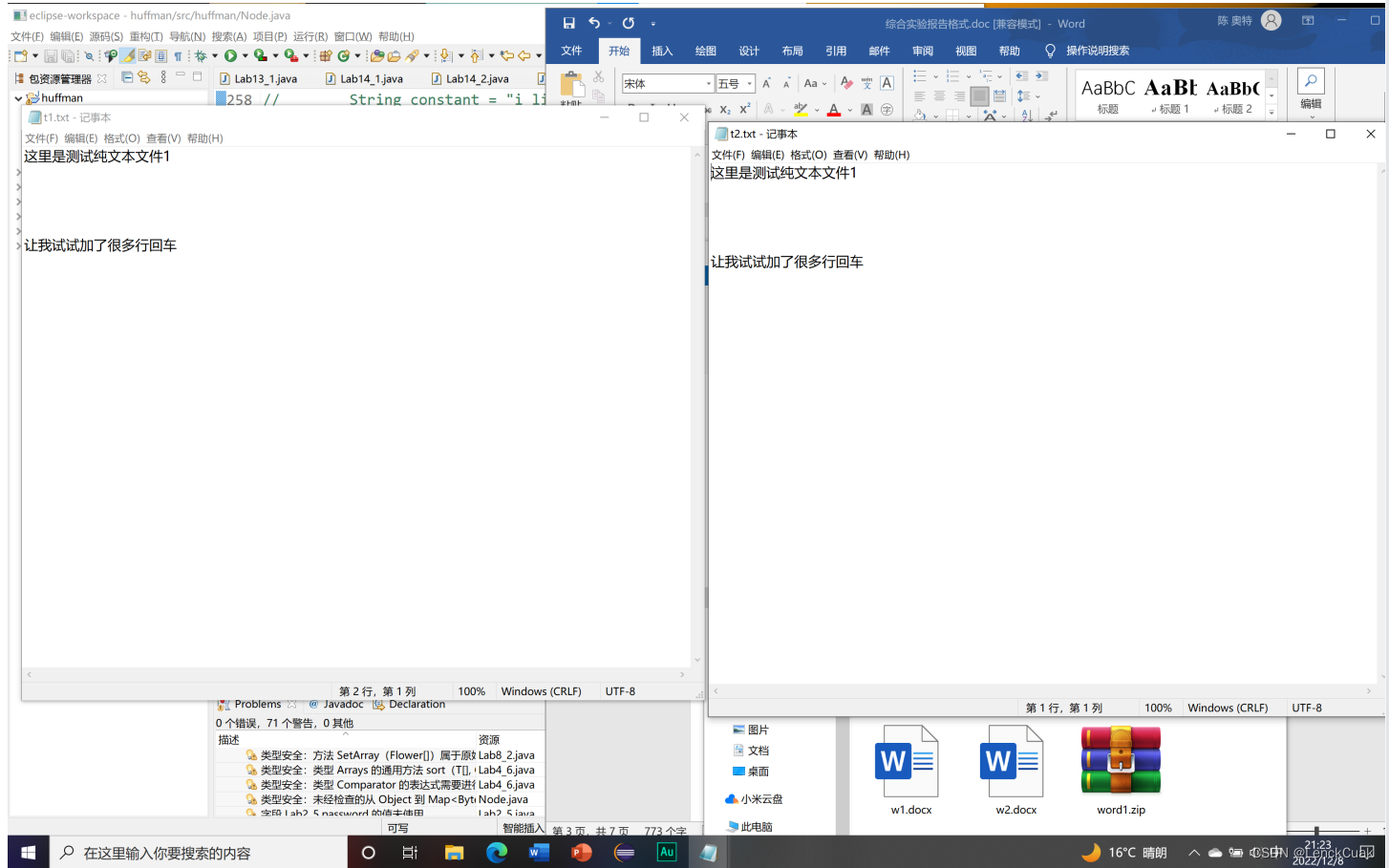
上图所示,即为原文件(t1.txt)和压缩再解压后的文件(t2.txt)对比示意图
3.对word文档的压缩和解压
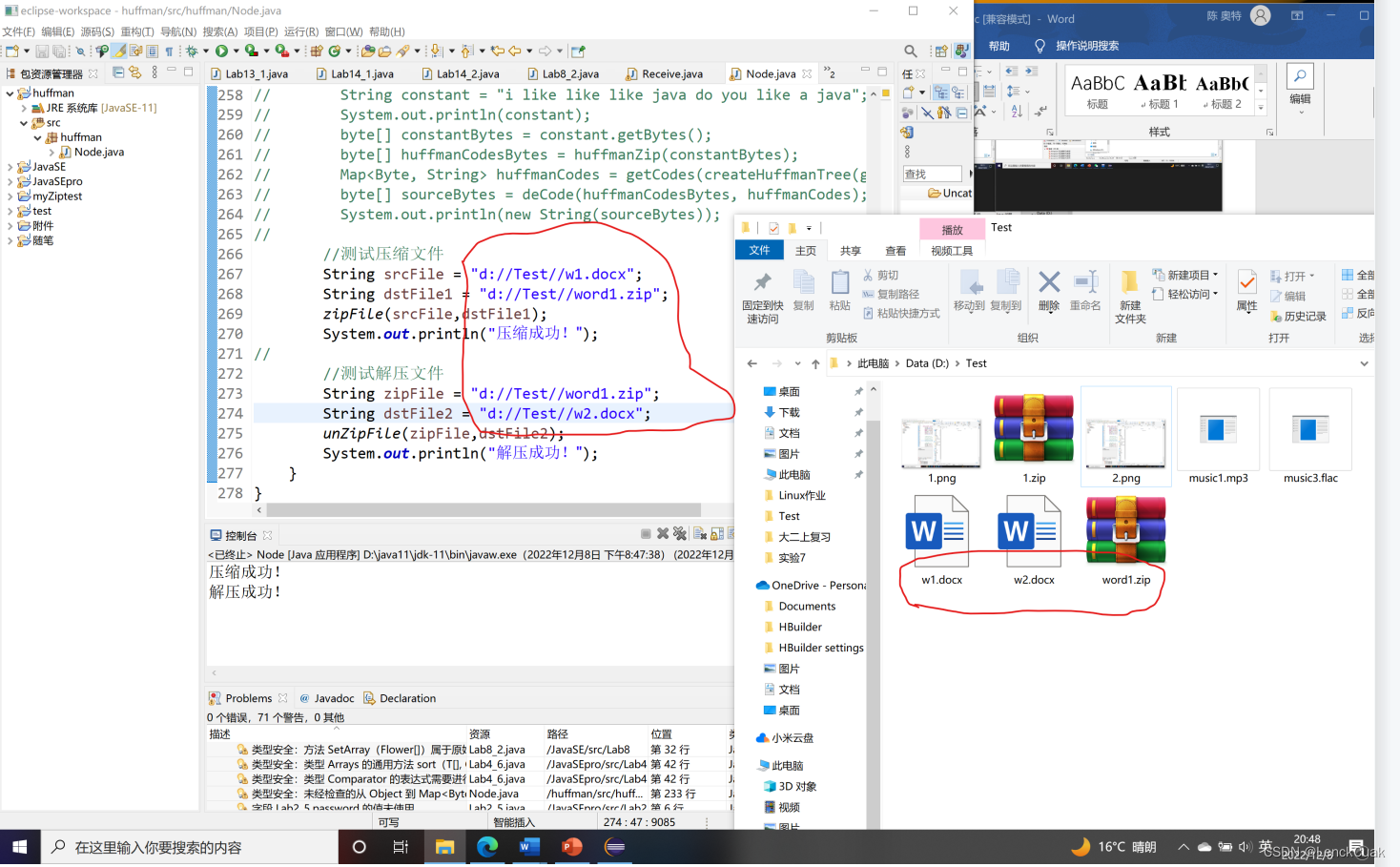
如上图所示,成功将word文件(w1.docx)成功压缩为word1.zip,后成功解压文件为w2.docx
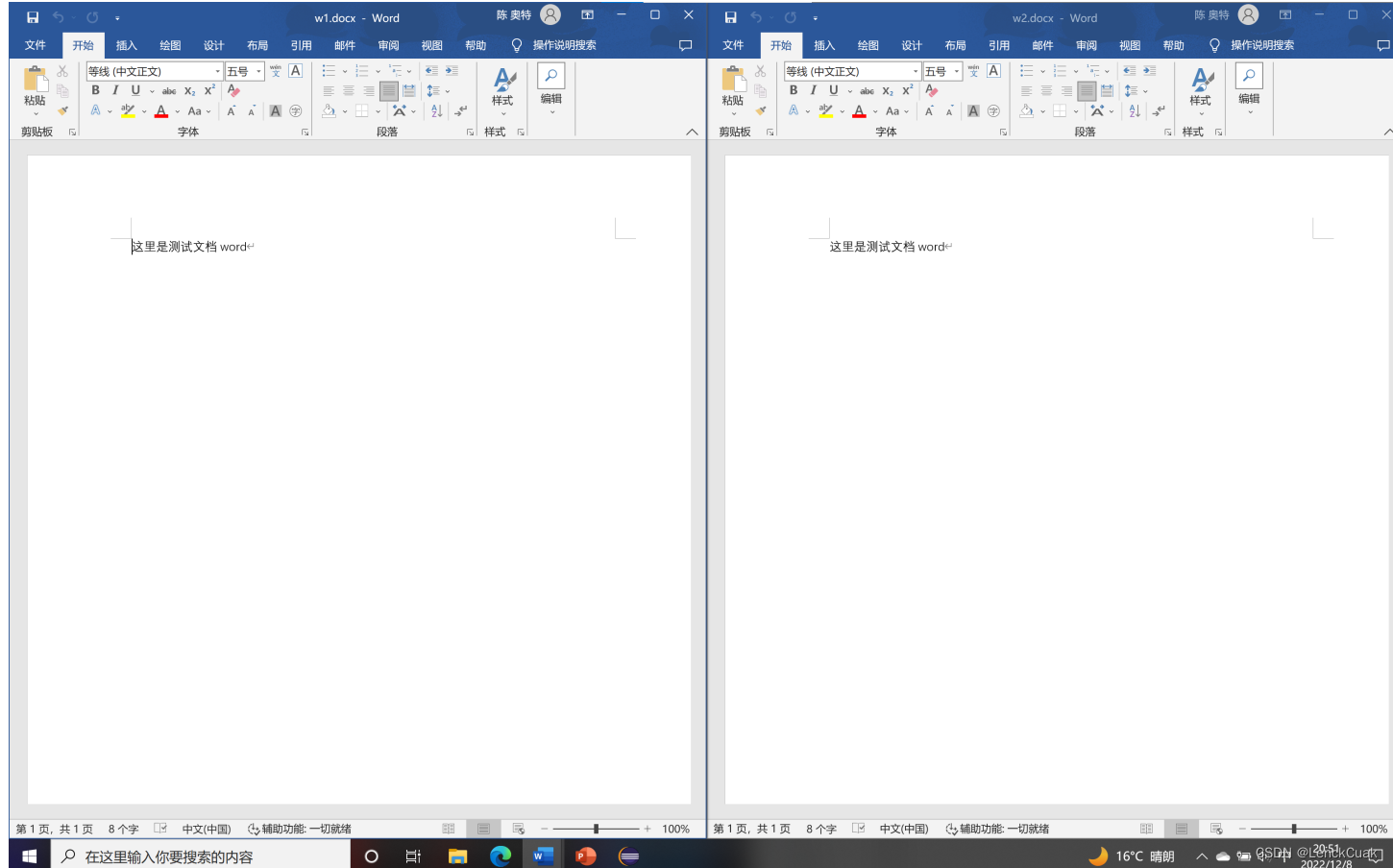
如上图所示,即为原文件和压缩解压后的文件对比示意图
4.对音频文件的压缩和解压
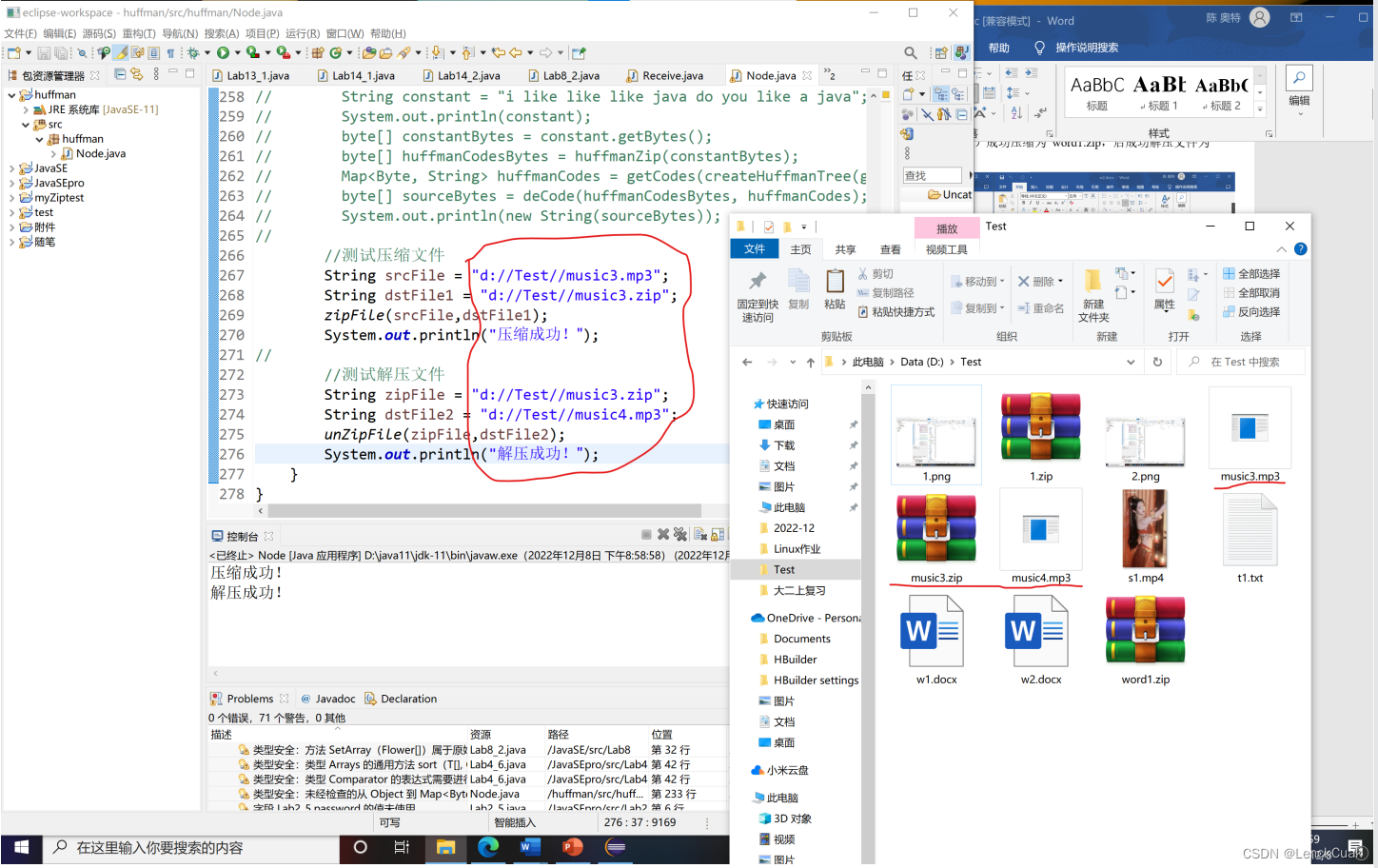
如上图所示,成功将原文件(music3.mp3)进行压缩为music3.zip后,成功地将music3.zip解压为music4.mp3
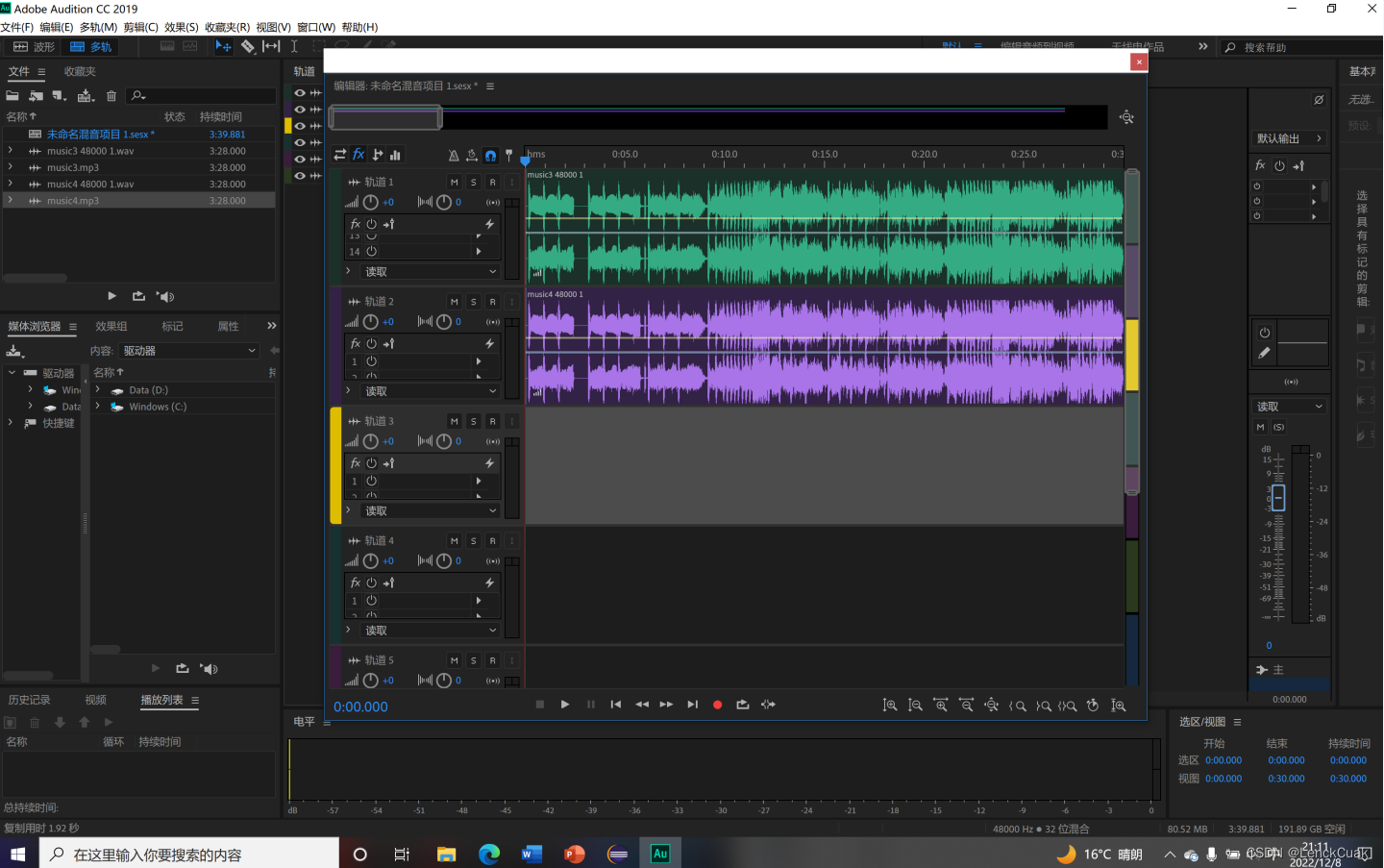
如图所示,这是原文件music3.mp3和压缩和解压后的文件music4.mp3的音频对比图
5.对视频文件的压缩和解压
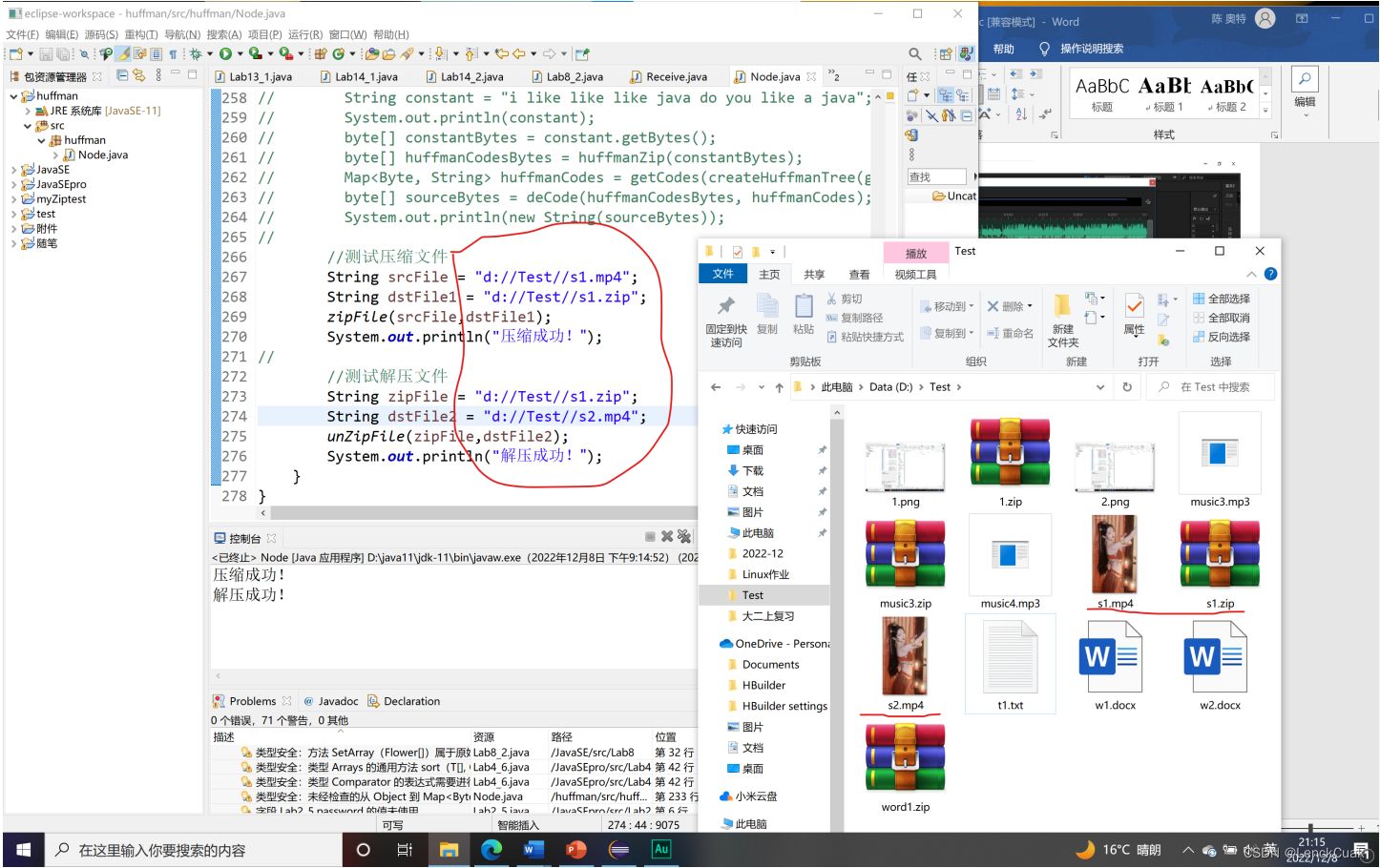
如上图所示,成功将原文件(s1.mp4)进行压缩为s1.zip后,成功地将s1.zip解压为s2.mp4
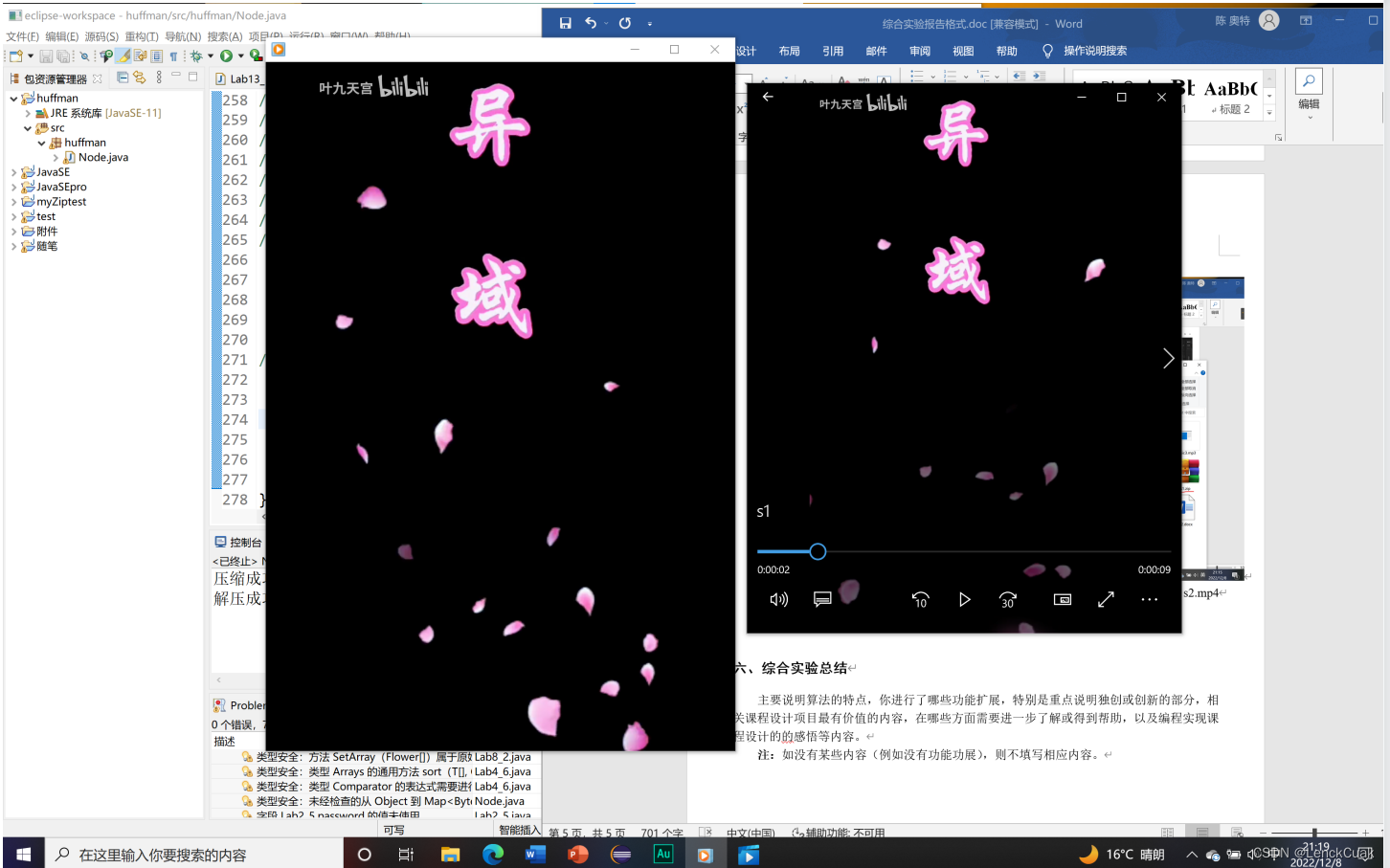
如图所示,这是原文件s1.mp4和压缩和解压后的文件s2.mp4的视频对比图
六、综合实验总结
主要说明算法的特点,你进行了哪些功能扩展,特别是重点说明独创或创新的部分,相关课程设计项目最有价值的内容,在哪些方面需要进一步了解或得到帮助,以及编程实现课程设计的的感悟等内容。
注:如没有某些内容(例如没有功能功展),则不填写相应内容。
(一)、功能拓展与创新
1. 在文件显示上通过设计字典文件和压缩率增强可视化。
本算法针对参考资料,自行设计了一个字典文件,可以将需要压缩的文件的字节所对应的权重和哈夫曼编码依次写在这个字典文件中,如下图:
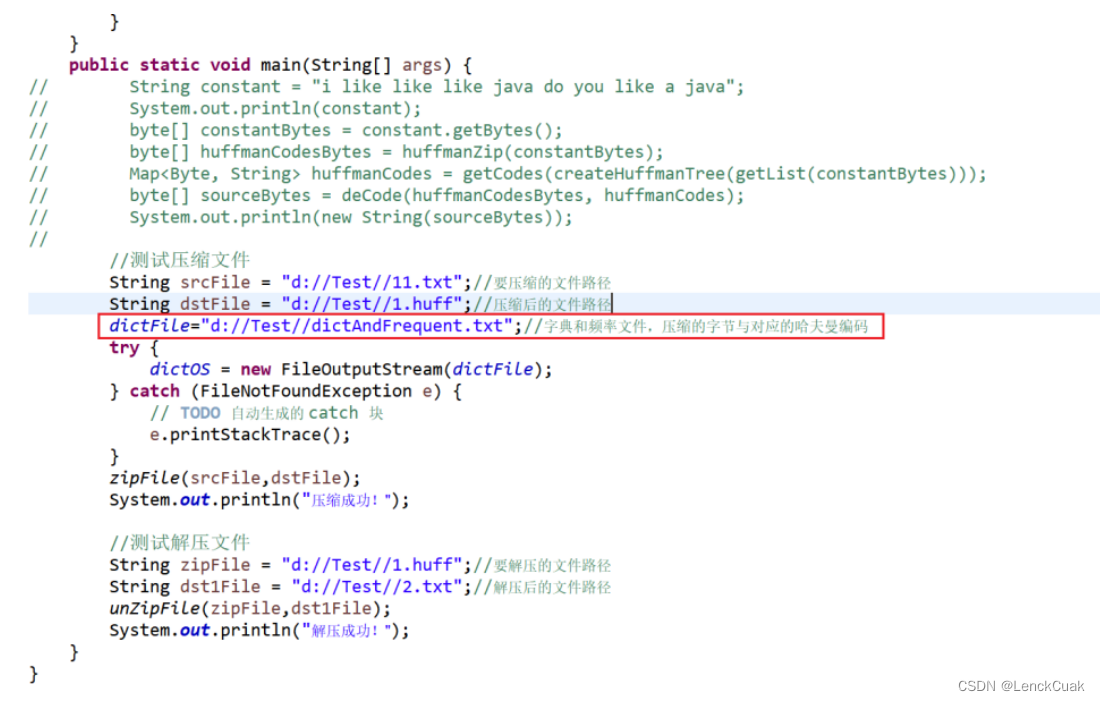
例如在需要压缩的11.txt文件中,输入一下简单的内容

对应的字典文件dictAndFrequent.txt内容如下:其中data为ascii码,weight为权重即频率,箭头所指向的为哈夫曼编码。data没有显示使用字符表示的原因是针对图片和视频以及其他非文本内容而言,可以更加直观的看到data的字节值,而不是乱码。

其中对应的解压文件2.txt内容如下:
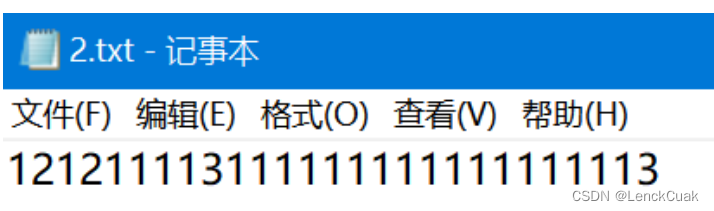
与11.txt内容完全一致,并且该算法在此文件的压缩率如下图:

意味着节省了绝大部分内存。(压缩率越低,节省空间越多)
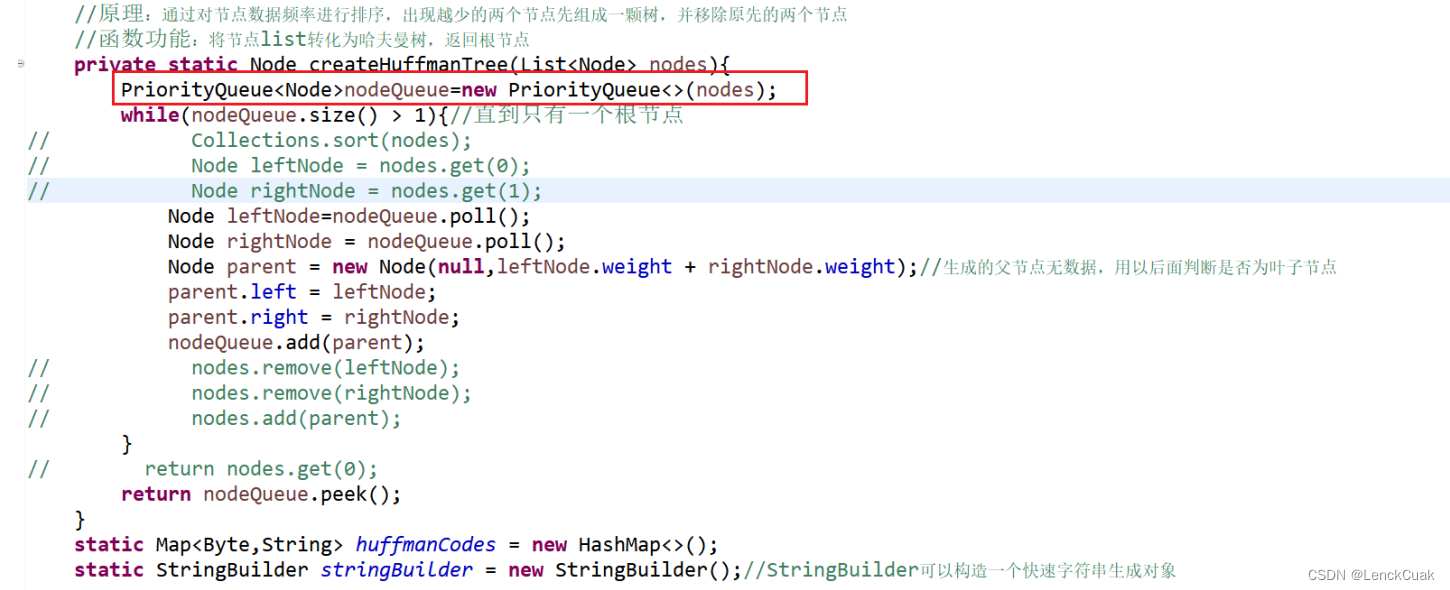
2. 减小了其中选择最小权重节点的时间复杂度。
参考资料中的代码采用Collection.sort()进行排序,而此方法的时间复杂度为O(nlog(n)),在建哈夫曼树(createHuffmanTree)这个函数的复杂度为O(n^2log(n)),而本文采用了PriorityQueue进行优化,其中PriorityQueue::poll()和PriorityQueue::add()的复杂度均为O(log(n)),且每次插入节点都可以调整堆结构,使堆一直维持最小堆的结构,从而每次只需提取根节点即可寻找到最小节点,从而将createHuffmanTree的时间复杂度减小为O(nlog(n))。
