前言
FlashOcc是一个它只需2D卷积就能实现“占用预测模型”,具有快速、节约内存、易部署的特点。
它首先采用2D卷积提取图形信息,生成BEV特征。然后通过通道到高度变换,将BEV特征提升到3D空间特征。
对于常规的占用预测模型,将3D卷积改为2D卷积,将三维体素特征改为BEV特征。而且不用Transformer注意力算子。
论文地址:FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin
代码地址:https://github.com/Yzichen/FlashOCC

一、模型框架
体素特征表示,需要大量内存和计算资源,而且通常会使用一些复杂算子,比如:3D卷积、Deformable Attention、Transformer。
FlashOcc认为理想的框架,应该对不同的芯片进行部署友好,同时保持高精度。
采用了一种即插即用的范式,使用2D卷积层来提取特征,并通过一个通道到高度的转换来,提升BEV层的输出到3D空间。
- FlashOcc首先采用2D卷积提取图形信息,生成BEV特征。然后通过通道到高度变换,将BEV特征提升到3D空间特征。
- 对于常规的占用预测模型,将3D卷积改为2D卷积,将三维体素特征改为BEV特征。而且不用Transformer注意力算子。
- 特点:快速、节约内存、易部署。
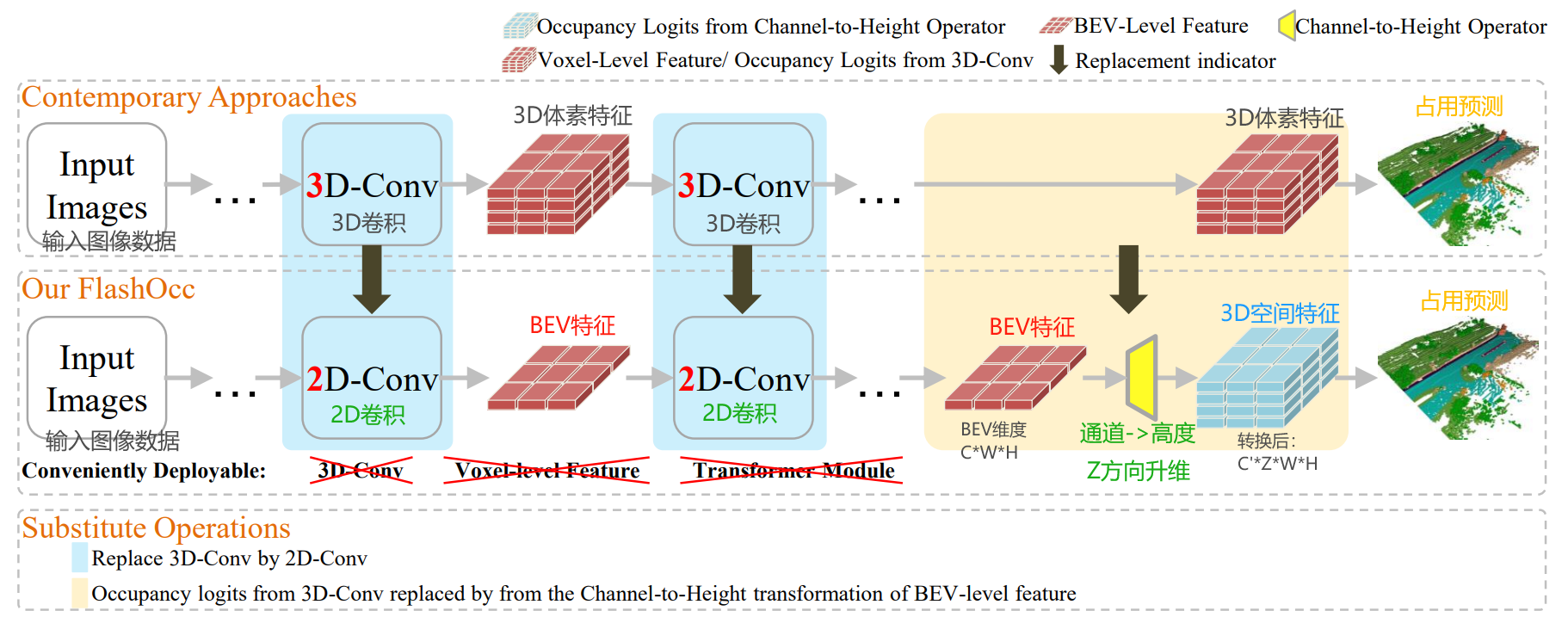
FlashOcc的模型框架如下图所示,核心步骤分为7步:
- 输入多视角图像数据,比如6个相机组成的,同时输入6张图像。
- 经过主干网络,提取图像信息,生成图像特征。
