1. 简介
HBase 是一个开源的、分布式的、版本化的典型非关系型数据库。它是 Google BigTable 的开源实现,并且是 Apache 基金会的 Hadoop 项目的一部分1。HBase 在 Hadoop Distributed File System (HDFS) 上运行,作为一个列式存储非关系数据库管理系统。它提供了存储稀疏数据集的容错方式,这类数据集在许多大数据用例中十分常见。HBase 非常适合实时数据处理或者对大量数据的随机读取/写入访问
2. 特性
HBase 的数据模型是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳。HBase 的列(Column)都得归属到列族(Column Family)中。在 HBase 中,定位一行数据会有一个唯一的值,这个叫做行键 (RowKey)。而在 HBase 的列不是我们在关系型数据库所想象中的列。
HBase 的主要功能组件包括库函数、一个 Master 主服务器和许多个 Region 服务器4。Master 主服务器负责管理和维护 HBase 表的分区信息,维护 Region 服务器列表,分配 Region,负载均衡4。Region 服务器负责存储和维护分配给自己的 Region,处理来自客户端的读写请求。
HBase 是一个开源的、分布式的、面向列的数据库,具有以下主要特性:
海量存储:HBase 的单表可以有百亿行、百万列,数据矩阵横向和纵向两个维度所支持的数据量级都非常具有弹性。它适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。
列式存储:HBase 是面向列的存储和权限控制,并支持列独立检索2。HBase表的数据是基于列族进行存储的,列族是在列的方向上的划分。
极易扩展:HBase 底层文件存储依赖HDFS,从“基因”上决定了其具备可扩展性2。HBase的扩展性是热扩展,在不停止现有服务的前提下,可以随时添加或者减少节点。
高可靠性:HBase 提供WAL 和Replication 机制。前者保证了数据写入时不会因集群异常而导致写入数据的丢失;后者保证了在集群出现严重问题时,数据不会发生丢失或者损坏。
高性能:底层的LSM 数据结构和Rowkey 有序排列等架构上的独特设计,使得HBase 具备非常高的写入性能2。Region 切分、主键索引和缓存机制使得HBase 在海量数据下具备一定的随机读取性能,该性能针对Rowkey 的查询能够达到毫秒级别。
稀疏:稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
总的来说,HBase 通过在廉价服务器上搭建大规模结构化存储集群,提供海量数据高性能的随机读写能力。它的数据模型和功能组件设计使得它在处理大数据的场景中具有很大的优势。
