什么是消息队列
- 消息队列:在消息的传输过程中保存消息的容器,生产者和消费者不直接通讯,依靠队列保证消息的可靠性,避免了系统间的相互影响。系统间的数据流通道
应用场景
- 异步处理:用户注册后,需要发注册邮件和注册短信
对于无需关注调用结果的场景,可以通过消息队列异步处理 - 应用解耦:用户下单后,订单系统需要通知库存系统。
将模块间的RPC调用改为通过消息队列中转,解除系统间的耦合 - 流量削锋:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。可以控制活动的人数,可以缓解短时间内高流量压垮应用。
系统的吞吐量往往取决于底层存储服务的处理能力,数据访问层可以调整消费速度缓解存储服务压力,避免短暂的高峰将系统压垮 - 日志处理:将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题。
- 消息通讯:实现点对点消息队列,或者聊天室等。
消息队列模式
- 点对点模式:一个具体的消息只能由一个订阅者消费。多个生产者可以向同一个消息队列发送消息
- 发布/订阅模式:单个消息可以被多个订阅者并发的获取和处理
主流消息队列
kafka 分析
名词解释
- Producer:生产者,消息产生和发送端。
- Broker:Kafka 实例,多个 broker 组成一个 Kafka 集群,通常一台机器部署一个 Kafka 实例,一个实例挂了不影响其他实例。
- Consumer:消费者,拉取消息进行消费。 一个 topic 可以让若干个消费者进行消费,若干个消费者组成一个 Consumer Group 即消费组,一条消息只能被消费组中一个 Consumer 消费。
- ZooKeeper:用于管理和协调的Kafka集群,也用它来通知生产者和消费者关于 Kafka 系统中任何新代理的存在或 Kafka 系统中代理的故障。
- Topic:主题,服务端消息的逻辑存储单元。一个 topic 通常包含若干个 Partition 分区
- Partition:topic 的分区,分布式存储在各个 broker 中, 实现发布与订阅的负载均衡。若干个分区可以被若干个 Consumer 同时消费,达到消费者高吞吐量。一个分区拥有多个副本(Replica)