- 通过LSS(Lift-splat-shot)思路,将2D图像特征转为BEV特征,形成初步的BEV特征。
- 得到初步的BEV特征,可以选择是否使用“时序信息融合模块”。如果使用的,会融合历史的BEV特征信息。如果不用,进入直接下一步。
- 对BEV特征进一步编码,提取特征,形成BEV特征'。
- BEV特征'经过占用头的处理,得到BEV特征'';接着,通过通道到高度变换,将BEV特征''提升到3D空间特征。
- 输出占用预测信息。
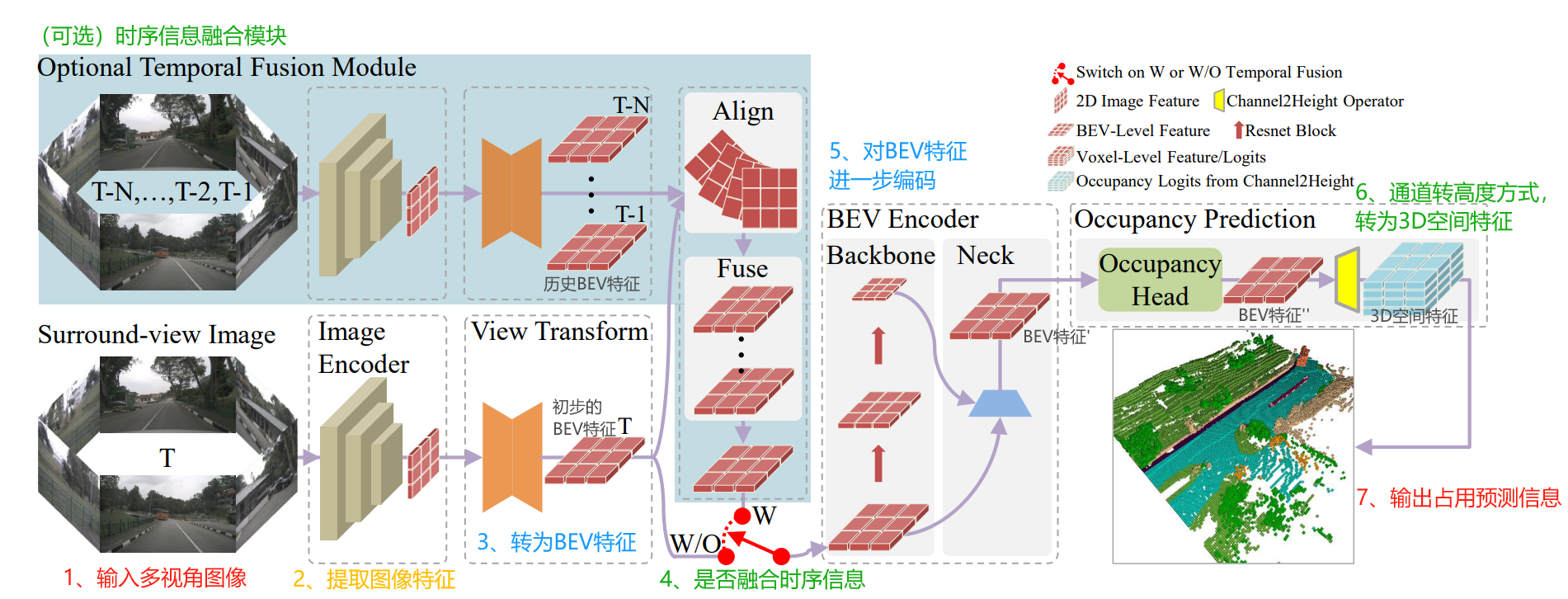
其中,通道到高度变换,是指将BEV特征(BxCxWxH),转为3D空间特征(BxC'xZxWxH)。
这里的B是指batch size,C是指BEV的特征通道数量,C'是指3D空间特征通道(类别数量);C = C' x Z,对应通道到高度变换思想。
W,H,Z分别对应三维空间中x,y,z的维度。
它由5个关键模型组成:
- 2D图像编码器:这个模块的任务是从由多个摄像头捕获的图像中提取特征。这些特征可能包括物体的形状、大小、颜色等,对于理解图像内容至关重要。
- 视图转换模块:该模块负责将2D感知图像特征,转换到鸟瞰视图(BEV)空间表示。
- BEV编码器:在完成视图转换后,BEV编码器处理鸟瞰视图中的特征信息。这一步进一步加工特征,使其适应于三维空间分析。
- 占用预测模块:这个模块的核心任务是预测每个体素(三维空间中的一个小立方体,类似于二维图像中的像素)是否被占用。这是通过分析前面模块提供的数据来完成的。
- 时间融合模块(可选):这个模块不是必须的,但可以用来提高模型的性能。它通过融合历史信息(如之前的观察或预测)来提供更准确的占用预测。