3. 部署搭建
3.1 下载
这里提供官方的下载地址
https://dlcdn.apache.org/hbase/
因为我是jdk17环境 所以我选择比较新的版本进行下载
jdk1.8的环境 可选择下载2.5.6
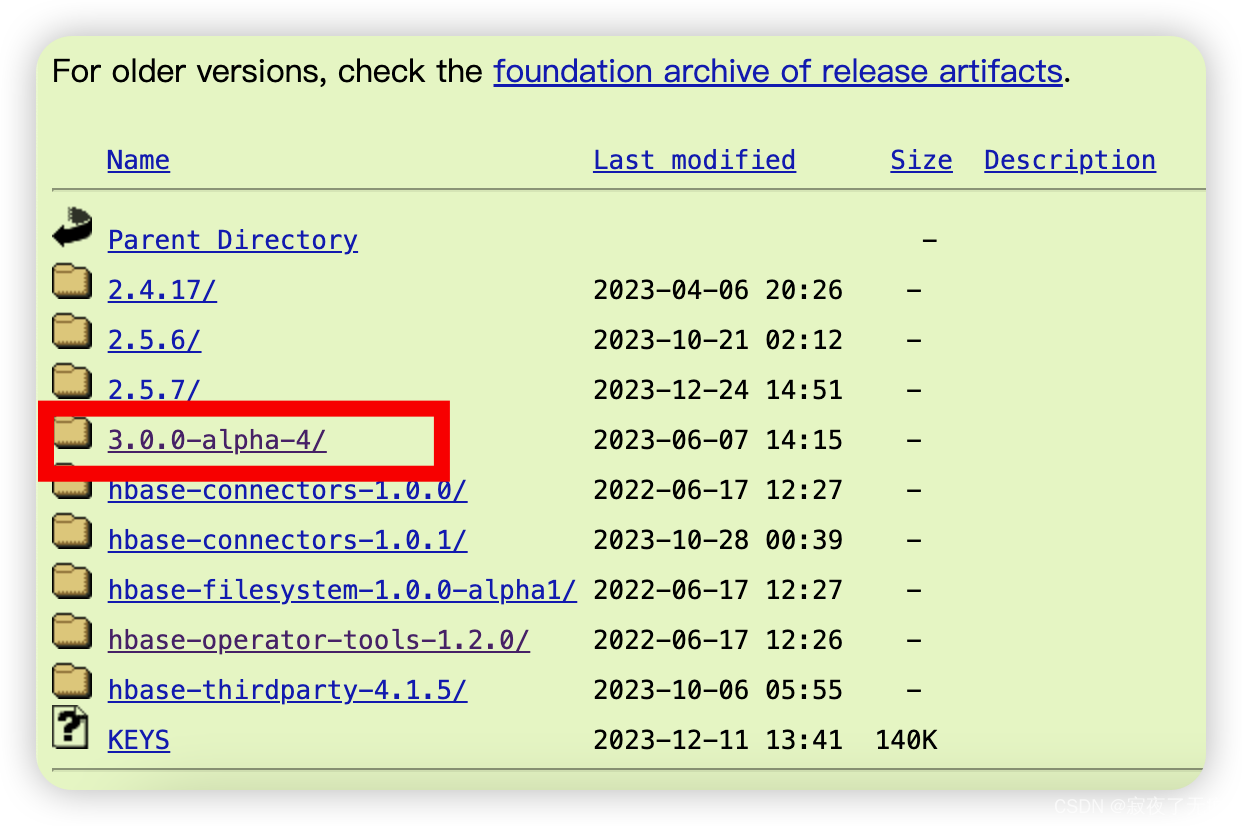
3.2 解压
解压后的目录如下
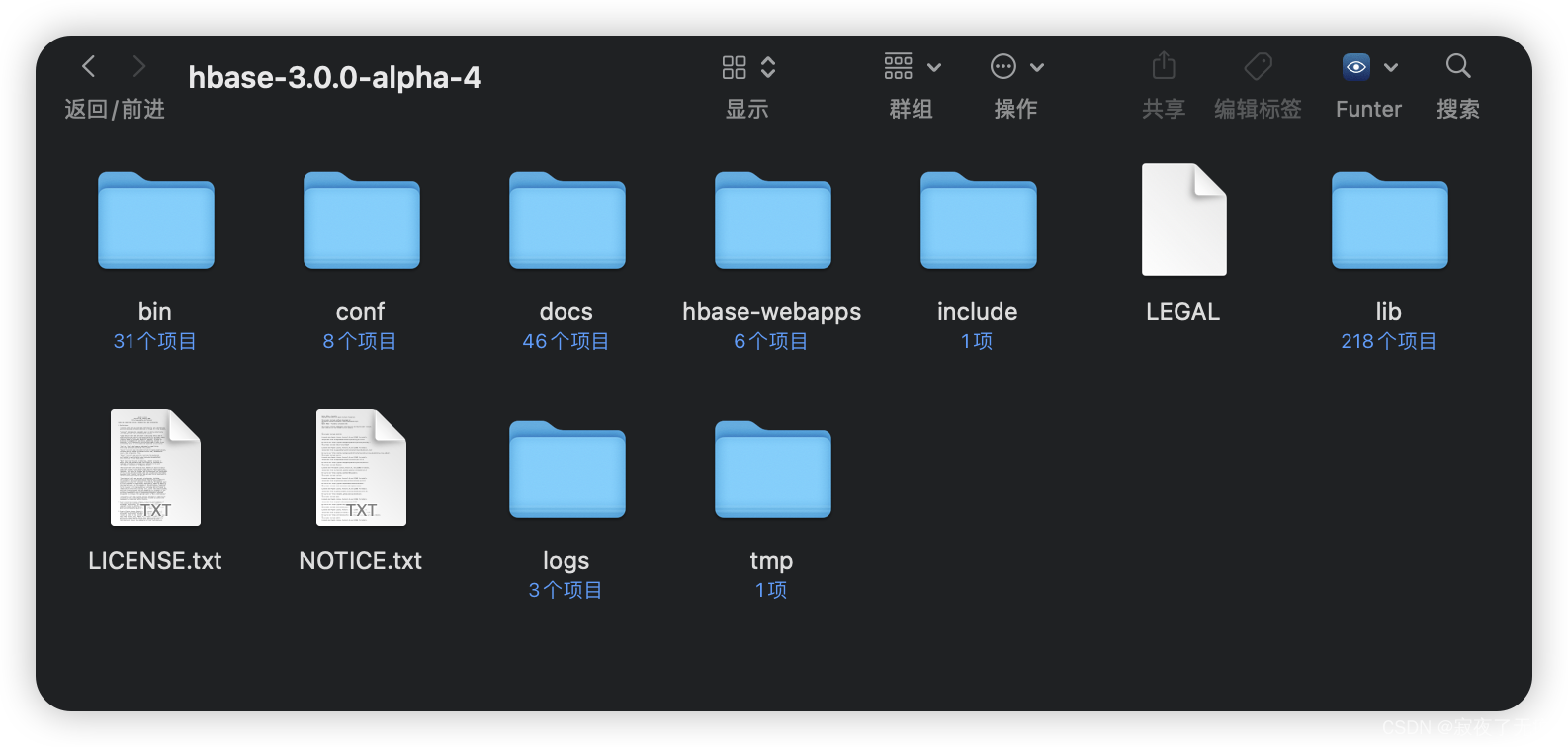
在doc的文件夹中是官方的文档 当然东西也比较多,可选择性看
3.3 配置
首先需要验证自己的java 环境这个是必须的
可直接使用java --version来验证
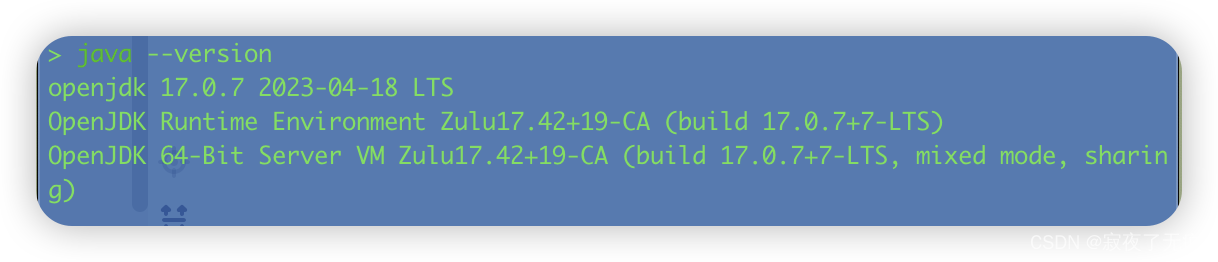
另外可以配置我们使用的java 环境 大多数适用于多环境的java 用户
直接修改配置 hbase-env.sh
新增 java的路径即可
export JAVA_HOME=/usr/local/develop/java/zulu-jdk17.0.7
没问题的话 可以下一步 配置hbase-site.xml
这里我们直接使用 本地文件路径 而不是hdfs 分布式文件系统
增加如下配置
<property>
<name>hbase.rootdir</name>
<!-- 修改为自己的hbase的路径-->
<value>file:///usr/local/develop/hbase</value>
</property>
3.4 启动
运行bin目录下的 start-hbase.sh 可直接启动

启动过程比较久 可观察日志 看看是否出错 启动完成后,会初始化一个master的单点应用
3.5 验证
第一个办法,看看日志
第二个 使用 hbase自带的控制页面来观察 http://localhost:16010/master-status
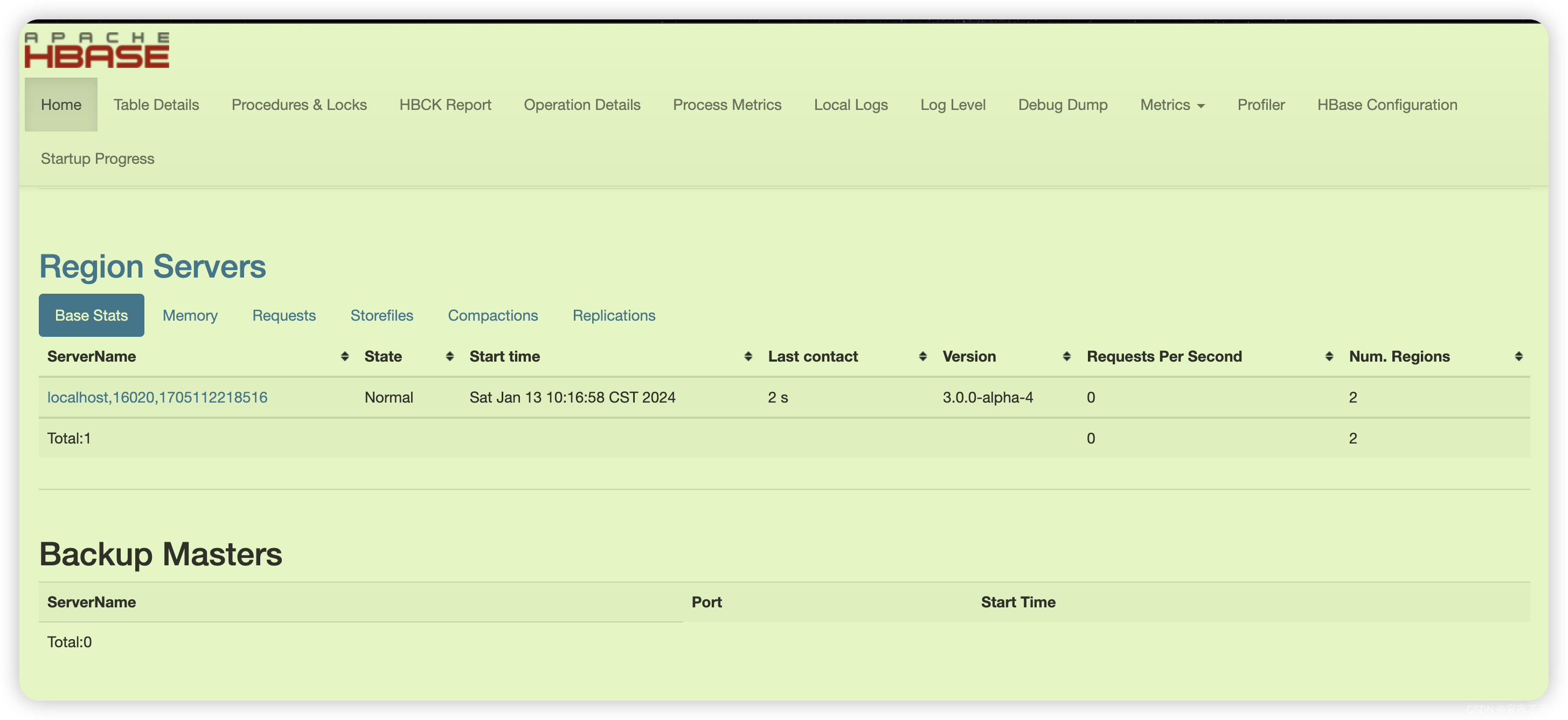
第三个 使用hbase shell
还是在bin目录下 直接运行 hbase shell
出来如下任务 即表示成功
第四个 使用jps 命令查看是否存在 HMaster
如下图

4. 基本使用
4.1 Create a table. 创建表
Use the create command to create a new table. You must specify the table name and the ColumnFamily name.
hbase(main):001:0> create 'test', 'cf'
0 row(s) in 0.4170 seconds
=> Hbase::Table - test
4.2 List Information About your Table 查看表