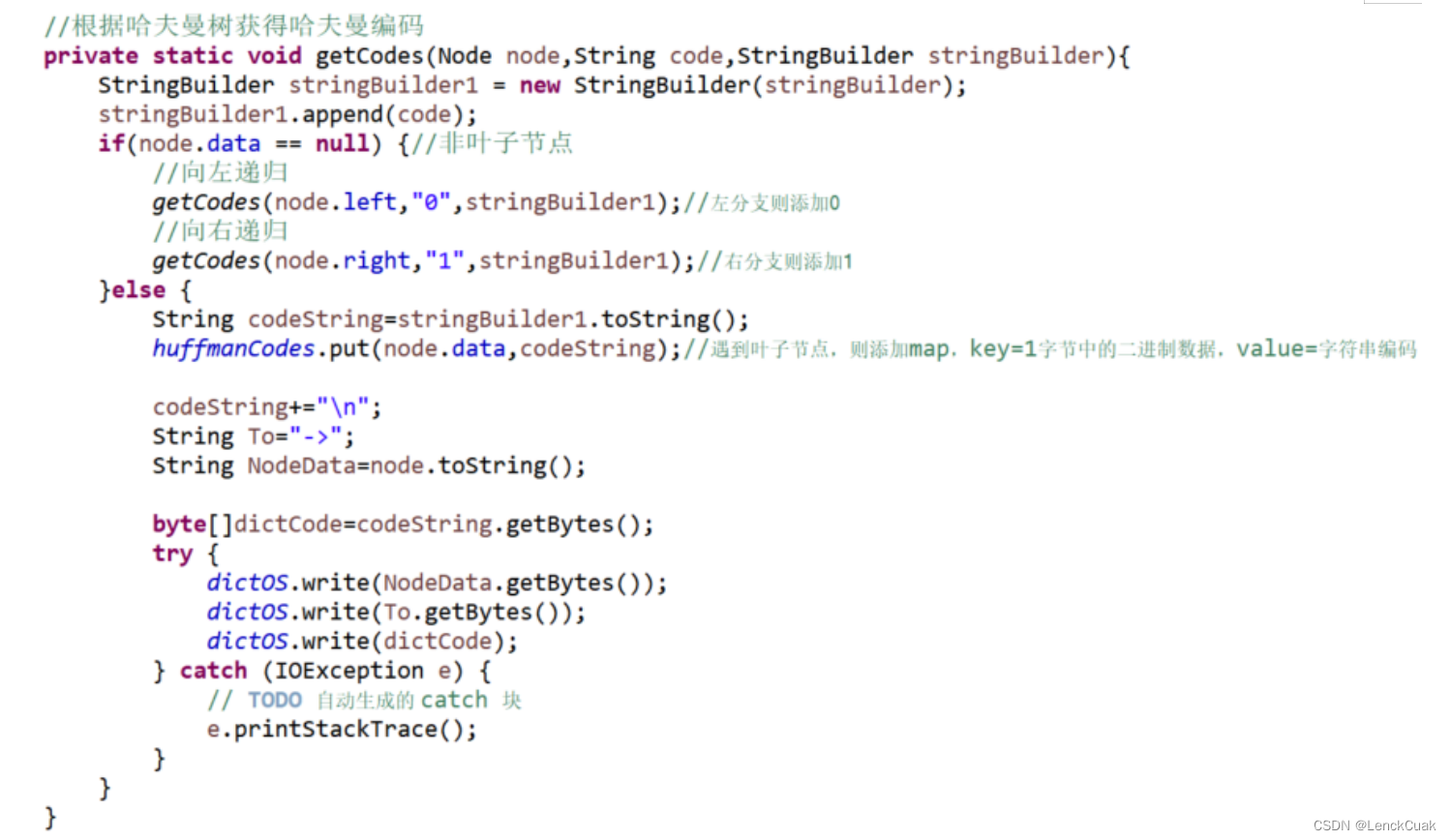
3. 减小了获取哈夫曼编码的时间复杂度
在将源文件字节数组转换为哈夫曼编码二进制字符串时,本文采用StringBuilder进行拼接,拼接速度比使用String类更加迅速。时间复杂度上,String类的时间复杂度为O(xn^2),x为需要拼接的字符串长度,n为拼接操作;而StringBuilder::append(String w)的时间复杂度是O(n),更加迅速。
4. 更方便地解压文件
在压缩时,本文使用对象流将不同的对象(字节数组和map<Byte,String>)输入到压缩文件中,从而在解压文件时,无需额外的字典文件进行解压,只需在压缩文件中直接提取((Map<Byte,String>)ObjectInputStream::readObject())即可。

(二)、课程设计项目最有价值的内容
本文以java为系统开发的基础语言,以哈夫曼编码构成哈夫曼树,以及哈夫曼树逆向解码过程为本次文件压缩解压程序设计的思想,设计并完成了基于哈夫曼编码对各类文件(纯文本文件,word文档,mp3音频文件,MP4视频文件,png图像文件)压缩解压的功能。并选用代表文件对其核心的文件压缩解压功能进行了测试,各类文件通过本次所设计系统压缩功能的压缩后,所得到的目标文件与原文件大小基本一致,且感官效果一致。通过对原文件和压缩解压文件进行比较,确定本次所设计的文件压缩解压功能,具有无损压缩和解压的特性,在压缩和解压的过程中,并不会存在数据的损坏与丢失。因此通过哈夫曼编码与哈夫曼原理所设计出的文件压缩解压系统,也是对需要压缩的文件的数据进行采集,并将采集后的数据通过哈夫曼编码进行一一转化,使编码符号与数字字符产生一一对应的关系而不会因丢失文件的数据,导致文件的变形或受损。
同时对于程序算法效率的提升也有显著价值,在将节点list转换为哈夫曼树的函数中,采用了PriorityQueue进行优化,将生成哈夫曼树的时间复杂度由O(n^2log(n))减小到O(nlog(n))
(三)、哪方面进一步了解或得到帮助
对于无损压缩方式的改进
直接将原文件数据先进行改进压缩改进,可以将数据替换成数据+重复次数,例如,文件的内容是AAAAABBBBCCCCCCCC,就可以替换成5A4B8C,将17个字符压缩为6个字符,大大减少了存储空间,但是这种情况比较使用于重复性大且连续重复的情况。
多线程优化
如果处理的文件较大,则单线程的设计模式效率就会很低。压缩一个文件看可能需要几分钟甚至更久,由于长时间的压缩时间不能满足实际开发需要,所以可以引入多线程的设计模式。例如使用javaSE11的多线程开发加快压缩和解压速率。

例如伪代码使用thread类来进行并发操作,同时使用两个线程让数据转换成节点和创建哈夫曼树同时进行,这样可以大大加快压缩速率。
(四)、编程实现课程设计的感悟
通过实现原理为哈夫曼编码的压缩解压程序,对国内外现有的压缩解压软件原理有了了解(大多数基于LZW码的改进算法的基础上开发的),同时对于哈夫曼编码有更加深刻的认识,哈夫曼编码作为一种变长编码技术,由于它能充分利用短码,所以同样可以根据它来开发压缩和解压软件,并且通过哈夫曼编码实现的压缩与解压软件更加简单易用,安全保密性能更好。
七、源码
