文章目录
- 概览:RL方法分类
- 策略梯度(Policy Gradient)
- Basic Policy Gradient
- 目标函数1:平均状态值
- 目标函数2:平均单步奖励
- 🟡PG梯度计算
- 🟦REINFORCE
本系列文章介绍强化学习基础知识与经典算法原理,大部分内容来自西湖大学赵世钰老师的强化学习的数学原理课程(参考资料1),并参考了部分参考资料2、3的内容进行补充。
系列博文索引:
- 强化学习的数学原理学习笔记 - RL基础知识
- 强化学习的数学原理学习笔记 - 基于模型(Model-based)
- 强化学习的数学原理学习笔记 - 蒙特卡洛方法(Monte Carlo)
- 强化学习的数学原理学习笔记 - 时序差分学习(Temporal Difference)
- 强化学习的数学原理学习笔记 - 值函数近似(Value Function Approximation)
- 强化学习的数学原理学习笔记 - 策略梯度(Policy Gradient)
- 强化学习的数学原理学习笔记 - Actor-Critic
参考资料:
- 【强化学习的数学原理】课程:从零开始到透彻理解(完结)(主要)
- Sutton & Barto Book: Reinforcement Learning: An Introduction
- 机器学习笔记
*注:【】内文字为个人想法,不一定准确
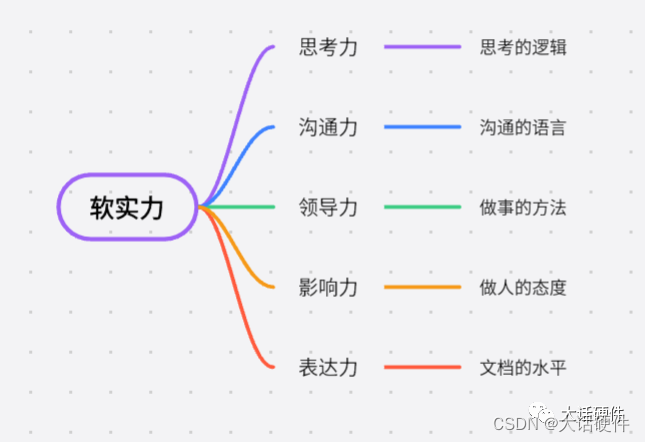
概览:RL方法分类
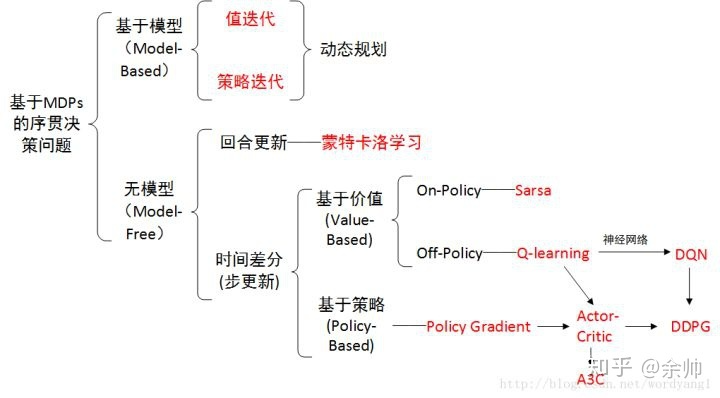
*图源:https://zhuanlan.zhihu.com/p/36494307
策略梯度(Policy Gradient)
在先前的内容中,策略用表(tabular)的形式进行表达,其也可以用函数的形式进行表达(尤其是当状态空间或动作空间连续或非常大时),优势在于降低存储开销和提升泛化能力。
之前的方法(值函数近似)称之为Value-based,而策略梯度(Policy Gradient)和Actor-Critic均为Policy-based。Value-based方法围绕状态值/动作值设计,而Policy-based优化关于策略的目标函数,从而直接得到最优策略。
Basic Policy Gradient
将策略表示为参数化函数:
π
(
a
∣
s
,
θ
)
\pi(a|s, \theta)
π(a∣s,θ),其中
θ
∈
R
m
\theta \in \mathbb{R} ^m
θ∈Rm为参数向量,
π
\pi
π是关于
θ
\theta
θ的函数。
*其他写法:
π
(
a
,
s
,
θ
)
\pi(a,s, \theta)
π(a,s,θ),
π
θ
(
a
∣
s
)
\pi_\theta(a|s)
πθ(a∣s),
π
θ
(
a
,
s
)
\pi_\theta(a,s)
πθ(a,s)
与tabular representation的区别:
- 最优策略:不是能够最大化每个状态值的策略,而是能够最大化特定scalar metrics的策略
- 动作概率:不能直接获取,需要进行计算
- 策略更新:不能直接更新,需要通过改变参数 θ \theta θ来进行改变
策略梯度方法通过优化指定目标函数
J
(
θ
)
J(\theta)
J(θ),直接得到最优策略:
θ
t
+
1
=
θ
t
+
α
∇
θ
J
(
θ
t
)
\theta_{t+1} = \theta_t + \alpha \nabla_\theta J(\theta_t)
θt+1=θt+α∇θJ(θt)
目标函数
J
(
θ
)
J(\theta)
J(θ)通常有以下两种类型:平均状态值
v
ˉ
π
\bar{v}_\pi
vˉπ和平均单步奖励
r
ˉ
π
\bar{r}_\pi
rˉπ。实际上,当折扣因子
γ
<
1
\gamma<1
γ<1时,二者是等价的:
r
ˉ
π
=
(
1
−
γ
)
v
ˉ
π
\bar{r}_\pi = (1- \gamma) \bar{v}_\pi
rˉπ=(1−γ)vˉπ。
目标函数1:平均状态值
平均状态值(average state value / average value):