Use the list command to confirm your table exists
hbase(main):002:0> list 'test'
TABLE
test
1 row(s) in 0.0180 seconds
=> ["test"]
4.3 查看表的详情
Now use the describe command to see details, including configuration defaults
hbase(main):003:0> describe 'test'
Table test is ENABLED
test
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE =>
'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'f
alse', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE
=> '65536'}
1 row(s)
Took 0.9998 seconds
4.4 Put data into your table. 向表中新增数据
To put data into your table, use the put command.
hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0850 seconds
hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0110 seconds
hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0100 seconds
Here, we insert three values, one at a time. The first insert is at row1, column cf:a, with a value of value1. Columns in HBase are comprised of a column family prefix, cf in this example, followed by a colon and then a column qualifier suffix, a in this case.
4.5 Scan the table for all data at once. 查看表里的所有数据
One of the ways to get data from HBase is to scan. Use the scan command to scan the table for data. You can limit your scan, but for now, all data is fetched.
hbase(main):006:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1421762485768, value=value1
row2 column=cf:b, timestamp=1421762491785, value=value2
row3 column=cf:c, timestamp=1421762496210, value=value3
3 row(s) in 0.0230 seconds
Get a single row of data.
4.6 To get a single row of data at a time, use the get command. 查看第一行数据
hbase(main):007:0> get 'test', 'row1'
COLUMN CELL
cf:a timestamp=1421762485768, value=value1
1 row(s) in 0.0350 seconds
Disable a table.
4.7 如果要删除表或更改其设置以及在其他某些情况下,则需要使用Disable命令首先禁用表。您可以使用enable命令重新启用它。
hbase(main):008:0> disable 'test'
0 row(s) in 1.1820 seconds
hbase(main):009:0> enable 'test'
0 row(s) in 0.1770 seconds
Disable the table again if you tested the enable command above:
hbase(main):010:0> disable 'test'
0 row(s) in 1.1820 seconds
Drop the table.
4.8 To drop (delete) a table, use the drop command. 删除表
hbase(main):011:0> drop 'test'
0 row(s) in 0.1370 seconds
4.9 退出 shell
exit
4.10 关闭 hbase
./bin/stop-hbase.sh
5. tip
创建hbase失败时 需要清除干净失败的的数据 然后在重新开启
例如 存放点 hbase的目录 logs目录 以及 tmp目录
the end
goods day ~
![[zabbix] 分布式应用之监控平台zabbix的认识与搭建](https://img-blog.csdnimg.cn/direct/6820427111a944abaf266b85bdc6d0ba.png)