package huffman;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.PriorityQueue;
public class Node implements Comparable<Node>{
public Byte data;
//使用字节表示的原因:字节可以表示所有文件,计算机所能表示的最小单位。1字节可以存储8bit,1字节表示最大的二进制数为11111111=十进制数255,
//一切文件数据(文本、图片、视频等)在存储时,都是以二进制数字的形式保存,都一个一个的字节,那么传输时一样如此。所以,字节流可以传输任意文件数据
public int weight;
public Node left;
public Node right;
public static String dictFile;
public static String frequentFile;
static FileOutputStream dictOS = null;
static byte[] b;//读取文件的原字节数组
public Node(Byte data,int weight){
this.data = data;
this.weight = weight;
}
public void preOrder(){
System.out.println(this);
if (this.left != null)
this.left.preOrder();
if(this.right != null)
this.right.preOrder();
}
@Override
public String toString() {
return "Node{" +
"data=" + data +
", weight=" + weight +
'}';
}
@Override
public int compareTo(Node o) {
return this.weight - o.weight;
}
//原理:将文件中的所有字节进行计数,1个字节中表示的不同二进制数值通过映射关系放入map中,即1字节中相同的二进制数值越多,编码越短
//函数功能:将字节数组转换成一个节点,存放在List集合中,每个节点由该数据和出现频率(即权值)组成。
private static ArrayList<Node> getList(byte[]bytes){
ArrayList<Node> nodes = new ArrayList<>();
Map<Byte,Integer> map = new HashMap<>();//map映射每个字节(键/key)出现的次数(值/value)
for(byte b : bytes){
Integer count = map.get(b);
if(count == null){
map.put(b,1);
}else
map.put(b,map.get(b) + 1);
}
//遍历map
for(Map.Entry<Byte,Integer> entry : map.entrySet()){//entry.getKey()得到map的键,entry.getValue()得到map的值
nodes.add(new Node(entry.getKey(),entry.getValue()));
}
return nodes;
}
//原理:通过对节点数据频率进行排序,出现越少的两个节点先组成一颗树,并移除原先的两个节点
