用LangChain建立知识库,文末中也推荐其他方案。
项目源码:ChatPDF实现
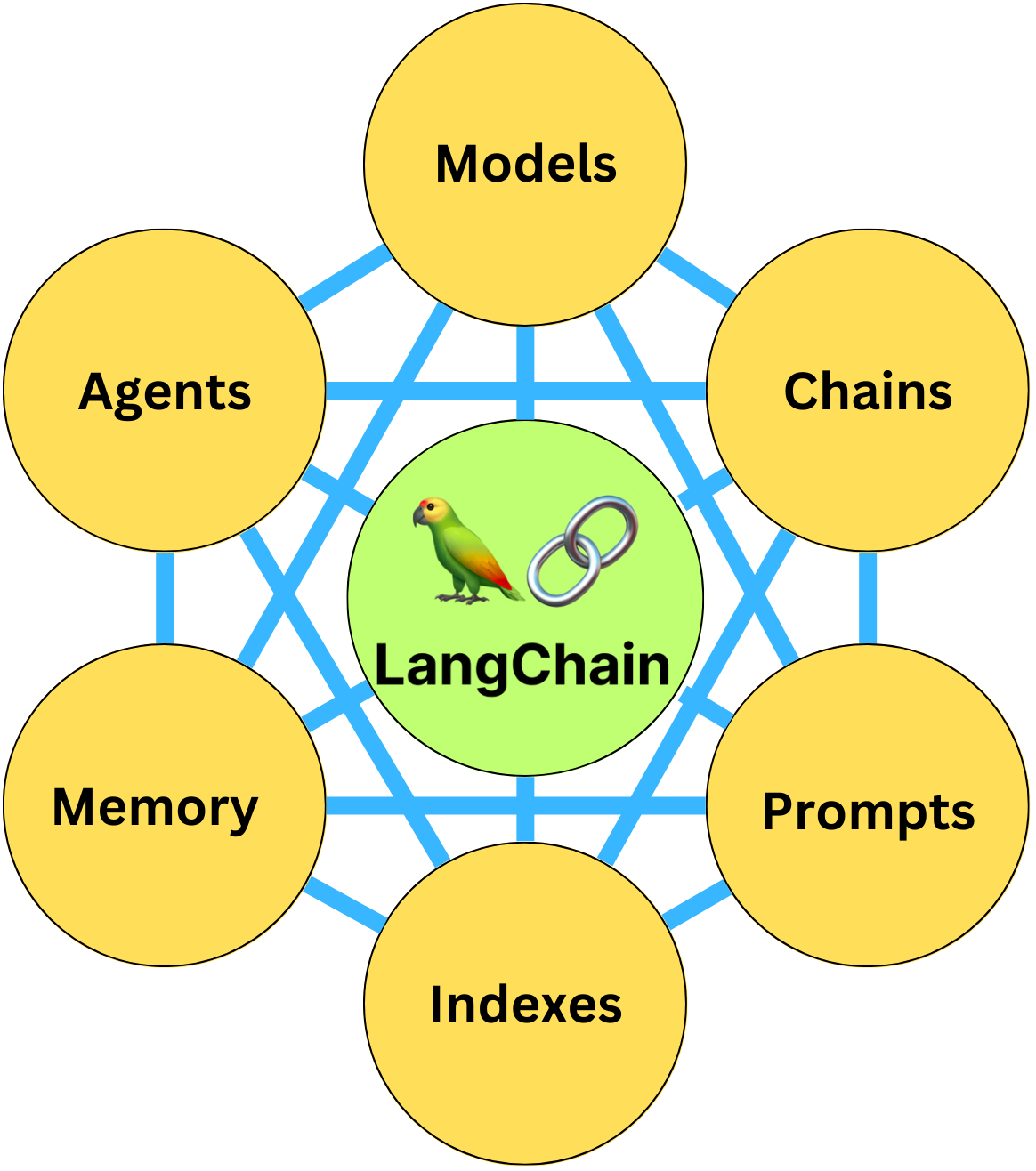
LangChain
Indexes使用
对加载的内容进行索引,在indexes中提供了一些功能:
- Document Loaders,加载文档
- Text Splitters,文档切分
- VectorStores,向量存储
- Retrievers,文档检索
LangChain作为问答可分为4个步骤:
- Step1,创建索引
- Step2,从该索引创建Retriever
- Step3,创建问答链
- Step4,提问!
