注:
- 本文根据《BGP in the Datacenter》整理,有兴趣和英文阅读能力的朋友可以直接看原文:https://www.oreilly.com/library/view/bgp-in-the/9781491983416/
- 上一部分笔记请参考:https://blog.csdn.net/tushanpeipei/article/details/128493161
一、如何选择路由协议
在传统的部署模型中,BGP学习从另一个路由协议中“发现”路由,并通告给自己的对等体。这些路由协议通常是开放式最短路径优先(OSPF)、中间系统到中间系统(IS-IS)或增强型内部网关路径路由协议(EIGRP)。它们被称为内部路由协议(IGP),它们用于路由的“计算”。因此,人们认为BGP在数据中心需要另一个路由协议也就不足为奇了。然而,在数据中心,BGP是仅有的内部路由协议。
在数据中心使用之前,BGP主要(如果不是完全)用于服务提供商网络(ISP)。由于其网络结构和用途与数据中心网络截然不同,所以BGP在部署在数据中心时,我们需要进行一定的调整。从网络架构来说,数据中心网络的密集连接是一个与自治区域(Autonomous System,或AS)之间相对稀疏的连接截然不同。在ISP网络中,稳定性优于快速通知更改。因此,BGP通常会暂时推迟发送有关更改的通知。在数据中心网络中,我们希望路由更新尽可能的迅速。另一个例子是,由于BGP的默认设计及其作为路径向量协议的性质,单条链路故障可能导致在所有节点之间传递过多的BGP消息,这是我们最好避免的。第三个例子是BGP的默认行为,当从许多不同的自治系统编号(ASN)学习前缀时,仅仅会构建单个最佳路径。但在数据中心内,为了提高链路的利用率,我们希望选择多条路径。
二、选择eBGP还是iBGP
通常我们的第一印象是,在单独的AS中,我们选择内部BGP(internal BGP或iBGP)建立对等体关系,而在AS之间则使用外部BGP(external BGP或eBGP)建立对等体关系。在数据中心的网络架构中,我们通常使用eBGP而非iBGP,这是可能和以往理解不同的。这主要是因为eBGP的一些特性更契合数据中心Clos网络结构的原因。
简单来说,使用eBGP的主要原因是eBGP比iBGP更容易理解和部署。iBGP可能会混淆其最佳路径选择算法、转发或不转发路由的规则以及对哪些前缀属性采取行为。例如,由于防环的需要,当节点收到自己iBGP对等体发送来的路由默认不转发给其他的iBGP对等体,如果需要其他对等体也能够收到对应的路由,则通常会部署路由反射器(Route Reflector),增加了网络的复杂度。相比之下,eBGP则简单粗暴,只要是对等体发送来对路由,都会通告给其他对对等体。此外,iBGP的多路径支持也有限制:在一些特定的场景下,当一条路由由两个不同的节点发布发布时,很难通过AS-path属性来选择。克服这个限制是可能的,但很麻烦。
最后,选择eBGP的一个强大的非技术原因是,与iBGP相比,eBGP的功能更强大。客户可以通过选择eBGP而不是iBGP来避免供应商锁定。直到2012年年中左右,当时iBGP实现有缺陷,功能不如数据中心内运行所需的功能。
三、ASN编号设计
自治系统编号(ASN)是BGP中的一个基本概念。每个BGP Speaker都必须有一个ASN。它可以用于标识路由环路,确定路由的最佳路径等。在Internet上,ASN是类似于公网IP地址,它被权威的分配给不同的区域。当然,ASN也有私有ASN(传统2字节AS 64512–65534,或4字节的AS 4200000000–4294967294),被应用于一个组织内部的网络中。因此,在一个数据中心中,我们应该使用的是私有的ASN,其好处是避免内部BGP信息泄露到外网,造成不必要的损失。
此外,如果我们确定了使用eBGP构建数据中心的Underlay网络,最直接的方式就是每一个节点(交换机)都使用单独的ASN。但是这种ASN分配方式会带来一定的问题:
- 如果是使用私有的2字节ASN,1023个编号无法满足使用需求;
- 造成路径狩猎(Path Hunting)。