二、细节信息
1、占用模型改进对比
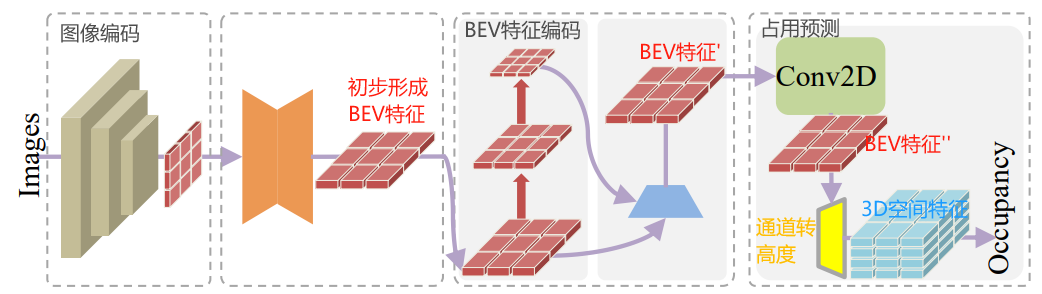
细节展开,下图是常规的占用预测模型,使用3D体素特征表示,并用到3D卷积和Transformer等算子。

下图是FlashOcc模型,使用BEV特征表示,只用到2D卷积算子。
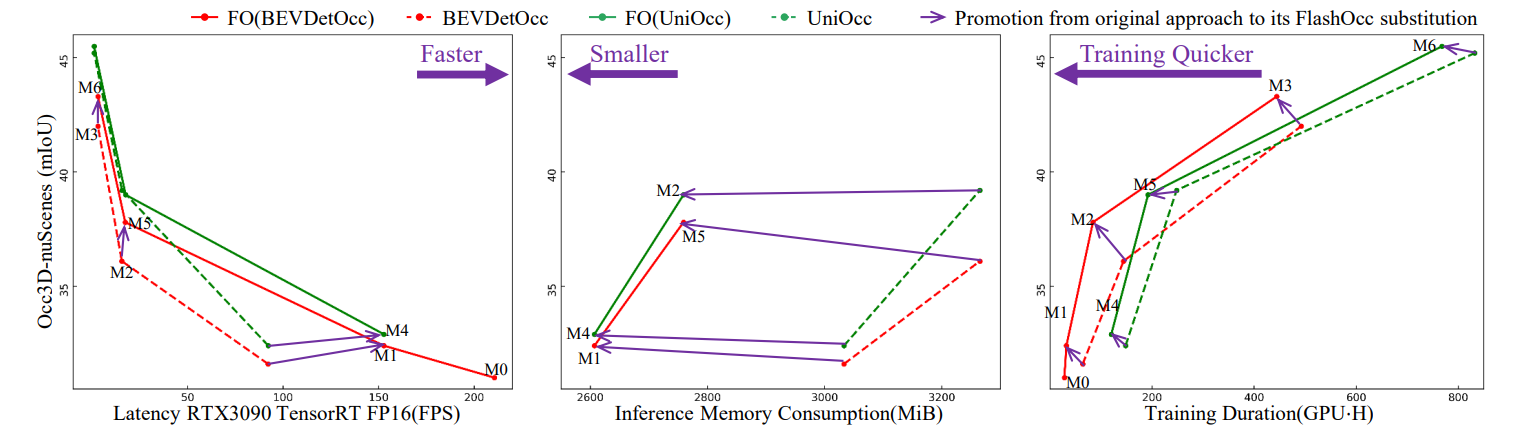
通过BEVDetOcc和UniOcc中组建替换为FlashOcc后,进行实验对比。
替换为FlashOcc后在速度、内存消耗和训练时间方面,都是更优的。
2、Efficient Sub-pixel Paradigm
子像素卷积技术: 这种技术首先在图像超分辨率中被提出,然后通道重排代替上采样来提高低分辨率数据的分辨率,与去卷积层相比,成本更低
基于这种方法,提出了通道到高度转换作为一种高效的占用预测方法,直接从平坦的BEV级特征通过通道到高度变换重塑占用空间特征。
在传统的图像超分辨率方法中,一个低分辨率图像会被上采样(即插值)到一个更高的分辨率。然而,这种插值通常是一种线性过程,可能会导致细节的丢失或模糊。子像素卷积采用一种不同的方法来解决这个问题。
在子像素卷积中,网络被训练来学习如何重新排列在低分辨率特征图中的信息,以生成高分辨率的输出。这是通过以下步骤完成的:
-
卷积层: 首先,使用卷积层来提取低分辨率图像的特征。
-
特征映射扩展: 接着,使用多个卷积滤波器来增加特征映射的数量。例如,如果目标是将图像的分辨率提高2倍,那么就会使用4倍(2x2)的特征映射数量。
-