//函数功能:将节点list转化为哈夫曼树,返回根节点
private static Node createHuffmanTree(List<Node> nodes){
PriorityQueue<Node>nodeQueue=new PriorityQueue<>(nodes);
while(nodeQueue.size() > 1){//直到只有一个根节点
// Collections.sort(nodes);
// Node leftNode = nodes.get(0);
// Node rightNode = nodes.get(1);
Node leftNode=nodeQueue.poll();
Node rightNode = nodeQueue.poll();
Node parent = new Node(null,leftNode.weight + rightNode.weight);//生成的父节点无数据,用以后面判断是否为叶子节点
parent.left = leftNode;
parent.right = rightNode;
nodeQueue.add(parent);
// nodes.remove(leftNode);
// nodes.remove(rightNode);
// nodes.add(parent);
}
// return nodes.get(0);
return nodeQueue.peek();
}
static Map<Byte,String> huffmanCodes = new HashMap<>();
static StringBuilder stringBuilder = new StringBuilder();//StringBuilder可以构造一个快速字符串生成对象
//函数功能:通过构造好的哈夫曼树生成哈夫曼编码map,key=字节中的二进制数 value=生成的字符串编码
private static Map<Byte,String> getCodes(Node root){
if (root == null)
return null;
getCodes(root,"",stringBuilder);
return huffmanCodes;
}
//根据哈夫曼树获得哈夫曼编码
private static void getCodes(Node node,String code,StringBuilder stringBuilder){
StringBuilder stringBuilder1 = new StringBuilder(stringBuilder);
stringBuilder1.append(code);
if(node.data == null) {//非叶子节点
//向左递归
getCodes(node.left,"0",stringBuilder1);//左分支则添加0
//向右递归
getCodes(node.right,"1",stringBuilder1);//右分支则添加1
}else {
String codeString=stringBuilder1.toString();
huffmanCodes.put(node.data,codeString);//遇到叶子节点,则添加map,key=1字节中的二进制数据,value=字符串编码
codeString+="\n";
String To="->";
String NodeData=node.toString();