首先,对于第一个问题。我们对于2字节的ASN不够用的情况,我们不可避免的需要重复使用一些ASN,并且在特定的节点使用AS rewrite或者allowas-in的方式重写或者允许对应AS路由被接收。此外,可以选择使用4字节的AS,目前4字节的AS基本上在所有的设备上都已经能过支持。
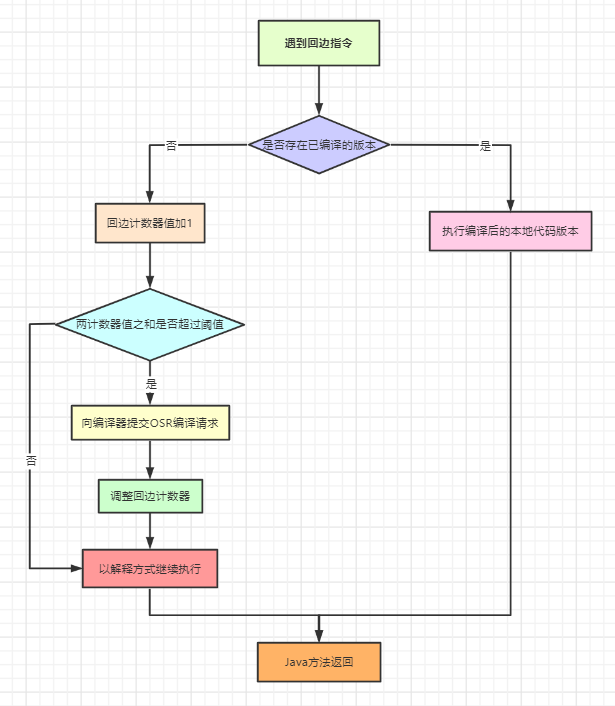
对于第二个问题,Path Hunting,这也是所有的距离矢量路由协议的通病。简单来说,Path Hunting就是因为一台设备仅仅学习并相信路由信息,而没有链路状态信息帮助其全面的了解整个网络,而导致当一条路由失效后,依然去选择一些“没有立刻消失的”,不应存在的路由来传递流量。下面用一个例子来展示:

在图1显示对拓扑中,所有节点都有单独的ASN。现在,从R1的角度考虑如何访问由R4通告的路由前缀10.1.1.1。R1可以从eBGP对等体R2和R3接收到前缀10.1.1.1。R2为10.1.1.1宣告的AS_PATH是[R2,R4],由R3宣告的AS_PATH是[R3,R4]。此外,当R1从R2和R3学习到10.1.1.1的路径时,它会选择其中一条作为最佳路径。但是也会将另外一条路径保存在对应的数据库中,以作为最优路由失效后的备份。
同理,R2也会从R4和R1学习到去往10.1.1.1的路由,AS-path分别为[R4],以及[R4,R3,R1]。由于R2会优选AS-path最短的路由,所有R2默认情况下会选择R4发送来的条目。但是一旦R4出现故障,导致10.1.1.1路由不可达。那么R2和R3都会撤销(withdraw)由R4发送来的10.1.1.1的路由。但是以R2为例子,它依然存在一条来自R1的,[R4,R3,R1]的无效路由,并转发流量。这种情况只能等到R1接受到了R3发送到10.1.1.1的撤销消息后,并通告给R2后才得以解除。虽然看似这不是一个大问题,但是在网络规模及其庞大的数据中心中,会造成大量的流量丢包,是需要我们尽可能避免的。
简单来说,我们可以通告另一种ASN分配方式来杜绝Path Hunting情况的发生。例如,我们将R2和R3规划使用相同的ASN,这样由于AS-path属性不允许接收相同ASN路由的原因,R2和R3仅仅保存一条直接去往R4的路由条。一旦该路由失效,R2和R3直接撤销去对应的路由条目即可。
因此,在Clos数据中心网络架构中,我们通常使用如下的ASN规划方式来规避Path Hunting:
- 所有Tor设备都分配了自己的ASN;
- 横跨Pod的Leaf节点有不同的ASN,但每个Pod的Leaf节点都有一个该Pod独有的ASN;
- 所有Spine共享一个共同的ASN。

在这种ASN的分配形式下,每一个Pod中的Leaf节点和Spine节点都不会保存多条去往目的地的路由。比如,右边65000 ASN的Leaf节点可以从[65001],[65002,65000,65001]两条路径获取到65001下的服务器的路由,但是由于第二条路由出现了AS-path环路的原因,不会进入BGP的数据库中。
当然,使用这种ASN分配方式依然存在其劣势,那就是不能在Leaf和Spine节点上进行路由聚合。我们可以通过如下的例子进行解释:如果65000 Leaf节点对65001 Tor节点下的路由进行了汇聚,并发送给了其下的65002 Tor节点。这时候,Leaf节点上学习到的65001 Tor节点路由出现了部分的丢失,但是Leaf依然会将同样的聚合路由发送给65002 Tor节点。那么就会导致65002 Tor下服务器需要去访问65001节点下服务器的时候,由于匹配到Leaf节点通告的聚合路由,会将报文转发给Leaf节点。然而Leaf节点由于没有对应的明细路由,会对65002 Tor过来的流量进行丢弃。然而,在Leaf没有聚合路由,仅通告明细路由的情况下,65002 Tor由于不存在去往对端设备的明细路由,则会直接丢弃对应的流量,减少了不必要的链路带宽损耗。
四、最优路径算法
BGP协议的一大优势就是拥有极为丰富的选路属性。通常IGP协议,例如OSPF、ISIS的选路方式很单一,就是通过metric值进行比较。而BGP则可以通过10多条规则进行比较(不同厂商实现的方式会略有不同),默认选择出一条自己认为最优的路由,加入到自己的BGP路由表中(实际上在各厂商实现时,在BGP的数据库中也会保存学习到的次优的路由),有着极大的灵活性。