像素重排: 然后,通过一个特殊的重排操作(也称为“像素洗牌”),将这些额外的特征映射转换为高分辨率图像的形式。这个过程实际上是在一个更细粒度的层面上重新排列特征映射,以形成高分辨率输出。
这种方法的优势在于其避免了传统上采样方法可能引入的模糊,同时允许网络学习更加复杂的上采样模式。
在自动驾驶系统中,子像素卷积技术可以用于提高感知模型的分辨率,从而允许车辆更准确地理解其周围的环境,包括路面状况、周围车辆和行人等。
子像素卷积技术被提议用于通过通道到高度变换来实现高效的占用预测,这是一种在BEV级别上工作的技术。
这种方法允许直接从BEV特征中推断出3D结构的高度信息,避免了计算上昂贵的3D卷积操作,从而提高了计算效率并减少了内存消耗。
3、View Transforme
View Transformer 将摄像头收集的2D图像数据,转换为BEV鸟瞰视图表示。
论文中默认使用LSS方案,它全称是Lift-Splat-Shoot,它先从车辆周围的多个摄像头拍摄到的图像进行特征提取,在特征图中估计出每个点的深度,然后把这些点“提升”到3D空间中。
接着,这些3D信息被放置到一个网格上,最后将这些信息“拍扁”到一个平面视图上,形成BEV特征图。
- Lift,是提升的意思,2D到3D特征转换模块,将二维图像特征生成3D特征;即:对每个像素预测深度值,然后结合相机内外参,投影到3D空间中。
- Splat,是展开的意思,3D到BEV特征编码模块,把3D特征“拍扁”得到BEV特征图;由于一个BEV网格可能对应多个3D点,需要进行融合得到该网格的特征。
- Shooting,是指在BEV特征图上进行相关任务操作,比如检测、分割、轨迹预测等。