byte[]dictCode=codeString.getBytes();
try {
dictOS.write(NodeData.getBytes());
dictOS.write(To.getBytes());
dictOS.write(dictCode);
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
//根据原字节数组和哈夫曼编码表对数据进行压缩
//函数功能:通过对原先的字节数组进行哈夫曼编码,然后将生成的哈夫曼编码(二进制)字符串转为字节数组
private static byte[] zip(byte[] bytes, Map<Byte, String> huffmanCodes) {
StringBuilder builder = new StringBuilder();
StringBuilder builder1 = new StringBuilder();
for(byte b : bytes){
builder.append(huffmanCodes.get(b));//将原字节数组用哈夫曼编码表示,存放再builder字符串中
}
//加7的原因是最大限度保证二进制数不丢失,且不浪费空间
//例如:1个二进制数(1),若length=builder.length()/8=1/8=0 则转换为0字节
//而length = (builder.length() + 7) / 8=8/8=1则转换为1个字节
//而当7个二进制时(1111000),length = (builder.length() + 7) / 8=14/8=1,转换为1个字节,不会转换为2个字节,这样就不会浪费空间
int length = (builder.length() + 7) / 8 ;//因为哈夫曼编码是二进制数,将二进制转化为字节
System.out.println("压缩率:"+(length*1.0/bytes.length)*100+"%");
byte[] by = new byte[length];
int index = 0;
String str;
for (int i = 0; i < builder.length(); i+= 8) {//将用哈夫曼编码(二进制)表示的字符串转为字节数组
if((i + 8) > builder.length()){
str = builder.substring(i);//从i开始往后截取
by[index] = (byte)Integer.parseInt(str,2);//将str中的字符串("10101...")转为2进制数,然后转换为1字节(8个二进制转为1个字节,多余的不要),并放入字节数组by中
index++;
}else {
str = builder.substring(i, i + 8);
by[index] = (byte)Integer.parseInt(str,2);
index++;
}
}
return by;
}
//函数功能:通过原字节数组得到哈夫曼二进制编码转换后的字节数组
private static byte[] huffmanZip(byte[] bytes){
//获取通过字节数组转化为节点数组的ArrayList<Node>集合,其中每个节点由二进制数据和权重组成
ArrayList<Node> nodes = getList(bytes);