ChatTxt实现
LangChain中定义的BaseRetriever,通过get_relevant_documents 函数,可以获取和query相关的文档列表。
在LangChain中使用了Chroma作为向量存储和检索引擎,所以你需要先安装工具箱。
from abc import ABC, abstractmethod
from typing import List
from langchain.schema import Document
class BaseRetriever(ABC):
@abstractmethod
def get_relevant_documents(self, query: str) ->
List[Document]:
"""Get texts relevant for a query.
Args:
query: string to find relevant texts for
Returns:
List of relevant documents
Chroma是一个用于构建带有embedding的 AI 应用的数据库。
import chromadb
# 获取Chroma Client对象
chroma_client = chromadb.Client()
# 创建Chroma数据集
collection =
chroma_client.create_collection(name="my_collection")
# 添加数据
collection.add(
documents=["This is an apple", "This is a banana"],
metadatas=[{"source": "my_source"}, {"source":
"my_source"}],
ids=["id1", "id2"]
)
# 查询数据
results = collection.query(
query_texts=["This is a query document"],
n_results=2
)
results
{‘ids’: [[‘id1’, ‘id2’]],
‘embeddings’: None,
‘documents’: [[‘This is an apple’, ‘This is a banana’]],
‘metadatas’: [[{‘source’: ‘my_source’}, {‘source’: ‘my_source’}]],
‘distances’: [[1.652575969696045, 1.6869373321533203]]}
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.document_loaders import TextLoader
from langchain.indexes import VectorstoreIndexCreator
# 文档加载
loader = TextLoader('./三国演义第1回.txt', encoding='utf8')
# 创建向量索引
index = VectorstoreIndexCreator().from_loaders([loader])
# 检索文档中的内容
query = "桃园三结义是哪三个人"
index.query(query)
更多参考项目源码:
Txt格式实现
LangChain的4种索引方式:
1.stuff
直接把文档作为prompt输入给OpenAI。