详细信息,看我这篇博客:【BEV感知 LSS方案】Lift-Splat-Shoot 论文精读与代码实现-CSDN博客
4、训练参数
数据情况
- 基准测试:实验使用了Occ3D-nuScenes数据集进行3D占用预测。这个数据集包含了700个训练场景和150个验证场景。
- 数据集:数据集覆盖了-40m到40m沿X和Y轴的空间范围,以及-1m到5.4m沿Z轴的空间范围。占用标签是使用尺寸为0.4m x 0.4m x 0.4m的体素为17个类别定义的。
- 数据收集:场景包含了20秒的注释感知数据,以2Hz的频率采集。数据收集车辆装备了一个激光雷达、五个雷达和六个摄像头,使得能够全面地观察车辆的周围环境。
- 评估指标:评估指标为平均交并比(mIoU)。
训练细节
- 设计:FlashOcc的设计为即插即用方式,并注重于泛化性和效率。
- 比较:实验中将FlashOcc与其他主流基于体素的占用预测方法进行了比较,如BEVDetOcc和UniOcc。
- 训练细节:所有模型都使用AdamW优化器进行训练,并应用了梯度裁剪,学习率为1e-4,总批量大小为64,分布在8个GPU上。
- 训练周期:BEVDetOcc和UniOcc的总训练周期设置为24,而FBOcc只训练了20个周期。
- 样本平衡:在所有实验中,没有使用类平衡的分组和采样。
下面表格展示了训练细节信息:
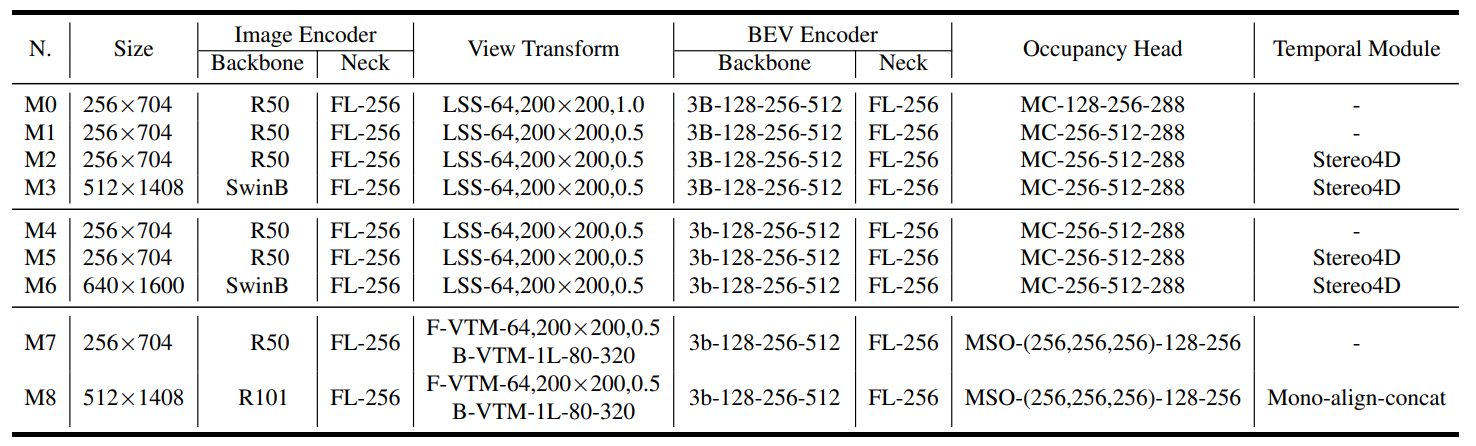
- “R50*”表示使用了ResNet-50主干网络,“R101”是指ResNet-101,“SwinB”是指Swin Transformer。
- “FL”是FPN LSS的缩写。