//通过节点数组获取哈夫曼树
Node root = createHuffmanTree(nodes);
//通过哈夫曼树获取哈夫曼编码表
Map<Byte,String>huffmanCodes = getCodes(root);
//对原字节数组进行哈夫曼编码,生成的哈夫曼编码组成的二进制字符串,得到二进制字符串转换得到的字节数组
byte[]huffmanCodesBytes = zip(bytes,huffmanCodes);
return huffmanCodesBytes;
}
/**
* 将字节类型的十进制转换为二进制的字符串类型
* @param flag 是否是最后一位,最后一位不需要补高位
* @param b 带转换的字节
* @return
*/
private static String byteToBitString(boolean flag,byte b){
int temp = b;
if(flag){
temp |= 256;//正数需要补高位;
}
String str = Integer.toBinaryString(temp);
if(flag){
return str.substring(str.length() - 8);
}else
return str;
}
/**
* 解压
* @param huffmanCodesBytes 哈夫曼编码后的字节数组
* @param huffmanCodes 哈夫曼编码表 key=二进制数据,value=哈夫曼编码
* @return 哈夫曼编码前的字节数组
*/
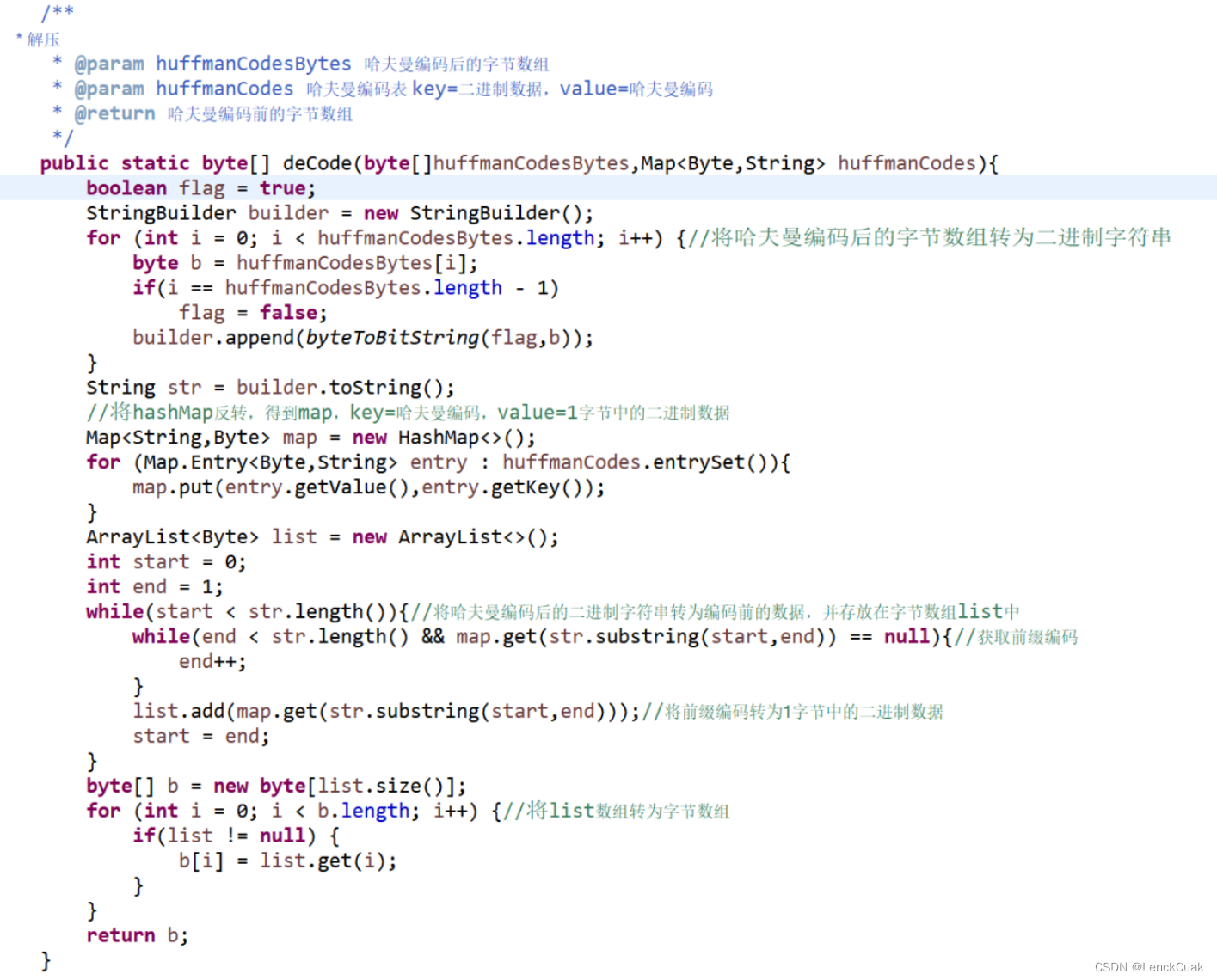
public static byte[] deCode(byte[]huffmanCodesBytes,Map<Byte,String> huffmanCodes){
boolean flag = true;
StringBuilder builder = new StringBuilder();
for (int i = 0; i < huffmanCodesBytes.length; i++) {//将哈夫曼编码后的字节数组转为二进制字符串
byte b = huffmanCodesBytes[i];
if(i == huffmanCodesBytes.length - 1)
flag = false;
builder.append(byteToBitString(flag,b));
}
String str = builder.toString();
//将hashMap反转,得到map,key=哈夫曼编码,value=1字节中的二进制数据
Map<String,Byte> map = new HashMap<>();
for (Map.Entry<Byte,String> entry : huffmanCodes.entrySet()){
map.put(entry.getValue(),entry.getKey());
}
ArrayList<Byte> list = new ArrayList<>();
int start = 0;
int end = 1;
while(start < str.length()){//将哈夫曼编码后的二进制字符串转为编码前的数据,并存放在字节数组list中
while(end < str.length() && map.get(str.substring(start,end)) == null){//获取前缀编码