当从一个或多个对等体收到新的UPDATE消息时,BGP的最佳路径选择会触发。当然我们也可以根据网络具体情况,可以选择是否使用缓冲算法,以便一次运行将处理所有更新,而不是通过非常频繁地运行算法来快速交换路由。
由于BGP默认总会通过规则的比较选择出一条最优的路由,那么就会导致去往一个目的地永远只会选择一条路径,无法实现ECMP,极大的浪费了Clos架构中的丰富的链路资源。
五、多路径选择
为了利用好Clos架构中丰富的链路资源,我们需要开启BGP的多路径选择功能(multipathing)。该功能一旦开启,那么仅仅会比较前面几个规则,如果相同,则可以实现等价多路径,以Cisco为例子,前八个比较规则中,只有前7条完全一致,才能满足BGP路由负载分担的条件:

需要注意的是,这里我们所提到的是属性完全相同,包含AS-path的具体路径。那么,在我们的数据中心网络中,通常不同的Tor下的很多提供相同功能的服务器使用同样的IP地址(或者一台服务器会为了可靠性会同时接入2台Tor),以实现业务的负载分担。那么由于Tor节点的ASN各不相同,会导致Leaf设备学习到的路由中的AS-path也各不相同,因此无法实现流量的负载均衡。所以,我们需要在设备上开启bestpath as-path multipath-relax的功能,在AS-path路径长度相同的情况下,忽视其中具体的ASN,以实现流量的负载分担。
需要注意的是,虽然我们可以通告多路径实现路由在本地的负载分担,但是当BGP发送给其对等体的时候,依然只会发送最优的路由。
六、由于默认计时器导致收敛缓慢
BGP作为一种特殊的路径矢量路由协议,相较于基于链路状态计算路由的OSPF、ISIS协议,其收敛速度会慢很多。其主要原因是因为BGP所运用的定时器的默认值是适用于ISP的环境,需要足够的稳定性。然而,在数据中心网络架构中,我们需要对其定时器进行修改,以匹配OSPF和ISIS对收敛速度。
首先,我们需要明白了解BGP存在四个定时器,分别是Advertisement Timer,Keepalive and Hold Timers以及Connect Timer。
- Advertisement Timer:该定时器也被称为更新定时器,设置其对主要目的是设定BGP向同一个peer最短的更新时间。这个最小间隔窗口内的事件聚集在一起,并在最小间隔到期时一次性发送。它有助于防止在短时间内进行多次更新时进行不必要的处理。此间隔的默认值对于eBGP对等体为30秒,对于iBGP对等体为0秒。然而,对于像数据中心这样的连接丰富的网络来说,在更新之间等待30秒是错误的选择。它应该设置为0秒,因为其实流量没有跨越真正的AS,和iBGP相同。
- Keepalive和Hold Timers:这两个定时器的作用是保持BGP对等体之间的连接。默认情况下,Keepalive计时器为60秒,Hold计时器为180秒(不同厂商设置的默认值可能不同)。这意味着节点每分钟都会为会话发送Keepalive消息。如果对等体在三分钟内没有看到对方发送的Keepalive报文,它将宣布会话死亡。此外,双向转发检测(BFD)的协议,也可以帮助BGP更快的检查对等体是否存活。但是,要捕捉BGP进程本身的错误,我们需要直接调整这些计时器。在数据中心内配置的最常见的值是Keepalive计时器为3秒,Hold计时器为9秒。
- Connect Timer:这是BGP初始连接或因为错误进行重新连接时需要的等待时间,默认是60s(不同厂商有不同的实现)。太长的Connect Timer可能会延缓BGP对等体的重新建立邻居的时间。此定时器也是四个定时器在数据中心应用中最不重要的。
七、数据中心的默认配置
在数据中心中,我们需要配置大量的BGP设备,所以我们需要固定下来我们的BGP的默认配置模板以减少出错的可能性。如下有一些设置我们最好需要统一记录,并作为我们数据中心网络建设的模版:
- 为eBGP和iBGP启用了多路径;
- Update更新间隔设置为0;
- keepalive和Hold计时器设置为3秒和9秒;
- 通过日志记录邻接状况的更改。
在后续的章节中,会进一步探索BGP在数据中心节点上的配置。