v
ˉ
π
=
∑
s
∈
S
d
(
s
)
v
π
(
s
)
=
E
[
v
π
(
S
)
]
\bar{v}_\pi = \sum_{s\in{\mathcal{S}}} d(s) v_\pi(s) = \mathbb{E}[v_\pi(S)]
vˉπ=s∈S∑d(s)vπ(s)=E[vπ(S)]
其中,
d
(
s
)
≥
0
d(s) \geq 0
d(s)≥0且
∑
s
∈
S
d
(
s
)
=
1
\textstyle\sum_{s\in{\mathcal{S}}} d(s) =1
∑s∈Sd(s)=1,因此
d
(
s
)
d(s)
d(s)既可以看作是状态
s
s
s的权重,也可以看作是随机变量
S
S
S的概率分布。
其他形式: v ˉ π = E [ ∑ t = 0 ∞ γ t R t + 1 ] \bar{v}_\pi = \mathbb{E} \Big[\sum_{t=0}^{\infin} \gamma^t R_{t+1} \Big] vˉπ=E[∑t=0∞γtRt+1]
向量形式: v ˉ π = d T v π \bar{v}_\pi = d^T v_\pi vˉπ=dTvπ
在常见的情况下,
d
d
d是取决于
π
\pi
π的平稳分布,即
d
π
(
s
)
d_\pi(s)
dπ(s),其具有以下性质:
d
π
T
P
π
=
d
π
T
d^T_\pi P_\pi = d^T_\pi
dπTPπ=dπT
其中,
P
π
P_\pi
Pπ是状态转移概率矩阵。
目标函数2:平均单步奖励
平均单步奖励(average one-step reward / average reward)
r
ˉ
π
=
∑
s
∈
S
d
(
s
)
r
π
(
s
)
=
E
[
r
π
(
S
)
]
\bar{r}_\pi = \sum_{s\in{\mathcal{S}}} d(s) r_\pi(s) = \mathbb{E}[r_\pi(S)]
rˉπ=s∈S∑d(s)rπ(s)=E[rπ(S)]
其中,
S
∼
d
π
S \sim d_\pi
S∼dπ,
d
π
d_\pi
dπ为平稳分布。
r
π
(
s
)
=
∑
a
∈
A
π
(
a
∣
s
)
r
(
s
,
a
)
r_\pi(s) = \sum_{a\in\mathcal{A}} \pi(a|s) r(s, a)
rπ(s)=∑a∈Aπ(a∣s)r(s,a)为策略
π
\pi
π在状态
s
s
s下取得的平均单步奖励,而
r
(
s
,
a
)
=
E
[
R
∣
s
,
a
]
=
∑
r
r
p
(
r
∣
s
,
a
)
r(s, a) = \mathbb{E} [R|s, a] = \sum_r r p(r | s, a)
r(s,a)=E[R∣s,a]=∑rrp(r∣s,a)。
另一种形式:
假设agent遵循一个策略生成了奖励为
(
R
t
+
1
,
R
t
+
2
,
⋯
)
(R_{t+1}, R_{t+2}, \cdots)
(Rt+1,Rt+2,⋯)的trajectory,其平均单步奖励为:
lim
n
→
∞
1
n
E
[
∑
k
=
1
n
R
t
+
k
∣
S
t
=
s
0
]
\lim_{n\rarr\infin} \frac{1}{n} \mathbb{E} \Big[ \sum_{k=1}^{n} R_{t+k} | S_t = s_0 \Big]
limn→∞n1E[∑k=1nRt+k∣St=s0]
其中,
s
0
s_0
s0为该trajectory的起始状态。考虑无穷多步的极限,上式等价于【似乎是与平稳随机过程有关,时间平均等于统计平均,不确定】:
lim
n
→
∞
1
n
E
[
∑
k
=
1
n
R
t
+
k
]
=
r
ˉ
π
\lim_{n\rarr\infin} \frac{1}{n} \mathbb{E} \Big[ \sum_{k=1}^{n} R_{t+k} \Big] = \bar{r}_\pi
limn→∞n1E[∑k=1nRt+k]=rˉπ
🟡PG梯度计算
策略梯度方法的梯度计算可以统一总结为下式:
∇
θ
J
(
θ
)
=
∑
s
∈