end++;
}
list.add(map.get(str.substring(start,end)));//将前缀编码转为1字节中的二进制数据
start = end;
}
byte[] b = new byte[list.size()];
for (int i = 0; i < b.length; i++) {//将list数组转为字节数组
if(list != null) {
b[i] = list.get(i);
}
}
return b;
}
/**
* 压缩文件
* @param srcFile 需要压缩的文件路径
* @param dstFile 压缩后的文件路径
* @return
*/
public static void zipFile(String srcFile,String dstFile){
//创建输入流
FileInputStream is = null;
//创建输出流和对象输出流
FileOutputStream os = null;
ObjectOutputStream oos = null;
try {
is = new FileInputStream(srcFile);
b = new byte[is.available()];//is.available()返回文件剩余的字节数,这里刚开始读取,所以返回的是文件所有的字节数
is.read(b);//读取b.length个字节的数据,并存储到字节数组b中
os = new FileOutputStream(dstFile);
oos = new ObjectOutputStream(os);
byte[] huffmanBytes = huffmanZip(b);//通过原字节数组b得到哈夫曼二进制编码转换后的字节数组
oos.writeObject(huffmanBytes);//向目标文件路径写入哈夫曼二进制编码转换后的字节数组
oos.writeObject(huffmanCodes);//写入huffmanCodes 哈夫曼编码表 key=二进制数据,value=哈夫曼编码,写入这个的原因是后面解压时可以直接提取字典,便于解压
} catch (Exception e) {
e.printStackTrace();
}finally {
try {
oos.close();
os.close();
is.close();
dictOS.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 解压文件
* @param zipFile 需要解压的文件路径
* @param dstFile 解压后的文件路径
* @return
*/
public static void unZipFile(String zipFile,String dstFile){
//创建输入流和对象输入流
FileInputStream is = null;
ObjectInputStream ois = null;
//创建输出流
FileOutputStream os = null;
try {
is = new FileInputStream(zipFile);
ois = new ObjectInputStream(is);
byte[] huffmanBytes = (byte[])ois.readObject();//将哈夫曼编码后的文件转为字节数组