- message:消息,或称日志消息,是 Kafka 服务端实际存储的数据,每一条消息都由一个 key、一个 value 以及消息时间戳 timestamp 组成。
- offset:偏移量,分区中的消息位置,由 Kafka 自身维护,Consumer 消费时也要保存一份 offset 以维护消费过的消息位置
- 控制器(Controller):控制器主要作用是管理和协调 Kafka 集群
- 主题管理:创建、删除 topic,以及增加 topic 分区等操作都是由控制器执行。
- 分区重分配:执行 Kafka 的 reassign 脚本对 topic 分区重分配的操作,也是由控制器实现。
- 集群成员管理,数据服务
Kafka 体系架构
组成部分
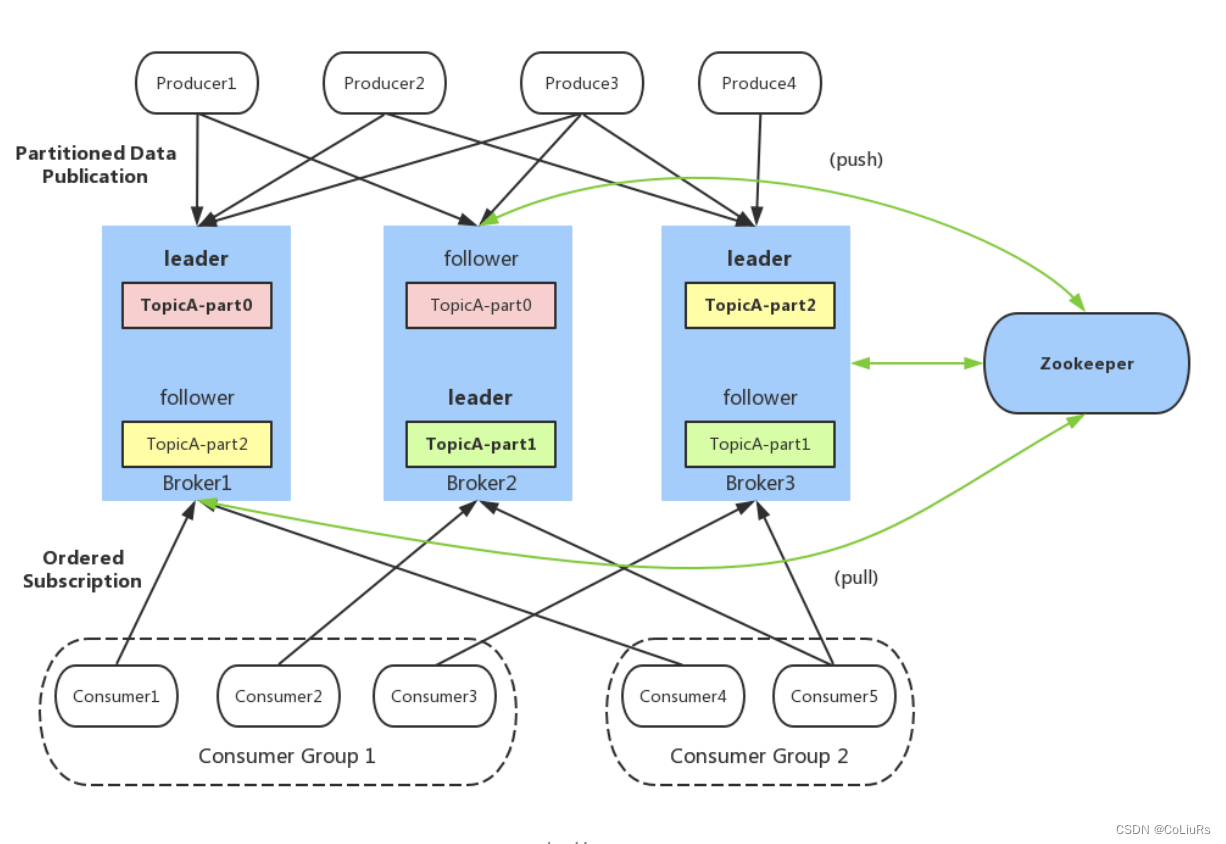
Kafka 消息存储
Topic 副本机制
- Topic 的Partition,分布式存储在各个 Broker 中,一个Partition拥有多个副本(Replica。
- 消息冗余存储,提高 Kafka 数据的可靠性;
- 提高 Kafka 服务的可用性,follower 副本能够在 leader 副本挂掉或者 broker 宕机的时候参与 leader 选举,继续对外提供读写服务。
- 为什么 follower 副本不提供读服务:在kafka中,实现副本的目的就是冗余备份,且仅仅是冗余备份,所有的读写请求都是由leader副本进行处理的。follower副本仅有一个功能,那就是从leader副本拉取消息,尽量让自己跟leader副本的内容一致。
- 复制仅发生在分区级别
- 对于给定的分区,一次只有一个Broker可以成为leader。 同时,其他Broker将拥有同步副本;这就是我们所说的 ISR(In Sync Replica)
- ISR 是分区中正在与 leader 副本进行同步的 replica 列表,且必定包含 leader 副本。
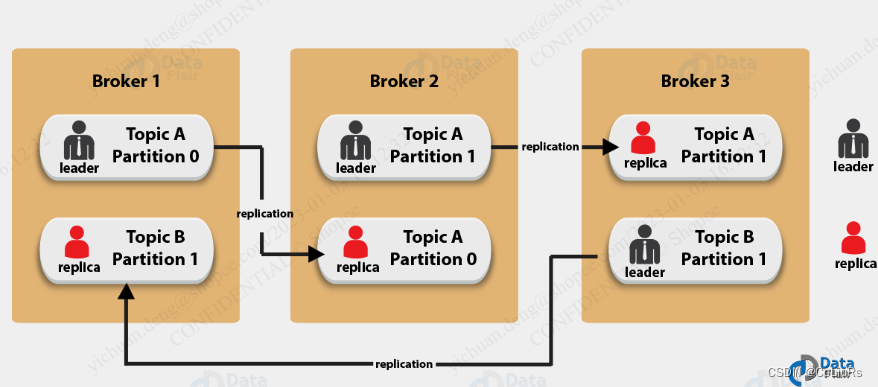