2.map_reduce
对于每个chunk做一个prompt(回答或者摘要),然后再做合并。
3.refine
在第一个chunk上做prompt得到结果,然后合并下一个文件再输出结果。
4.map_rerank
对每个chunk做prompt,然后打个分,然后根据分数返回最好的文档中的结果。
ChatPDF实现
方法1
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain
# 读取本地知识
loader = UnstructuredPDFLoader("三国演义第一回.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_documents(pages, embeddings).as_retriever()
query = "桃园三结义都有谁"
docs = docsearch.get_relevant_documents(query)
chain = load_qa_chain(OpenAI(temperature=0), chain_type="stuff")
output = chain.run(input_documents=docs, question=query)
print(output)
方法2
相对完整版的ChatPDF:
Step1,生成embedding,保存到本地
1.加载PDF,得到文本 content。
2.将content切分成多个docs,设置每个doc的max_length,比如 max_length=300。
3.设置embedding编码方法,比如OpenAIEmbeddings,并对docs进行embedding。
4.持久化到本地目录,比如 db文件夹
Step2,用户query
1.检索相关docs(可以设置 Topk= 4)
2.使用 load_qa_chain,设置input_documents参数
3.得到Answer
import os
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
# os.environ["OPENAI_API_KEY"] = "{your-api-key}"
global retriever
def load_embedding():
global retriever
# 使用OpenAI Embedding
embedding = OpenAIEmbeddings()
# 指定了persist_directory, 所以在本地会有db文件夹,保存持久化结果
vectordb = Chroma(persist_directory='db', embedding_function=embedding)
# 检索Top4
retriever = vectordb.as_retriever(search_kwargs={"k": 4})
# 基于query进行问答
def prompt(query):
prompt_template = """
请注意:请谨慎评估query与提示的Context信息的相关性,
只根据本段输入文字信息的内容进行回答,如果query与提供的材料无关,请回答"我不知道",
另外也不要回答无关答案:
Context: {context}
Question: {question}
Answer:"""
PROMPT = PromptTemplate(
input_variables=["context", "question"],
