毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
技术栈:
Python语言+Django框架+数据库+jieba分词+ scikit_learn机器学习(K-means聚类算法)+情感分析 snownlp
2、项目界面
(1)微博舆情分析
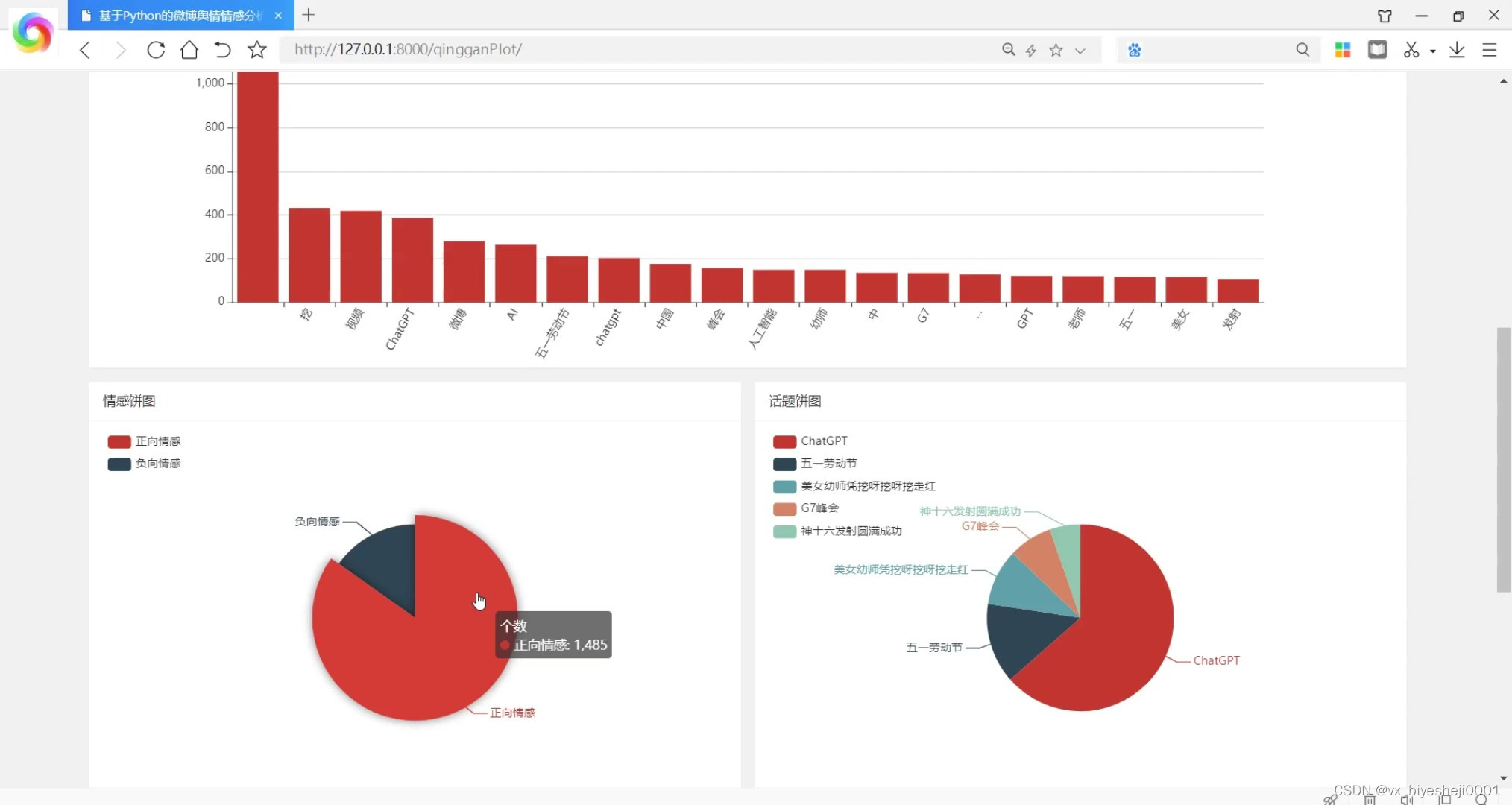
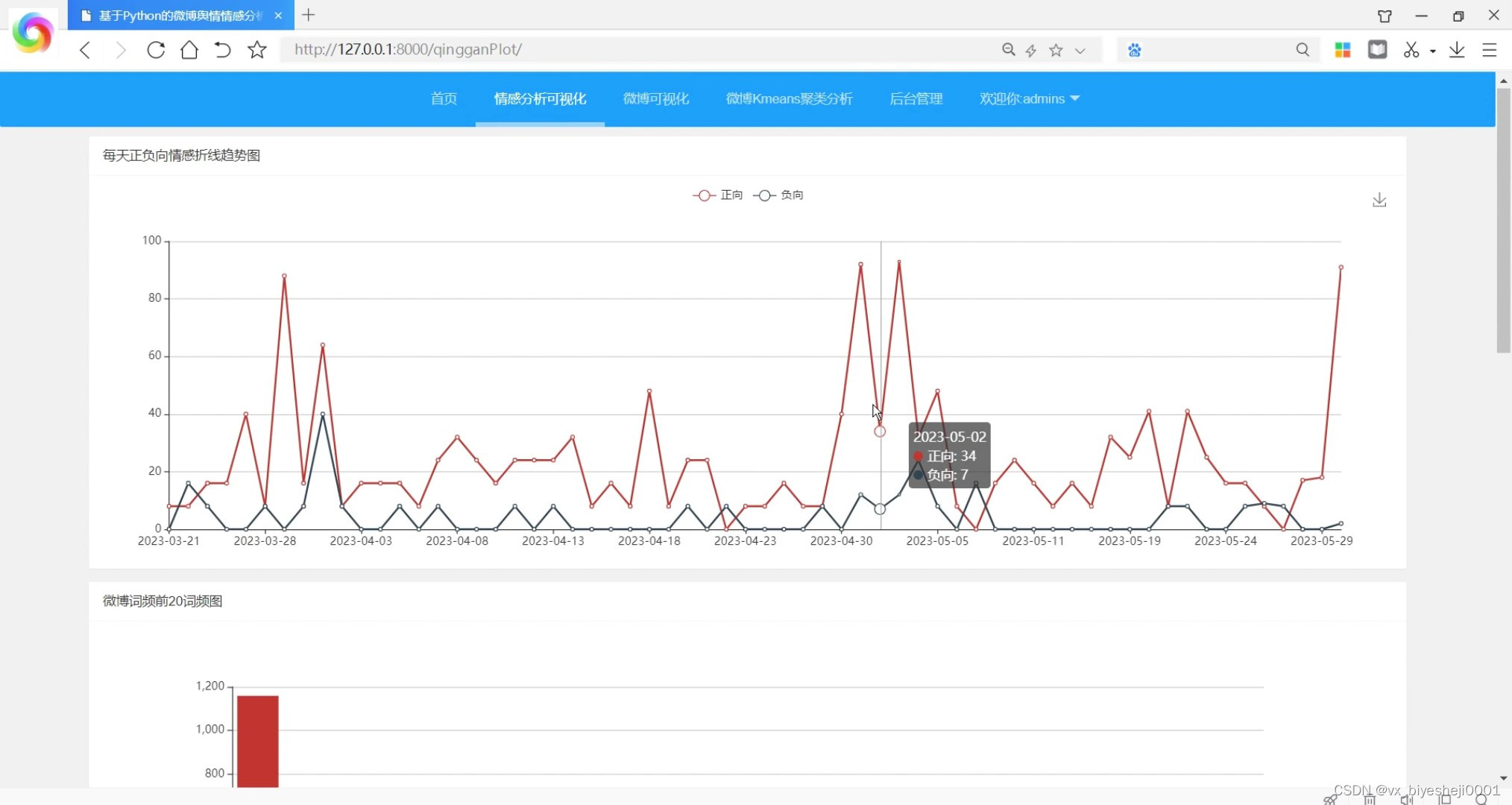
(2)情感分析可视化
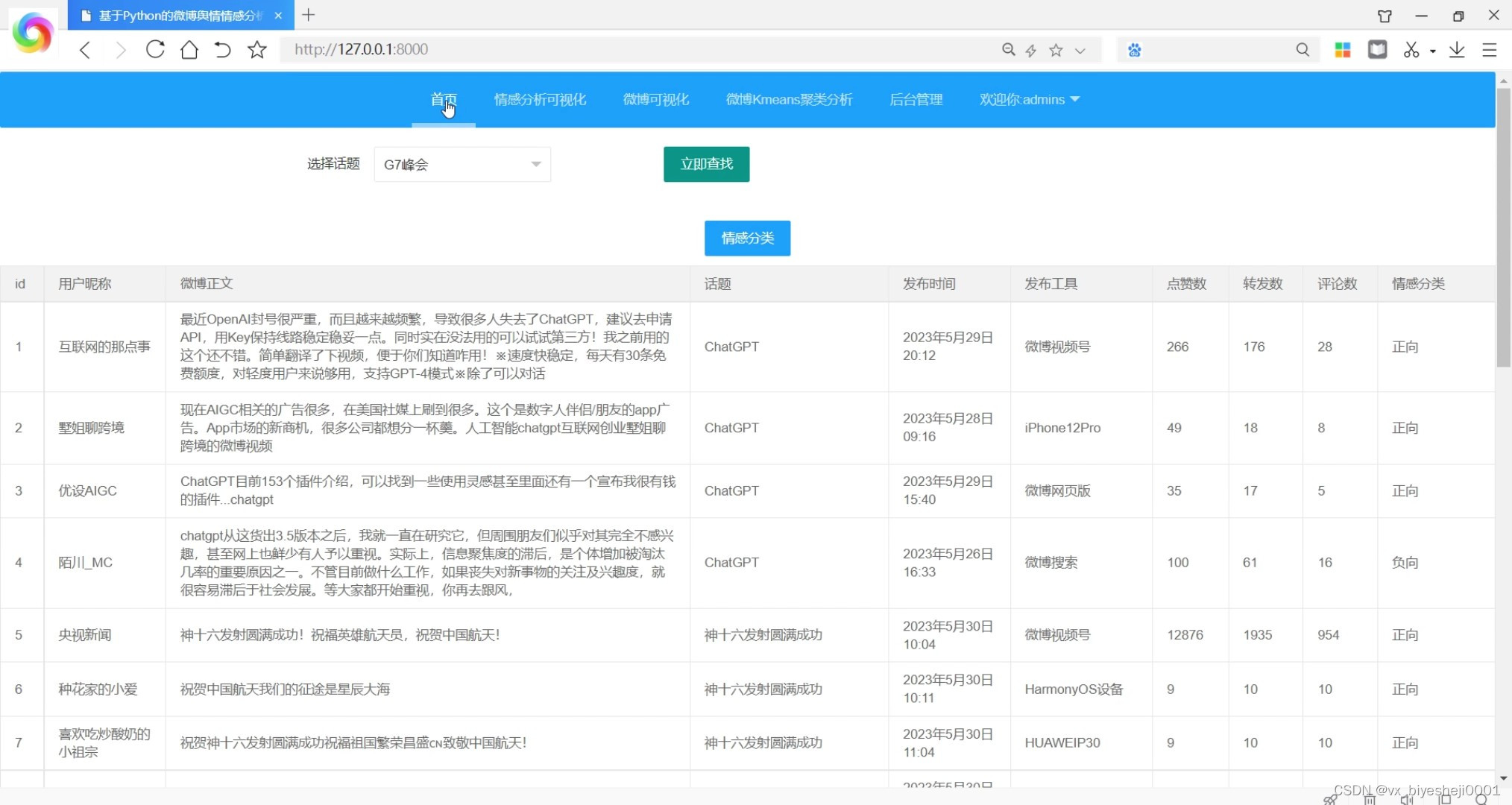
(3)微博数据浏览
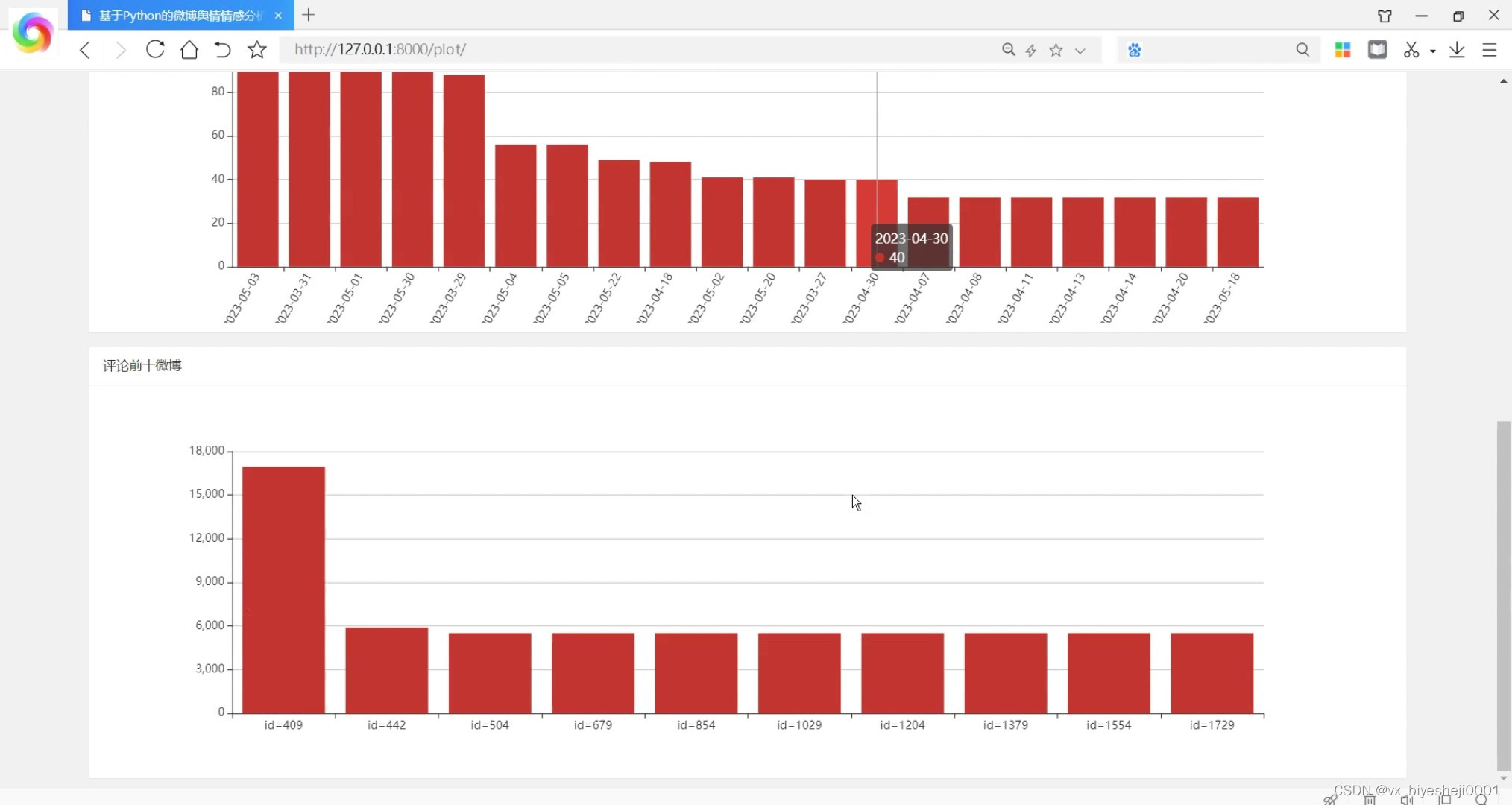
(4)评论前十
(5)K-Means聚类分析
(6)注册登录界面
3、项目说明
1、所用技术
Python语言+Django框架+数据库+jieba分词+
scikit_learn机器学习(K-means聚类算法)+情感分析 snownlp
微博舆情分析系统是基于Python语言和Django框架开发的,使用了数据库存储数据,并利用jieba分词进行中文文本的分词处理。系统还集成了scikit_learn机器学习库中的K-means聚类算法,以及snownlp库进行情感分析。
该系统的主要功能是对微博中的舆情进行分析和评估。用户可以通过系统上传微博数据,并进行分词处理和情感分析。系统会自动将微博数据进行分词,并根据分词结果进行情感分析,判断微博的情感倾向(积极、消极或中性)。同时,系统还会利用K-means聚类算法对微博进行聚类,将相似主题的微博归为一类。