S
η
(
s
)
∑
a
∈
A
∇
θ
π
(
a
∣
s
,
θ
)
q
π
(
s
,
a
)
\nabla_\theta J(\theta) = \sum_{s\in\mathcal{S}} \eta (s) \sum_{a\in\mathcal{A}} \nabla_\theta \pi (a|s, \theta) q_\pi(s, a)
∇θJ(θ)=s∈S∑η(s)a∈A∑∇θπ(a∣s,θ)qπ(s,a)
其中:
- J ( θ ) J(\theta) J(θ)可以为 v ˉ π \bar{v}_\pi vˉπ、 r ˉ π \bar{r}_\pi rˉπ或 v ˉ π 0 \bar{v}_\pi^0 vˉπ0
- = = =可以为相等、约等 ≈ \approx ≈、成比例 ∝ \propto ∝
- η \eta η是状态的分布或权重(如上文中的 d π d_\pi dπ)
进一步地,可以基于下式计算梯度:
∇
θ
J
(
θ
)
=
E
[
∇
θ
ln
π
(
A
∣
S
,
θ
)
q
π
(
S
,
A
)
]
\nabla_\theta J(\theta) = \mathbb{E} [\nabla_\theta \ln\pi (A|S, \theta) q_\pi(S, A) ]
∇θJ(θ)=E[∇θlnπ(A∣S,θ)qπ(S,A)]
其中,
S
∼
η
S\sim\eta
S∼η且
A
∼
π
(
A
∣
S
,
θ
)
A\sim\pi(A|S, \theta)
A∼π(A∣S,θ)。通过随机采样的方式估计期望,则有:
∇
θ
J
(
θ
)
≈
∇
θ
ln
π
(
A
∣
S
,
θ
)
q
π
(
S
,
A
)
\nabla_\theta J(\theta) \approx \nabla_\theta \ln\pi (A|S, \theta) q_\pi(S, A)
∇θJ(θ)≈∇θlnπ(A∣S,θ)qπ(S,A)
注意:为了计算对数
ln
\ln
ln,对所有的
s
,
a
,
θ
s, a,\theta
s,a,θ,策略必须满足:
π
(
a
∣
s
,
θ
)
>
0
\pi(a|s, \theta) > 0
π(a∣s,θ)>0。即:策略必须是随机性(stochastic)的,且为探索性(exploratory)的。(*确定性策略见后续介绍的Actor-Critic中的DPG)
这可以通过softmax实现,将向量从
(
−
∞
,
+
∞
)
(-\infin,+\infin)
(−∞,+∞)限界至
(
0
,
1
)
(0,1)
(0,1)。softmax限界后的形式为:
π
(
a
∣
s
,
θ
)
=
e
h
(
s
,
a
,
θ
)
∑
a
′
∈
A
e
h
(
s
,
a
′
,
θ
)
\pi(a|s, \theta) = \frac{e^{h(s, a, \theta)}}{\textstyle\sum_{a' \in \mathcal{A}} e^{h(s, a', \theta)}}
π(a∣s,θ)=∑a′∈Aeh(s,a′,θ)eh(s,a,θ)
其中,
h
(
s
,
a
,
θ
)
h(s, a, \theta)
h(s,a,θ)类似于特征函数,具体由神经网络确定。
推导:
已知 d ln x d x = 1 x \frac{\mathrm{d} \ln x}{\mathrm{d} x} = \frac{1}{x} dxdlnx=x1,则 ∇ ln f ( x ) = ∇ f ( x ) f ( x ) \nabla \ln f(x) = \frac{\nabla f(x)}{f(x)} ∇lnf(x)=f(x)∇f(x),故有: ∇ θ ln π ( a ∣ s , θ ) = ∇ θ π ( a ∣ s , θ ) π ( a ∣ s , θ ) \nabla_\theta \ln \pi(a|s, \theta) = \frac{\nabla_\theta \pi(a|s, \theta)}{\pi(a|s, \theta)} ∇θlnπ(a∣s,θ)=π(a∣s,θ)∇θπ(a∣s,θ)