- ISR 是分区中正在与 leader 副本进行同步的 replica 列表,且必定包含 leader 副本。
Kafka 消息发送机制
-
异步发送: 异步生产者使用channel接收(生产成功或失败)的消息,并且也通过channel来发送消息,这样做通常是性能最高的
-
同步发送:同步生产者需要阻塞,直到收到了acks。这会带来两个问题,一是性能变得更差了,而是可靠性是依靠参数acks来保证的。
-
批量发送:发送到缓冲 buffer 中消息将会被分为一个一个的 batch,分批次的发送到 broker 端,批次大小由参数 batch.size 控制,默认16KB。这就意味着正常情况下消息会攒够 16KB 时才会批量发送到 broker 端,所以一般减小 batch 大小有利于降低消息延时,增加 batch 大小有利于提升吞吐量。
-
消息重试:Kafka 生产端支持重试机制,对于某些原因导致消息发送失败的,比如网络抖动,开启重试后 Producer 会尝试再次发送消息

-
基本流程就是:创建对象(主题、分区、key/value)-> 序列化数据 -> 到达分区(可自己指定,也可以通过key hash)-> 放入批次(相同主题和分区) -> 独立线程发送 -> 返回主题/分区/分区偏移量/时间戳。
-
分区策略:顺序分配,随机分配,Hash分配
Kafka 消息消费机制
- Pull 模式消费数据,采用 Pull 模式的好处是Consumer可以自主决定是否批量的从Broker拉取数据。Pull模式有个缺点是,如果Broker没有可供消费的消息,将导致Consumer不断在循环中轮询,直到新消息到达。为了避免这点,可以配置让Consumer阻塞直到新消息到达。
- Kafka Consumer Client 消费消息通常包含以下步骤:
- 配置客户端
- 创建消费者
- 订阅主题
- 拉取消息并消费
- 提交消费位移
- 关闭消费者实例
Kafka 消费端 Rebalance 机制
Rebalance 是让一个消费组的所有消费者就如何消费订阅 topic 的所有分区达成共识的过程,在 Rebalance 过程中,所有 Consumer 实例都会停止消费,等待 Rebalance 的完成。