Map<Byte,String> huffmanCodes = (Map<Byte,String>)ois.readObject();//将哈夫曼编码后的文件转为哈夫曼字典,key=1字节的二进制数据,value=哈夫曼二进制编码字符串
//ObjectInputStream::readObject()根据类的对象,类的签名,类的非静态字段的值等读取对象,意味着可以读取到不同的对象,并且不会乱
byte[] bytes = deCode(huffmanBytes,huffmanCodes);//解压,得到哈夫曼编码前的字节数组
os = new FileOutputStream(dstFile);
os.write(bytes);//写入哈夫曼编码前的字节数组,即未被压缩的文件
} catch (Exception e) {
e.printStackTrace();
}finally {
try {
os.close();
ois.close();
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
// String constant = "i like like like java do you like a java";
// System.out.println(constant);
// byte[] constantBytes = constant.getBytes();
// byte[] huffmanCodesBytes = huffmanZip(constantBytes);
// Map<Byte, String> huffmanCodes = getCodes(createHuffmanTree(getList(constantBytes)));
// byte[] sourceBytes = deCode(huffmanCodesBytes, huffmanCodes);
// System.out.println(new String(sourceBytes));
//
//测试压缩文件
String srcFile = "d://Test//11.txt";//要压缩的文件路径
String dstFile = "d://Test//1.huff";//压缩后的文件路径
dictFile="d://Test//dictAndFrequent.txt";//字典和频率文件,压缩的字节与对应的哈夫曼编码
try {
dictOS = new FileOutputStream(dictFile);
} catch (FileNotFoundException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
zipFile(srcFile,dstFile);
System.out.println("压缩成功!");
//测试解压文件
String zipFile = "d://Test//1.huff";//要解压的文件路径
String dst1File = "d://Test//2.txt";//解压后的文件路径
unZipFile(zipFile,dst1File);
System.out.println("解压成功!");
}
}八、参考资料
赫夫曼编码实现二进制文件压缩解压_程序dunk的博客-CSDN博客_二进制数据压缩
在参考资料的基础上做了详细解释与优化,减小了参考资料的时间复杂度,优化了界面操作。