在系统的界面上,用户可以查看微博的分词结果、情感分析结果以及聚类结果。用户还可以通过系统提供的搜索功能查找特定的微博,以及按照情感倾向或聚类类别进行筛选和排序。
微博舆情分析系统的应用范围广泛,可以帮助企业、政府等机构了解公众对特定事件、产品或政策的态度,从而进行舆情监测和管理。同时,该系统也可以用于学术研究领域,帮助研究人员对社会舆情进行分析和研究。
4、核心代码
###首页
@check_login
def index(request):
# 话题列表
topic_raw = [item.topic for item in WeiBo.objects.all() if item.topic]
topic_list = []
for item in topic_raw:
topic_list.extend(item.split(','))
topic_list = list(set(topic_list))
# yon用户信息
uid = int(request.COOKIES.get('uid', -1))
if uid != -1:
username = User.objects.filter(id=uid)[0].name
# 得到话题
if 'key' not in request.GET:
key = topic_list[0]
raw_data = WeiBo.objects.all()
else:
key= request.GET.get('key')
raw_data = WeiBo.objects.filter(topic__contains=key)
# 分页
if 'page' not in request.GET:
page = 1
else:
page = int(request.GET.get('page'))
data_list = raw_data[(page-1)*20 : page*20 ]
return render(request, 'index.html', locals())
# 情感分类
def fenlei(request):
from snownlp import SnowNLP
# j = '我喜欢你'
# s = SnowNLP(j)
# print(s.sentiments)
for item in tqdm(WeiBo.objects.all()):
emotion = '正向' if SnowNLP(item.content).sentiments >0.45 else '负向'
WeiBo.objects.filter(id=item.id).update(emotion=emotion)
return JsonResponse({'status':1,'msg':'操作成功'} )
# 登录
def login(request):
if request.method == "POST":