template=prompt_template
)
# 从向量数据库中,检索出Top5相似文档
docs = retriever.get_relevant_documents(query)
print('docs=', docs)
print('len(docs)=', len(docs))
# 基于docs来prompt,返回你想要的内容
chain = load_qa_chain(ChatOpenAI(temperature=0), chain_type="stuff", prompt=PROMPT)
result = chain({"input_documents": docs, "question": query}, return_only_outputs=True)
return result['output_text']
#%%
# 加载embedding
load_embedding()
print('hhhhh')
query = "桃园三结义都有谁"
#query = "曹操都有哪些部将"
print("Query:" + query + '\nAnswer:' + prompt(query) + '\n')
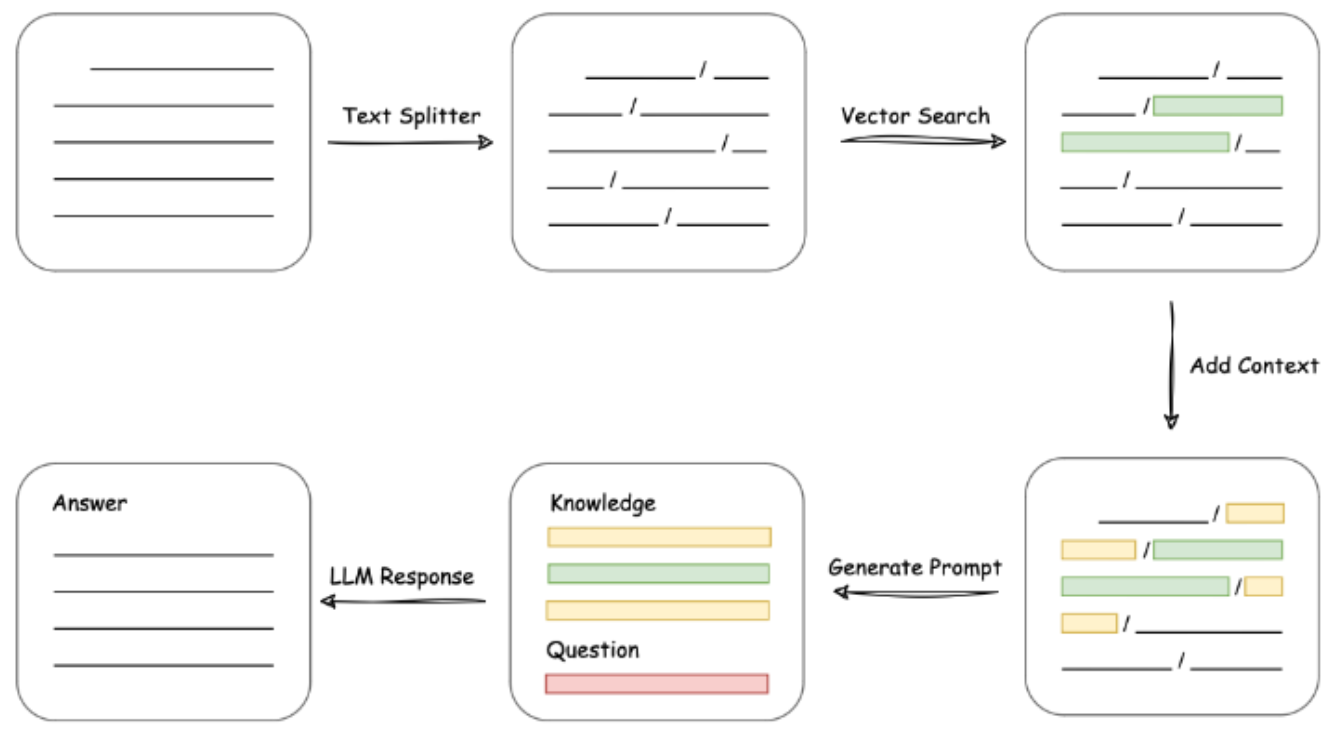
ChatPDF实现原理
加载文件 -> 读取文本-> 文本分割 -> 文本向量化-> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个-> 匹配出的文本作为上下文和问题一起添加到 prompt 中-> 提交给 LLM 生成回答。

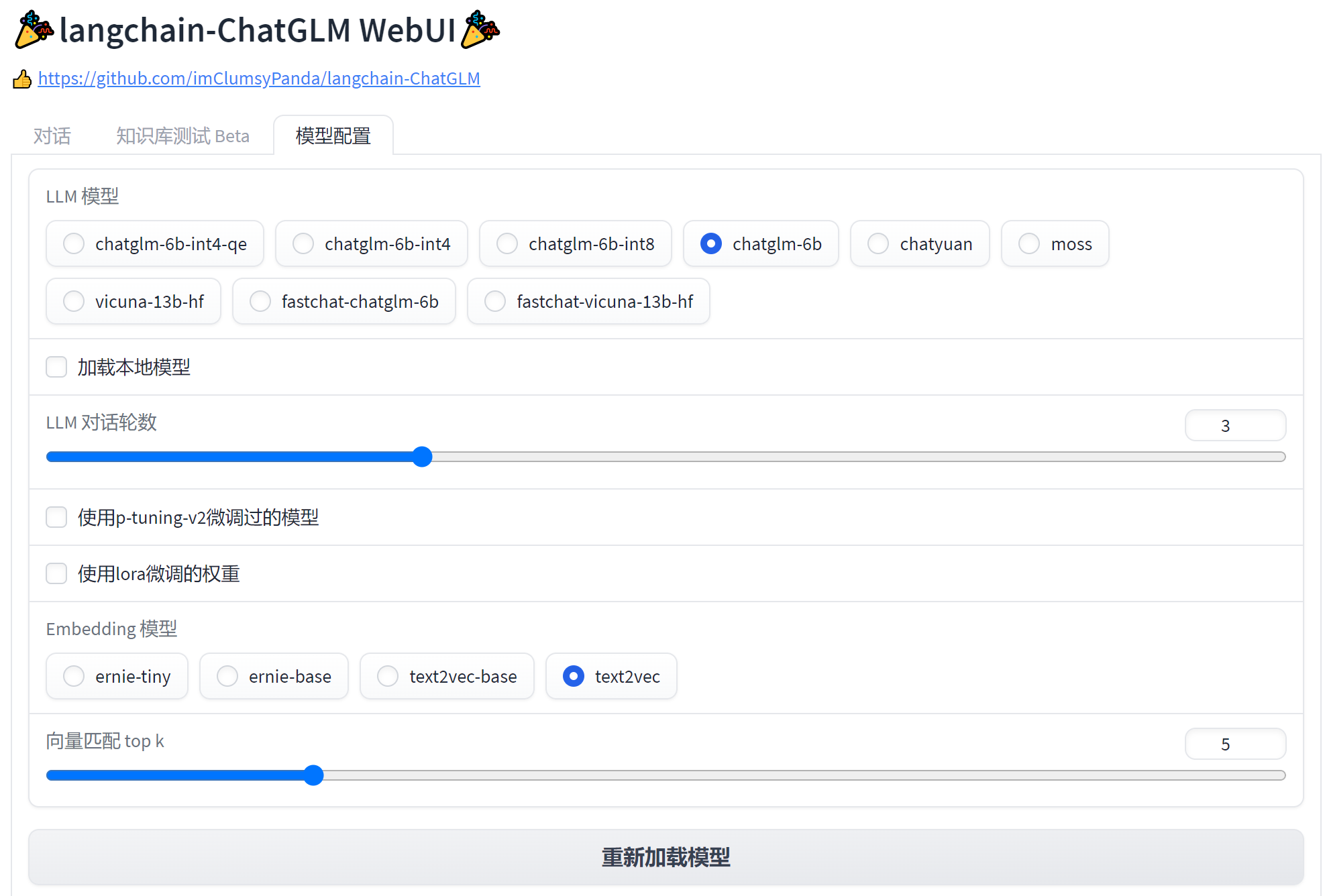
LangChain + ChatGLM
https://github.com/imClumsyPanda/langchain-ChatGLM
# 加载Google云硬盘
from google.colab import drive
drive.mount('/content/drive’)
# 拉取仓库
%cd /content/drive/MyDrive/chatglm/langchain-ChatGLM
!pip install -r requirements.txt
!pip install gradio==3.28.3
# 下载模型
%cd /content/drive/MyDrive/chatglm/langchain-ChatGLM
!git clone https://huggingface.co/THUDM/chatglm-6b-int4
!git clone https://huggingface.co/GanymedeNil/text2veclarge-chinese
#修改web.py和model_config.py文件
!sed -i 's/share=False/share=True/g'
/content/drive/MyDrive/chatglm/langchainChatGLM/webui.py
!sed -i 's/GanymedeNil\/text2vec-largechinese/\/content\/drive\/MyDrive\/chatglm\/langchainChatGLM\/text2vec-large-chinese/g'
/content/drive/MyDrive/chatglm/langchainChatGLM/configs/model_config.py