- “MC”代表多卷积头。
- MSO指的是指多尺度占用预测头。
- F-VTM和B-VTM分别表示前向投影和深度感知的后向投影。
- Stereo4D指的是使用立体声体积来增强LSS的深度预测,而不包括来自上一帧的BEV特征。
- Mono-align-concat表示使用单目深度预测用于LSS,其中历史帧的bev特征被对齐并沿通道连接。
三、设计背景
这不是不是重点,放在后面。占用预测,能解决3D感知中的三个问题:复杂形状缺失、长尾缺陷、无限类别。
- 复杂形状缺失: 有些物体的形状很复杂,无法描述细节和几何形状。比如,一辆挖掘机,由机械臂和车身组成,用3D目标检测只能框出这是一个矩形体,无法知道那部分是机械臂。
- 长尾缺陷问题: 在现实世界中,某些物体出现得很少,而另一些则很常见。比如,在路上,普通汽车和卡车很多,但冰淇淋车或救护车就比较少,识别那些不常见的物体就比较难。
- 无限类别问题:在真实世界中,存在数以万计的不同物体,常规训练任务中,只能识别的有限数量的类别。实际场景中会遇到预定义类之外的目标。

占用预测: 判断周围空间中哪些部分被物体占据,哪些是空的。
为了进行占用预测,一种常见的方法是使用三维体素来表示物体和环境。这种方法可以提供非常详细的三维信息,但问题在于它需要大量的内存和计算资源。
因为体素是以三维网格的形式存在的,所以当细节级别增加时,所需处理的数据量会呈指数级增长。
同时当前大多占用预测模型使用Transformer注意力等复杂算子,阻碍了占用预测部署。
四、实验测试与效果
在Occ3D-nuScenes评估数据集上,进行的3D占用预测性能测试。使用ResNet-101和Swin Transformer-Base两种不同的基础网络进行了评估。
- FlashOcc在BEVDetOcc和UniOcc框架上进行了评估,并与MonoScene、TPVFormer、OccFormer、CTF-Occ、RenderOcc和PanoOcc等流行方法进行了性能比较。
- 表格中最后两行,将BEVDetOcc和UniOcc中组建替换为FlashOcc后,FlashOcc在BEVDetOcc上提高了1.3 mIoU,在UniOcc上提高了0.3 mIoU。
- FlashOcc的实现超过了基于Transformer的PanoOcc方法1.1 mIoU,证明了该方法的性能。

- 星号(*)表示这些模型在训练前已经在FCOS3D模型上进行了预训练。
- “FO”是FlashOcc的缩写,而“FO()”表示对应名为“”的模型进行插件替换。
在训练和部署期间,资源消耗分析。FPS是在单个RTX3090上通过tensorrt以fp16精度测试的。
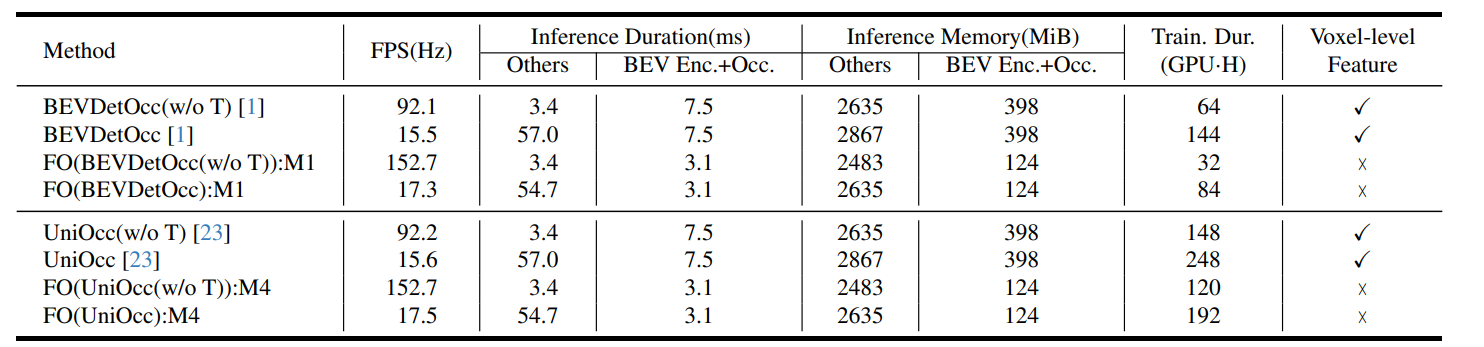
- “Train. Dur.”是训练持续时间的缩写。
- “Enc.”、“Occ.”和“Feat”分别代表编码器、占用预测和特征。
- “GPU·H”表示“1个GPU × 1小时”。
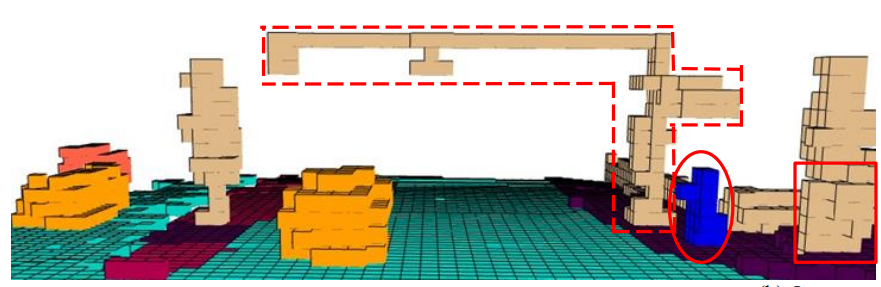
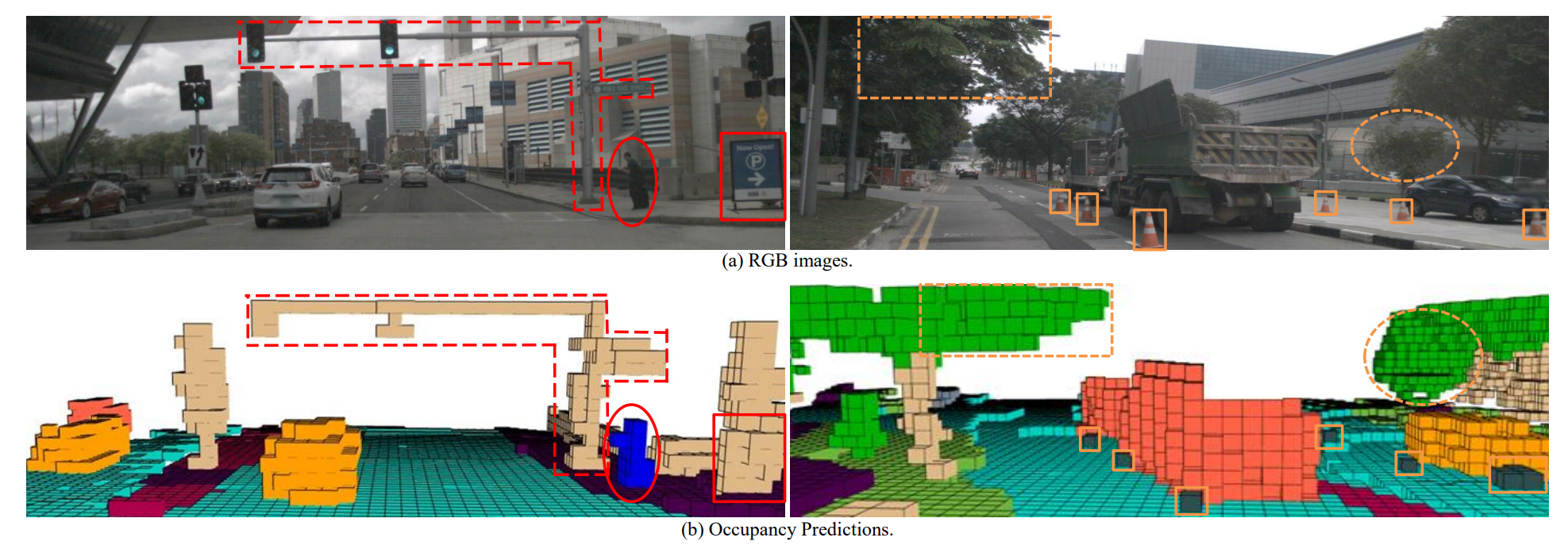
模型预测效果,如下图所示,展示了其精确捕捉复杂形状的能力。
特别是在对行人的体素描述上,比如突出在胸部的体素可以表示行人手持的移动设备,或行李箱部分。
分享完成~