tel, pwd = request.POST.get('tel'), request.POST.get('pwd')
if User.objects.filter(tel=tel, password=pwd):
obj = redirect('/')
obj.set_cookie('uid', User.objects.filter(tel=tel, password=pwd)[0].id, max_age=60 * 60 * 24)
return obj
else:
msg = "用户信息错误,请重新输入!!"
return render(request, 'login.html', locals())
else:
return render(request, 'login.html', locals())
# 注册
def register(request):
if request.method == "POST":
name, tel, pwd = request.POST.get('name'), request.POST.get('tel'), request.POST.get('pwd')
print(name, tel, pwd)
if User.objects.filter(tel=tel):
msg = "你已经有账号了,请登录"
else:
User.objects.create(name=name, tel=tel, password=pwd)
msg = "注册成功,请登录!"
return render(request, 'login.html', locals())
else:
msg = ""
return render(request, 'register.html', locals())
# 注销
def logout(request):
obj = redirect('index')
obj.delete_cookie('uid')
return obj
# 微博可视化
@check_login
def plot(request):
"""
折线图 每月发表数
柱状图 每日发表微博前20
饼图 正负向
柱状图 评论前十
"""
uid = int(request.COOKIES.get('uid', -1))
if uid != -1:
username = User.objects.filter(id=uid)[0].name
#1 折线图 每天发布微博折线图
raw_data = WeiBo.objects.all()
main1 = [item.time.strftime('%Y-%m-%d') for item in raw_data]
main1_x = sorted(list(set(main1)))
main1_y = [main1.count(item) for item in main1_x]
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