因为要停止消费等待重平衡完成,因此 Rebalance 会严重影响消费端的 TPS,是应当尽量避免的。
Rebalance 非常重要,它为消费者群组带来了高可用性 和 伸缩性,我们可以放心的添加消费者或移除消费者。
关于何时会发生 Rebalance,总结起来有三种情况:
- 消费组的消费者成员数量发生变化
- 消费主题的数量发生变化
- 消费主题的分区数量发生变化
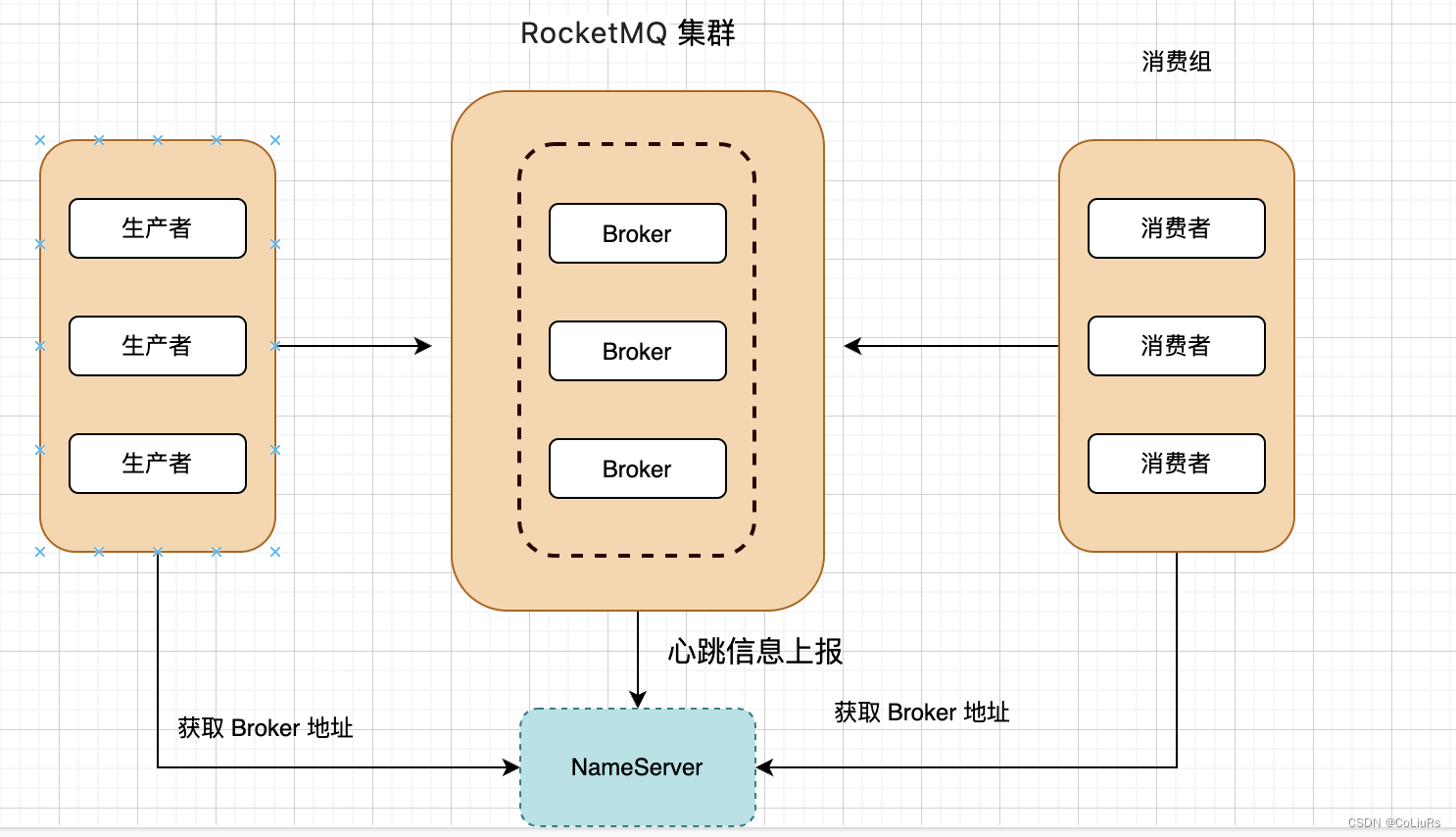
RocketMQ
- RocketMQ是一个纯Java、分布式、队列模型的开源消息中间件
- RocketMQ 有很多概念都和kafka类似,这里只例举与kafka不相同的概念
基本概念
- NameServer:一个功能齐全的服务器,其角色类似Zookeeper。
- Tag:子主题,它是消息的第二级类型,用于为用户提供额外的灵活性,Topic 是消息的第一级类型
- Queue:队列,在Kafka中叫Partition。每个Queue内部是有序的
文档参考
- https://mp.weixin.qq.com/s/9fJchPJa_raHSkvo29bkEA
- https://mp.weixin.qq.com/s?__biz=MzkzMDI1NjcyOQ==&mid=2247487730&idx=1&sn=c51de28679d92f9086f1b94e72a5cb62&source=41#wechat_redirect
- https://mp.weixin.qq.com/s/P8bt9JYIiQlVHzwZfjr0AQ
- https://www.cnblogs.com/rickiyang/p/14649750.html
- https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html
- https://www.lixueduan.com/posts/kafka/11-consumer-group-rebalance/#2-consumer-group