进一步地, π \pi π的梯度可以计算为: ∇ θ π ( a ∣ s , θ ) = π ( a ∣ s , θ ) ∇ θ ln π ( a ∣ s , θ ) {\nabla_\theta \pi(a|s, \theta)} = {\pi(a|s, \theta)} \nabla_\theta \ln \pi(a|s, \theta) ∇θπ(a∣s,θ)=π(a∣s,θ)∇θlnπ(a∣s,θ)
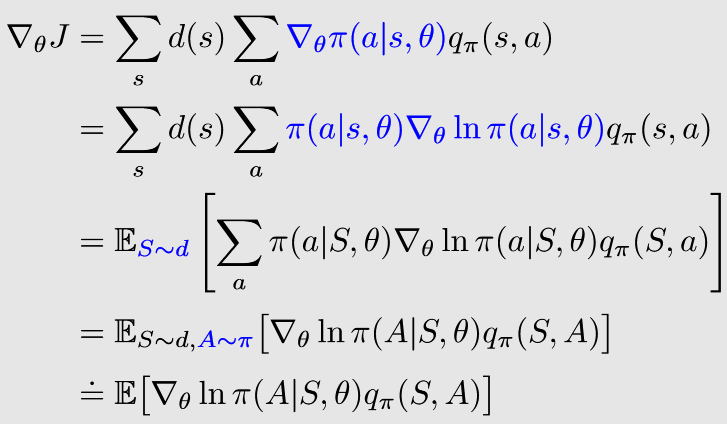
🟦REINFORCE
策略梯度(PG)方法基于梯度上升方法最大化目标函数:
θ
t
+
1
=
θ
t
+
α
E
[
∇
θ
ln
π
(
A
∣
S
,
θ
t
)
q
π
(
S
,
A
)
]
\theta_{t+1} = \theta_t + \alpha \mathbb{E} \big[ \nabla_\theta \ln\pi (A|S, \theta_t) q_\pi(S, A) \big]
θt+1=θt+αE[∇θlnπ(A∣S,θt)qπ(S,A)]
实际中,通过随机采样的方式估计期望与
q
π
(
s
t
,
a
t
)
q_\pi(s_t, a_t)
qπ(st,at),有:
θ
t
+
1
=
θ
t
+
α
∇
θ
ln
π
(
a
t
∣
s
t
,
θ
t
)
q
t
(
s
t
,
a
t
)
\theta_{t+1} = \theta_t + \alpha \nabla_\theta \ln\pi (a_t|s_t, \theta_t) q_t(s_t, a_t)
θt+1=θt+α∇θlnπ(at∣st,θt)qt(st,at)
注意: A ∼ π ( A ∣ S , θ ) A\sim\pi(A|S,\theta) A∼π(A∣S,θ), a t a_t at的采样依赖于状态 s t s_t st下的策略 π ( θ t ) \pi(\theta_t) π(θt),因此策略梯度是on-policy方法。
估计 q π ( s t , a t ) q_\pi(s_t,a_t) qπ(st,at)有两种方法:
- 蒙特卡洛(MC):REINFORCE(策略梯度的代表性算法)
- 时序差分(TD):Actor-Critic系列算法
REINFORCE算法步骤(伪代码):
初始化:
π
(
a
∣
s
,
θ
)
\pi(a|s, \theta)
π(a∣s,θ),
γ
∈
(
0
,
1
)
\gamma \in (0,1)
γ∈(0,1),
α
>
0
\alpha >0
α>0
目标:最大化
J
(
θ
)
J(\theta)
J(θ)
步骤:在第
k
k
k次迭代中,选择策略
π
(
θ
k
)
\pi(\theta_k)
π(θk)的起始状态
s
0
s_0
s0,设其episode为
{
s
0
,
a
0
,
r
1
,
⋯
,
s
T
−
1
,
a
T
−
1
,
r
T
}
\{ s_0, a_0, r_1, \cdots, s_{T-1}, a_{T-1}, r_T \}
{s0,a0,r1,⋯,sT−1,aT−1,rT}
- 在每个时间步
t
=
0
,
1
,
⋯
,
T
−
1
t=0,1,\cdots,T-1
t=0,1,⋯,T−1:
- 值更新(蒙特卡洛方法): q t ( s t , a t ) = ∑ k = t + 1 T γ k − t − 1 r k q_t(s_t,a_t) = \textstyle \sum_{k=t+1}^T \gamma^{k-t-1} r_k qt(st,at)=∑k=t+1Tγk−t−1rk
- 策略更新:更新参数
θ
t
+
1
\theta_{t+1}
θt+1,公式见上
- *注意:蒙特卡洛是offline的,需要整个episode的数据,所以这里更新完参数后不立即使用策略去采集数据
- θ k = θ T \theta_k = \theta_T θk=θT,在下次迭代中生成下一组episode的数据


![[zabbix] 分布式应用之监控平台zabbix的认识与搭建](https://img-blog.csdnimg.cn/direct/6820427111a944abaf266b85bdc6d0ba.png)