……
ChatPDF实现场景
典型的使用场景:
- 项目经理角色:项目管理文档 + LLM
- 新车导购角色:新车导购文章 + LLM
- 二手车专家:二手车鉴定文档 + LLM
- 老中医角色: 中医问诊文档 + LLM
- 智能客服:客服聊天记录 + LLM
- 律师角色:律师咨询记录 + LLM
- HR角色:考勤绩效手册 + LLM
一个典型的prompt模板
已知信息:
{context} 根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息",不允许在答案中添加编造成分,答案请使用中文。
问题是:{question}
向量数据库
存储embedding的数据库称为向量数据库。ChatGPT中的Transformer结构需要对知识进行Embedding。

其他知识库方案
https://chat.openai.com/g/g-V2KIUZSj0-ai-pdf
Ai PDF是基于GPT的一个PDF文档处理工具,具有以下特点:
- 可以处理体积高达2GB的单个PDF文件,没有限制。
- 支持在http://myaidrive.com免费账号下上传大量PDF,无需重复上传文件。
- PRO版本可以在数千个PDF中进行检索,并可以处理扫描的OCR文档。
- 可以为长度较长的文档生成高质量的摘要。
- 利用GPT的能力从PDF中提取信息,进行问答。
- 整体而言,Ai PDF致力于提供PDF文档处理、搜索、摘要和问答等功能,可以节省人工查阅PDF的大量时间,提高工作效率。
- 该服务正在不断完善中,需要用户签约才能使用ChatGPT进行互动。
https://github.com/imartinez/privateGPT
这是一个开源项目,让用户可以利用GPT的力量与自己的文档进行交互,完全本地运行,不会泄露用户数据。用户可以导入各种文档,然后用自然语言提出问题,GPT会基于这些文档给出回答。
https://github.com/nomic-ai/gpt4all
它提供了开源的GPT聊天机器人,可以在本地环境运行,不需要连接外部API。支持多种编程语言实现,可以自定义训练来优化对话效果。
https://github.com/PromtEngineer/localGPT
这也是一个本地运行GPT模型的开源项目。用户可以将文档导入本地,GPT模型会基于这些文档内容来回答用户提出的问题,保护了用户隐私。
https://filegpt.app/
这是一个商业化的工具,同样可以让用户与各种格式的文档和内容进行自然语言交互,获取精确的回复。它支持PDF、Word文档、文本、音频、视频等多种格式。
https://www.popai.pro/
这是一个面向个人的AI工作空间服务,用户可以自定义训练模型来优化不同的任务,如写作、总结、问答等。它提供了可视化的训练监控界面。主要面向企业用户。
https://www.humata.ai/
Humata是一个利用AI技术让用户可以与各种数据文档进行自然语言交互的工具。
https://askwise.ai/
askwise.ai是一个基于GPT的知识助手服务。
结语
知识就是力量,AI生成筑高楼。
欢迎留言交流!
我是李孟聊AI,独立开源软件开发者,SolidUI作者,对于新技术非常感兴趣,专注AI和数据领域,如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢!